
1.引言
随着信息技术的快速发展,数据增长的速度越来越快。无处不在的传感器、社交网站(SNS)、医疗保健应用、商业交易等设备每秒生成的不同格式的数据正在以指数速率增加。为了处理如此大规模的数据,云计算是大数据研究社区的一个热点。
1961 年,McCarthy 在麻省理工学院百年庆典上首次提出“云”的概念,因为计算可能在一段时间内被组织为公用事业。它是一组共享计算资源的商品硬件。目前已经有许多基于云的大数据解决方案来提供数据密集型计算平台,例如 GFS、HDFS、BSP、Twitter Storm 和 GPGPU。这样的系统在商品机器上提供可扩展、分布式、高效和容错的机制。Hadoop 分布式文件系统已成为支持云上 MapReduce计算模型的高效分布式存储和处理框架。
Big Data Service Engine (BISE) 是一个平台,BISE 将存储在 HDFS 中的多结构数据转换为中间关系数据库,其他应用程序使用该数据库进行活动识别、情感识别。它使用 MapReduce进行数据转换和可视化。将电子健康记录 (EHR)、患者健康记录 (PHR) 和电子病历 (EMR) 等临床数据提供给医生以分析患者的临床情况。
此外,也可以使用可穿戴医疗保健监控设备,将设备收集到的数据推送到 Hadoop 系统。在 Hadoop 中,数据是在 Apache Sqoop 工具的帮助下以 csv 格式接收的。为了跨Hadoop平台的数据安全传输,研究人员使用更为安全的Apache Ranger。Ranger 基于 Apache 密钥管理系统来保护数据。然后使用 hive 映射和减少接收到的值,然后这些值以高度信息化和用户友好的方式呈现给用户。
另一种方法也遵循类似的路径,即将儿童的游戏分数与健康数据一起进行分析。系统采用的游戏是治疗游戏,主要用于心理治疗,以及检测注意力缺陷的游戏。因此,基于这个结果,他们的父母和导师可以在初始阶段对孩子进行个人关注。研究人员提出了一个非常友好的基于 Android 的应用程序,用户可以通过它登录并跟踪他们孩子的健康详细信息。 Hadoop 基础设施中启用的安全功能将使数据存储和传输高度机密和安全。
2大数据系统
2.1 Hadoop
Hadoop 是设计在商品集群上处理大数据的框架,其计算范式为 MapReduce。 它最初由 Google 提出,称为 Google 文件系统 (GFS),Apache Hadoop 是 GFS 的开源实现。 Hadoop 分布式文件系统 (HDFS) 被 Facebook、Oracle和 Yahoo等许多大型组织采用。 MapReduce已被用于大规模索引策略,并推荐用于 TB 级数据的索引。由于其容错性高、效率高、可靠性强它已被机器学习、医疗保健和数据分析社区广泛采用。
Hadoop 和 MapReduce 已广泛应用于医疗保健领域。罗斯等人提出了医疗生态系统中的大数据并将Hadoop 和 MapReduce用于大数据处理,例如数据探索和分析。为了支持大规模医学图像分析,Markonis 等人提出了三个实例,包括:肺纹理分类的参数优化、基于内容的医学图像索引和三维定向小波分析。他们的结果表明,原本将执行 130 小时的任务现在减少到仅 6 小时,处理时间显着减少。Hadoop MapReduce 也被用于大规模肽识别。一个名为 MRMSPolygraph 的搜索应用程序提供了一种混合方法来匹配实验光谱库中某些蛋白质序列的光谱。与单个最先进的台式机相比,他们在花费的时间减少了大约 333 倍。
