
⭐️写在前面
这里是温文艾尔の源码学习之路- 👍如果对你有帮助,给博主一个免费的点赞以示鼓励把QAQ
- 👋博客主页🎉 温文艾尔の学习小屋
- ⭐️更多文章👨🎓请关注温文艾尔主页
- 🍅文章发布日期:2021.12.16
- 👋java学习之路!
- 🔎更多文章请关注个人主页!
- 🔎热门文章一览:
- 🍅【源码那些事】超详细的ArrayList底层源码+经典面试题
- 🍅HashMap底层红黑树原理(超详细图解)+手写红黑树代码
- 🍅HashMap底层源码解析上(超详细图解+面试题)
- 🍅HashMap底层源码解析下(超详细图解)

文章目录
⭐️1 LinkedList的继承体系图
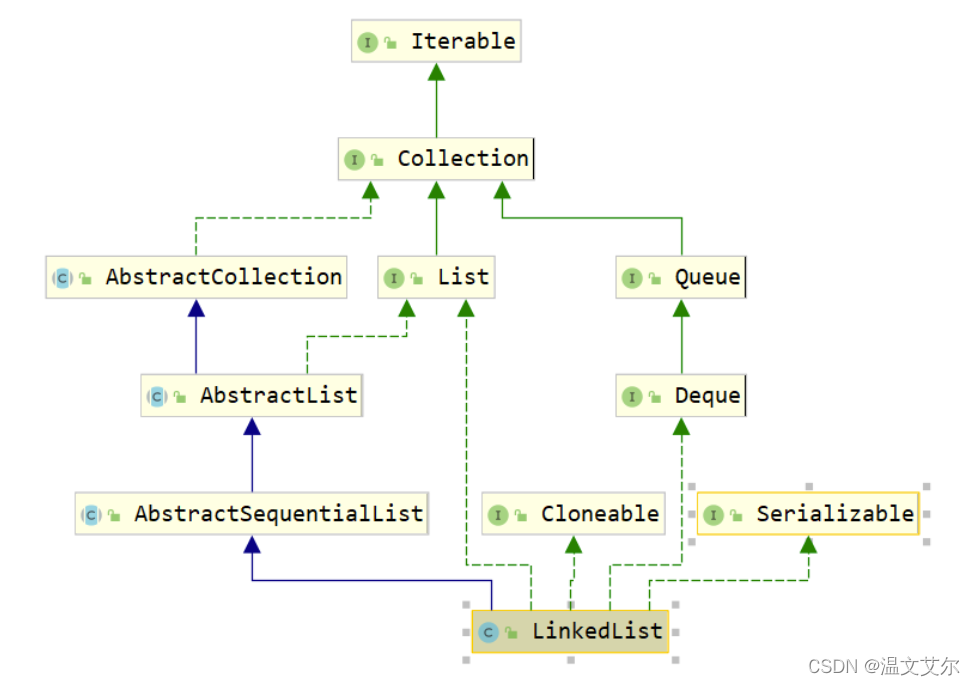
从继承体系上可以看到
-LinkedList实现了Queue和Deque接口,所以他可以作为List来使用,也可以作为双端队列来使用,甚至可以作为
- 栈来使用
-LinkedList实现了Cloneable和Serializable接口,由此可得LinkedList可以被克隆与序列化
⭐️2 LinkedList源码分析
⭐️2.1 LinkedList的主要属性
//size:链表中元素的数量transientint size =0;//first:链表中的头节点transientNode<E> first;//last:链表中的尾节点transientNode<E> last;
transient:
**在不需要序列化的属性前添加关键字
transient
,序列化对象的时候,这个属性就不会序列化到指定的目的地中
所以size,first,last均不会被序列化**

⭐️2.2 LinkedList源码
⭐️2.2.1 LinkedList构造方法
无参构造
publicLinkedList(){}
有参构造
//传入Collection集合并把Collection集合中的元素添加到LinkedList集合中 publicLinkedList(Collection<?extendsE> c){this();addAll(c);}publicbooleanaddAll(Collection<?extendsE> c){returnaddAll(size, c);}publicbooleanaddAll(int index,Collection<?extendsE> c){//检查index是否越界checkPositionIndex(index);//将集合转成Object[]数组Object[] a = c.toArray();//获得数组长度,记录为numNewint numNew = a.length;//数组长度为0,则证明无可添加元素if(numNew ==0)returnfalse;//pred为要拼接的集合的前驱节点指针,succ为要拼接集合的后继节点指针Node<E> pred, succ;//如果要插入位置的索引位于链表末尾if(index == size){//集合c的后继为空
succ =null;//集合c的前驱为原链表的尾节点
pred = last;}else{//node(index)为index索引处的节点,要插入集合的后继指向它
succ =node(index);//要插入集合的前驱节点指向index所处节点的前一个节点
