
ideal—Spark
新建工程
新建maven工程,添加scala
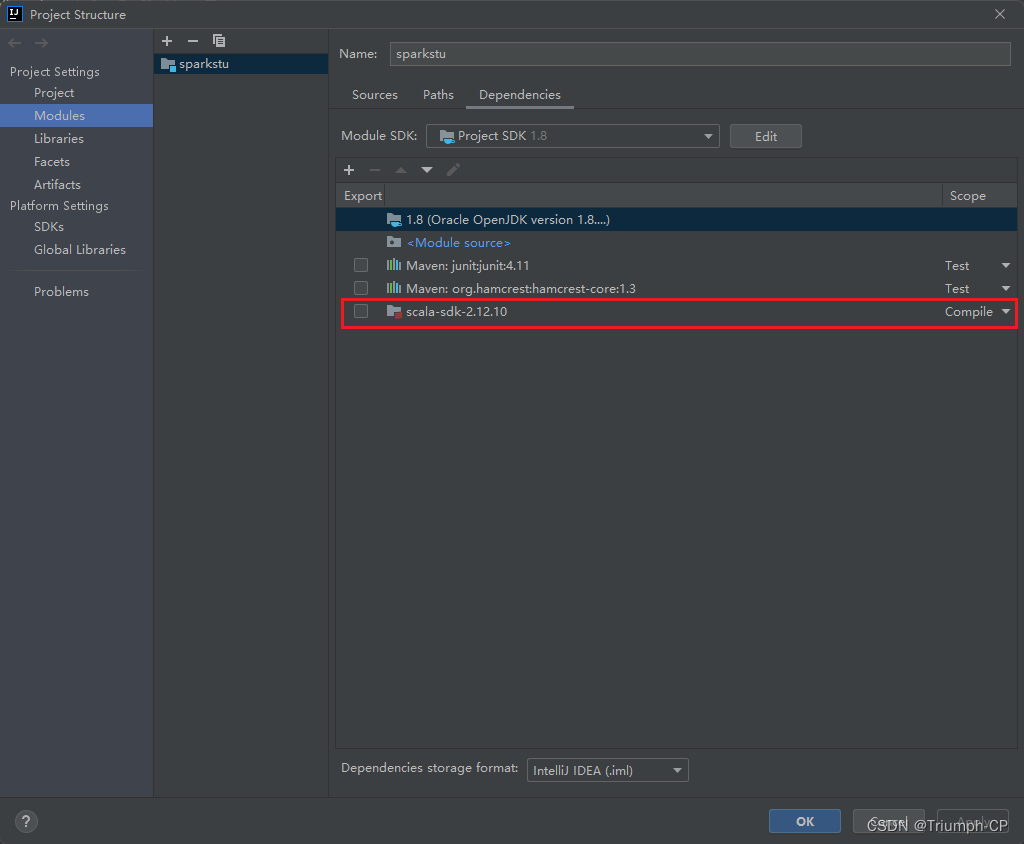
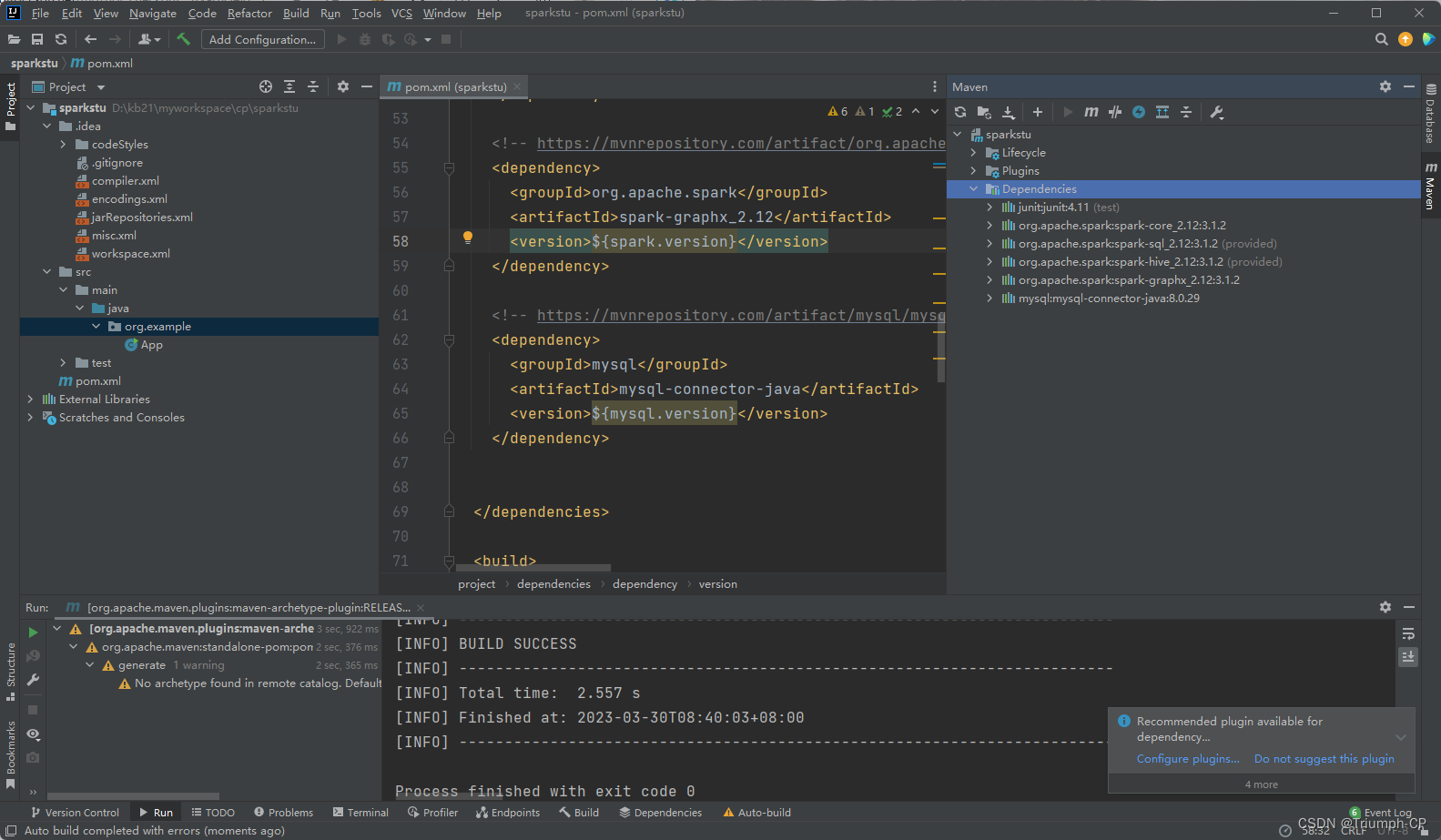
添加依赖
去官网查询依赖
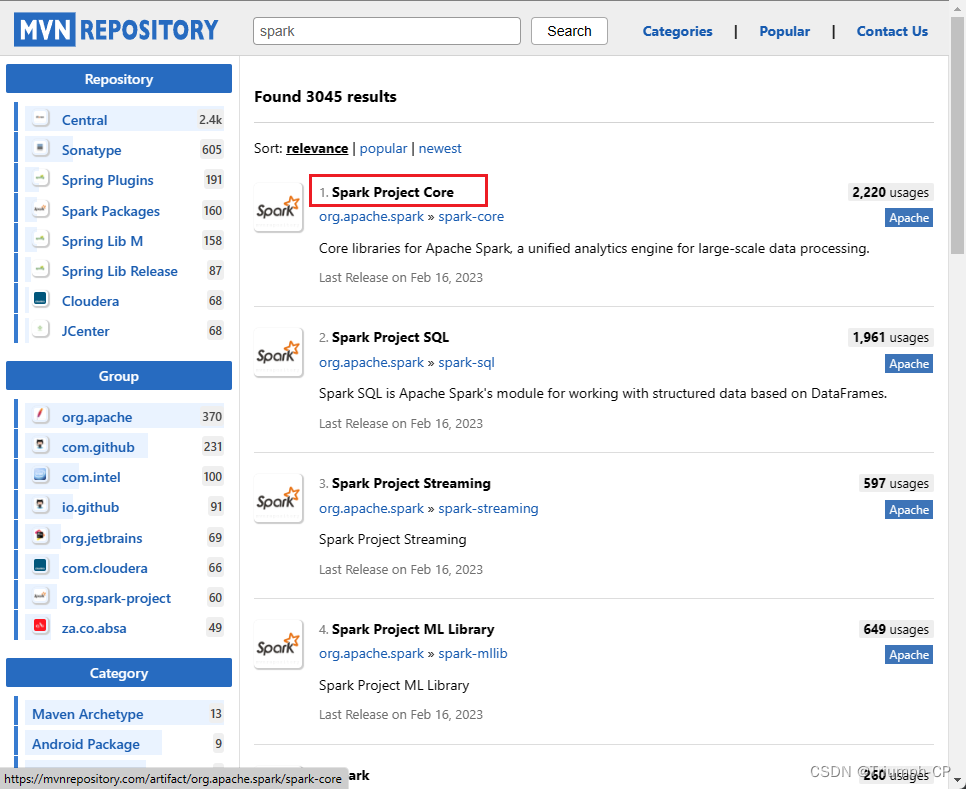
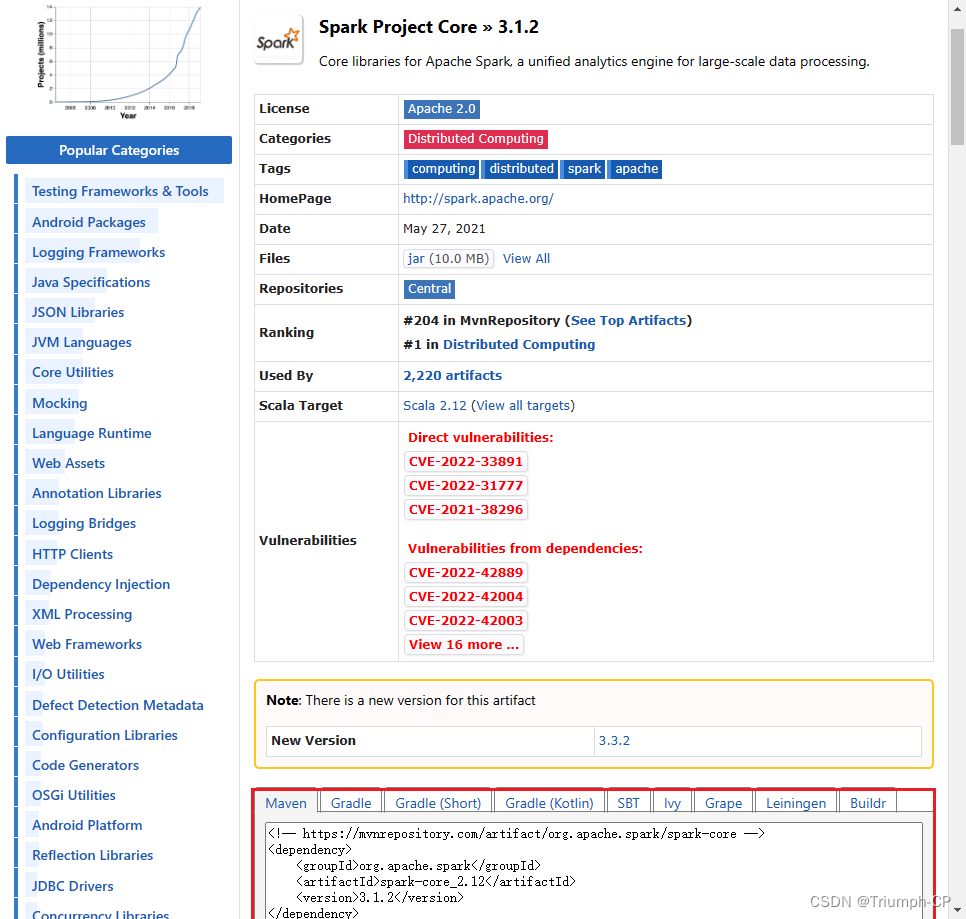
pom添加依赖并下载 spark-core
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.2</version></dependency>
重复步骤下载spark-sql
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.1.2</version><scope>provided</scope></dependency>
