
1.创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
然后输入自己当前hadoop账户的密码进行验证,接着:
sudo passwd hadoop
设置自己hadoop用户登录的密码,显示设置成功后,为hadoop用户添加管理员权限
sudo adduser hadoop sudo

然后切换到hadoop用户进行登录,密码就是刚才自己为hadoop用户设置的密码
2.进入hadoop用户后,先进行软件更新,以防后续安装配置出现报错,这里更新需要输入hadoop用户密码验证
sudo apt-get update
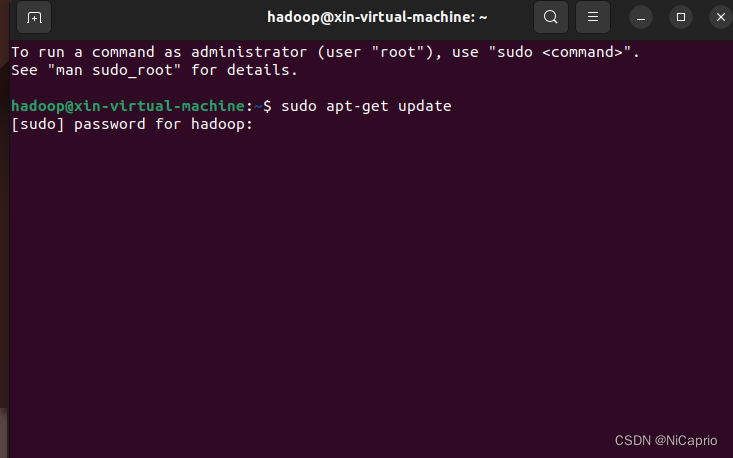
3.显示如下界面时,代表更新完成
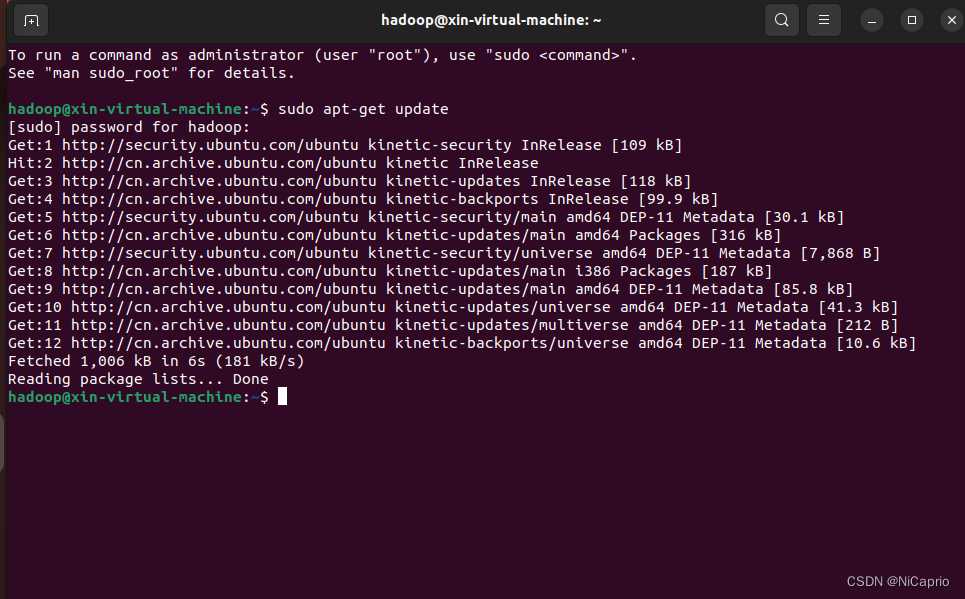
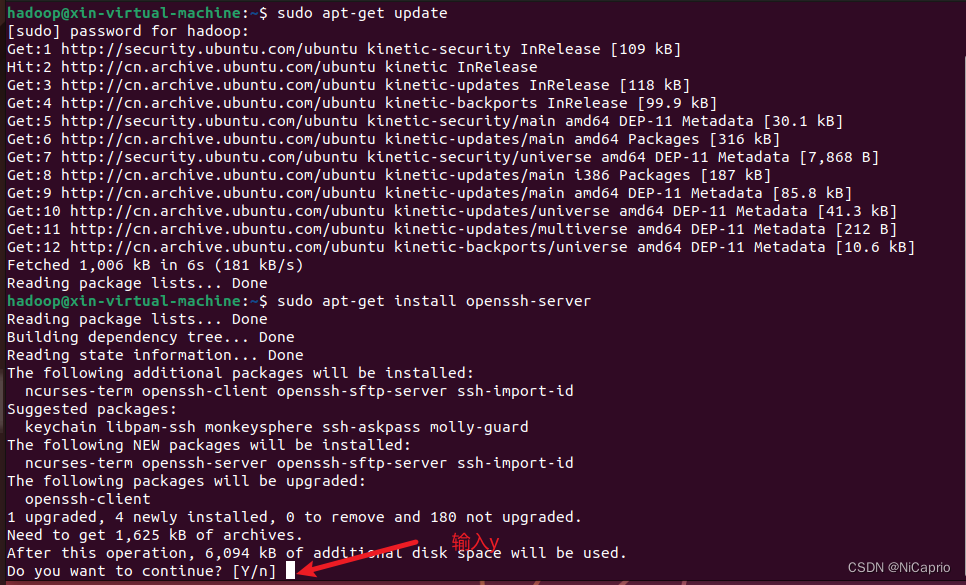
4.安装SSH服务端
由于hadoop集群单点模式要使用到SSH登录,Ubuntu默认有SSH client ,这里我们安装SSH Server即可
sudo apt-get install openssh-server
