
Hello 大家好,我是一名新来的金融领域打工人,日常分享一些python知识,都是自己在学习生活中遇到的一些问题,分享给大家,希望对大家有一定的帮助!
相信很多小伙伴在使用python的使用会用来爬取一些网站上常见的数据,在做金融分析的时候如果没有数据的话我们可以去网上爬取,那么今天我要介绍的一个最近学到的爬虫神器—Postman。
它具体有什么功能呢?我们下面来慢慢你介绍:
Postman是一个接口测试工具,在做接口测试的时候,Postman相当于一个客户端,它可以模拟用户发起的各类HTTP请求,将请求数据发送至服务端,获取对应的响应结果, 从而验证响应中的结果数据是否和预期值相匹配;并确保开发人员能够及时处理接口中的bug,进而保证产品上线之后的稳定性和安全性。它主要是用来模拟各种HTTP请求的(如:get/post/delete/put..等等),Postman与浏览器的区别在于有的浏览器不能输出Json格式,而Postman更直观接口返回的结果。——来源百度百科
作为一个接口测试工具,如何运用到python爬虫中去呢?让我们一步一步来看:
1.首先需要在电脑下载安装Postman客户端
下载链接就是Postman的官网的下载链接,我把链接附在下面:Postman下载安装链接

下载好之后,直接双击安装就行,什么都不用做。
2.注册一个Postman账号,然后打开Postman

3.进入我们想要爬取的网页页面,找到想要爬取的内容
这里我们试着爬取一个旅游网站的景点名:
网址:厦门旅游景点推荐-2022厦门旅游必去景点-排名,网红,好玩-去哪儿攻略 (qunar.com)
比如说我们想要爬取页面中的景点的名字,比如:鼓浪屿、曾厝垵、 环岛路等等
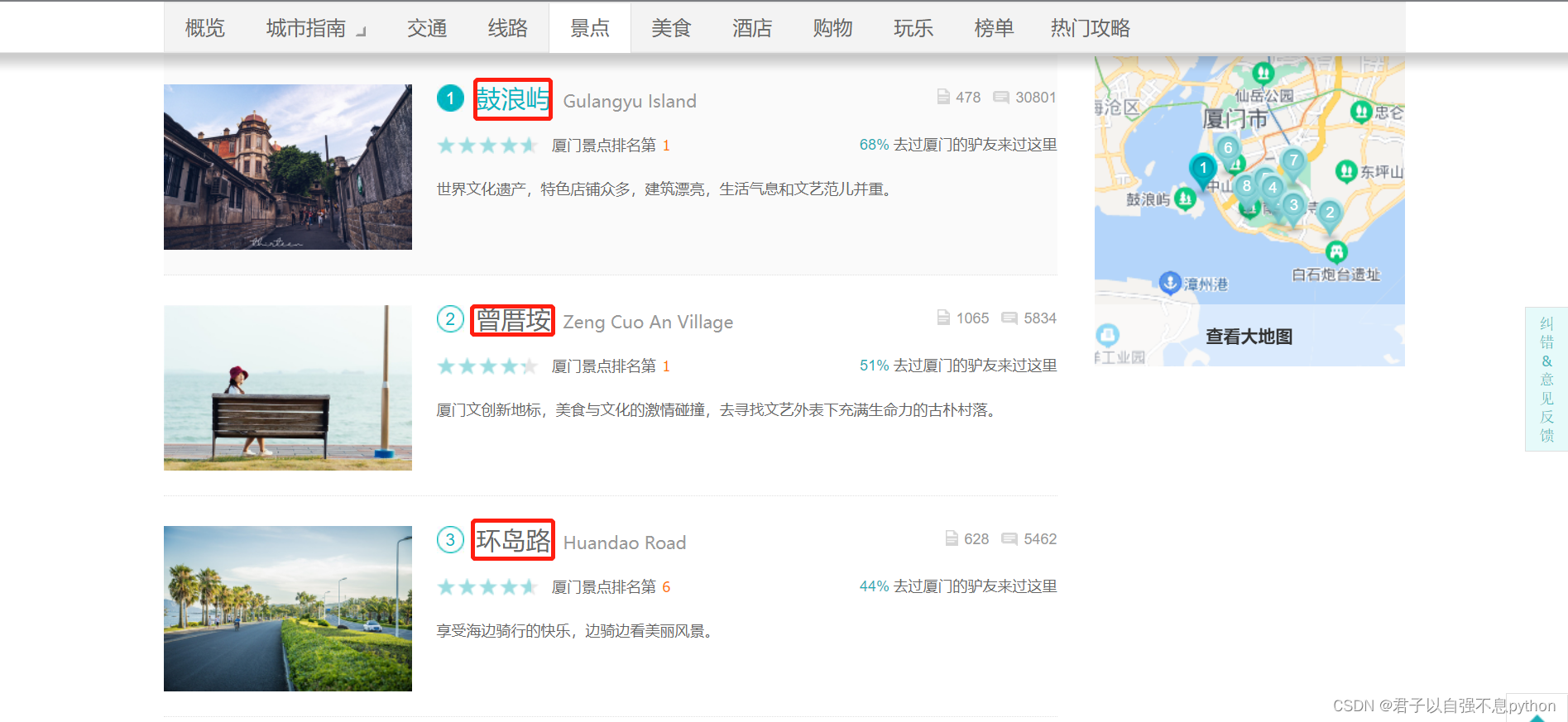
4.在页面中鼠标右键选择“检查”或者打开浏览器的“开发人员工具”
在上述操作后我们进入如下的页面:

我们将目光聚焦在右半侧,这时候我们需要“刷新”一下页面,得到如下结果,点击红色框选的内容:
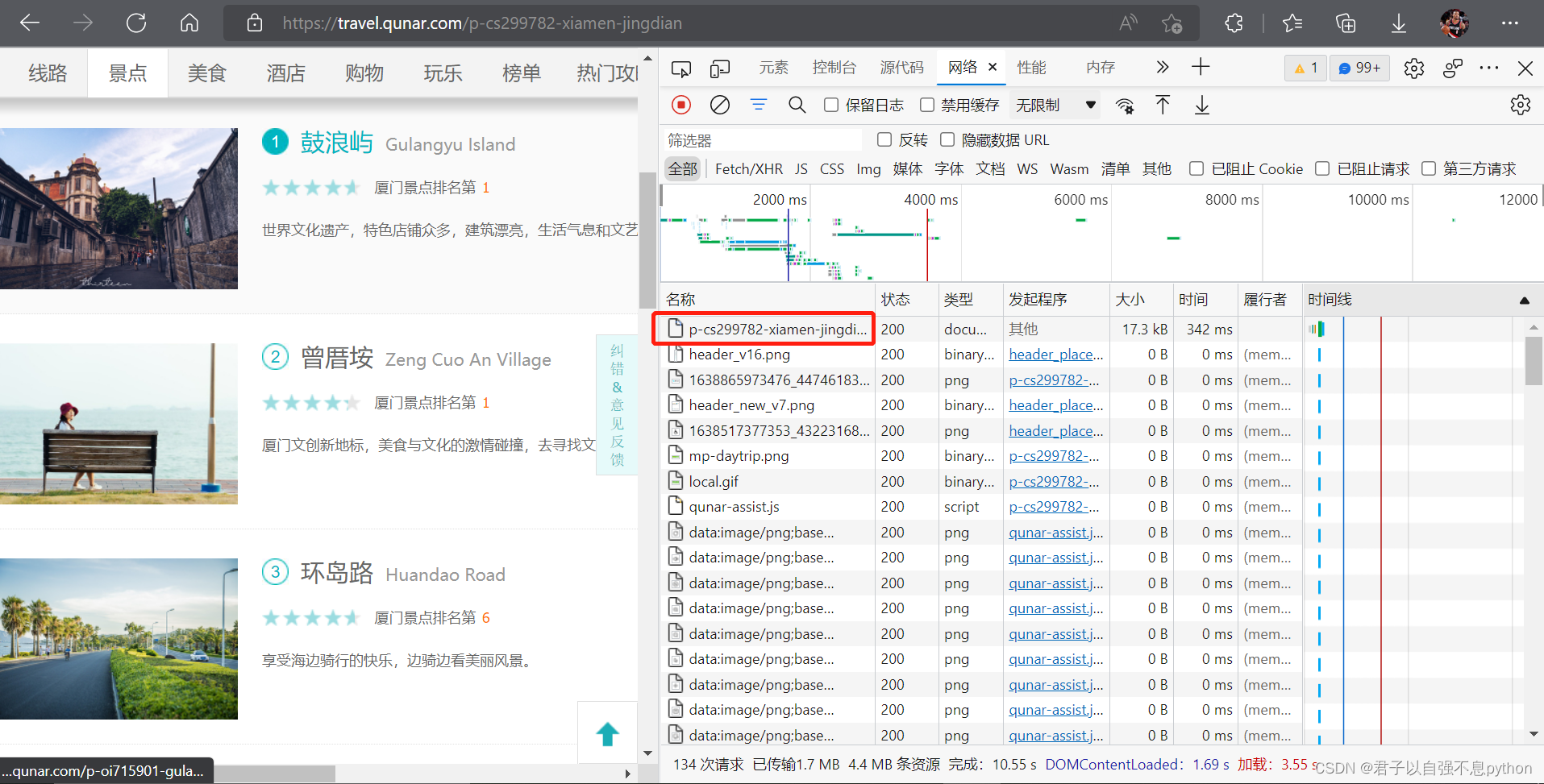
我们点击红色框选的内容得到如下结果:
