
在hive sql开发的过程中,对于当前数据在另一个数据集合中,是否存在的判断有三种方式,一种是in ,一种是exists,另一种可以是left semi join,但是由于hive不支持in|not in子查询,所以如果是单纯判断一个值是否在一个集合里面存在的时候,可以用in,但是判断一个集合在另一个集合存在的时候,还是推荐使用exists和left semi join。
一、数据准备
1,建表
CREATETABLE test.in_test1
(
id varchar(10),name varchar(10),sex varchar(10),age varchar(10));CREATETABLE test.in_test2
(
id varchar(10),name varchar(10),class varchar(10),school varchar(10));
2,插入数据
INSERTINTO test.in_test1 VALUES('1','xiaoming','1','17'),('2','xiaohua','0','23'),('3','jack','1','12'),('4','rose','0','28'),('5','jenny','0','45'),('6','judy','0','10'),('7','wangwu','1','35');INSERTINTO test.in_test2 VALUES('1','xiaoming','3','花花高中'),('2','xiaohua','5','北京大学'),('3','jack','2','新民中学'),('4','rose','1','清华大学');
3,查询数据
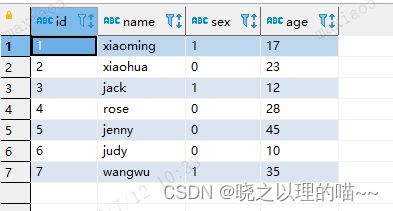
SELECT*FROM test.in_test1;
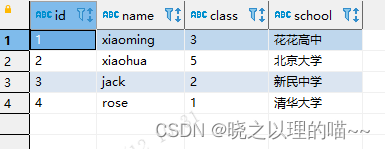
SELECT*FROM test.in_test2;
二、join
1,查询语句
SELECT*FROM test.in_test1 test1
JOIN test.in_test2 test2
ON test1.name = test2.name
;
2, 查询结果
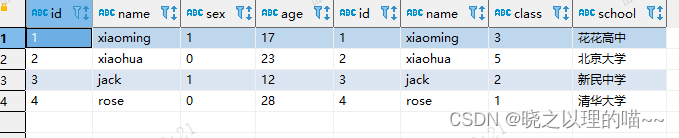
三、exists
1,查询语句
SELECT*FROM test.in_test1 test1
WHERE1=1ANDEXISTS(SELECT*FROM test.in_test2 test2 WHERE test1.name = test2.name)
;
2, 查询结果
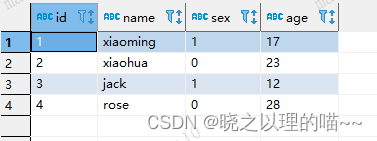
四、left semi join
left semi join 只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表;遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,在关联的时候会更加的高效。
1,查询语句
SELECT*FROM test.in_test1 test1
left semi JOIN test.in_test2 test2
ON test1.name = test2.name;
2, 查询结果
总结
所以在判断是否存在的时候,由于Hive 不支持 where 子句中的子查询,所以最好的办法是采用exists和left semi join,这样在运行效率上面也会提高很多。
本文转载自: https://blog.csdn.net/weixin_42011858/article/details/125838641
版权归原作者 晓之以理的喵~~ 所有, 如有侵权,请联系我们删除。
版权归原作者 晓之以理的喵~~ 所有, 如有侵权,请联系我们删除。