pred = succ.prev;}//开始插入for(Object o : a){@SuppressWarnings("unchecked")E e =(E) o;//创建新节点,新节点的前驱指向index所处节点的前驱Node<E> newNode =newNode<>(pred, e,null);//如果为空则证明,要插入的节点位于链表的首部if(pred ==null)//首指针指向新节点
first = newNode;else//否则pred的后继指向新节点
pred.next = newNode;//pred向后移动
pred = newNode;}//如果succ==null,说明index处于链表尾部,直接在尾部添加集合if(succ ==null){//尾指针指向拼接完成的链表的尾部
last = pred;}else{//否则,要插入集合尾部的后继为succ
pred.next = succ;//succ的前驱指向插入集合的尾部
succ.prev = pred;}//链表容量+要插入集合的长度
size += numNew;//链表修改次数+1
modCount++;returntrue;}
⭐️2.2.2 添加元素的方法
LinkedList作为一个双端队列,既可以从队列首部添加元素,也可以从队列尾部添加元素
⭐️在队首添加元素
publicvoidaddFirst(E e){//调用linkFirst方法,将e元素插到linkedlist首部linkFirst(e);}privatevoidlinkFirst(E e){//f记录队列首节点finalNode<E> f = first;//创建新节点,使新节点的next为原队列首节点,新节点的prev为空finalNode<E> newNode =newNode<>(null, e, f);//新节点作为新的首节点,首指针指向新节点
first = newNode;//判断链表是否为空//如果为空则尾指针last指向新节点//否则将原队列首节点的prev指向新节点if(f ==null)
last = newNode;else
f.prev = newNode;//链表容量+1
size++;//链表被修改次数+1,说明这是一个支持fail-fast的集合
modCount++;}
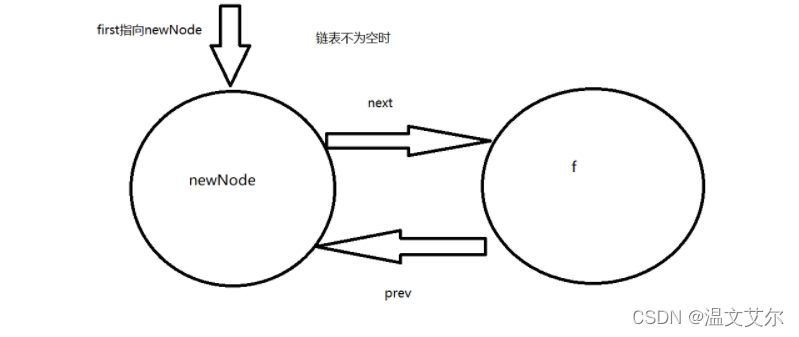
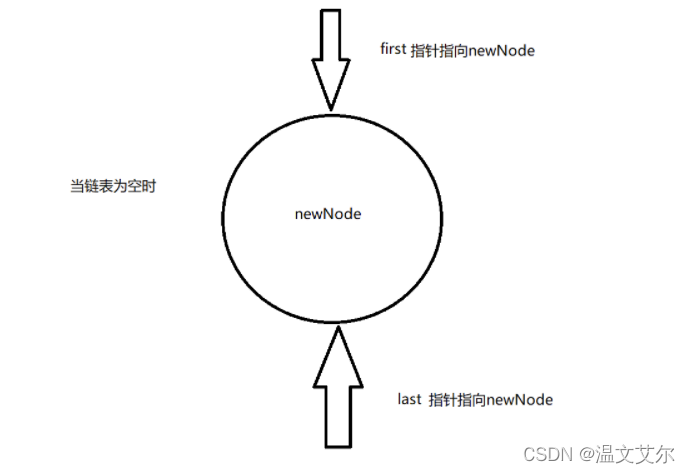

⭐️在队尾添加元素
publicvoidaddLast(E e){//调用linkLast方法,将e元素插到linkedlist尾部linkLast(e);}voidlinkLast(E e){//l记录队列尾节点finalNode<E> l = last;//创建新节点,新节点的prev为原队列尾节点,新节点的next为空finalNode<E> newNode =newNode<>(l, e,null);//新节点作为新的尾节点,尾指针指向新节点
last = newNode;//判断链表中是否有元素节点//如果为空则新节点为队列第一个元素//那么头指针也指向新节点if(l ==null)
first = newNode;else//如果链表不为空,原来的最后一个节点的next指向新节点,使新节点加入链表
l.next = newNode;//链表容量+1