spark-hive
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.1.2</version><scope>provided</scope></dependency>
spark-graphx
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-graphx --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-graphx_2.12</artifactId><version>3.1.2</version></dependency>
mysql-connector-java
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.29</version></dependency>
安装完成
新建SparkDemo的scala object
sc对象
object SparkDemo{
def main(args:Array[String]):Unit={
val conf:SparkConf=newSparkConf().setMaster("local[*]").setAppName("sparkDemo")
val sc:SparkContext=SparkContext.getOrCreate(conf)println(sc)}}
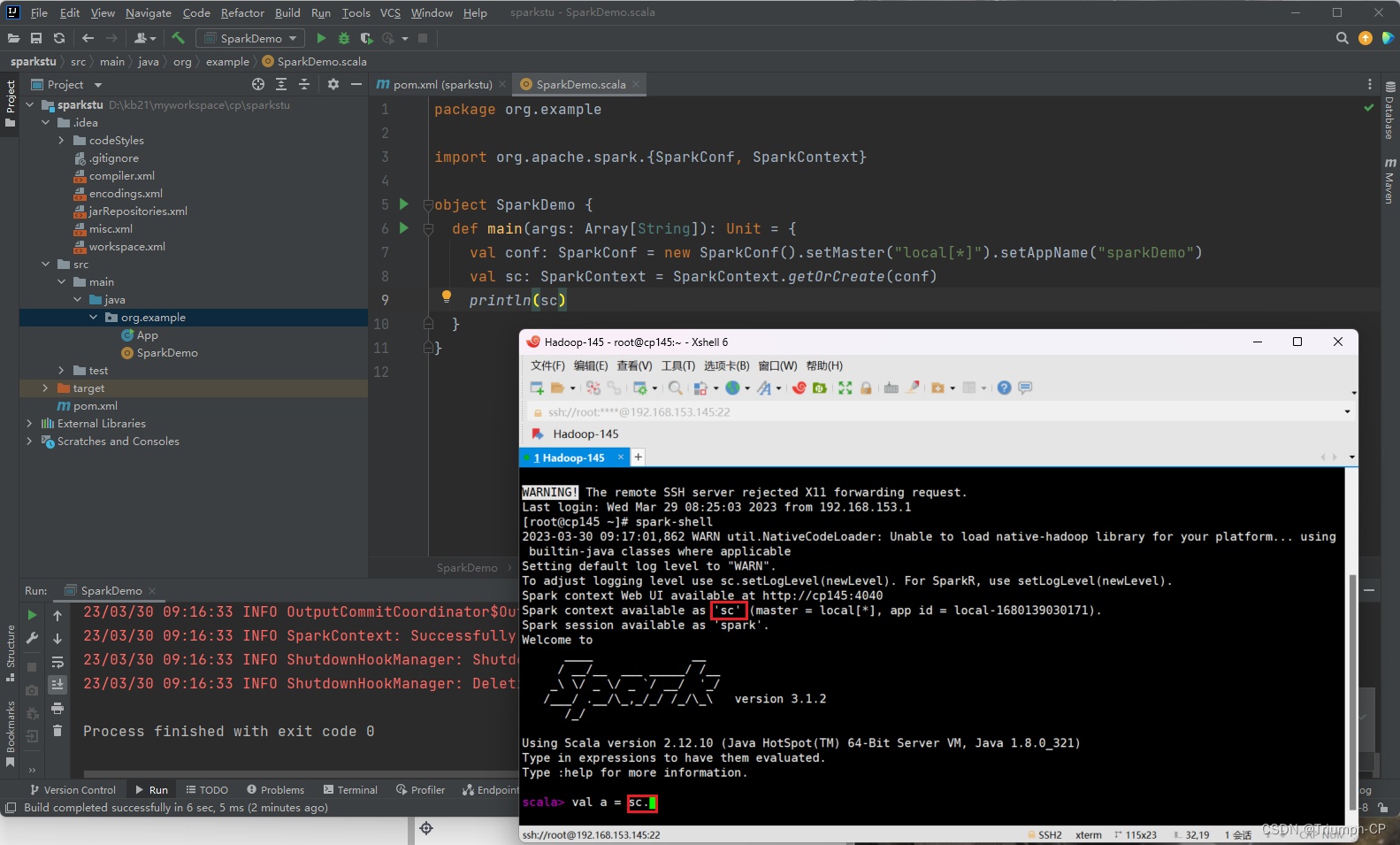
去除红色的字段,去
D:\environment\server\apache-maven-3.6.1\repository\org\apache\spark\spark-core_2.12\3.1.2\spark-core_2.12-3.1.2.jar!\org\apache\spark\log4j-defaults.properties
将-defaults删除,然后将
