
版本:
- Chrome 124
- Python 3.12
- Selenium 4.19.0
版本与我有差异不要紧,只要别差异太大比如 Chrome 用 57 之前的版本了,就可以看本文。
如果你从前完全没使用过、没安装过Selenium,可以参考这篇博客《【记录】Python3|Selenium4 极速上手入门(Windows)》快速安装Edge版本的webdriver,再继续看下文。
前言
这个问题我本来以为就是抓个包解决的,不过后来才发现因为现在浏览器的设计原因,返回
Content-Type:application/pdf
;的时候就会自动在浏览器中预览文件,报文的响应会解析成以下东西:
<!doctypehtml><html><bodystyle='height: 100%;width: 100%;overflow: hidden;margin:0px;background-color:rgb(51, 51, 51);'><embedname='2F7A72AC9A127791D290DA205760BBE4'style='position:absolute;left: 0;top: 0;'width='100%'height='100%'src='about:blank'type='application/pdf'internalid='2F7A72AC9A127791D290DA205760BBE4'></body></html>
这会导致网页在遇到这种响应的时候会预览PDF,而不是下载PDF。
网上方法一大堆我看五花八门的其实解决起来就那么回事,有人问我我就汇总一下ok废话不多说。
文章目录
方式一:浏览器设置,PDF打开方式默认为下载
1.1 具体做法
参考:如何使 pdf 文件在浏览器里面直接下载而不是打开-Jacob’s Blog
如果关掉浏览器的PDF阅读模式就不会预览而是会直接下载,例如谷歌浏览器中的设置项,步骤如下:
- 打开设置,搜索pdf,前往网站设置。
