
Kafka概述
kafka是一个多分区、多副本且基于zookeeper协调的分布式消息系统。也是一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。
目 前企 业中比 较常 见的 消息 队列产 品主 要有 Kafka、ActiveMQ 、RabbitMQ 、RocketMQ 等。
在大数据场景主要采用 Kafka 作为消息队列。在 JavaEE 开发中主要采用 ActiveMQ、RabbitMQ、RocketMQ。
官网地址:https://kafka.apache.org/
应用场景:
1)缓存消峰
2)解耦
3)异步通信
消息队列类型:
1)点对点模式
2)发布/订阅模式(Topic队列)
Kafka 基础架构
kafka的基础架构图如下所示,它的broker对应的是服务器,由broker构成kafka集群,每个broker内可以包含多个消息队列(图中以生产环境中常用的Topic为例),每个topic又可以划分多个分区,存放于不同的broker上,每个分区又可以包括副本,即每个分区有leader和follower,leader提供服务,follower只在leader挂了时转为leader用,平时只同步数据。对应topic 的分区,为了提高消息的消费速度,消费者也可以由消费者构成消费者组,组内每个消费者对应消费一个topic 分区的数据。Zookeeper用于辅助记录分区的leader,帮助leader选举和切换等,Kafka2.8.0之后,Zookeeper不是必须的。
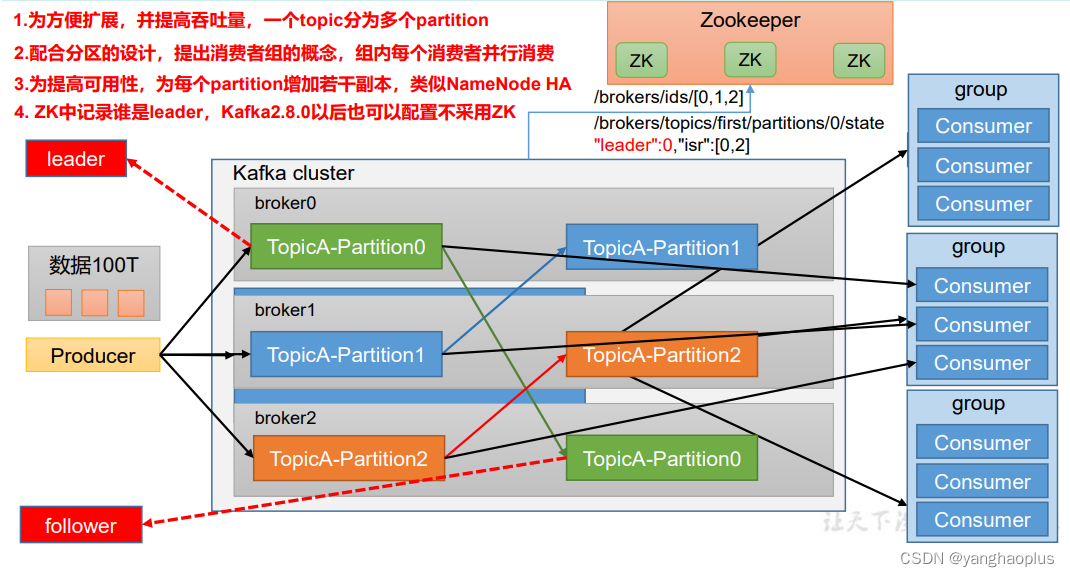
上诉架构中每个组件的详细解释如下:
(1)Producer:消息生产者,就是向 Kafka broker 发消息的客户端。
(2)Consumer:消息消费者,向 Kafka broker 取消息的客户端。
(3)Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消
费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不
影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
(4)Broker:一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个
broker 可以容纳多个 topic。
(5)Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。
(6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服
务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
(7)Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个
Follower。
(8)Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数
据的对象都是 Leader。
(9)Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和
Leader 数据的同步。Leader 发生故障时,某个 Follower 会成为新的 Leader。
生产者消息发送流程
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。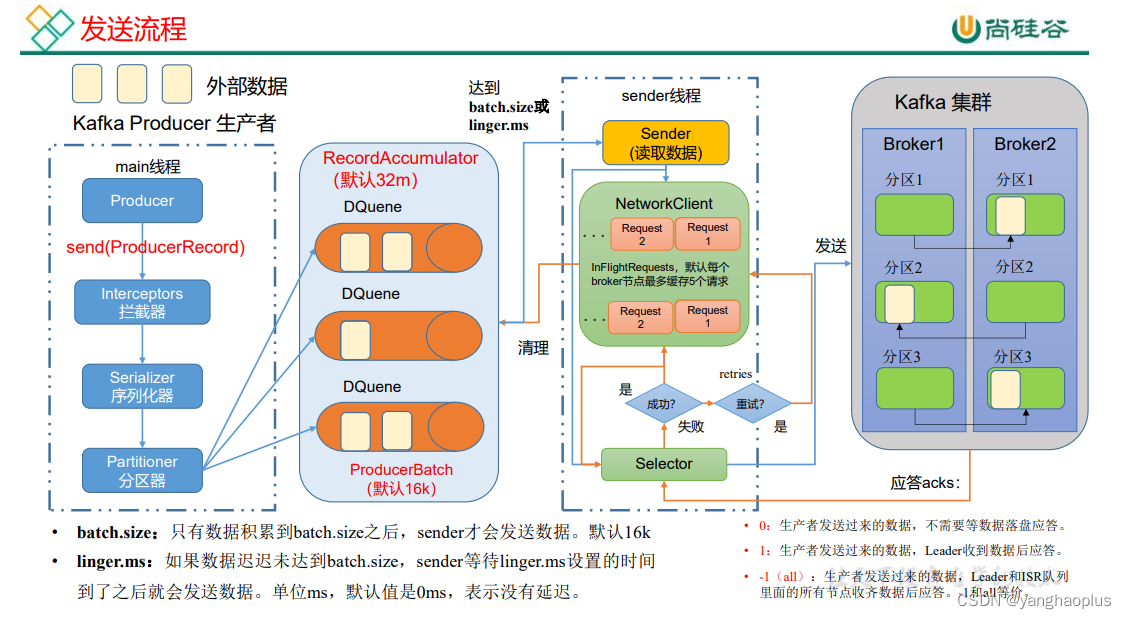
比较关键的点:
序列化器:JDK自带的序列化方式比较笨重,所以一般自己指定序列化方式。
拦截器:一般对应Flume中的拦截器。
分区器:决定消息发送到队列的哪个分区,可以通过实现Patitioner接口自定义分区方式。