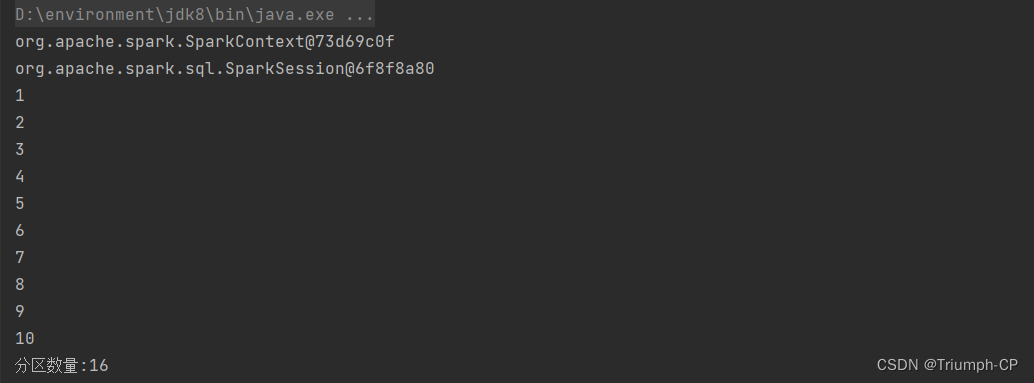
val spark:SparkSession=SparkSession.builder().master("local[*]").appName("SparkSessionDemo").getOrCreate()println(spark)
val rdd: RDD[Int]= sc.parallelize(1to10)
rdd.collect().foreach(println)
val pNum:Int= rdd.getNumPartitions
println("分区数量:"+ pNum)
可能会出现报错,参考这位老哥的解决办法
Exception in thread “main“ java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$——红目香薰
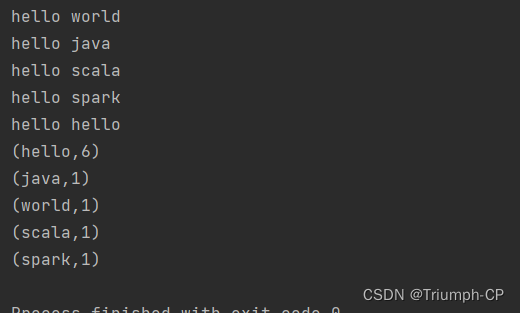