出现选择是否继续,输入 Y 即可
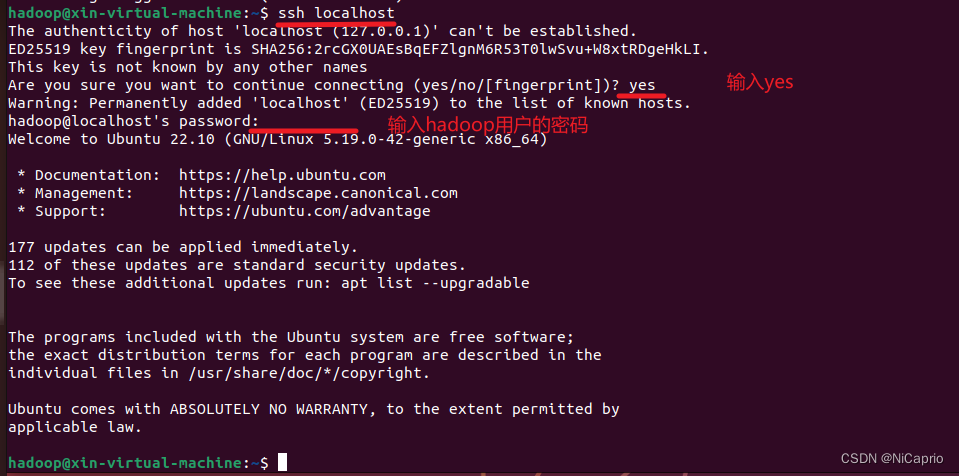
5.登录SSH
ssh localhost
出现是否继续,输入yes ,用hadoop用户密码进行验证
6.配置无密码登录SSH
首先退出SSH,输入exit退出

进入~/.ssh/,并用ssh-keygen生成密钥
cd ~/.ssh/
ssh-keygen -t rsa
接着按三次回车即可

将密钥加入到授权中,再次使用 ssh localhost登录,发现不再需要密码
cat ./id_rsa.pub >> ./authorized_keys

7.安装Java环境
首先更新软件包
sudo apt-get update
然后安装openjdk-8,出现选择是否继续时,输入y即可
sudo apt-get install openjdk-8-jdk
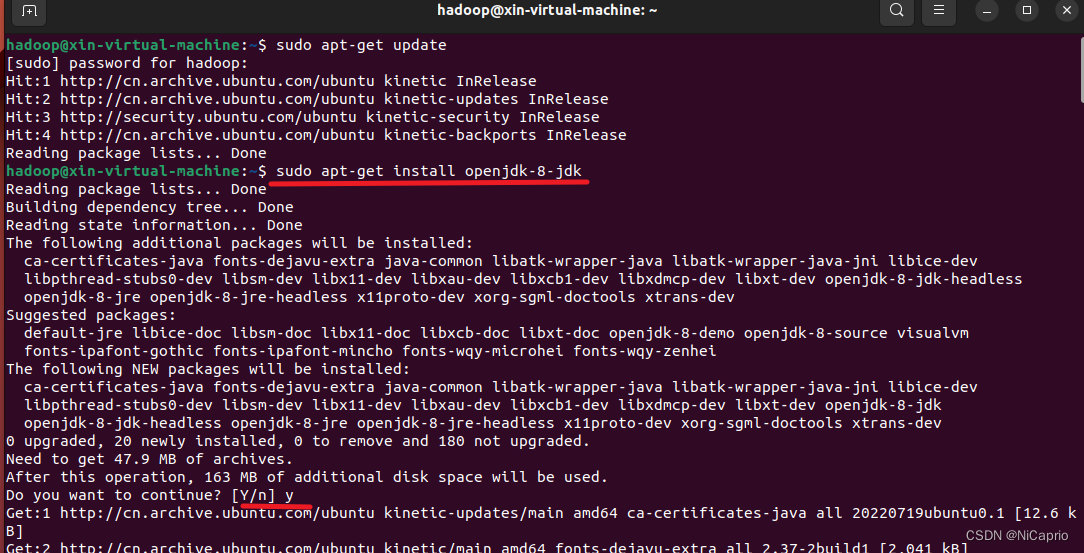
查看java是否安装成功
java -version

配置环境变量,这里使用gedit来编辑,如果没有安装,输入下方命令进行安装:
sudo apt install gedit
安装好gedit后继续
gedit ~/.bashrc
