
Flink状态一致性检查点
一致性检查点:是指在某一个时刻所有算子将同一个任务都完成的情况下进行的一个快照(方便后续计算出错时,提供一个数据恢复的快照)。Flink有状态的流处理,内部每个算子任务都可以有自己的状态,对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确。
1、Spark & Flink 的CheckPoint
–
Spark的CheckPoint也容错机制,对RDD的状态进行保存切断血缘关系,而Spark在map->reduce过程中宽窄依赖划分出的stage会又临时中间结果,所以我们可以拿此中间结果进行CP,这样就实现了Spark的容错机制,即便后面计算出现错误也可以通过CP重新计算。
–Flink的CheckPoint也是容错机制(是状态一致性检查点),因为Flink的算子大部分都是有状态的,所以在某个时刻所有算子都完成了同一个任务时,进行一个快照,此时则是一个CheckPoint,其中涉及到了一个
barrier(栅栏)的概念来实现快照时数据的混乱以及系统的暂停。
**
一个完整的快照包含=Source状态+算子状态+Sink事务/两次提交机制
**
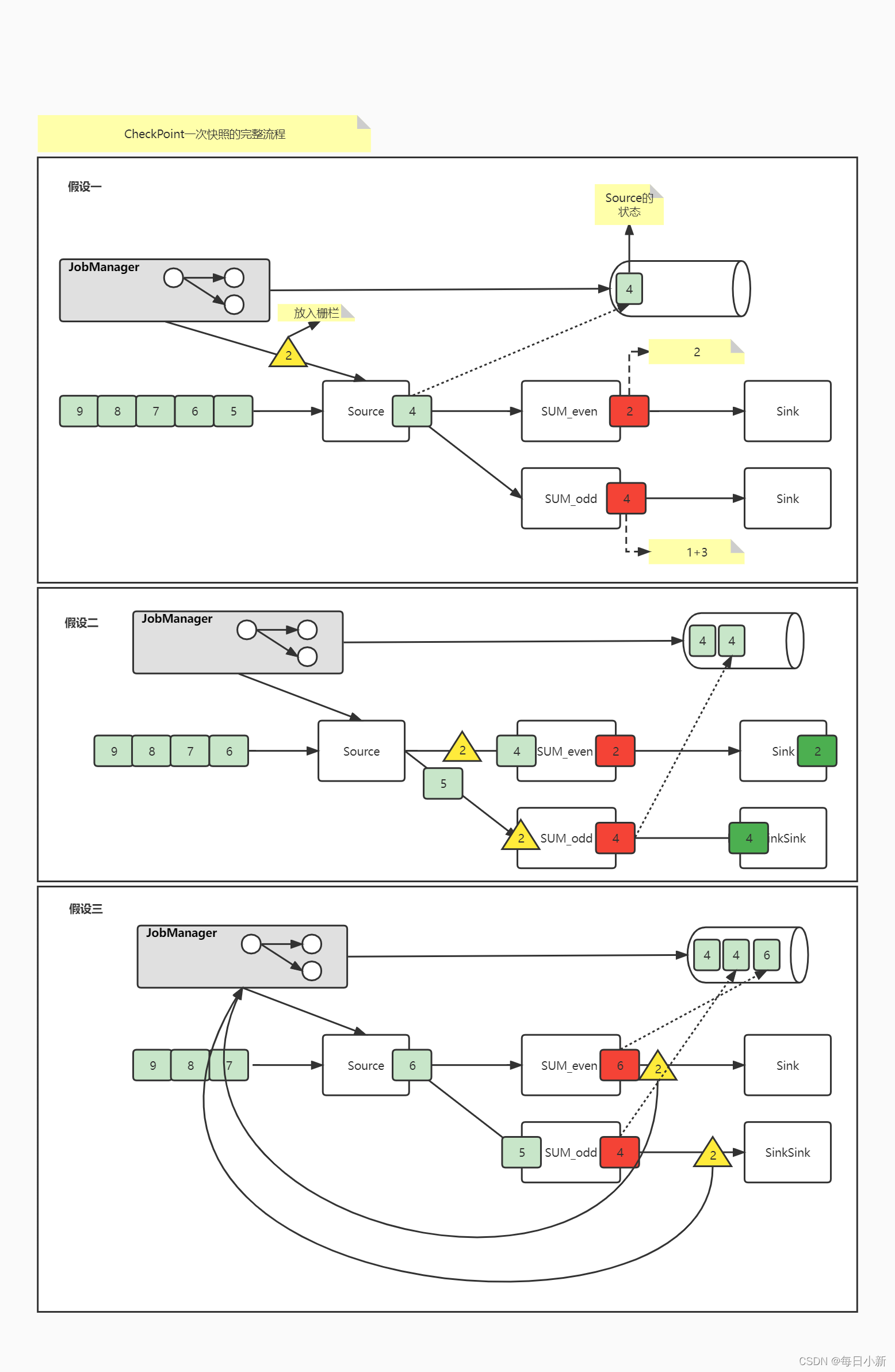
2、单数据源快照流程
流程:
— 图1:首先由图看出数据源此时状态是数据4,此时由JobManager发送栅栏到数据中,随数据流动(特殊的一条数据),当栅栏到达source时则保存source的状态到存储系统中(HDFS、DB等)。