Hadoop系统也被用在医疗应急管理系统领域。传感器用于从人体实时收集异构数据,并处理该数据以在危急健康情况下采取紧急行动。他们使用主传感器将数据转发到中央智能系统。使用ZigBee 收集数据,并通过互联网 (LTE/3G/Wi-Fi) 转发到智能楼宇。采用强大的平台来存储、处理和检索数据有助于大数据发展和 Hadoop系统的使用。
在现有工作中,提议的框架和开发的模型主要工作并使用特定的结构化(关系)或非结构化(文本、感官、XML)数据。这些框架对于对单一格式的数据进行高计算密集型处理最有效。然而,Hadoop 表现出处理结构化、半结构化和非结构化等各种数据的特性。因此Hadoop 是处理如此大规模、各种格式的数据的合适候选者。
2.2 BISE
BISE是一种大数据服务引擎。我们的系统存储和处理来自各种来源的多结构数据,以提供医疗保健服务。所提出的系统由三层和一个自适应中间数据库组成。三层包括数据采集层、数据存储和处理层、服务层。数据采集层由为系统收集/生成数据的多个来源组成;存储处理层由数据处理模块组成;服务层由多个促进医疗保健的服务引擎组成。所提出系统的整体架构如图1所示。服务层子组件使用自适应中间数据库对临床、身体、心理和社会健康服务的关系数据执行计算和计算。服务层中的每个子组件执行统计和分析算法以提供医疗保健服务。但是,这些算法超出了本文的范围。
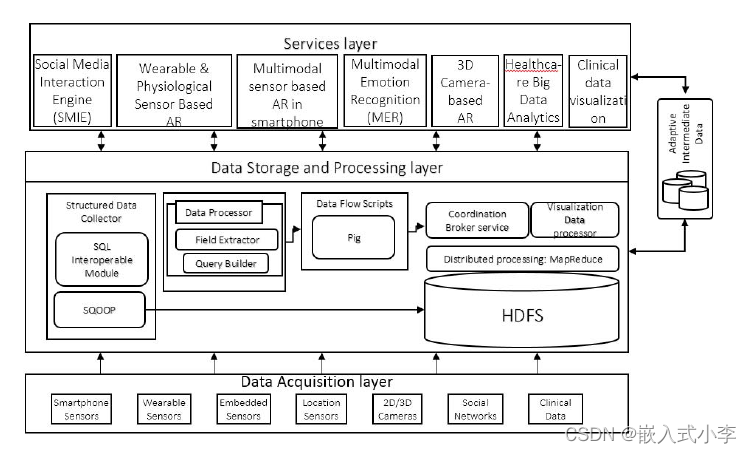
图一 大数据服务引擎详细架构
2.2.1数据采集层
大数据服务引擎 (BISE) 处理从各种来源以不同格式收集的各种数据,包括 XML、CSV、关系和图像。数据源包括智能手机传感器、可穿戴传感器、嵌入式传感器、位置传感器、2D/3D 摄像头、社交网站 (SNS) 和健康记录。传感器生成不同格式的数据,用于服务层的活动识别。2D/3D 相机以图像形式生成数据,用于使用面部表情技术进行情感识别。SNS数据为文本和 XML 格式,供社交媒体交互引擎 (SMIE) 在服务层使用监控用户的日常活动和兴趣。临床数据采用临床文档架构 (CDA),用于生成医疗保健分析。这些分析基于糖、基于性别、位置、年龄和各种其他参数的血压疾病趋势。目前数据采集以批处理方式进行存储在HDFS中。时间、层次结构和目录结构等技术用于区分来自各种输入源的数据并维护版本。
2.2.2数据存储和处理层
在这一层中,存储在HDFS中的数据根据服务层中医疗保健服务的需要进行处理。 Apache Sqoop 和 Pig 分别用于将批量数据传输到自适应中间数据库,并分别处理 Hadoop 中的大数据以进行分析。数据存储和处理层有以下子组件。
1)结构化数据收集器:目标是从HDFS中的各种数据中生成和收集结构化数据,供服务层的服务模块处理。结构化数据存储在中间数据库中,以便快速访问和处理。服务层中的各个模块,如SMIE、活动识别(AR)、情绪识别(ER),根据服务的需求和采集层采集的数据,为结构化数据采集器提供模式。Sqoop 用于将数据从大型非结构化格式(HDFS、Pig)传输到结构化格式(中间数据库)。
