
前言
大家好,我是秋意零。
在上一篇中,我们讲解了 DaemonSet 控制器,相信你以及理解了其的工作过程,分为三部。一是,获取所有 Node 节点中的 Pod;二是,判断是否有符合 DaemonSet 管理的 Pod;三是,通过“亲和性”和“容忍”来精确控制并保证 Pod 在目标节点运行。
今天的内容是 Job 与 CronJob 离线业务控制器。
👿 简介
- 🏠 个人主页: 秋意零
- 🔥 账号:全平台同名, 秋意零 账号创作者、 云社区 创建者
- 🧑 个人介绍:在校期间参与众多云计算相关比赛,如:🌟 “省赛”、“国赛”,并斩获多项奖项荣誉证书
- 🎉 目前状况:24 届毕业生,拿到一家私有云(IAAS)公司 offer,暑假开始实习
- 💕欢迎大家:欢迎大家一起学习云计算,走向年薪 30 万
- 💕推广:CSDN 主页左侧,是个人扣扣群推广。方便大家技术交流、技术博客互助。

系列文章目录
【云原生|探索 Kubernetes-1】容器的本质是进程
【云原生|探索 Kubernetes-2】容器 Linux Cgroups 限制
【云原生|探索 Kubernetes 系列 3】深入理解容器进程的文件系统
【云原生|探索 Kubernetes 系列 4】现代云原生时代的引擎
【云原生|探索 Kubernetes 系列 5】简化 Kubernetes 的部署,深入解析其工作流程
更多点击专栏查看:深入探索 Kubernetes
正文开始:
- 快速上船,马上开始掌舵了(Kubernetes),距离开船还有 3s,2s,1s...

一、离线业务
通过前面篇章中的学习的控制器,如:Deployment、StatefulSet、DaemonSet 这三个编排控制器,它们所部署的服务都有什么共同点吗?
答案是:有的。
- 其实,它们主要编排的对象业务,都是“在线业务”,即:Long Running Task(长作业)。比如:Nginx、Tomcat、Apache、MySQL 等等,这部分业务只要一运行起来,如果不出现错误或手动停止删除,这些服务的容器(进程)会一直运行(Running)下去。
既然有了这种“在线业务”,那是不是就一定有“离线业务”呢?
答案:是的。
- “离线业务”对比“在线业务”是相反的概率,就是服务不会一直运行下去,而是服务自己的任务完成之后就会自动退出。
如果使用控制“在线业务”的控制器,来编排“离线业务”会是怎么样呢?
- “离线业务”或者叫作 Batch Job(计算业务):这种情况下是没有意义的,比如:使用 Deployment 来编排一个“离线业务”,“离线业务”完成后就会自动退出,而因为 Deployment 的缘故会实际状态的 Pod 个数保持在期望状态的 Pod 个数,也就会重新创建这个“离线业务”。
- 咋一看,好像也没什么,如果将“离线业务”任务是用来计算 1+1 的这种运行结果时,不断重建“离线业务”是不是就失去了意义了呢?
