
FlinkSql 的 Join
Flink 官网将其分为了 Joins 和 Window Joins两个大类,其中里面又分了很多 Join 方式
参考文档:
Joins | Apache Flink
Window JOIN | Apache Flink
Joins
官网介绍共有6种方式:
- Regular Join:流与流的 Join,包括 Inner Join、Outer Equal Join
- Interval Join:流与流的 Join,两条流一段时间区间内的 Join
- Temporal Join:流与流的 Join,包括事件时间,处理时间的 Temporal Join,类似于离线中的快照 Join
- Lookup Join:流与外部维表的 Join
- Array Expansion:表字段的列转行,类似于 Hive 的 explode 数据炸开的列转行
- Table Function:自定义函数的表字段的列转行,支持 Inner Join 和 Left Outer Join

Regular Join
写法上和传统数据库没有区别,关联条件支持等值和非等值Join,有Inner Join 和 Outer Join(Left Join、Right Join、FULL JOIN)
有人问我为什么要特别区分内外连接,后面会用到
内连接是通过匹配两个表之间的共同列,返回满足连接条件的行。只有在连接条件匹配的情况下,才会返回结果。
外连接是在内连接的基础上,还包括了不满足连接条件的行。
SELECT order_id, uid, price, user_name
FROM order a
Left JOIN user b
ON a.uid = b.uid
顺便了解一下流是怎么 Join 的:
和离线不同,离线是一批数据一起运算的,完成后输出结果
FlinkSql是Dynamic Table的概念,数据在 State 里面,每来一条数据就会对左右两边的数据进行关联
Regular Join 的 State 默认是永久保存的,为了避免 State 无限膨胀,可以根据情况决定是否设置状态清理:table.exec.state.ttl(目前是根据更新时间来判断是否过期,而非访问时间)
再来看看几种 Join ,其中outer Join产生的回撤流是和传统离线方式有很大区别的:
首先不考虑数据源有回撤的情况,Regular Join在 Outer Join 时会产生回撤流,L-左表、R-右表
Inner Join:两条流 Join 到才输出
+[L, R],关联不上不会输出Left Join:当左流数据到达之后就会直接输出
可以 Join 到右流则输出
+[L,R]
,Join 不到右流输出
+[L,null]
)
如果之后右流之后数据到达之后,发现左流之前输出过没有 Join 到的数据
则会发起回撤流,先输出
-[L,null]
,然后在输出一条
+[L,R]
Right Join:有 Left Join 一样,只是逻辑相反
Full Join:和Left原理一样,左流或者右流的数据到达之后,无论有没有 Join 到另外一条流的数据,都会输出,如果一条流的数据到达之后,发现之前另一条流之前输出过没有 Join 到的数据,则会发起回撤流
对右流来说:Join 到输出
+[L,R]
,没 Join 到输出
+[null,R]
,左流数据到达后回撤
-[null,R]
,输出
+[L,R]
对左流来说:Join 到输出
+[L,R]
,没 Join 到输出
+[L,null]
),右流数据到达后回撤
-[L, null]
,输出
+[L,R]