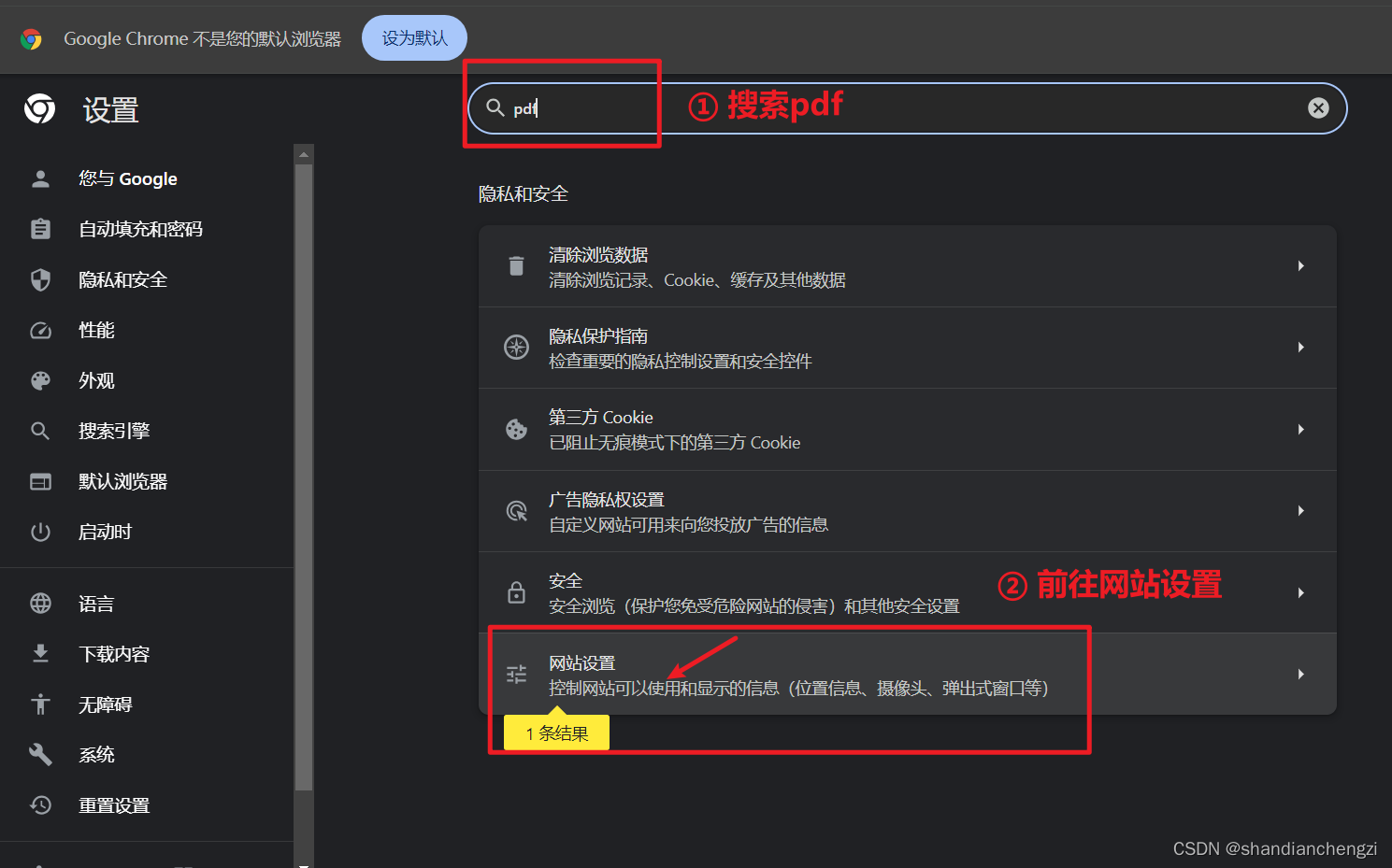
- 展开更多内容设置,并点击PDF文档。
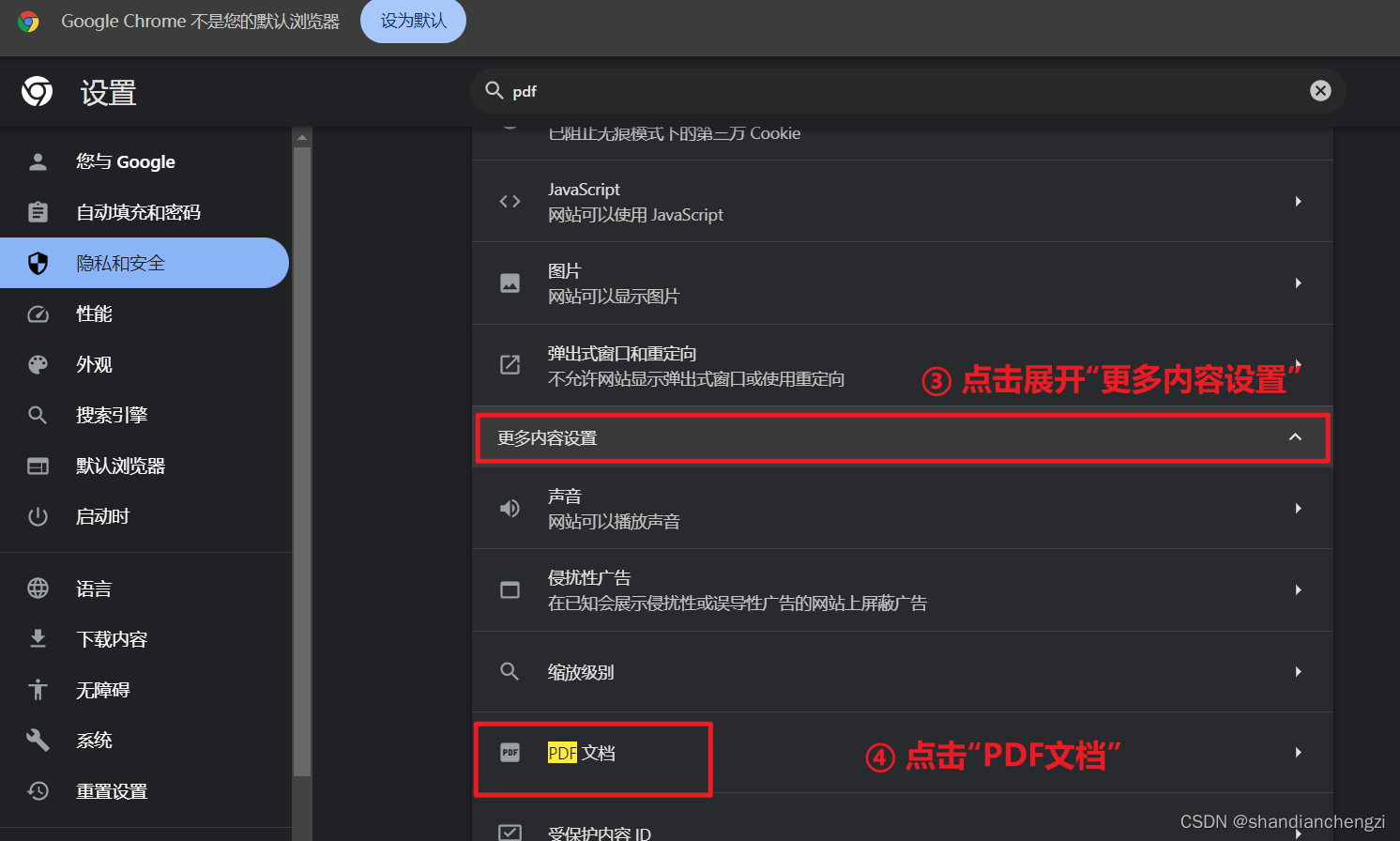
- 修改默认行为为下载PDF文件。
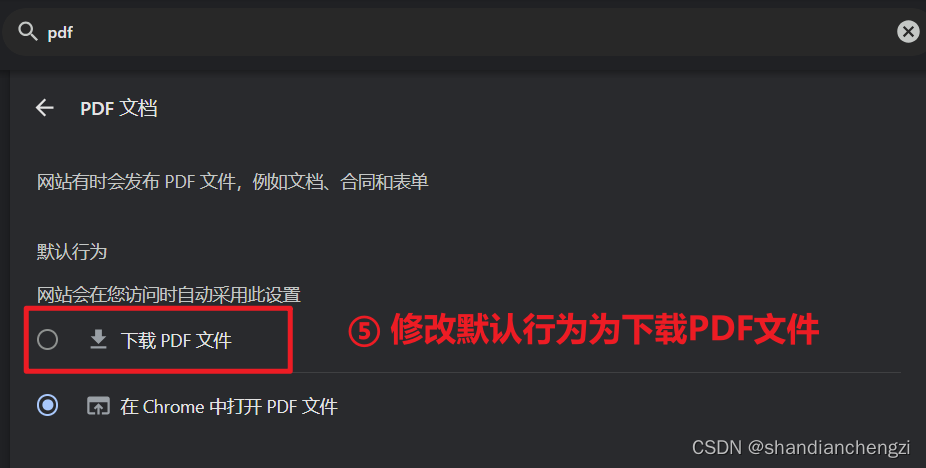
如果设置了下载路径为“另存为”的话,仍然需要手动选择PDF的下载路径。如下所示。
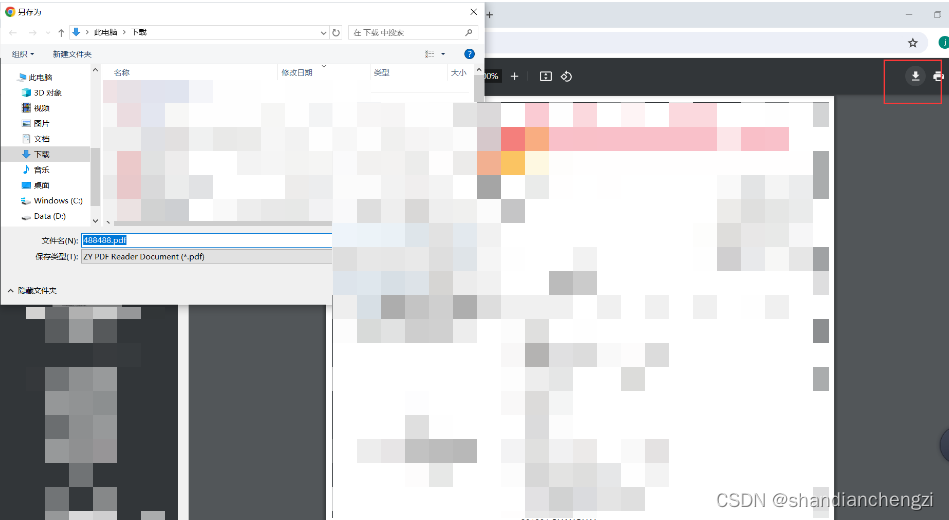
但是,这个问题是可以解决的。
如果根据下面的步骤设置了默认下载路径,则会自动下载如下。
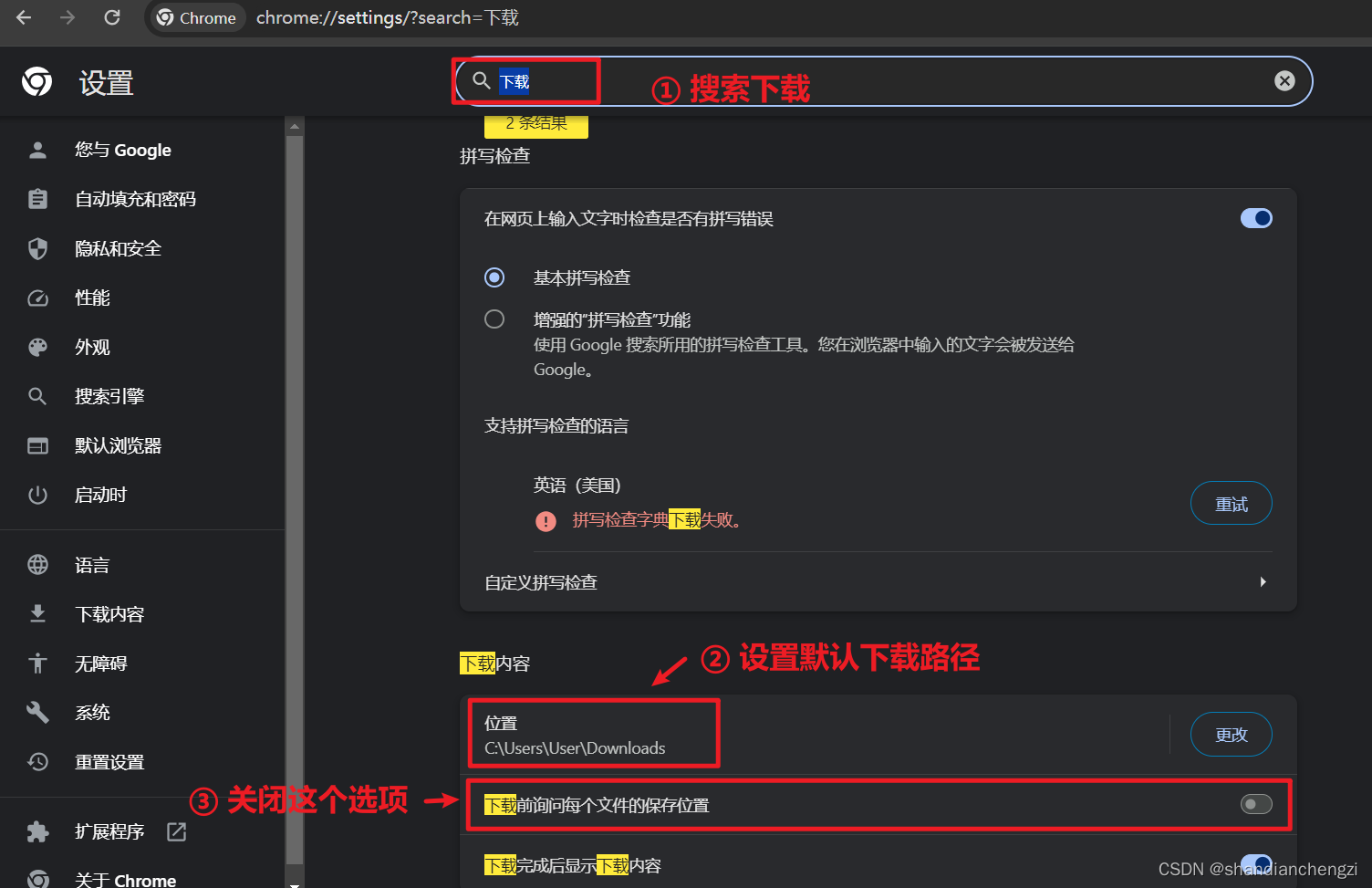
如下所示:

1.2 做法评估
- 优点:能让我们的读者朋友们弄清楚不预览不弹窗的可视化逻辑。
- 缺点: 1. 这种做法放到selenium里面就没用了,因为这个设置不会继承到 chromedriver 中去。2. 不会继承的问题是有可能解决的,即设置
user-data-dir。不过我按照这个思路去解决发现并不起效:options.add_argument("user-data-dir=C:/Users/User/AppData/Local/Google/Chrome/User Data/Default")具体路径可以通过chrome://version查看(路径查找参考:chromedriver官方文档),如下所示。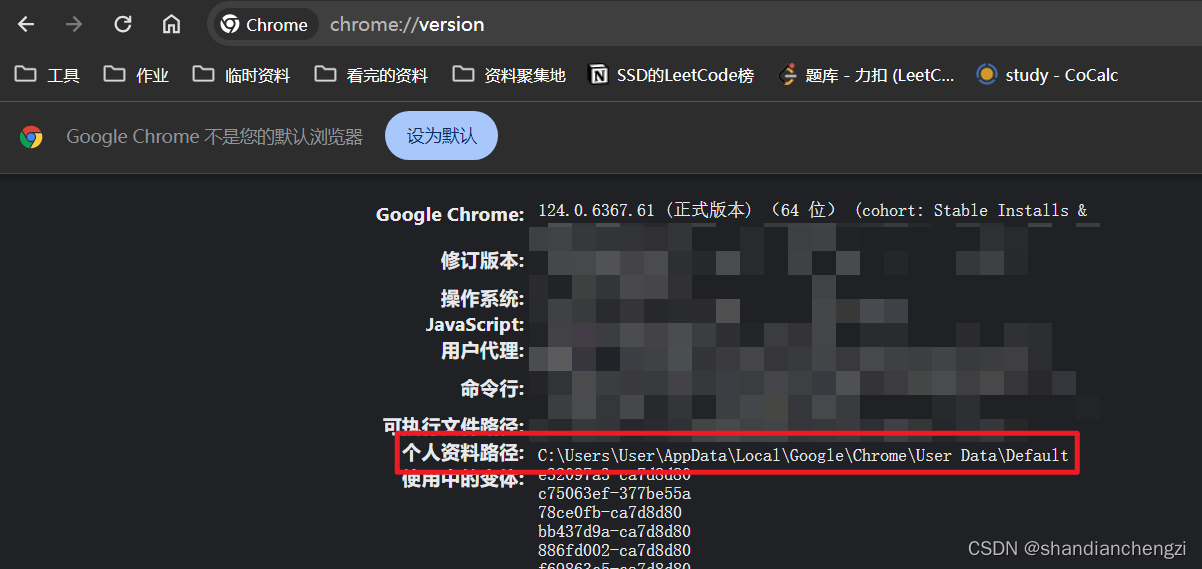
方式二:Selenium设置,禁用PDF Viewer插件
2.1 具体做法
参考:selenium disable chrome pdf viewer python-稀土掘金
根据这篇博客,说其实谷歌浏览器是靠一个自带的叫PDF-Viewer的插件来打开网页的pdf,selenium有个语句能禁用这个插件。
相关代码如下:
from time import sleep