size++;//链表被修改的次数+1,说明这是一个支持fail-fast的集合
modCount++;}
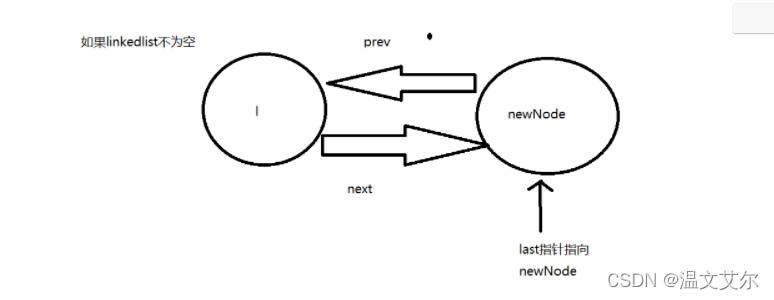
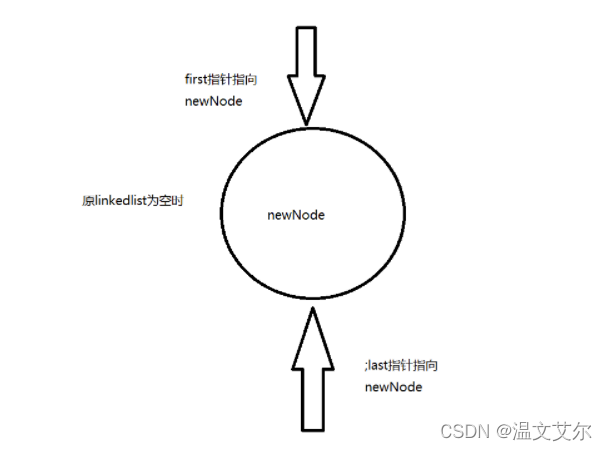
⭐️指定元素位置添加元素
publicvoidadd(int index,E element){//检查index是否越界checkPositionIndex(index);//判断index是不是尾部位置if(index == size)//如果index是尾部位置,则直接将他插入到尾节点之后linkLast(element);else//否则在中间位置,调用linkBefore,在中间位置插入结点//node(index)为当前要插入位置的节点linkBefore(element,node(index));}//根据index寻找index位置上的Node节点Node<E>node(int index){//size>>1=size/2,如果index<size/2,则证明节点在链表的前半部分if(index <(size >>1)){//从头节点开始定位index元素的位置Node<E> x = first;for(int i =0; i < index; i++)
x = x.next;//没有到达index之前,指针一直向后移动return x;//到达index位置,将该位置的node节点返回}else{//否则从尾节点开始查找index元素Node<E> x = last;for(int i = size -1; i > index; i--)
x = x.prev;//没有到达index之前,指针一直向前移动return x;//到达index位置,将该位置的node节点返回}}//e为要插入节点,succ为原位置节点voidlinkBefore(E e,Node<E> succ){//找到原位置节点的前一个节点,标记为predfinalNode<E> pred = succ.prev;//创建根据e新节点,新节点的prev为原位置节点的前一个节点,新节点的next为原位置节点finalNode<E> newNode =newNode<>(pred, e, succ);//原位置节点的前置指针prev指向新节点
succ.prev = newNode;//如果succ为链表的第一个元素if(pred ==null)//那么first指针指向新节点,新节点作为链表头节点
first = newNode;else//否则pred的next为新节点
pred.next = newNode;//链表容量+1
size++;//链表被修改次数+1
modCount++;}

⭐️添加元素的三种方法图示
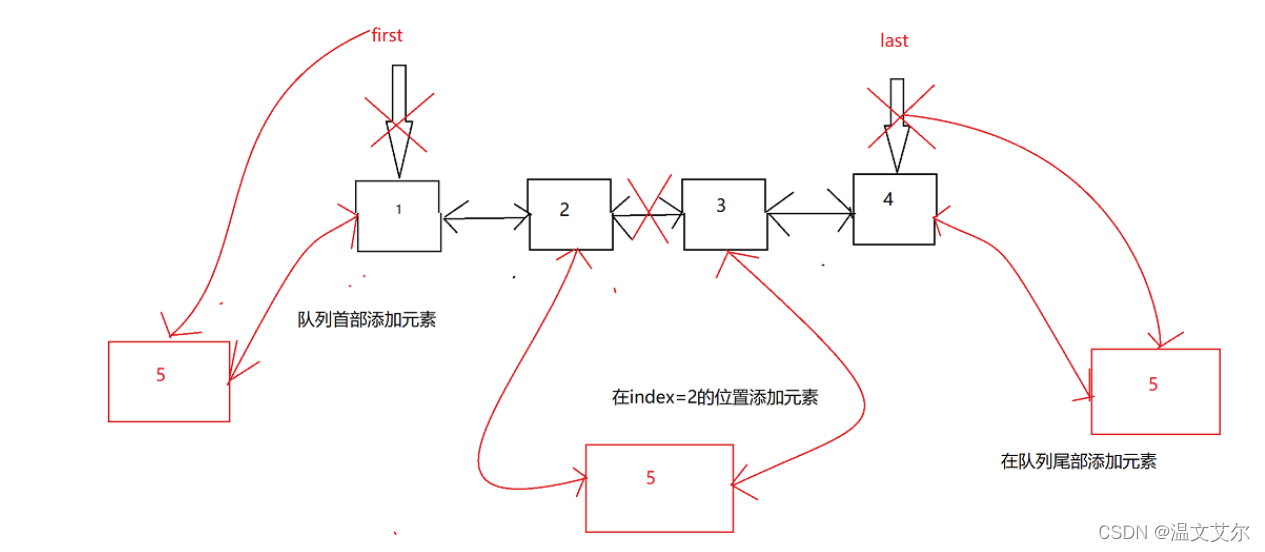
可以看到,在
队列首尾添加元素很高效
,时间复杂度为
O(1)
在
中间添加元素效率很低
,需要先找到插入位置的节点,再修改前后指针,时间复杂度为O(n)
⭐️2.2.3 删除元素
我们上面讲到,LinkedList实现了Queue和Deque接口,所以他可以作为List来使用,也可以作为双端队列来使用,那么作为双端队列,他可以从队列首部删除元素,也可以从队列尾部删除元素,而作为List,他也可以从中间删除元素