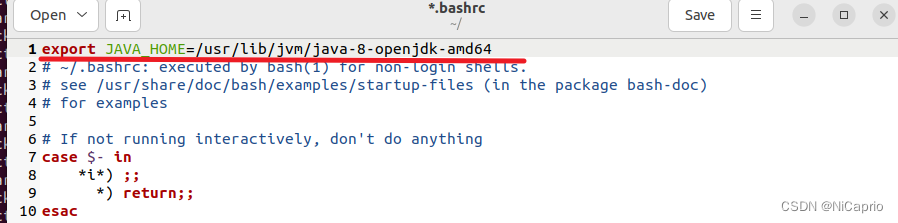
在第一行添加如下代码
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
保存后退出
然后输入下面命令,让环境变量生效
source ~/.bashrc
查看配置的环境变量
echo $JAVA_HOME
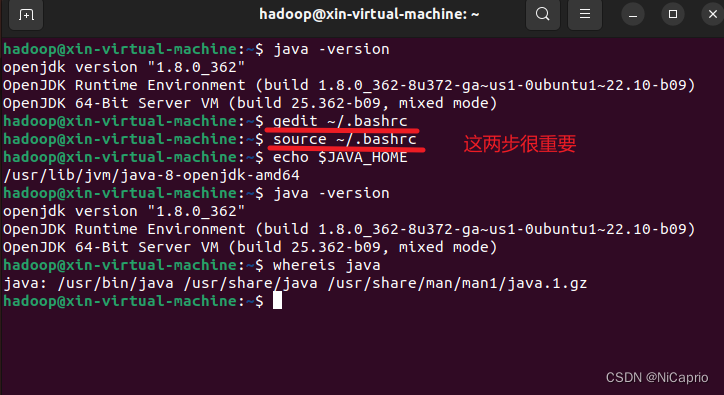
配置完成
8。下载Hadoop压缩包
确保自己的虚拟机可以连接到网络,到浏览器搜索hadoop,然后下载hadoop压缩包,这里我选择了hadoop3.2.4版本,如果官网下载速度慢的话,可以搜索hadoop镜像去下载,下边是清华镜像站的hadoop链接
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/

9.解压Hadoop压缩包
输入下面命令解压到 /usr/local路径:
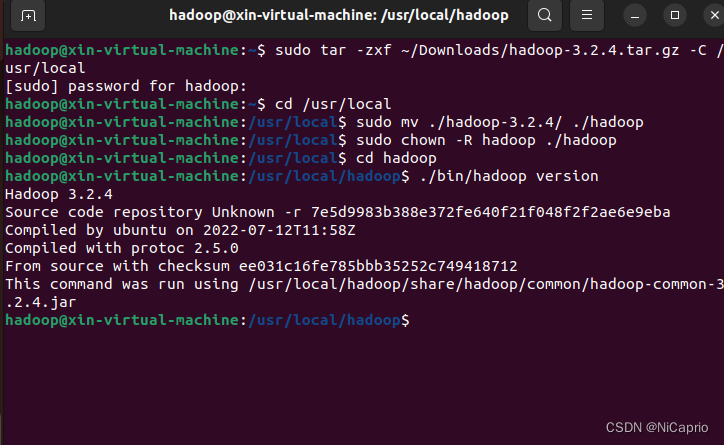
sudo tar -zxf ~/Downloads/hadoop-3.2.4.tar.gz -C /usr/local
