
1.Experimental purpose: 实验目的
The main purpose of this experiment is to verify Hadoop's support for HDFS (Distributed file system) and MapReduce by deploying Hadoop clusters in Docker containers. Through this experiment, we aim to gain an in-depth understanding of the configuration, startup, and verification process of Hadoop, as well as how Hadoop clusters work in a distributed environment.
这个实验的主要目的是通过在Docker容器中部署Hadoop集群,验证Hadoop对HDFS(分布式文件系统)和MapReduce的支持。通过这个实验,我们旨在深入了解Hadoop的配置、启动和验证过程,以及Hadoop集群在分布式环境中的工作原理。
2.Experimental steps: 实验步骤
2.1 Creating a Network and a Volume 创建网络与容器
Create Docker network bgnet and volume bgsysvol.
Function:Created a Docker network called bgnet,set up subnets and gateways.At the same time, a Docker volume named bgsysvol was created for sharing file systems between multiple containers.
创建Docker网络bgnet和卷bgsysvol。
功能:创建名为bgnet的Docker网络,设置子网和网关。同时,创建了一个名为bgsysvol的Docker卷,用于在多个容器之间共享文件系统。
2.2 Load images and create containers
#加载镜像
docker load -i ubtsshjava.img.tar
#创建容器
docker run -itd --name bgsvr0 --hostname bgsvr0 --ip 192.168.100.20 --network bgnet --volume bgsysvol:/bgsys:rw ubtsshjava
docker run -itd --name bgsvr1 --hostname bgsvr1 --ip 192.168.100.21 --network bgnet --volume bgsysvol:/bgsys:ro ubtsshjava
docker run -itd --name bgsvr2 --hostname bgsvr2 --ip 192.168.100.22 --network bgnet --volume bgsysvol:/bgsys:ro ubtsshjava

Function: Three containers, bgsvr0, bgsvr1, and bgsvr2, are created, each assigned a static IP, and connected to the bgnet network. In the meantime, the shared volume is mounted.
Then, start the container and log in to it:
功能:创建三个容器,分别命名为bgsvr0、bgsvr1和bgsvr2,为每个容器分配静态IP,并连接到bgnet网络。与此同时,将共享卷挂载到这些容器。
然后,启动这些容器并登录:
#停止/启动容器
docker stop bgsvr0
docker start bgsvr0
#如果容器已经启动,登入容器中
docker exec -it bgsvr0 /bin/bash

2.3 Installing and Configuring Hadoop 安装与配置Hadoop
Edit Hadoop configuration files, including workers, core-site.xml, hdfs-site.xml, yarn-site.xml, and mapred-site.xml.
steps:
- Copy the Hadoop installation package to bgsvr0: Installs Hadoop on the active node.
- Decompress the Hadoop installation package: Prepare the Hadoop file system and execution environment.
- Edit the workers file: list all working nodes to provide processing power for the cluster.
- Configure core-site.xml: Set the core configuration of HDFS, such as file system URI.
- Configure hdfs-site.xml: Set the data replication policy and storage path.
- Configure mapred-site.xml: Define parameters for executing MapReduce jobs.
- Configure yarn-site.xml: Configure YARN as a platform for job scheduling and resource management.
This step is the core of cluster functionality, including file storage, resource management, and job scheduling.
编辑Hadoop配置文件,包括workers、core-site.xml、hdfs-site.xml、yarn-site.xml和mapred-site.xml。
步骤:
- 将Hadoop安装包复制到
bgsvr0:在活动节点上安装Hadoop。 - 解压Hadoop安装包:准备Hadoop文件系统和执行环境。
- 编辑workers文件:列出所有工作节点,为集群提供处理能力。
- 配置core-site.xml:设置HDFS的核心配置,如文件系统URI。
- 配置hdfs-site.xml:设置数据复制策略和存储路径。
- 配置mapred-site.xml:定义执行MapReduce作业的参数。
- 配置yarn-site.xml:将YARN配置为作业调度和资源管理的平台。
这一步是集群功能的核心,包括文件存储、资源管理和作业调度。
#2 安装配置Hadoop
#拷贝Hadoop到容器中
docker cp hadoop-3.3.6.tar.gz bgsvr0:/bgsys
#进入容器,解包Hadoop
docker exec -it bgsvr0 /bin/bash
cd /bgsys
tar -zxvf hadoop-3.3.6.tar.gz
#编辑配置文件
vi /bgsys/hadoop-3.3.6/etc/hadoop/workers
bgsvr0
bgsvr1
bgsvr2