- 因为完全没有必要。而使用 Deployment 的“滚动更新”功能也是一样的道理,无意义。
二、Job 基本概念与用法
现在,我们来看一个 Job 计算 π 后 10000 位小数的例子:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=10000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4
可以看到,这个例子的
spec.template
字段可谓是非常熟悉了吧(Pod 模板)。但是,跟其他控制器不同的是,Job 对象并不要求你定义一个 spec.selector 来绑定要控制哪些 Pod。
这个 Job 使用的一个 ubuntu 镜像 ,安装有 bc 精度的计算命令,并运行了一条计算 π 后 10000 位小数的命令:
echo 'scale=10000; 4*a(1)' | bc -l
- scale:定义某些操作如何使用小数点后的数字,默认为 0;
- *4a(1)*:a(1),是调用数学库中的 arctangent 函数,4atan(1) 正好就是 π,也就是 3.1415926…;
- -l 参数:定义使用的标准数学库。
- 运行这个 Job:
[root@master01 yaml]# kubectl apply -f job.yaml
job.batch/pi created
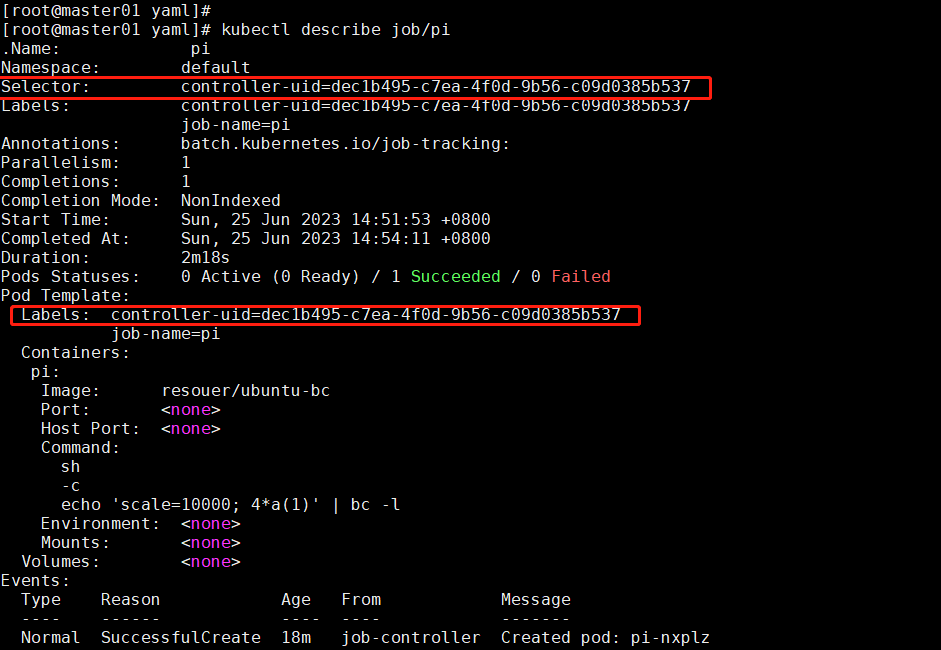
[root@master01 yaml]# kubectl describe job/pi
我们来查看一下这个 Job 对象详细信息:
- 可以看到创建 Job 之后,Job 自动为 Pod Template 添加了一个标签,格式为:controller-uid=<一个随机字符串>。Job 本身也添加了对应的 Selector,从而保证了 Job 与它所管理的 Pod 之间的匹配关系。
- 而 Job 控制器使用这种 UID 的标签,就是为了避免不同 Job 对象所管理的 Pod 发生重合。因为它不需要对特定的副本进行选择或管理,Job 仅负责执行一次性任务,而不需要与其他副本进行交互或进行标签选择。
- Job 中也没有 replicas 字段。因为, Job 的主要目的是确保任务的完成,不是保持一定数量的副本运行。当 Job 中定义的任务成功完成后,Job 会认为任务已经完成,并且不会重新创建新的任务。因此,replicas 字段在 Job 中没有意义。
- 创建 Job 后,查看 Pod 的状态:
[root@master01 yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-nxplz 1/1 Running 0 31s
几分钟后 Pod 进入 Completed 状态,说明它的任务已经完成。不重启的原因:我们在 Pod 模板中定义过了 restartPolicy=Never 策略。
Job 中的重启策略 restartPolicy,只能被设置为 Never 和 OnFailure;
[root@master01 yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-nxplz 0/1 Completed 0 4m
[root@master01 yaml]# kubectl get job
NAME COMPLETIONS DURATION AGE
pi 0/1 3s 3s
- kubectl logs 命令,查看运行结果:
[root@master01 ~]# kubectl logs pod/pi-nxplz
3.141592653589793238462643383279502884197169399375105820974944592307\
81640628620899862803482534211706798214808651328230664709384460955058\
22317253594081284811174502841027019385211055596446229489549303819644\
28810975665933446128475648233786783165271201909145648566923460348610\
....
- 离线作业失败了要怎么办?