2)数据处理器:在大数据服务引擎中,数据来自各种格式的不同输入源。各种数据格式包括诸如关系数据(临床数据即 EHR)、半结构化如 XML(Twitter 流)、非结构化如传感数据。服务层的子组件需要处理特定格式的数据,例如活动识别(AR)需要使用机器学习技术处理数据。为了向子组件提供所需的数据,数据处理器模块生成并执行 Apache Pig 脚本以对这些大数据集执行操作。Pig 脚本是根据服务层的可视化需求生成的。可以对任何数据进行可视化和分析,包括身体活动、面部表情和情绪、去过的地方、临床发现和临床疾病分析。数据处理器旨在处理 HDFS 数据以识别用户所有数据中的异常行为,包括临床、社交、情感和活动。它有两个子组件:字段提取器和查询构建器。字段提取器提取上层传递过来的参数进行数据处理。查询生成器根据字段提取器提取的参数生成查询并执行
通过数据流脚本 (Apache Pig) 在 HDFS 上运行。返回的结果存储回 HDFS 并由服务层中的可视化模块使用以生成交互式视觉图像,如图 2 所示。
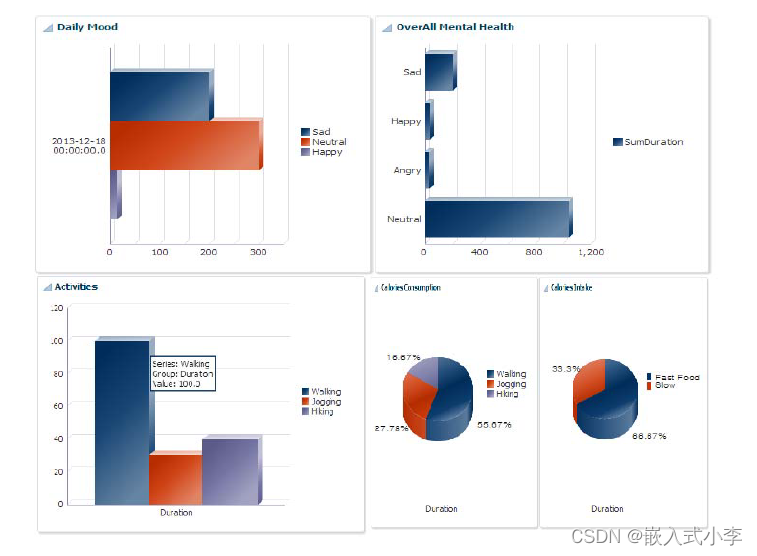
图二 日常情绪(左上)、整体情绪(右上)、日常活动(左下)和每日卡路里消耗/摄入量(右下)的可视化。
2.2.3服务层
在BISE中,我们为用户提供临床、社会、心理和身体健康服务和建议方面的健康监测。 BISE 中的服务层包括提供个性化服务的子组件,例如社交媒体交互、基于可穿戴传感器日志的活动识别、智能手机中的活动识别、2D/3D 视频和图像中的情绪识别、临床数据可视化以。通过所有这些不同的服务,用户/患者可以监控和分析当前的身体活动、情绪和临床状况。
3大数据系统的应用
在当今快速的业务环境中,StreamCentral 是一种最终用户应用程序/产品,允许其用户快速处理新数据流、从源添加新数据以及分析和揭示业务绩效。 Stream Central 提供的功能包括运营智能、按需商业智能、知识发现和社会协作。然而, BISE 框架旨在用于整合精神、身体和社会健康信息的医疗保健服务。 BISE 框架在性质(BISE 使用 Hadoop)、目的(BISE 专注于积极的生活方式)和服务方面与 StreamCentral 不同。
研究人员已实施大数据服务引擎 (BISE) 作为两个医疗保健项目的子部分,包括人类参与健康应用程序的活动意识 (ATHENA) 和个性化无处不在的生命护理支持引擎 (PULSE)。 Hadoop分布式文件系统(HDFS)作为多种数据存储机制,MapReduce作为其处理框架。 Apache Pig 配置在 Hadoop 之上,为活动和活动提供快速数据处理和临床数据可视化。 Apache Sqoop 用于将数据从 HDFS(各种格式)传输和转换到自适应中间数据库,供服务层用于服务提供。 数据上传到HDFS是批量上传,服务层实时访问HDFS和中间数据库中的数据。