内存池:消息发送时会先累计到一个内存池中,即RecordAccumulator,默认大小32M,有几个消息队列里面就有几个双端队列,一一对应。
Sender发送时机:当数据达到阈值,如累计了16KB或者过来多少时间,就由sender线程读取数据,通过NIO的方式发送到Kafka集群中。
保证消息发送到:通过应答机制确认消息是否到达:acks设置为0,表示不需要应答直接发送,高效但不可靠;acks设置为1,每次由leader应答,一般可靠,适用于重要度不高的日志信息;acks设置为-1或者all,代表需要由leader和isr里所有副本应答,保证可靠。
kafka如何对producer保证数据可靠:每个partition都给配上副本,做数据同步,保证数据不丢失。
kafka的副本同步策略:和zookeeper不同的是,Kafka选择的是全部完成同步,才发送ack。但是又有所区别。这里的完全同步是阉割版的,仅仅针对ISR内的副本完全同步,ISR动态调整,是一种对性能和可靠性的平衡。
1、AR(Assigned Repllicas)一个partition的所有副本(就是replica,不区分leader或follower)
2、ISR(In-Sync Replicas)能够和 leader 保持同步的 follower + leader本身 组成的集合。
3、OSR(Out-Sync Relipcas)不能和 leader 保持同步的 follower 集合
4、公式:AR = ISR + OSR
参考博客:Kafka之ISR机制的理解
生产者发送消息示例
1、pom文件导入
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency></dependencies>
2、具体代码如下
importorg.apache.kafka.clients.producer.KafkaProducer;importorg.apache.kafka.clients.producer.ProducerRecord;importjava.util.Properties;publicclassCustomProducer{publicstaticvoidmain(String[] args)throwsInterruptedException{// 1. 创建 kafka 生产者的配置对象Properties properties =newProperties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");//hadoop102:9092是对应的Kafka端口// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 3. 创建 kafka 生产者对象KafkaProducer<String,String> kafkaProducer =newKafkaProducer<String,String>(properties);// 4 调用 send 方法,发送消息//4.1 无回调函数的发送for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first","hello"+ i));}//4.2 带有回调函数的发送for(int i =0; i <5; i++){// 添加回调
kafkaProducer.send(newProducerRecord<>("first","hello"+ i),newCallback(){// 该方法在 Producer 收到 ack 时调用,为异步调用@OverridepublicvoidonCompletion(RecordMetadata metadata,Exception exception){if(exception ==null){// 没有异常,输出信息到控制台System.out.println(" 主题: "+ metadata.topic()+"->"+"分区:"+ metadata.partition());}else{// 出现异常打印