由于,定义了
restartPolicy=Never
,那么离线作业失败后 Job Controller 就会不断地尝试创建一个新 Pod,如:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
pi-55h89 0/1 ContainerCreating 0 2s
pi-tqbcz 0/1 Error 0 5s
不过,为了不让这个 Pod 一直创建下去,因为一直创建下去说明我们程序就有问题,这个时候我们使用
spec.backoffLimit
字段来设置重试次数,这个 Job 为 4,这个字段的默认值是 6。
需要注意的是:Job Controller 重新创建 Pod 的间隔是呈指数增加的,即:下一次重新创建 Pod 的动作会分别发生在 10 s、20 s、40 s …后。
而如果你定义的
restartPolicy=OnFailure
,那么离线作业失败后,Job Controller 就不会去尝试创建新的 Pod。但是,它会不断地尝试重启 Pod 里的容器。
- 如果这个 Pod 因为某种原因一直不肯结束呢?
spec.activeDeadlineSeconds
字段可以设置最长运行时间,比如:
spec:
backoffLimit: 4
activeDeadlineSeconds: 100
这个程序运行一旦超过 100 s,那 Pod 会被终止。
以上,就是一个 Job API 对象最主要的概念和用法了。不过,离线业务之所以被称为 Batch Job,当然是因为它们可以以“Batch”(批处理),也就是并行的方式去运行。
三、Job Controller 并行作业的控制方法
在 Job 对象中,负责并行控制的参数有两个:
- 1. spec.parallelism:Job 最多可以启动多少个 Pod 同时运行;
- **2.**spec.completions:Job 至少要完成的 Pod 数目,即 Job 的最小完成数。
在之前计算 Pi 值的 Job 里,添加这两个参数:
- 并行数量为 2
- 至少完成的数量为 4
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
parallelism: 2
completions: 4
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=5000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4
- 创建 Job:
[root@master01 yaml]# kubectl apply -f job.yaml
- 查看 Job:
- COMPLETIONS:需要完成的数量以及完成的数量,比如:2/4,已完成 2 个任务,至少需要完成 4 个任务。
[root@master01 yaml]# kubectl get job
NAME COMPLETIONS DURATION AGE
pi 2/4 57s 57s
当一组 Pod 完成后,就会有新的一组 Pod 继续执行
[root@master01 yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-js98q 1/1 Running 0 25s
pi-mhfsl 1/1 Running 0 25s
pi-t2w8n 0/1 Completed 0 55s
pi-z7gqh 0/1 Completed 0 55s
当所有 Pod 任务完成之后,Job 的 COMPLETIONS 字段也就变成了 4/4
[root@master01 yaml]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pi-js98q 0/1 Completed 0 8m56s
pi-mhfsl 0/1 Completed 0 8m56s
pi-t2w8n 0/1 Completed 0 9m26s
pi-z7gqh 0/1 Completed 0 9m26s
[root@master01 yaml]# kubectl get job
NAME COMPLETIONS DURATION AGE
pi 4/4 59s 3m59s
Job Controller 实际上控制了,作业执行的并行度,以及总共需要完成的任务数这两个重要参数。而在实际使用时,你需要根据作业的特性,来决定并行度(parallelism)和任务数(completions)的合理取值。
四、使用 Job 常用的方法
外部管理器 +Job 模板
这种模式的用法是:把 Job 的 YAML 文件当作一个模板,然后使用外部工具来控制生成 Job。如下:
apiVersion: batch/v1
kind: Job
metadata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: job-example
labels:
jobgroup: jobexample
spec:
containers:
- name: busybox-job
image: busybox
command: ["sh", "-c", "echo Hello $ITEM && sleep 5"]
restartPolicy: Never