wordcount
val dataString: RDD[String]= sc.makeRDD(Array("hello world","hello java","hello scala","hello spark","hello hello"))
dataString.collect().foreach(println)
dataString.flatMap(x => x.split(" ")).map(x =>(x,1)).reduceByKey(_+_).collect.foreach(println)
打架包
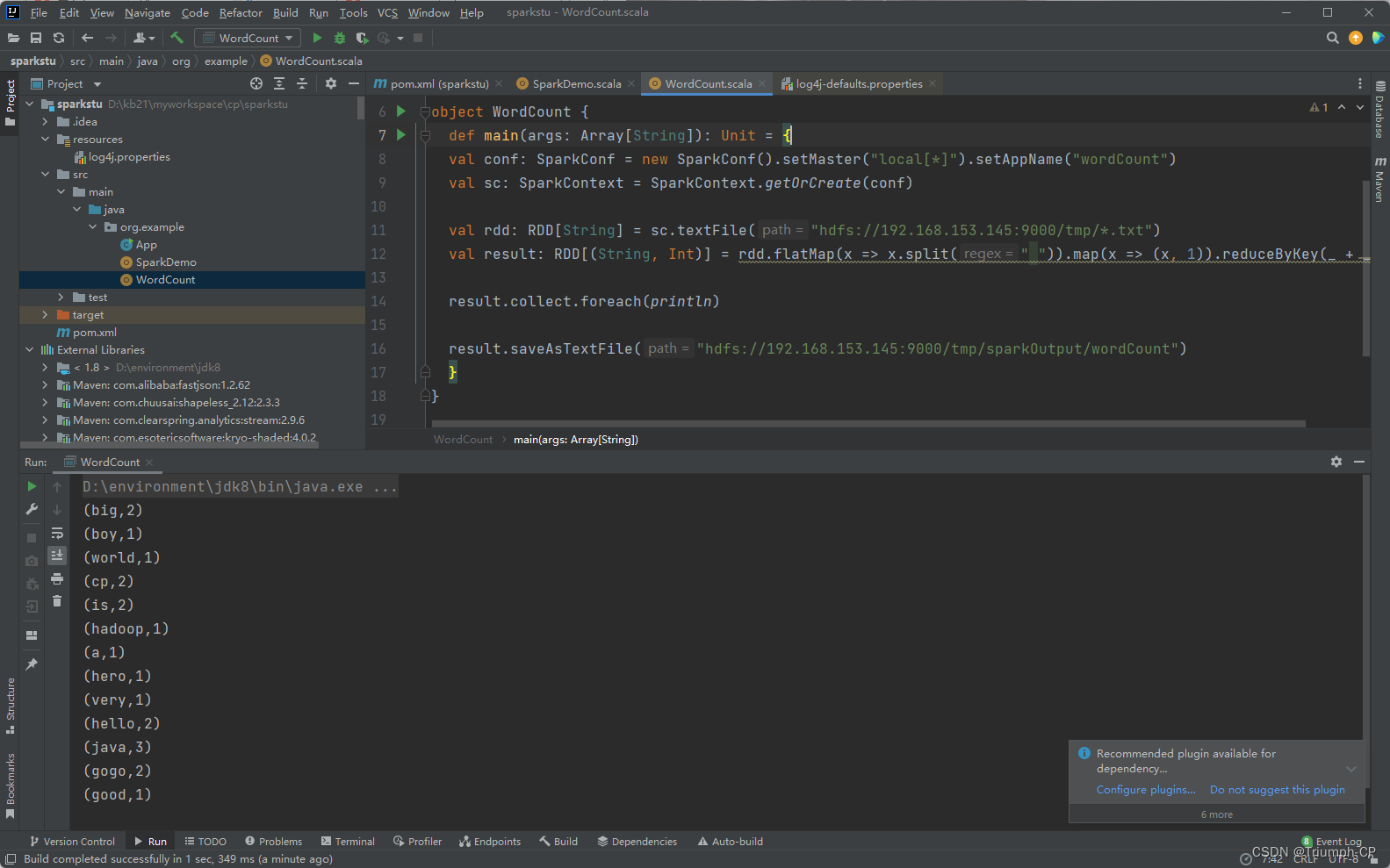
将代码编译打包,上传到虚拟机的opt目录下
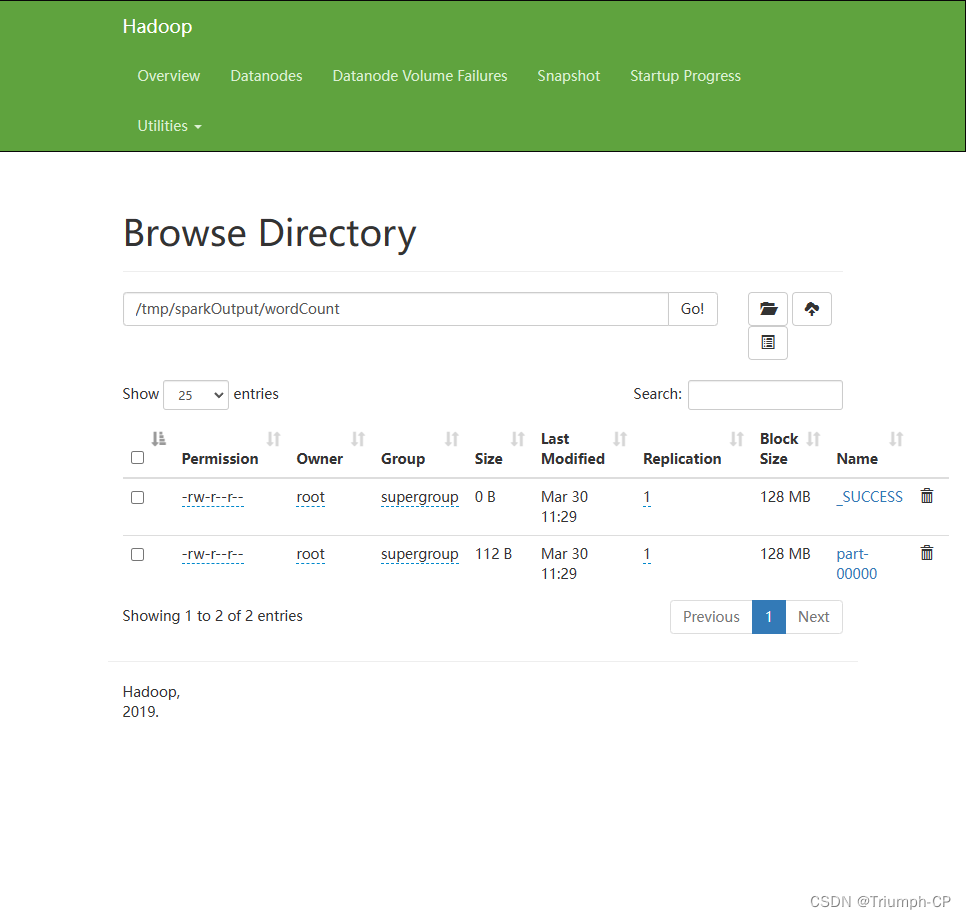
执行
[root@cp145 opt]# spark-submit --classorg.example.WordCount--master local[*]./sparkstu-1.0-SNAPSHOT.jar