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(chrome_options=chrome_options)
chrome_options.add_experimental_option('prefs',{"download.prompt_for_download":False,'plugins.always_open_pdf_externally':True})
driver = webdriver.Chrome(chrome_options=chrome_options)
sleep(1000)# 有时候会有人还没等到它下载就退出了,然后觉得这个方法没有作用,所以特地加一行sleep
注意一点,网上还流传着另一种代码:
'plugins.plugins_disabled': ["Chrome PDF Viewer"]
,这个早就已经没用了(自从 Chrome 57)。具体的讨论帖子可以看 Disabling PDF Viewer plugin in chromedriver-StackOverflow。
2.2 做法评估
- 优点:和Selenium结合得非常好;
- 缺点:有人说这个方法不起效,因为他们没有sleep,在还没开始下载的时候这个程序就退出了。这个并不是编程人员的毛病,而是这个方法本身确实有缺点。① 它具体下载到哪里了不太好获取(因为是Default),还得另外写代码;② 你没办法确定这个 PDF 是否下载好了。(和第一个缺点一样,都是因为这个下载位置都不太好获取,下载状态更难获取)③ 需要等待一定的时间去下载它,但又难以知道要等多久。(这就是 Selenium 的缺点了,它在模拟方面登峰造极,也在线程控制方面和浏览器的线程控制一样随意而混乱……)
这个做法的缺点如此之多,以至于第三个方式存在极大的生存土壤。
方式三:requests库,直接请求url
3.1 具体做法
参考:没参考,这就是我自己平常的写法。