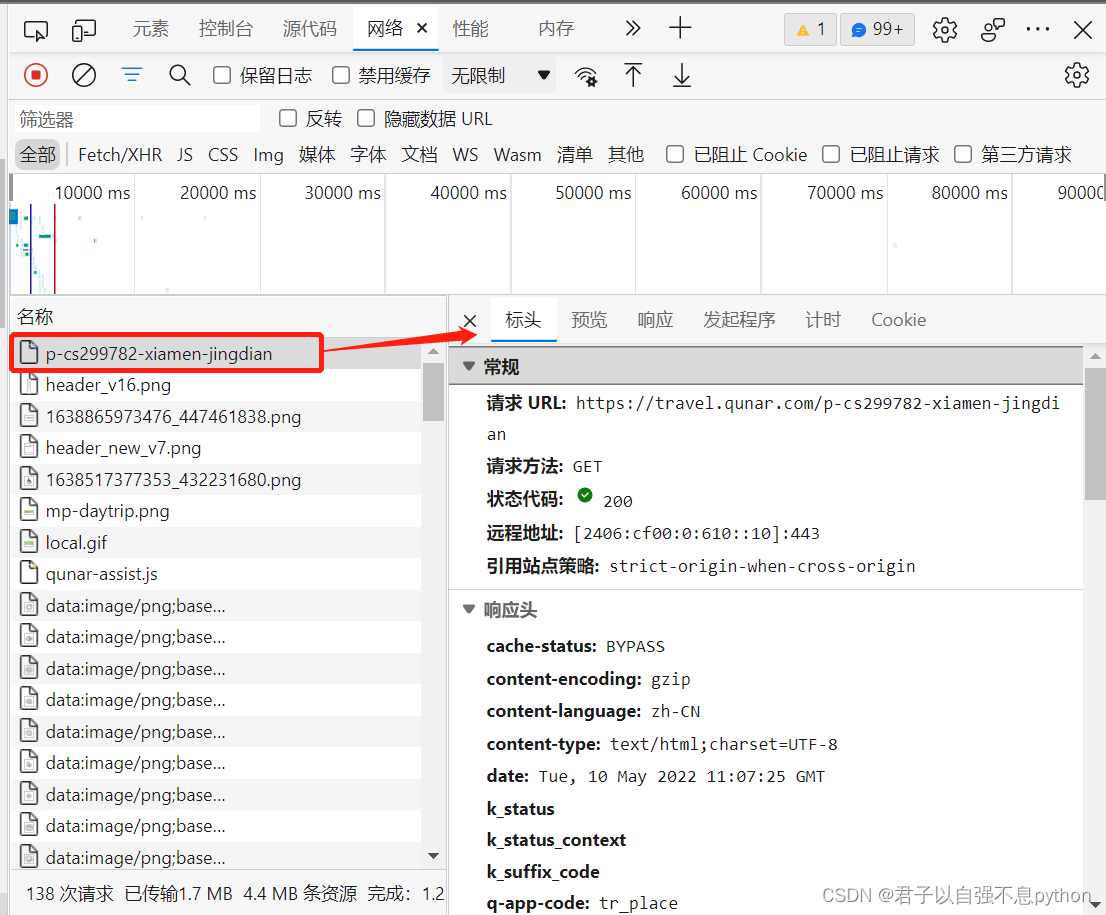
我们可以选择“预览”,并且在里面查询是否存在我们想要爬取的内容,比如说“鼓浪屿”:
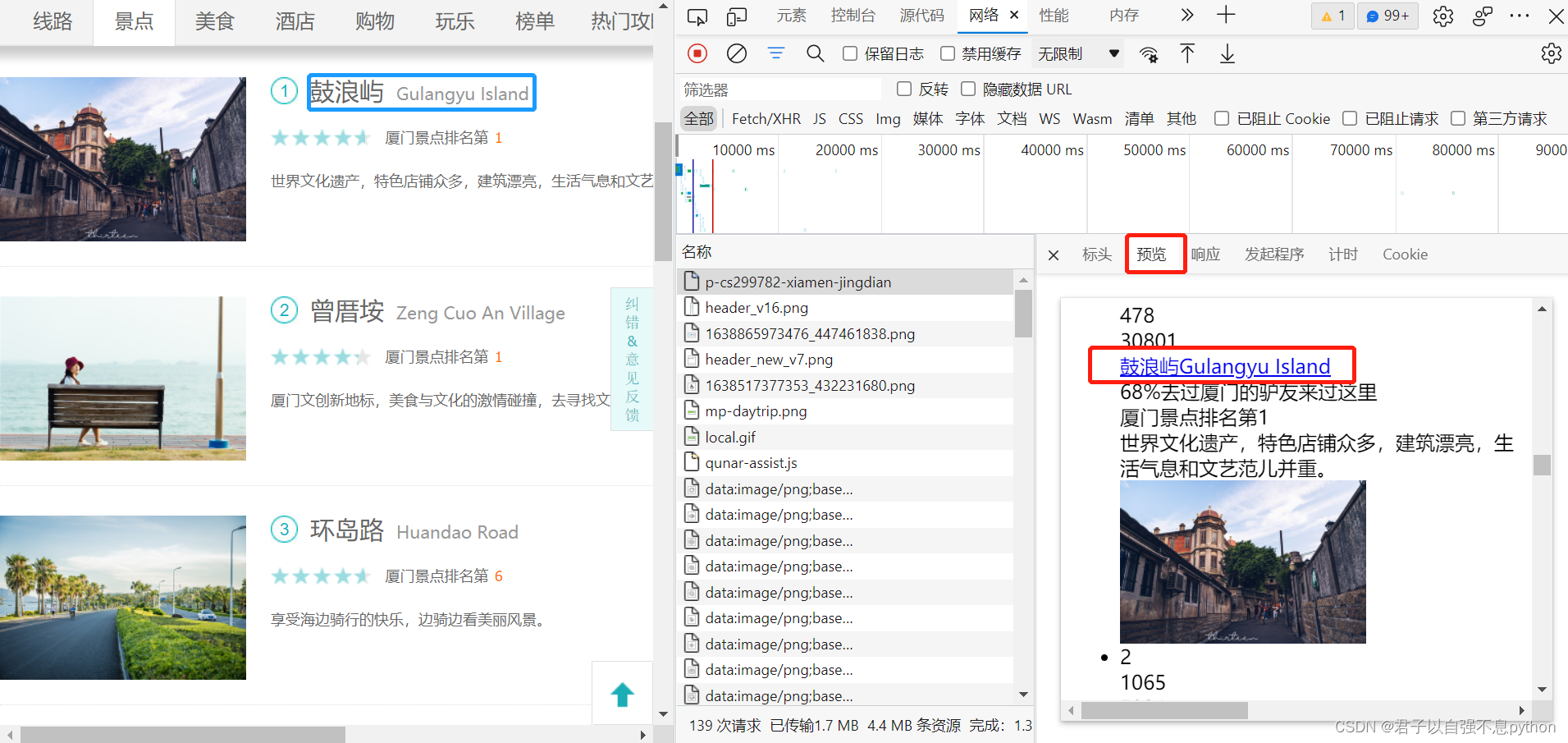
很明显可以看出,“预览”中存在我们想要的内容,并且可以和左侧的内容对应上 。
接下来我们鼠标选到如下内容,然后右键,选择复制为**cURL(bash)**:
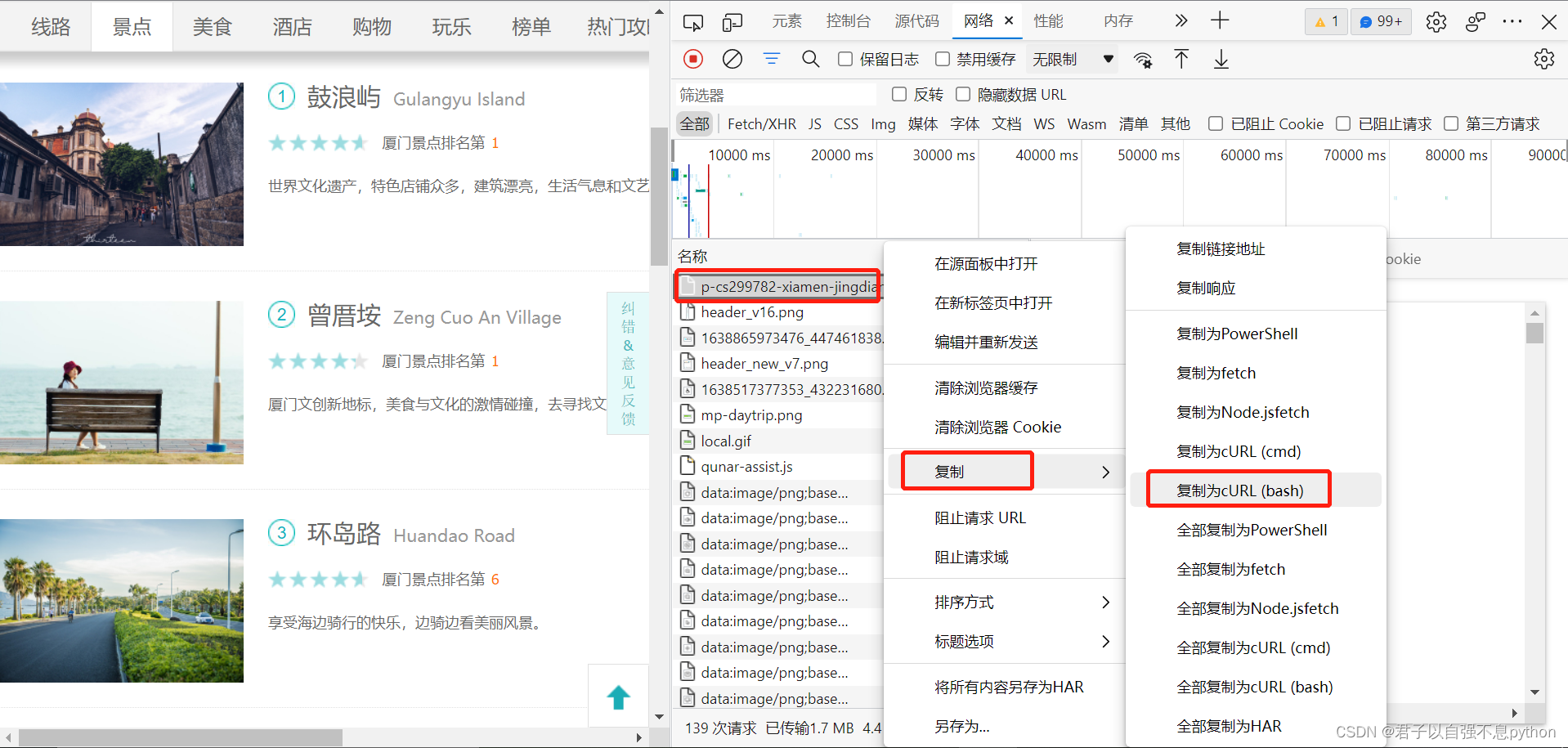
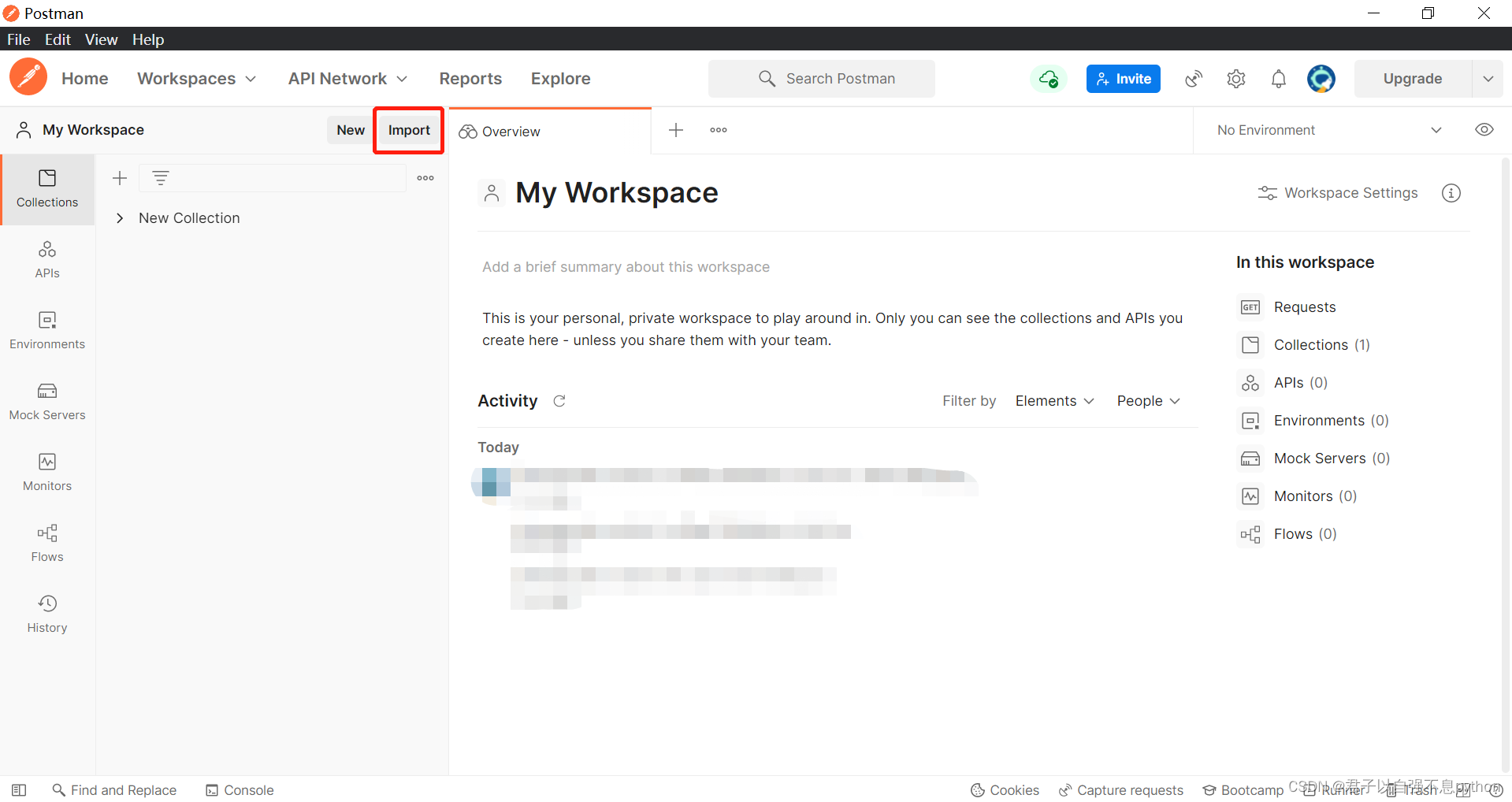
5.进入Postman,将复制的内容加载进去
我们在Postman中选择import,然后选择Raw text,将我们复制的内容粘贴进去:
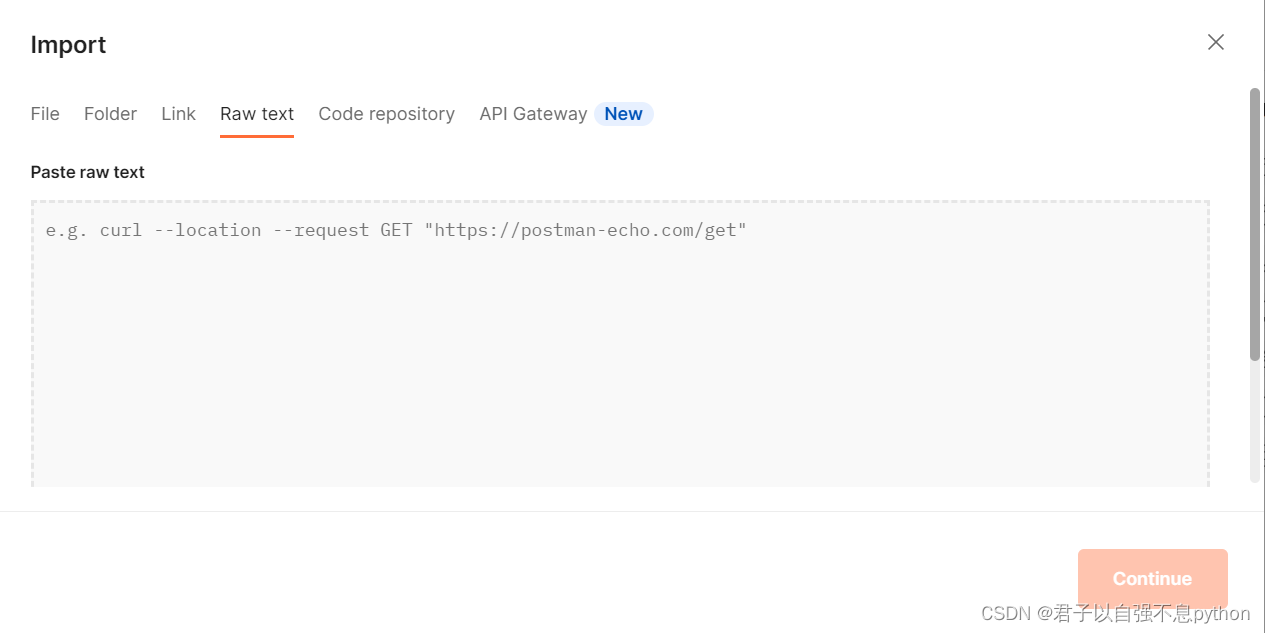
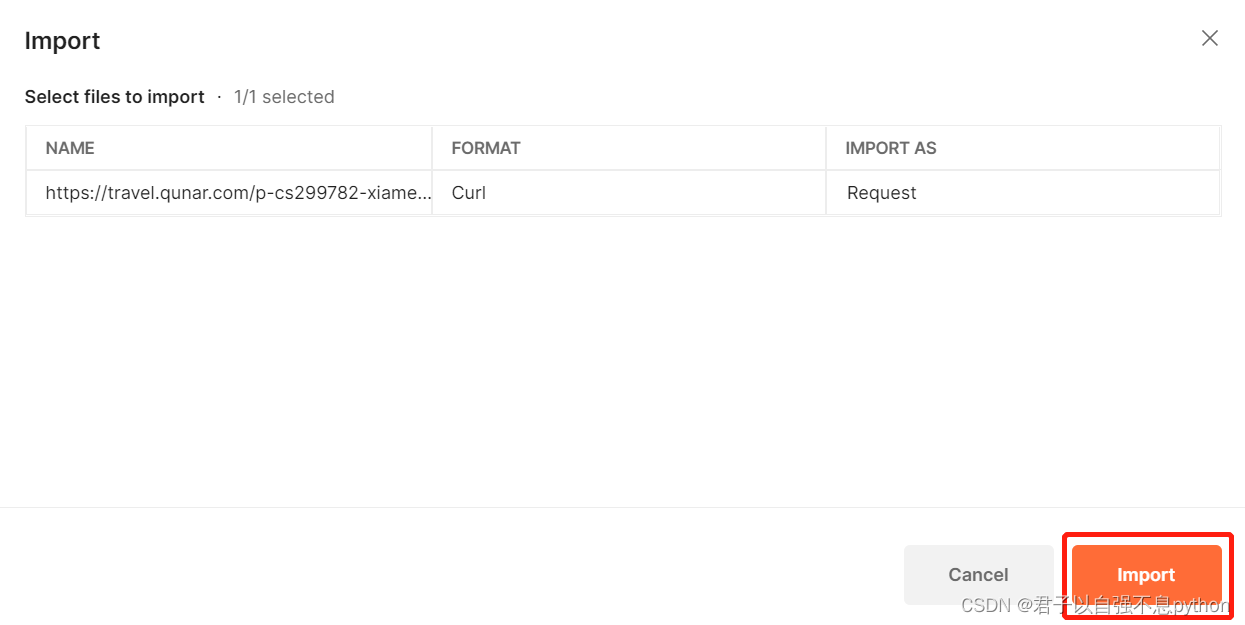
粘贴复制的内容,并点击Continue,下一步点击Import:

6.通过Postman发送请求
在完成上一步的Import后我们进入如下页面,这时候我们点击Send:

点击Send后我们相当于通过Postman向服务器发送了请求,并且服务器返回给了我们HTML格式的内容如下:

这个返回给我们的HTML格式文档其实就是我们爬取的页面的页面源代码,我们可以从下图得到验证:

7.通过Postman生成python爬虫代码
我们点击右上角的这个按钮:
得到如下页面,其中我们选择Python - Requests,之后我们将右侧代码复制,粘贴到python文件中:
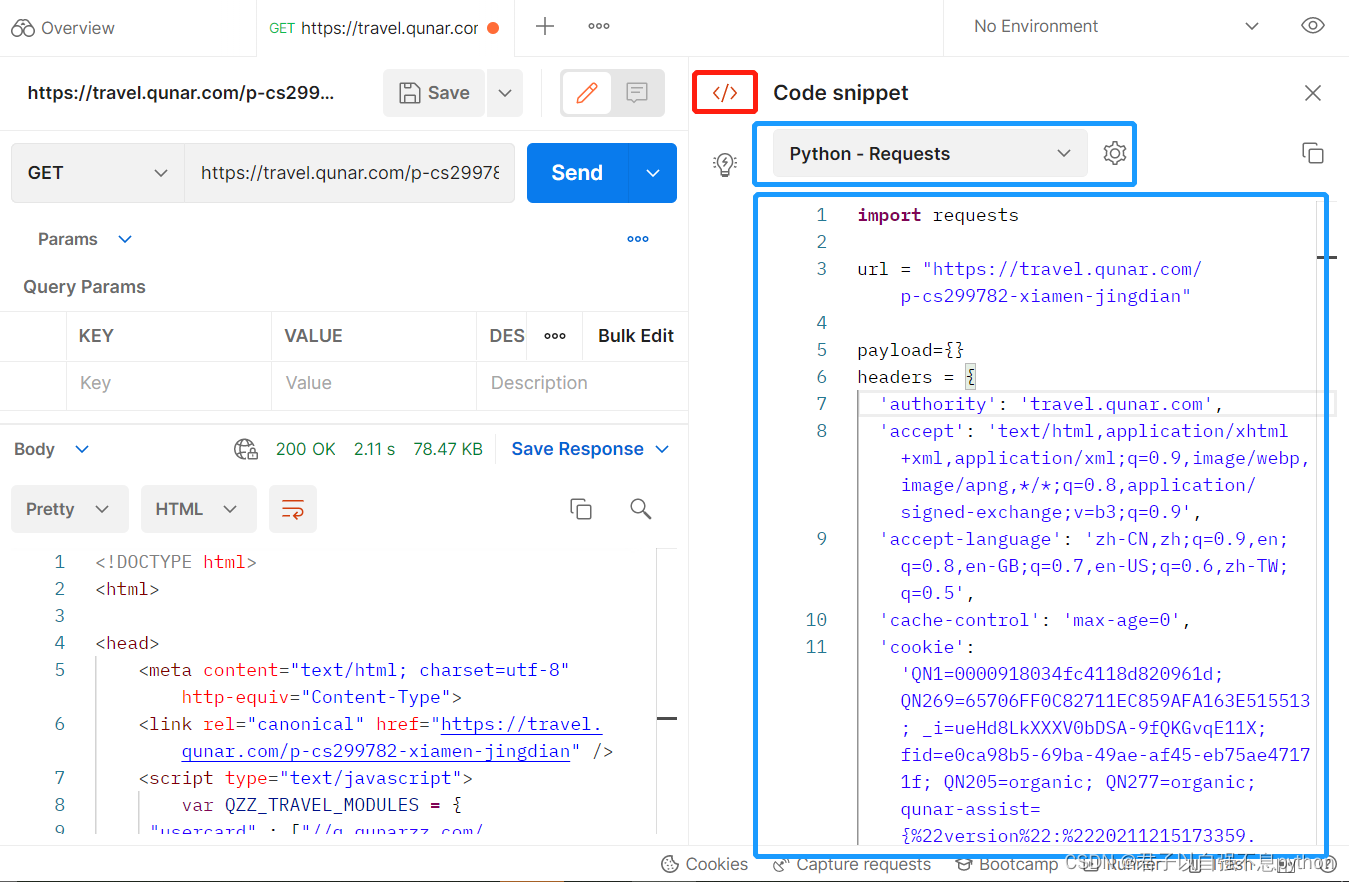 得到的python代码如下:
得到的python代码如下:
## postman工具的使用
import requests
url = "https://travel.qunar.com/p-cs299782-xiamen-jingdian"
payload={}
headers = {