然后进入到解压路径下,改名为hadoop
cd /usr/local
sudo mv ./hadoop-3.2.4/ ./hadoop
修改hadoop文件权限
sudo chown -R hadoop ./hadoop
进入到hadoop文件,查看hadoop是否安装成功
cd /usr/local/hadoop
./bin/hadoop version
显示出hadoop版本号说明安装成功
10.Hadoop伪分布式配置
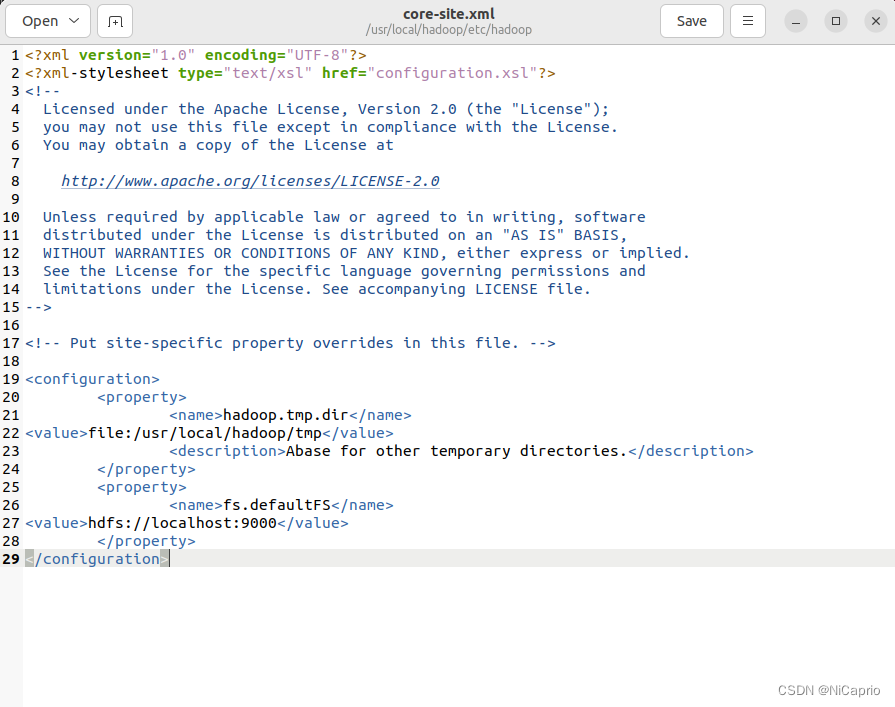
首先配置 core-site.xml 文件
cd /usr/local/hadoop
gedit ./etc/hadoop/core-site.xml

在<configuration></configuration>中加入代码:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
然后配置 hdfs-site.xml 文件
gedit ./etc/hadoop/hdfs-site.xml
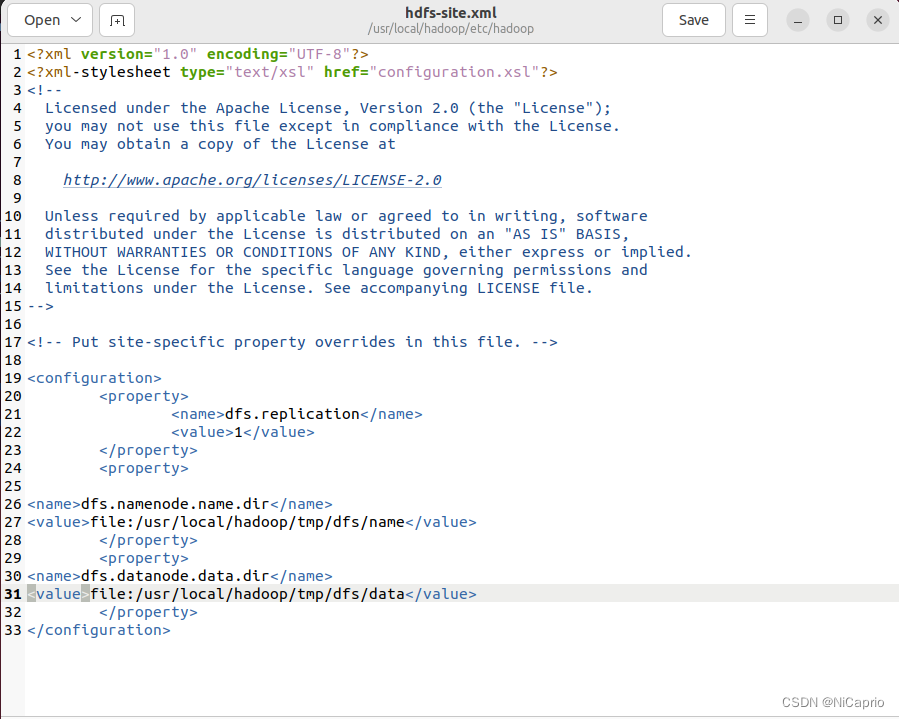