vi /bgsys/hadoop-3.3.6/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bgsvr0:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/root/data/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
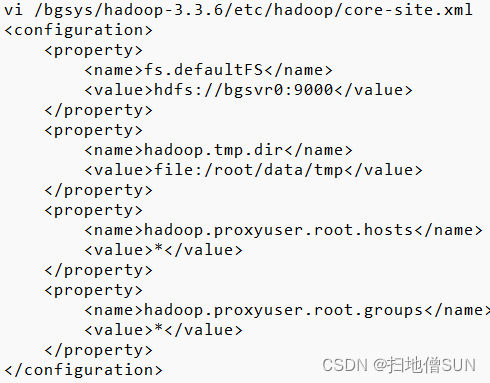
vi /bgsys/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
</description>
</property>
</configuration>
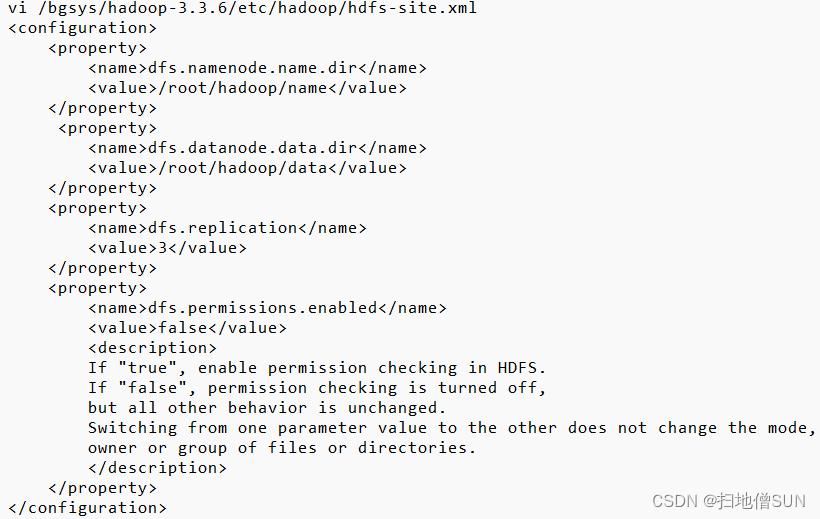
vi /bgsys/hadoop-3.3.6/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bgsvr0</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
vi /bgsys/hadoop-3.3.6/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bgsvr0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bgsvr0:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/root/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/root/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME/root/hadoop</value>
</property>
</configuration>
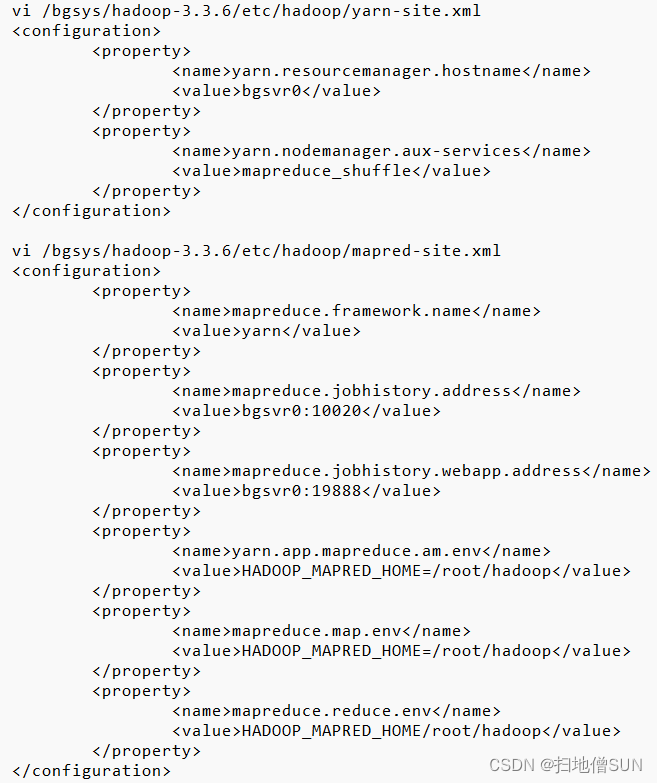
2.4 Configure user identities and related paths for Hadoop to start and stop services
配置Hadoop启动和停止服务的用户身份和相关路径
#root身份运行服务所需配置
vi /bgsys/hadoop-3.3.6/sbin/start-dfs.sh
vi /bgsys/hadoop-3.3.6/sbin/stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
vi /bgsys/hadoop-3.3.6/sbin/start-yarn.sh
vi /bgsys/hadoop-3.3.6/sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
#共享hadoop软件所需配置,在bgsvr0\1\2上
mkdir /root/hadoop/data -p
mkdir /root/hadoop/name
mkdir /root/hadoop/logs
#在bgsvr0上
ln -s /root/hadoop/logs /bgsys/hadoop-3.3.6/logs
①Specifies the user identity used by the corresponding component when Hadoop's distributed file system (HDFS) is started and stopped.
②Specifies the user identity used by the corresponding component when the YARN (Yet Another Resource Negotiator) is started and stopped.
③A directory is created on each node for storing Hadoop data (/root/hadoop/data), name nodes (/root/hadoop/name), and logs (/root/hadoop/logs).
④Create a symbolic link on bgsvr0 linking /bgsys/hadoop-3.3.6/logs to /root/hadoop/logs. The purpose of this is to enable Hadoop to write log files to the /root/hadoop/logs directory, thus achieving centralized management of logs.
The above configuration and actions ensure that Hadoop starts and stops with the correct user identity and provides it with the correct directory structure to store data and logs.
①指定在启动和停止Hadoop的分布式文件系统(HDFS)时,相应组件使用的用户身份。
②指定在启动和停止YARN(Yet Another Resource Negotiator)时,相应组件使用的用户身份。
③在每个节点上创建用于存储Hadoop数据(/root/hadoop/data)、名称节点(/root/hadoop/name)和日志(/root/hadoop/logs)的目录。
④在bgsvr0上创建一个符号链接,将/bgsys/hadoop-3.3.6/logs链接到/root/hadoop/logs。这样做的目的是使Hadoop能够将日志文件写入/root/hadoop/logs目录,从而实现对日志的集中管理。
以上配置和操作确保了Hadoop以正确的用户身份启动和停止,并提供了正确的目录结构来存储数据和日志。
2.5 Formatting HDFS 格式化HDFS
/bgsys/hadoop-3.3.6/bin/hdfs namenode -format
Function: Initialize the HDFS file system and prepare the file system structure for the cluster.
功能:初始化HDFS文件系统,为集群准备文件系统结构。
2.6 Starting a Hadoop Cluster 启动Hadoop集群
#4 启动hadoop, 在bgsvr0上
#hdfs
/bgsys/hadoop-3.3.6/sbin/start-dfs.sh
#yarn
/bgsys/hadoop-3.3.6/sbin/start-yarn.sh