exception.printStackTrace();}}});// 延迟一会会看到数据发往不同分区Thread.sleep(2);}//4.3 同步发送for(int i =0; i <5; i++){
kafkaProducer.send(newProducerRecord<>("first","hello"+ i)).get();}// 5. 关闭资源
kafkaProducer.close();}}
分区的好处
(1)便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
(2)提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
生产者如何提高吞吐量
• batch.size:批次大小,默认16k
• linger.ms:等待时间,修改为5-100ms
• compression.type:压缩snappy
• RecordAccumulator:缓冲区大小,修改为64m
可靠性总结
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等;
- acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低; 在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据, 对可靠性要求比较高的场景。
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
• 最多一次(At Most Once)= ACK级别设置为0
• 总结:
At Least Once可以保证数据不丢失,但是不能保证数据不重复;
At Most Once可以保证数据不重复,但是不能保证数据不丢失。
幂等性问题
acks: -1(all):生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答。可能出现重复发送问题,即副本从leader处同步后,且应答前,leader挂了,新上任的leader是之前已发送过数据的副本,导致再次发送。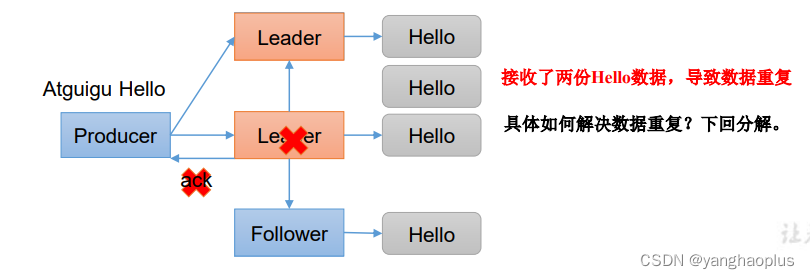
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2) 。
幂等性默认开启,可以通过生产者配置项 enable.idempotence 关闭。
幂等性的工作原理很简单,每条消息都有一个「主键」,这个主键由 <PID, Partition, SeqNumber> 组成,他们分别是:
PID:ProducerID,每个生产者启动时,Kafka 都会给它分配一个 ID,ProducerID 是生产者的唯一标识,需要注意的是,Kafka 重启也会重新分配 PID
Partition:消息需要发往的分区号
SeqNumber:生产者,他会记录自己所发送的消息,给他们分配一个自增的 ID,这个 ID 就是 SeqNumber,是该消息的唯一标识
对于主键相同的数据,Kafka 是不会重复持久化的,它只会接收一条,但由于是原理的限制,幂等性也只能保证单分区、单会话内的数据不重复,如果 Kafka 挂掉,重新给生产者分配了 PID,还是有可能产生重复的数据,这就需要另一个特性来保证了——Kafka 事务。
Kafka 事务
Kafka 事务基于幂等性实现,通过事务机制,Kafka 可以实现对多个 Topic 、多个 Partition 的原子性的写入,即处于同一个事务内的所有消息,最终结果是要么全部写成功,要么全部写失败。
Kafka 事务分为生产者事务和消费者事务,但它们并不是强绑定的关系,消费者主要依赖自身对事务进行控制,因此这里我们主要讨论的是生产者事务。
面试官:Kafka 事务是如何工作的?
生产者乱序问题
同类设置类似滑动窗口的方式来保证不同分区间数据的有序。
待更新
版权归原作者 yanghaoplus 所有, 如有侵权,请联系我们删除。