— 图2:栅栏经过Source之后准备进入SUM_even和SUM_odd两个算子,此处栅栏到达到算子,则对算子保存当前状态到存储器中。
— 图3:算子状态保存完毕,栅栏则返回给JobManager,此时JobManager形成映射图,并保存CheckPoint ID (栅栏ID)
Sink对外输出数据,也需要控制其发送的情况,保证状态一致性,其中包含两个策略:① 事务输入 ② 两次提交策略
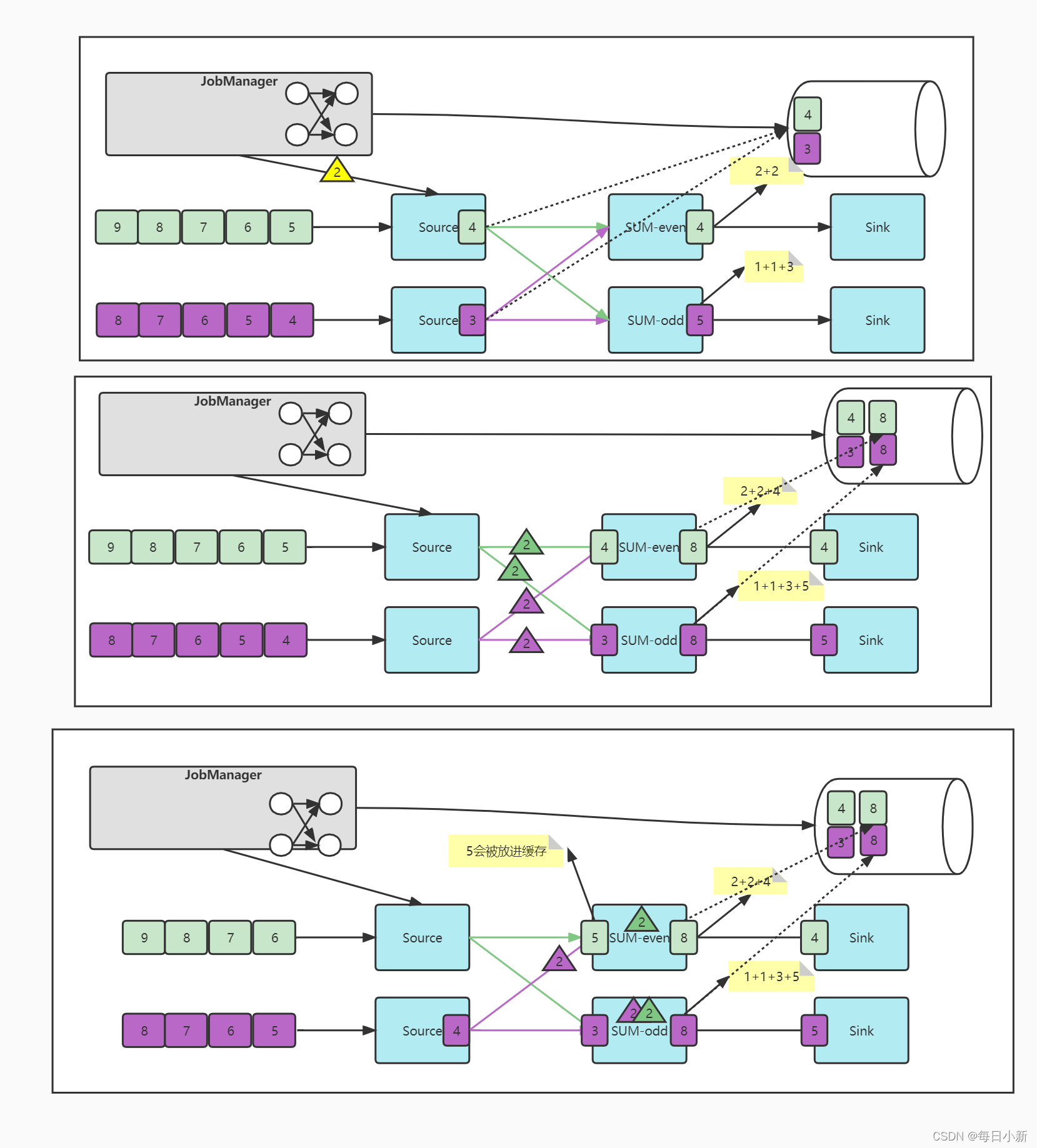
3、并行数据源快照 流程
由图可知两个数据源并行发送数据
流程:
– 图一 、也是JM发送我们的栅栏,当栅栏到达我们的Source时,对状态进行保存,也就是状态4,3.
– 图二、我们的栅栏跟随数据流向算子,算子SUM_even需要接收到Source1的栅栏和Source2的栅栏都接受到后,才能对自己本身状态进行一个保存,如图二,算子状态分别为8,8。
– 图三、表现得是一种特殊情况,就是当我们的Source1的栅栏已经到达算子,但我们的Source2的栅栏处理慢,此时Source1发出数据5,导致数据5到Source2的栅栏前面,一旦算子5处理后在进行保存状态,会导致算子的状态不一致,故此会将数据5放入缓存区中,等我们的算子接收到Source2的栅栏保存完状态后在进行处理数据。(算子与算子之间保存状态不需要等待,在多个数据源的情况下,算子需要等待每个数据源的快照到达,才能对状态保存)
版权归原作者 每日小新 所有, 如有侵权,请联系我们删除。