在<configuration></configuration>中加入代码:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
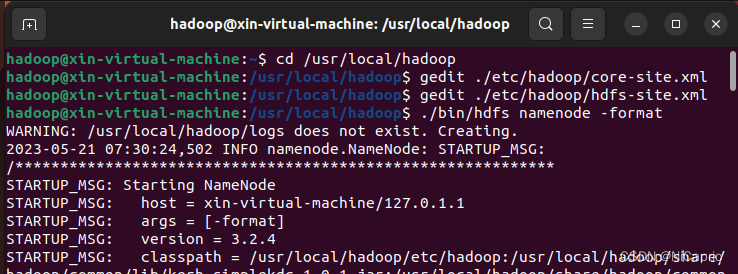
配置完成后,执行namenode的格式化
./bin/hdfs namenode -format
然后开启namenode和datanode守护进程
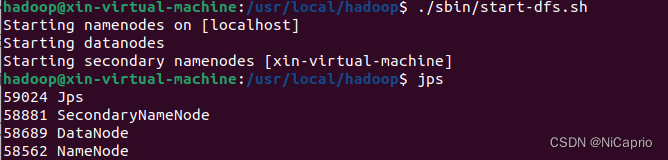
./sbin/start-dfs.sh
通过 jps 来查看是否成功启动,显示下图代表启动成功,如果没有namenode或者datanode进程显示,说明前面配置出现问题,请检查前面步骤是否出现错误
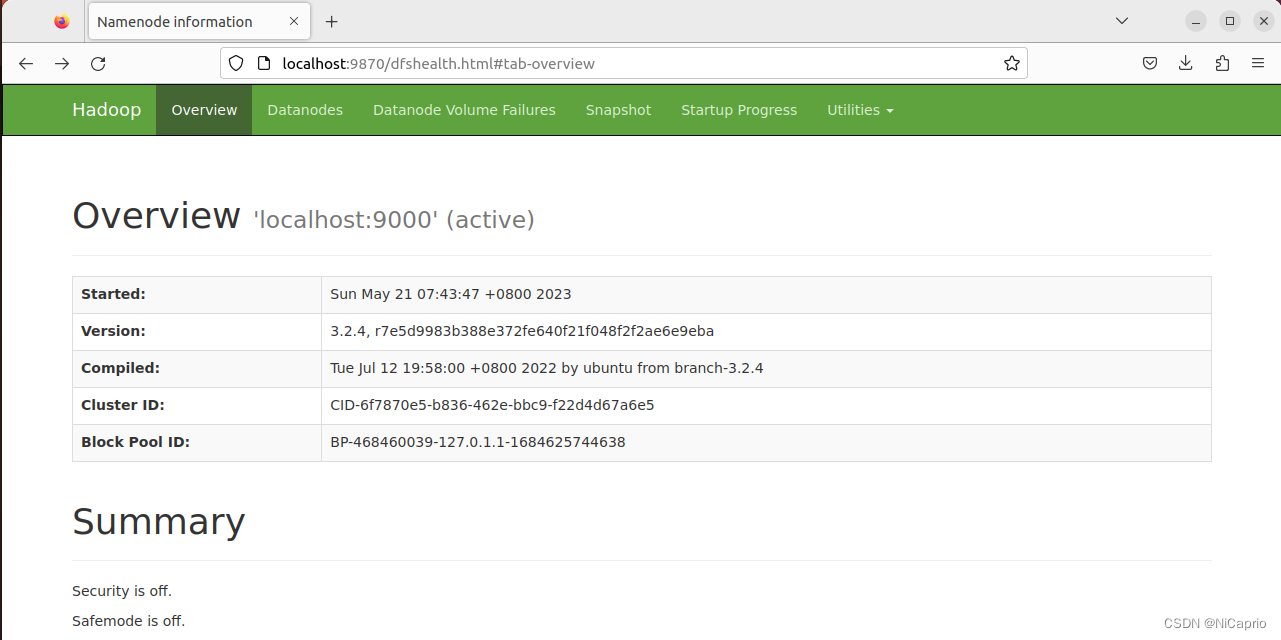
在浏览器地址栏中访问 localhost:9870,出现如下界面,此时hadoop的伪分布式就配置成功啦,注意从hadoop3.x版本开始,端口号改为了9870,而不是50070
说明:这里配置的Ubuntu版本是22.10,Hadoop版本是3.2.4,文章可能存在不严谨的地方,还希望大佬们指正,在此共勉。
版权归原作者 无敌欣 所有, 如有侵权,请联系我们删除。