
文章目录
01 引言
最近因为
DataX
需要集成
impala
,所以有必要学习下
impala
,本文来讲解下。
02 impala概述
2.1 简介
简介:
Impala
是一个
MPP
(大规模并行处理)
SQL
查询引擎:
- 是一个用
C ++和Java编写的开源软件; - 用于处理存储在
Hadoop集群中大量的数据; - 性能最高的
SQL引擎(提供类似RDBMS的体验),提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
优点:
- 使用
impala,用户可以使用传统的SQL知识以极快的速度处理存储在HDFS、HBase和Amazon s3中的数据中的数据,而无需了解Java(MapReduce作业)。 - 由于在数据驻留(在
Hadoop集群上)时执行数据处理,因此在使用Impala时,不需要对存储在Hadoop上的数据进行数据转换和数据移动。
缺点:
- 不提供任何对序列化和反序列化的支持;
- 只能读取文本文件,而不能读取自定义二进制文件;
- 每当新的记录/文件被添加到
HDFS中的数据目录时,该表需要被刷新。
2.2 架构
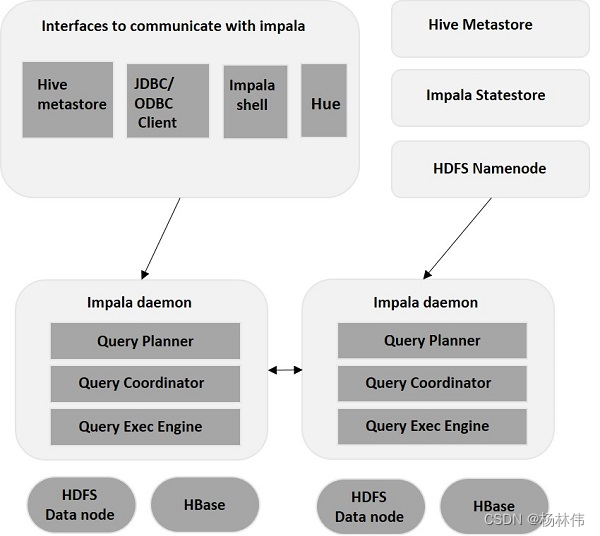
impala
主要由以下三个组件组成:
- Impala daemon(守护进程);
- Impala Statestore(存储状态);
- Impala元数据或metastore(元数据即元存储)。
下面来讲解下。
2.2.1 Impalad(守护进程)
daemon
安装在
Impala
的每个节点上运行,它接受来自各种接口的查询,然后将工作分发到
Impala
集群中的其它
Impala
节点来并行化查询,结果返回到中央协调节。
可以将查询提交到专用Impalad或以负载平衡方式提交到集群中的另一Impalad
2.2.2 Statestore(存储状态)
Statestore
负责检查每个
Impalad
的运行状况,然后经常将每个
Impala Daemon
运行状况中继给其他守护程序,如果由于任何原因导致节点故障的情况下,
Statestore
将更新所有其他节点关于此故障,并且一旦此类通知可用于其他
Impalad
,则其他
Impala
守护程序不会向受影响的节点分配任何进一步的查询。
2.2.3 metadata(元数据)/metastore(元存储)
Impala
使用传统的
MySQL
或
PostgreSQL
数据库来存储表定义和列信息这些元数据。
当表定义或表数据更新时,其它
Impala
后台进程必须通过检索最新元数据来更新其元数据缓存,然后对相关表发出新查询。
03 impala 安装
详细安装方式可以参考:https://www.w3cschool.cn/impala/impala_environment.html
安装方式这里不会详解,大致讲一下流程:
- 下载QuickStartVM
- 下载
cloudera-quickstart-vm-5.5.0-0-virtualbox.ovf文件后,我们需要使用虚拟盒导入 - 然后启动
Impala,打开终端并执行命令:impala-shell
04 impala 接口
**
Impala
提供了三种方式去做查询处理**:
- Impala-shell :命令窗口中键入
impala-shell命令来启动Impala shell; - Hue界面 :您可以使用
Hue浏览器处理Impala查询; - ODBC / JDBC驱动程序 :与其他数据库一样,
Impala提供ODBC / JDBC驱动程序。
在做查询处理之前,很有必要了解
impala
的数据类型:
数据类型描述BIGINT此数据类型存储数值,此数据类型的范围为-9223372036854775808至9223372036854775807.此数据类型在create table和alter table语句中使用BOOLEAN此数据类型只存储true或false值,它用于create table语句的列定义CHAR此数据类型是固定长度的存储,它用空格填充,可以存储最大长度为255DECIMAL此数据类型用于存储十进制值,并在create table和alter table语句中使用DOUBLE此数据类型用于存储正值或负值4.94065645841246544e-324d -1.79769313486231570e + 308范围内的浮点值FLOAT此数据类型用于存储正或负1.40129846432481707e-45 … 3.40282346638528860e + 38范围内的单精度浮点值数据类型INT此数据类型用于存储4字节整数,范围从-2147483648到2147483647SMALLINT此数据类型用于存储2字节整数,范围为-32768到32767STRING这用于存储字符串值TIMESTAMP此数据类型用于表示时间中的点TINYINT此数据类型用于存储1字节整数值,范围为-128到127VARCHAR此数据类型用于存储可变长度字符,最大长度为65,535ARRAY这是一个复杂的数据类型,它用于存储可变数量的有序元素Map这是一个复杂的数据类型,它用于存储可变数量的键值对Struct这是一种复杂的数据类型,用于表示单个项目的多个字段
05 impala 查询处理
5.1 database
创建数据库:
-- 示例:CREATEDATABASEIFNOTEXISTS database_name;
删除数据库:
-- 语法:DROP(DATABASE|SCHEMA)[IFEXISTS] database_name [RESTRICT|CASCADE][LOCATION hdfs_path];-- 示例:DROPDATABASEIFEXISTS sample_database;