⭐️从首部删除元素
publicEremoveFirst(){//获取首节点finalNode<E> f = first;//如果首节点为空,则链表为空,抛出NoSuchElementException()异常if(f ==null)thrownewNoSuchElementException();//否则删除首部元素returnunlinkFirst(f);}privateEunlinkFirst(Node<E> f){// assert f == first && f != null;//获取首部节点的值,用来返回finalE element = f.item;//获得首节点的后继节点finalNode<E> next = f.next;//将首节点的值置空
f.item =null;//将首节点的后继置空
f.next =null;// 置空的目的是方便GC进行垃圾回收//将首节点的后继作为新的首节点
first = next;//删除之后如果链表为空if(next ==null)//则把last也置为空
last =null;else//将next的前驱置为空
next.prev =null;//链表的容量-1
size--;//链表的修改次数+1
modCount++;//将被删除元素返回return element;}
⭐️从尾部删除元素
publicEremoveLast(){//获取尾节点finalNode<E> l = last;//链表为空则抛出异常if(l ==null)thrownewNoSuchElementException();//否则删除尾部元素returnunlinkLast(l);}privateEunlinkLast(Node<E> l){//获取尾节点的值finalE element = l.item;//获取尾节点的前驱finalNode<E> prev = l.prev;//将尾节点的值置为空
l.item =null;//将尾节点的前驱置为空
l.prev =null;//垃圾回收//尾节点的前驱作为新的尾节点
last = prev;//如果尾节点的前驱为空,则链表为空,将first置为空if(prev ==null)
first =null;else//否则prev的后继置为空
prev.next =null;//链表的容量-1
size--;//链表被修改的次数+1
modCount++;//将被删除的尾节点返回return element;}
⭐️删除指定下标节点
publicEremove(int index){//检查索引是否越界,越界则抛出IndexOutOfBoundsException异常checkElementIndex(index);//node(index)为要删除的节点returnunlink(node(index));}//根据index寻找index位置上的Node节点Node<E>node(int index){//size>>1=size/2,如果index<size/2,则证明节点在链表的前半部分if(index <(size >>1)){//从头节点开始定位index元素的位置Node<E> x = first;for(int i =0; i < index; i++)