图解:
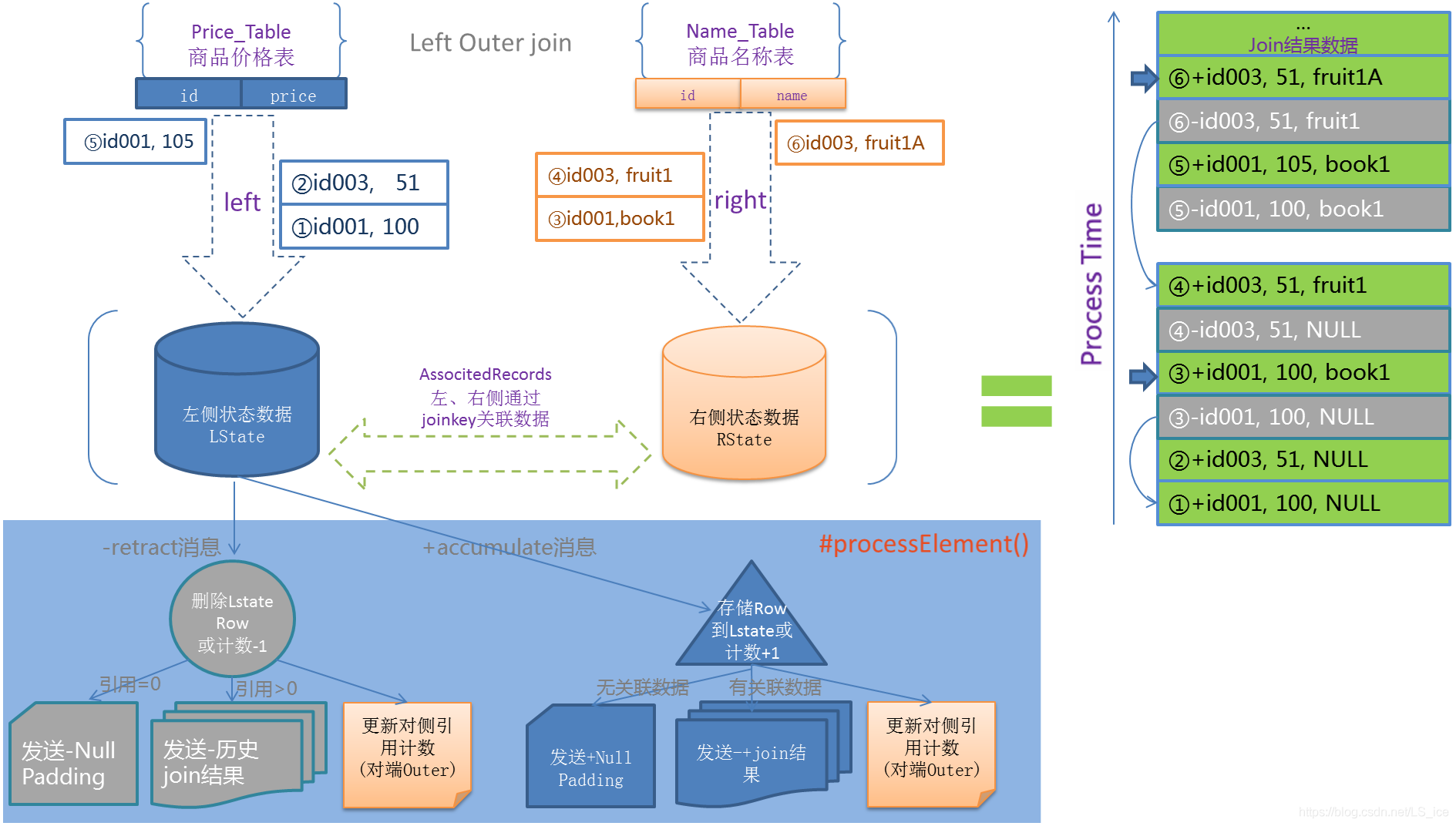
Regular Join 过程图
inner join 和 lef join 输出结果示例:
inner join
+I[5, d, 5, f]
+I[5, d, 5, 8]
+I[3, 4, 3, 0]
left join
+I[3, 4ab, null, null]
+I[5, f3c, 5, c05]
+I[5, 6e2, 5, c05]
-D[3, 4ab, null, null]
+I[3, 4ab, 3, 765]
关于 Regular Join 的注意事项:
- 实时 Regular Join 可以不是
等值 join。等值 join和非等值 join区别在于,等值 join数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;非等值 join数据 shuffle 策略是 Global,所有数据发往一个并发,按照非等值条件进行关联 - Join 的流程是左流新来一条数据之后,会和右流中符合条件的所有数据做 Join,然后输出,如果是outer join会立即输出之后产生回撤流
- 流的上游是无限的数据,所以要做到关联的话,Flink 会将两条流的所有数据都存储在 State 中,所以 Flink 任务的 State 会无限增大,因此你需要为 State 配置合适的 TTL,以防止 State 过大。
Interval Join
Interval Join 只支持普通 Append 数据流,不支持含 Retract 的动态表
Interval Join 左右表仅在某个时间范围(给定上界和下界)内进行关联,这个时间区间支持event time 和 processing time两种语义,如果是 event time,会根据区间和Watermark自动清理状态
场景示例:用户下单产生订单信息,用户必须在下单后一个小时以内付款,输出付款的订单信息
SELECT
o.orderId,
o.productName,
p.payType,
o.orderTime,
cast(payTime as timestamp) as payTime
FROM Orders o
JOIN Payment p
ON o.orderId = p.orderId
AND p.payTime BETWEEN orderTime AND orderTime + INTERVAL ‘1’ HOUR
Interval Join 几种方式,需要注意 Interval Join 不会产生回撤流:
- Inner Join:只有两条流 Join 到才输出,输出
+[L, R] - Left Join:和 Regular Join 不同,左流数据到达之后,如果没有 Join 到右流的数据,就会等待(放在 State 中等),如果之后右流之后数据到达之后,发现能和刚刚那条左流数据 Join 到,这时输出
+[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间)。如果发现发现左流 State 中的数据过期了,就把左流中过期的数据从 State 中删除,然后输出+[L, null](这时候其实已经延迟了),如果右流 State 中的数据过期了,就直接从 State 中删除 - Right Join:同 Left Join,逻辑相反
- Full Join:流任务中,左流或者右流的数据到达之后,如果没有 Join 到另外一条流的数据,就会等待(左流放在左流对应的 State 中等,右流放在右流对应的 State 中等),如果之后另一条流数据到达之后,发现能和刚刚那条数据 Join 到,则会输出