选择数据库:
-- 语法:USE db_name;
5.2 table
创建表:
-- 语法:createtableIFNOTEXISTS database_name.table_name (
column1 data_type,
column2 data_type,
column3 data_type,
………
columnN data_type
);-- 示例:CREATETABLEIFNOTEXISTS my_db.student
(name STRING, age INT, contact INT);
插入表:
-- 语法:insertinto table_name (column1, column2, column3,...columnN)values(value1, value2, value3,...valueN);insert overwrite table_name values(value1, value2, value2);-- 示例:insertinto employee (ID,NAME,AGE,ADDRESS,SALARY)VALUES(1,'Ramesh',32,'Ahmedabad',20000);insert overwrite employee values(1,'Ram',26,'Vishakhapatnam',37000);
查询表:
-- 语法:SELECT column1, column2, columnN from table_name;--示例:select name, age from customers;
表描述:
-- 语法:describe table_name;-- 示例:describe customer;
修改表(重命名表案例,其它自行查阅):
-- 语法:ALTERTABLE[old_db_name.]old_table_name RENAMETO[new_db_name.]new_table_name
-- 示例:ALTERTABLE my_db.customers RENAMETO my_db.users;
删除表:
-- 语法:DROPtable database_name.table_name;--示例:droptableifexists my_db.student;
截断表:
-- 语法:truncate table_name;-- 示例:truncate customers;
显示表:
showtables
创建视图:
-- 语法:CreateViewIFNOTEXISTS view_name asSelect statement
-- 示例:CREATEVIEWIFNOTEXISTS customers_view ASselect name, age from customers;
修改视图:
-- 语法ALTERVIEW database_name.view_name为Select语句
-- 示例Alterview customers_view asselect id, name, salary from customers;
删除视图:
-- 语法:DROPVIEW database_name.view_name;-- 示例:Dropview customers_view;
5.3 条件
order by 子句:
--语法select*from table_name ORDERBY col_name [ASC|DESC][NULLS FIRST|NULLS LAST]--示例Select*from customers ORDERBY id asc;
group by 字句:
-- 语法selectdatafrom table_name GroupBY col_name;-- 示例Select name,sum(salary)from customers GroupBY name;
having 子句:
--语法select*from table_name ORDERBY col_name [ASC|DESC][NULLS FIRST|NULLS LAST]-- 示例selectmax(salary)from customers groupby age havingmax(salary)>20000;
limit限制:
-- 语法:select*from table_name orderby id limit numerical_expression;
offset偏移:
-- 示例:select*from customers orderby id limit4offset0;
union聚合:
-- 语法:
query1 union query2;-- 示例:select*from customers orderby id limit3unionselect*from employee orderby id limit3;
with子句:
-- 语法:with x as(select1), y as(select2)(select*from x union y);-- 示例:with t1 as(select*from customers where age>25),
t2 as(select*from employee where age>25)(select*from t1 unionselect*from t2);
distinct去重:
-- 语法:selectdistinctcolumns… from table_name;-- 示例:selectdistinct id, name, age, salary from customers;
06 文末
本文主要讲解了
impala
的一些概念以及查询处理方式,谢谢大家的阅读,本文完!
版权归原作者 杨林伟 所有, 如有侵权,请联系我们删除。