x = x.next;//没有到达index之前,指针一直向后移动return x;//到达index位置,将该位置的node节点返回}else{//否则从尾节点开始查找index元素Node<E> x = last;for(int i = size -1; i > index; i--)
x = x.prev;//没有到达index之前,指针一直向前移动return x;//到达index位置,将该位置的node节点返回}}Eunlink(Node<E> x){//获得要删除节点(x)的值finalE element = x.item;//获得x的后继节点finalNode<E> next = x.next;//获得x的前驱节点finalNode<E> prev = x.prev;//如果前驱为空,则x为首节点,则将x的后继作为新的首节点if(prev ==null){
first = next;}else{//则前驱的next指向x的后继
prev.next = next;//将x的前驱置空
x.prev =null;}//如果后继为空,则x为尾节点,将x的前驱作为新的尾节点if(next ==null){
last = prev;}else{//否则将后继的prev指向x的前驱
next.prev = prev;//x的后继置为空
x.next =null;}//经过上面两个步骤,x的前驱后继均为空,将x的值置为空,便于GC垃圾回收
x.item =null;//链表的容量-1
size--;//链表被修改的次数+1
modCount++;//将被删除的元素返回return element;}
⭐️删除元素的三种方法图示
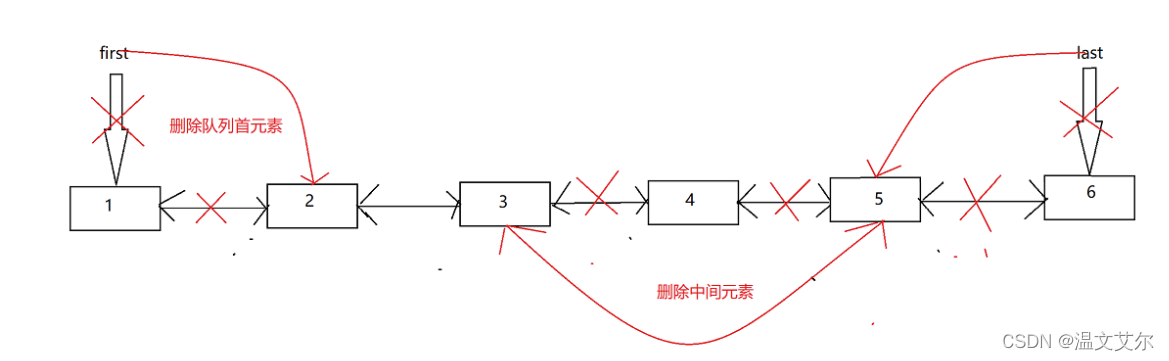
由此我们可以得知
- 删除元素时,在队列首尾删除元素很高效,时间复杂度为
O(1) - 在
中间删除元素比较低效,首先要站到删除位置的节点,再修改前后指针,时间复杂度为O(n)
⭐️3 总结
-LinkedList是一个以双链表实现的List;
-LinkedList还是一个双端队列,具有队列、双端队列、栈的特性;
-LinkedList在队列首尾添加、删除元素非常高效,时间复杂度为O(1);
-LinkedList在中间添加、删除元素比较低效,时间复杂度为O(n);
-LinkedList不支持随机访问,所以访问非队列首尾的元素比较低效;
-LinkedList在功能上等于ArrayList+ArrayDeque;
这里是温文艾尔の源码学习之路- 👍如果对你有帮助,给博主一个免费的点赞以示鼓励把QAQ
- 👋博客主页🎉 温文艾尔の学习小屋
- ⭐️更多文章👨🎓请关注温文艾尔主页
- 🍅文章发布日期:2021.12.16
- 👋java学习之路!
- 🔎更多文章请关注个人主页!
- 🔎热门文章一览:
- 🍅【源码那些事】超详细的ArrayList底层源码+经典面试题
- 🍅HashMap底层红黑树原理(超详细图解)+手写红黑树代码
- 🍅HashMap底层源码解析上(超详细图解+面试题)
- 🍅HashMap底层源码解析下(超详细图解)

本文转载自: https://blog.csdn.net/wenwenaier/article/details/122106215
版权归原作者 温文艾尔 所有, 如有侵权,请联系我们删除。
版权归原作者 温文艾尔 所有, 如有侵权,请联系我们删除。