+[L, R]。事件时间中随着 Watermark 的推进(也支持处理时间),发现 State 中的数据能够过期了,就将这些数据从 State 中删除并且输出(左流过期输出+[L, null],右流过期输出-[null, R])
图解:
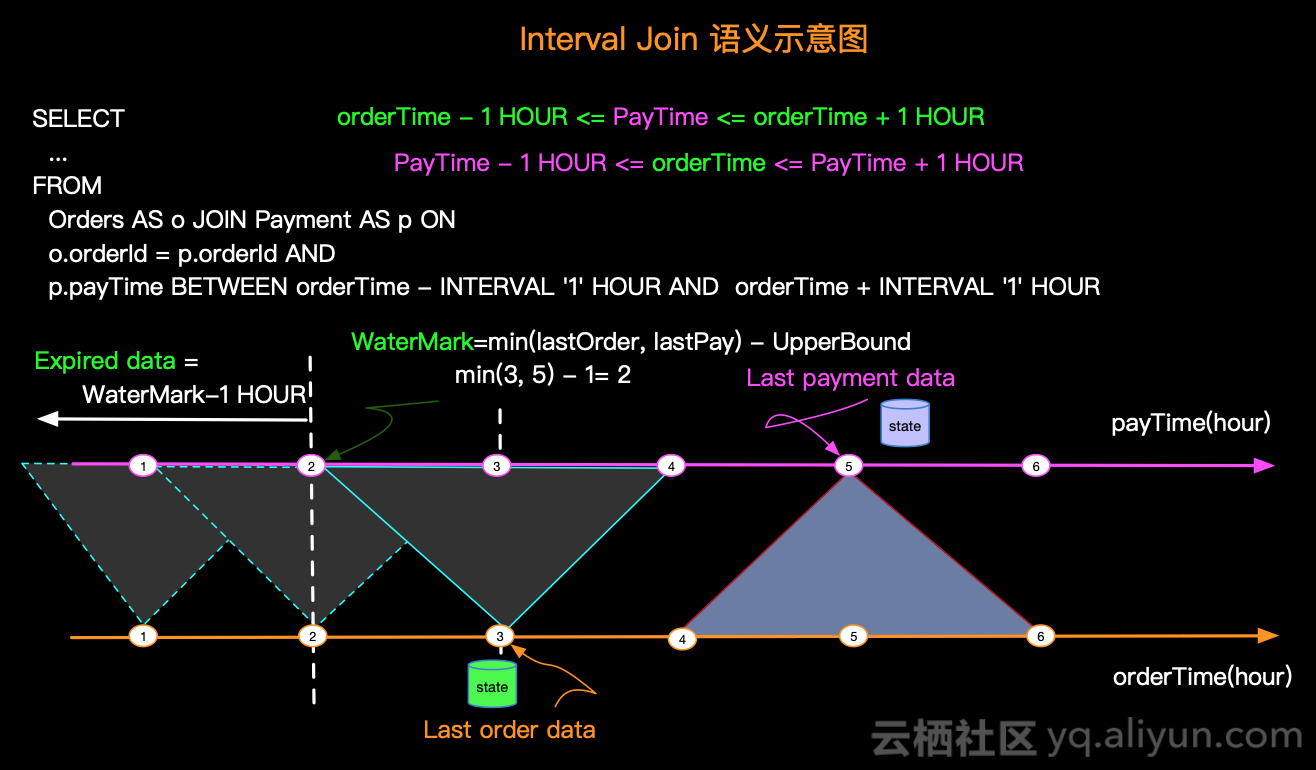
图片来自阿里云社区
inner join不用多说,看看 left join 输出结果示例:
+I[6, e, 6, 7]
+I[11, d, null, null]
+I[7, b, null, null]
+I[8, 0, 8, 3]
+I[13, 6, null, null]
关于 Interval Join 的注意事项:
- 实时 Interval Join 可以不是 等值 join。等值 join 和 非等值 join 区别在于,等值 join 数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游;非等值 join 数据 shuffle 策略是 Global,所有数据发往一个并发,然后将满足条件的数据进行关联输出
- outer join 不会产生回撤流,关联不上会在 State 过期时发送数据,会有延迟
Temporal Joins
这种关联方式同样是传统数据库没有的,但是会发现和数仓的拉链表Join有点类似
Temporal Join 支持和 Verisoned Table 进行关联,也支持 event time 和 processing time 两种语义,支持inner join 和 left join 两种方式
事件时间
,在解决多版本问题时有奇效:
- 事件时间的 Temporal Join 一定要给左右两张表都设置 Watermark
- 事件时间的 Temporal Join 一定要把 Versioned Table 的主键包含在 Join on 的条件中
--官网案例
CREATE TABLE orders (
order_id STRING,
price DECIMAL(32,2),
currency STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '15' SECOND
) WITH (/* ... */);
-- 必须定义一个 versioned table
CREATE TABLE currency_rates (
currency STRING,
conversion_rate DECIMAL(32, 2),
update_time TIMESTAMP(3)
METADATA FROM `values.source.timestamp` VIRTUAL,
WATERMARK FOR update_time AS update_time - INTERVAL '15' SECOND,
PRIMARY KEY(currency) NOT ENFORCED
) WITH (
'connector' = 'kafka'
/* ... */
);
SELECT
order_id,
price,
orders.currency,
conversion_rate,
order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;
order_id price currency conversion_rate order_time