3.Verification method and results 验证方法和结果
Hadoop run verification.
Execute a command:jps
Running result:
Hadoop运行验证。
执行命令:jps
运行结果:

4.Experimental summary 实验总结
Through this experiment, we have a deep understanding of the installation, configuration and verification process of Hadoop. A distributed cluster containing HDFS and MapReduce is set up successfully, and the normal running of the cluster is verified.
During the experiment, I learned the basic concept of Hadoop cluster, the working principle of HDFS, and the submission and monitoring methods of MapReduce jobs. This lays the foundation for further in-depth learning of big data processing and distributed computing.
In general, this experiment made me have a deeper understanding of the distributed system of Hadoop, and improved my practical operation and problem solving ability in the field of big data.
通过这次实验,我们深入了解了Hadoop的安装、配置和验证过程。成功搭建了一个包含HDFS和MapReduce的分布式集群,并验证了集群的正常运行。
在实验过程中,我学习了Hadoop集群的基本概念、HDFS的工作原理,以及MapReduce作业的提交和监控方法。这为进一步深入学习大数据处理和分布式计算奠定了基础。
总体而言,这次实验使我对Hadoop的分布式系统有了更深刻的理解,提高了我在大数据领域的实际操作和问题解决能力。
用心写好每一篇文章。感谢大家的支持~
版权归原作者 扫地僧SUN 所有, 如有侵权,请联系我们删除。