'authority': 'travel.qunar.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,zh-TW;q=0.5',
'cache-control': 'max-age=0',
'cookie': 'QN1=0000918034fc4118d820961d; QN269=65706FF0C82711EC859AFA163E515513; _i=ueHd8LkXXXV0bDSA-9fQKGvqE11X; fid=e0ca98b5-69ba-49ae-af45-eb75ae47171f; viewdist=299782-6; uld=1-299782-6-1652167178; JSESSIONID=07447CB2149341056CEBB815F1EDF0F6; qunar-assist={%22version%22:%2220211215173359.925%22%2C%22show%22:false%2C%22audio%22:false%2C%22speed%22:%22middle%22%2C%22zomm%22:1%2C%22cursor%22:false%2C%22pointer%22:false%2C%22bigtext%22:false%2C%22overead%22:false%2C%22readscreen%22:false%2C%22theme%22:%22default%22}; QN205=organic; QN277=organic; QN267=08897278013e594d4; csrfToken=pG8P5YxlawgK4xLy5gqboMfjzc3PL8f6; ariaDefaultTheme=undefined; _vi=ZVM5OVJRff5-WqKRSR8z-1-5wsxUZFKe3HjjzY36FjM2dAB9Kid_TTlErMLyxiV_LRIKgmGxb1f112lFh2V3k5KmcOWUWaXPhZABjEAJYERJXu6lED-BVDqGdxMi6Cpadvxt5kTHWmL-GrSJVgDkNAHwEu1STc_ZoDyrwh6qiywq; Hm_lvt_c56a2b5278263aa647778d304009eafc=1651283208,1651290050,1651291263,1652167180; Hm_lpvt_c56a2b5278263aa647778d304009eafc=1652167180; QN271=749e150b-d9b2-49a3-960a-7fa27373fbfb; SECKEY_ABVK=LG1DqJApvTrEf9k99/qQFt4OsSw6VpB+noTf6BSInqQ%3D; BMAP_SECKEY=H2dLlEk7yFbg2TroK6omHBgP0C5Z8rMsdadN13glWW_rmOYweLnZ20x1TWwCuwF_fS_aLBiPAVFI2Eh4KJKMatp-gktEUhpMzj_VFo_15mVV-TTyqV2tV6Q-rw6Fe0Y4fTbjUCcMrevzr_y8nlhxtFjgLVgD9kStuYoAs3HtEVcZwevbYDQHNfSSiMcsyq-D; JSESSIONID=A5E2B3B84C33240FFD867ABCE81BB2AA; uld=1-299782-7-1652167254; viewdist=299782-7',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="101", "Microsoft Edge";v="101"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36 Edg/101.0.1210.39'
}
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)
我们打印一下结果如下,这样我们就得到最后爬取下来的结果,如果我们后面要继续获得景点名称的话,我们就在如今得到的HTML结果的基础上采用Xpath、正则表达式、Beautiful Soup等等工具进行查找即可,这个内容我们后面再讲:

今天的文章就分享到这里啦!
版权归原作者 君子以自强不息python 所有, 如有侵权,请联系我们删除。