======== ===== ======== =============== =========
o_001 11.11 EUR 1.14 12:00:00
o_002 12.51 EUR 1.10 12:06:00
Flink SQL 会为 Versioned Table 维护 Primary Key 下的所有历史时间版本的数据,然后根据左表Orders的事件时间关联到对应时间的 Versioned Table 的汇率
Processing Time,由于是处理时间,只维护了最新的状态数据,不需要关心历史版本的数据,直接根据LeftTable数据到达的时间关联最新的数据
另外还支持 Temporal Table Functionv Join,但是一般不怎么用(至少我基本不这样写)
SELECT
o_amount, r_rate
FROM
Orders,
LATERAL TABLE (Rates(o_proctime))
WHERE
r_currency = o_currency
Lookup Join
Lookup Join 通常用于关联外部系统数据(比如Mysql、Hbase等),但是目前只支持 processing time,只能以处理时间关联最新的数据(这个最新是有代价的)
实际用起来其实会发现功能上和 version table 的processing 类似
-- 官网案例,需要定义一个外部存储的表
CREATE TEMPORARY TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
);
-- enrich each order with customer information
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;
待办:lookup支持cache,cache的异步查询原理,数据更新的延迟,参数调优等等
Array Expansion
常见的用法就是类似Spark 的 lateral view expload(arr)
SELECT order_id, tag
FROM Orders CROSS JOIN UNNEST(tagArray) AS t (tag)
Table Function
其实和 Array Expansion 功能类似,但是 Table Function 本质上是个 UDTF 函数,并且支持自定义函数
Window Joins
见 FlinkSql 窗口函数
语法示例:
SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id,
COALESCE(L.window_start, R.window_start) as window_start,
COALESCE(L.window_end, R.window_end) as window_end
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L
INNER JOIN (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R
ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE EXISTS (
SELECT * FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end);
版权归原作者 orange大数据技术探索者 所有, 如有侵权,请联系我们删除。