推特、脸书、Myspace 等社交网站(SNS)产生的大数据可用于预测和分析世界事务、医疗保健等已知领域的趋势分析。Hyeokju 等人提出了一种在 MapReduce 上进行大规模社交数据分析的实现。 他们的系统由两部分组成:数据采集代理和数据分析模块。数据分析模块由改进版的TF-IDF和Weighted-MINMAX分析组成,用于提取高优先级的趋势词。系统根据效率和性能进行评估,与现有系统相比,性能提高了 3-5 倍,并且可以通过集群中的其他节点进一步降低性能,为智能手机用户提供廉价、可用和可靠的分布式技术。
还可以将Hadoop用在治疗性游戏所获取的数据上,使用数据预测疾病的最终 C4.5 算法以预测孩子的健康状况。其关键思想是使用传感器和游戏远程监控孩子的健康和行为。由于该系统专注于儿童的福祉和心理健康,鼓励孩子玩治疗游戏。这些游戏是检测注意力缺陷多动障碍 (ADHD)的,其中包含一些必须由父母或导师回答的问卷。如图3所示,该系统还融合了Stroop和Visual Spatial等其他更注重脑力的游戏,使孩子能够准确地思考和回答。在玩游戏时,同时使用传感器监测孩子的健康参数。不同的用户通过系统给出的唯一 ID 进行标识。主要使用三个不同的传感器从孩子那里捕获三个参数,即体温、血压和心跳。获得的值通过无线传输不断发送到控制器,直到孩子完成游戏。Hadoop 文件系统从本地数据库获取这些数据,以便使用 Sqoop 进行分析。 Sqoop 充当 HDFS 和关系数据库之间的中介,用于传输数据。
在 Hadoop 中,通过将数据与 Hadoop 文件系统中相应编码的阈值进行比较来处理数据。 为了在 Hadoop 中安全存储数据,他们采用了 apache ranger,它也是 Hadoop 系统的一部分。 收集到的读数然后在 Hadoop 系统中映射和减少,以提高存储和处理的效率。 整个数据都封装在客户端应用程序中,在该应用程序中将根据用户要求生成报告。 最终用户可以选择在他们需要时查看他们孩子的健康和行为详细信息。
Apache Ranger 提供了跨 Hadoop 平台的完整数据安全性。 这使用密钥管理服务 (KMS) 并采用加密密钥来加密数据。 Ranger 跟踪并集中存储在 Hadoop 文件系统中的文件的位置,还跟踪所有接收到 Hadoop 平台的访问请求。 所有存储的数据都经过加密,未经授权的用户无法访问。 因此,Hadoop 中的 Apache ranger 为整个系统提供了全面的安全性。
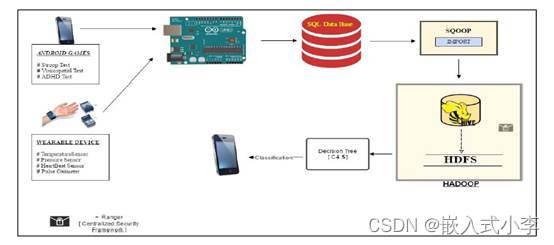
图 3 治疗性游戏的整体系统架构
4系统的测试与分析
本节描述了 BISE 原型开发的实验框架,并基于一个场景展示了一些结果,该场景涵盖了使用哪些数据以及生成哪些健康信息和可视化的细节。本文的目标是为异构的海量数据源提供框架,以在云上集成并提供一个简单/便宜的可用系统。所呈现的场景仅介绍了我们如何收集和使用来自异构来源的数据以改善用户的生活方式。
4.1实验框架和实现
研究人员已实施大数据服务引擎 (BISE) 作为两个医疗保健项目的子部分,包括人类参与健康应用程序的活动意识 (ATHENA) 和个性化的生命护理支持引擎。Hadoop分布式文件系统(HDFS)作为多种数据存储机制,MapReduce作为其处理框架。 Apache Pig 配置在 Hadoop 之上,为活动和活动提供快速数据处理