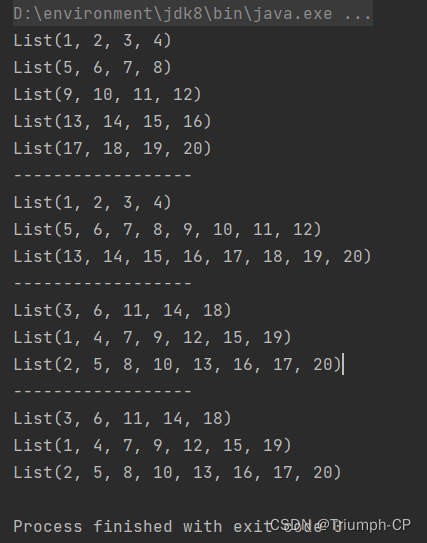
分区
def main(args:Array[String]):Unit={
val conf:SparkConf=newSparkConf().setAppName("partitions").setMaster("local[5]")
val sc:SparkContext=SparkContext.getOrCreate(conf)
val rdd: RDD[Int]= sc.parallelize(1to20)
rdd.glom().collect.foreach(x =>println(x.toList))println("---------假分区----------")
val rdd2: RDD[Int]= rdd.coalesce(3,false)
rdd2.glom().collect.foreach(x =>println(x.toList))println("---------真分区----------")
val rdd3: RDD[Int]= rdd.coalesce(3,true)
rdd3.glom().collect.foreach(x =>println(x.toList))println("---------真分区----------")
val rdd4: RDD[Int]= rdd.repartition(3)
rdd4.glom().collect.foreach(x =>println(x.toList))}
本文转载自: https://blog.csdn.net/cp1002327672/article/details/129850212
版权归原作者 Triumph-CP 所有, 如有侵权,请联系我们删除。
版权归原作者 Triumph-CP 所有, 如有侵权,请联系我们删除。