Job 的 YAML 中,定义了 $ITEM 变量,所以在控制这中 Job 时,需要注意两个方面:
- 创建 Job 时,替换掉 $ITEM 变量,为自己的信息;
- 来自于同一个模板的 Job,这里都有一个
jobgroup: jobexample标签,也就是说这一组 Job 使用这样一个相同的标识。
- 来自于同一个模板的 Job,这里都有一个
使用 Shell 把 $ITME 替换掉
[root@master01 yaml]# mkdir ./jobs
[root@master01 yaml]# for i in qyl-1 qyl-2 qyl-3
> do
> cat job-1.yaml | sed "s/\$ITEM/$i/g" > ./jobs/job-$i.yaml
> done
这样通过 Shell 脚本的方式,同一个 Job 模板生成了不同的 Job 的 YAML 文件
[root@master01 yaml]# ll ./jobs
total 12
-rw-r--r-- 1 root root 372 Jun 25 17:31 job-qyl-1.yaml
-rw-r--r-- 1 root root 372 Jun 25 17:31 job-qyl-2.yaml
-rw-r--r-- 1 root root 372 Jun 25 17:31 job-qyl-3.yaml
[root@master01 yaml]# kubectl apply -f ./jobs
job.batch/process-item-qyl-1 created
job.batch/process-item-qyl-2 created
job.batch/process-item-qyl-3 created
[root@master01 yaml]# kubectl get pods -l jobgroup=jobexample
NAME READY STATUS RESTARTS AGE
process-item-qyl-1-tgr5k 0/1 Completed 0 53s
process-item-qyl-2-bftz4 0/1 Completed 0 53s
process-item-qyl-3-cgvwd 0/1 Completed 0 53s

五、CronJob
顾名思义,CronJob 描述的,是定时任务。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- date; echo Hello qyl-0
restartPolicy: OnFailure
CronJob 的 YAML 文件中,
spec.jobTemplate
字段表示的是“Job模板”,所以 CronJob 是 Job 对象的控制器。CronJob 与 Job 之间的关系就与 Deployment 和 ReplicaSet 一样的。不过它生命周期是由 schedule 字段控制的。
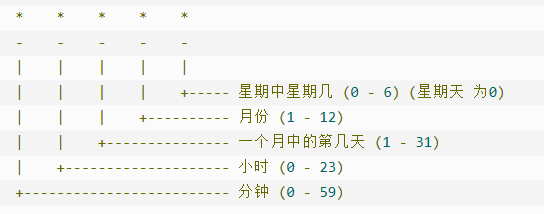
它也像我们 Linxu 里面的 CronTab,所以这里的 schedule 字段的格式是一个标准的 Cron 格式。*比如:"/1 * * * *"**。
这个 Cron 表达式里 */1 中的 * 表示从 0 开始,/ 表示“每”,1 表示偏移量。所以,它的意思就是:从 0 开始,每 1 个时间单位执行一次。
所以,上面的 CronJob 的 YAML 文件会一分钟后创建 Job:
[root@master01 yaml]# kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 26s 58s
[root@master01 yaml]# kubectl get job
NAME COMPLETIONS DURATION AGE
hello-28128130 1/1 4s 27s
需要注意的是,由于定时任务的特殊性,很可能某个 Job 还没有执行完,另外一个新 Job 就产生了。这时候,你可以通过
spec.concurrencyPolicy
字段来定义具体的处理策略。比如:
concurrencyPolicy=Allow:这也是默认情况,这意味着这些 Job 可以同时存在concurrencyPolicy=Forbid:这意味着不会创建新的 Pod,该创建周期被跳过;concurrencyPolicy=Replace:这意味着新产生的 Job 会替换旧的、没有执行完的 Job。
而如果某一次 Job 创建失败,这次创建就会被标记为“miss”。当在指定的时间窗口内,miss 的数目达到 100 时,那么 CronJob 会停止再创建这个 Job。
这个时间窗口,可以由
spec.startingDeadlineSeconds
字段指定。比如:
startingDeadlineSeconds=200,意味着在过了 200 s 后,如果 miss 的数目达到了 100 次,那么这个 Job 就不会被创建执行了。
总结
今天,主要讲解了 Job 这种“离线业务”控制器的概率用法,并行控制的方法。
最后,解释了 CronJob 的使用,CronJob 也体现了,用一个对象控制另一个对象,是 Kubernetes 编排的精髓所在。
版权归原作者 秋意零 所有, 如有侵权,请联系我们删除。