临床数据可视化。 Apache Sqoop 用于从 HDFS(各种格式)传输和转换数据,以适应服务层用于服务提供的 hive 中间数据库。数据上传到HDFS是批量上传,服务层实时访问HDFS和中间数据库中的数据。
Hadoop集群由10个节点组成,5台物理机,每台物理机上1台虚拟机。所有物理机都有4GB内存,500GB硬盘,英特尔酷睿i5处理器,Ubuntu 12.10操作系统。 数据收集自 Facebook 和 Twitter 等社交网站、加速度计等智能手机活动识别传感器、视频 2D/3D 摄像头,以及来自医院的临床观察数据(例如电子健康记录 (EHR))。服务层子组件在 Oracle Jdeveloper 中作为 Web 应用程序与分析和活动监控一起开发。原型系统成功地集成了各种技术,并为用户提供集中的健康监控。一些数据可视化结果显示在说明活动和临床观察中。
4.2案例研究场景和讨论
考虑到想要监控人们的身体、心理活动和食物摄入量,活动数据由各种活动识别传感器和可穿戴设备生成,日常生活和心理健康数据是从人们在 Facebook、Twitter、KakaoStory和图像上的社交活动中收集的。至于食物信息以及卡路里摄入量是从人们在餐厅的日常登记和退房中收集的。基于用户的这些信息,系统将用户数据可视化并显示在图二中。在该图中,用户活动、卡路里消耗/摄入、日常情绪和整体心理健康被可视化。卡路里消耗信息由用户提供,卡路里摄入信息是通过用户在活动中完成的签到和食物摄入收集的。基于这些信息,用户可以监测他们的心理、身体和社会健康状况,并与正常的人类生活方式进行比较。研究人员提出了一种集成解决方案,可以在一个地方使用各种数据作为大数据服务引擎(BISE)。
4.3大数据系统在物联网上的测试
大数据在物联网上的应用系统是使用微控制器 Arduino UNO 实现的,这是一块带有ATmega328P 的板,与可穿戴医疗监测设备相连,能够读取体温、压力和心跳,并将这些数据与游戏生成的数据一起传输。治疗性游戏可以安装在从安卓 4.1 到最新版本的任何安卓设备上。传输的数据在推送到 Hadoop 之前临时存储在使用 Xamp 服务器创建的本地服务器中。但是,为了获得更好的结果,可以使用 ThingSpeak 等其他云平台来存储数据。该系统在具有3.2GHz处理器和 4 GB 内存的 Windows Server 操作系统机器上的Horton Data Platform 2.3.4 中具有Hadoop 单节点设置
MapReduce 用作前端编程,带有 Hadoop 库,用在收集单元处理和生成序列文件。研究人员实现的 Map 函数映射了相应的传感器值。它将这些值与预定义的阈值进行比较,并在出现任何异常情况时生成警报。map 函数生成一个带有传感器读数计数的中间结果,如图 4 所示。不是存储大型数据集,而是将数据缩减并作为文件存储在 Hadoop 中。 然后,reducer 聚合结果并组织它们。最后,通过使用 C4.5 算法将新数据与系统中的先前数据集进行比较来做出决定。该系统最终会预测孩子患上任何类型疾病的几率。为了捕捉孩子的身体参数,他们使用血压、体温和心跳传感器。
版权归原作者 2401_87556747 所有, 如有侵权,请联系我们删除。