都已经有url了就别那么麻烦了,赶紧直接请求得到结果吧。。
可用的示例代码如下:
import requests
# URL of the PDF file
pdf_url ='https://xx.pdf'# Send an HTTP GET request to the URL
response = requests.get(pdf_url)# Check if the request was successful (status code 200)if response.status_code ==200:# Open a file in binary write modewithopen('downloaded_pdf.pdf','wb')as f:# Write the PDF content to the file
f.write(response.content)print("PDF downloaded successfully.")else:print("Failed to download PDF. Status code:", response.status_code)
3.2 方法评估
- 优点:简单直接高效。
- 缺点:requests库有个坏处,就是总是要自己定义header的参数。而这一点Selenium弥补得很好。为了继承Selenium的自动填充的参数,避免反爬虫的问题,GPT添加headers如下所示:
from selenium import webdriverimport requests# Set up Selenium WebDriver (make sure to have appropriate driver installed)driver = webdriver.Chrome()# Navigate to the website containing the PDFdriver.get("https://example.com/your_pdf_link")# Extract the URL of the PDF filepdf_url = driver.current_url# Retrieve the headers from the WebDriverheaders = driver.execute_script("return Object.fromEntries(new Map(Object.entries(arguments[0].headers)))", driver.execute_script("return window.navigator"))# Use requests to download the PDF file with headersresponse = requests.get(pdf_url, headers=headers)# Check if the request was successfulif response.status_code ==200:# Save the PDF filewithopen("output.pdf","wb")as f: f.write(response.content)print("PDF file downloaded successfully.")else:print("Failed to download the PDF file.")# Close the Selenium WebDriverdriver.quit()
说实在的啊,这个script是不能用的,但是思路就是继承Selenium的参数。
根据我的精心查找,我发现写出一个继承 Selenium 参数的 script 的方式已经值得再写一篇博客了,这篇博客的链接是【代码】Python3|Requests 库怎么继承 Selenium 的 Headers (2024,Chrome)。
一般情况(指对 headers 要求不高时)加上这一个参数就行,反爬虫厉害的网站得再加点别的:
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'}
彩蛋:不下载PDF直接读取内容
通过 requests 已经获取了 response 之后,可以通过如下步骤直接使用 pdf 的内容,这样做和下载之后再open是一样的:
import io
import PyPDF2
# 使用 io 模块创建一个 BytesIO 对象,以便将 response.content 传递给 PyPDF2
pdf_file = io.BytesIO(response.content)# 创建一个 PdfFileReader 对象来读取 PDF 文件内容
pdf_reader = PyPDF2.PdfFileReader(pdf_file)# 获取 PDF 文件中的页数
num_pages = pdf_reader.numPages
print("Number of pages:", num_pages)# 逐页提取文本并打印for page_num inrange(num_pages):# 获取页面对象
page = pdf_reader.getPage(page_num)# 提取文本
text = page.extractText()# 打印文本print("Page", page_num +1,":", text.strip())# 关闭 BytesIO 对象
pdf_file.close()
注意一定要用BytesIO,不需要再with open什么东西了。
好的就分享到这里。
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://blog.csdn.net/qq_46106285/article/details/137883196。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。
版权归原作者 shandianchengzi 所有, 如有侵权,请联系我们删除。