
一、用cookie池模拟登录
在网络请求交互中,为了维持用户的登录状态,引入了cookie的概念。当用户第一次登录某个网站时,网站服务器会返回维持登录状态需要用到的信息,这些信息就称为cookie。浏览器会将cookie信息保存在本地计算机中,再次对同一网站发起请求时就会携带上cookie信息,服务器从中可以分析判断出用户的登录状态。
服务器中的资源有些不需要登录就能获取,有些则需要登录才能获取,如果在爬虫程序中携带正确的cookie信息,就可以爬取那些需要登录才能获取的数据了。
1、用浏览器获取cookie信息
代码文件:用浏览器获取cookie信息.py
第一次登录一个网页后,浏览器会从响应头的set-cookie字段中读取cookie值并保存起来。下次访问该网页时,浏览器就会携带cookie值发起请求,服务器从cookie值中得到用户登录信息,就会直接返回用户登录之后的页面。下面以人人网为例讲解如何获取cookie值。
在谷歌浏览器中打开人人网(http://www.renren.com/),输入账号和密码,登录成功后通过开发者工具对数据进行抓包,即在开发者工具的“Network”选项卡下刷新当前页面后选中第一个数据包,在“Headers”选项卡下的“Request Headers”中查看Cookie字段,该字段的值就是发起请求时携带的cookie值,如下图所示。
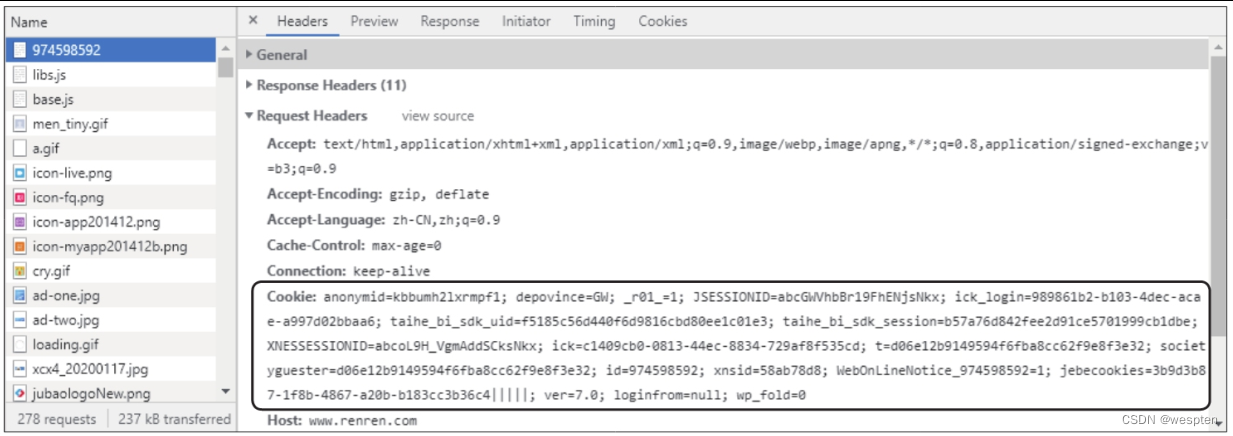
在爬虫程序中使用requests模块的get()函数发起请求时,携带cookie值的方式有两种,下面分别介绍。
第一种方式是在get()函数的参数headers中直接携带cookie值的字符串。
演示代码如下:
1 import requests
2 url = 'http://www.renren.com/974388972/newsfeed/photo'
3 cookie = 'anonymid=kbbumh2lxrmpf1; depovince=GW; _r01_=1; JSESSIONID=abcGWVhbBr19FhENjsNkx; ick_login=989861b2-b103-4dec-acae-a997d02bbaa6; taihe_bi_sdk_uid=f5185c56d440f6d9816cbd80ee1c01e3; taihe_bi_sdk_session=b57a76d842fee2d91ce5701999cb1dbe; XNESSESSIONID=abcoL9H_VgmAddSCksNkx; ick=c1409cb0-0813-44ec-8834-729af8f535cd; t=d06e12b9149594f6fba8cc62f9e8f3e32; societyguester=d06e12b9149594f6fba8cc62f9e8f3e32; id=974598592; xnsid=58ab78d8; WebOnLineNotice_974598592=1; jebecookies=3b9d3b87-1f8b-4867-a20b-b183cc3b36c4|||||; ver=7.0; loginfrom=null; wp_fold=0'
4 headers = {'Cookie': cookie, 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} # 在headers中携带cookie值
5 response = requests.get(url=url, headers=headers).text # 获取页面源代码
6 print(response)
第二种方式是将获取到的cookie值的字符串处理成字典,作为get()函数的参数cookies携带上。
演示代码如下:
1 import requests
2 url = 'http://www.renren.com/974388972/newsfeed/photo'
3 cookie = 'anonymid=kbbumh2lxrmpf1; depovince=GW; _r01_=1; JSESSIONID=abcGWVhbBr19FhENjsNkx; ick_login=989861b2-b103-4dec-acae-a997d02bbaa6; taihe_bi_sdk_uid=f5185c56d440f6d9816cbd80ee1c01e3; taihe_bi_sdk_session=b57a76d842fee2d91ce5701999cb1dbe; XNESSESSIONID=abcoL9H_VgmAddSCksNkx; ick=c1409cb0-0813-44ec-8834-729af8f535cd; t=d06e12b9149594f6fba8cc62f9e8f3e32; societyguester=d06e12b9149594f6fba8cc62f9e8f3e32; id=974598592; xnsid=58ab78d8; WebOnLineNotice_974598592=1; jebecookies=3b9d3b87-1f8b-4867-a20b-b183cc3b36c4|||||; ver=7.0; loginfrom=null; wp_fold=0'
4 headers = {'Cookie': cookie, 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'}
5 cookie_dict = {}
6 for i in cookie.split(';'): # 将cookie值的字符串格式化为字典
7 cookie_keys = i.split('=')[0]
8 cookie_value = i.split('=')[1]
9 cookie_dict[cookie_keys] = cookie_value
10 response = requests.get(url=url, headers=headers, cookies=cookie_dict).text # 将cookie字典作为参数cookies的值,获取页面源代码
11 print(response)
2、自动记录cookie信息
代码文件:自动记录cookie信息.py
上面介绍用浏览器获取cookie信息的方式需要我们自己在数据包中定位cookie信息并提取出来,相对比较烦琐。
这里介绍一种自动记录登录数据的方法:先使用requests模块中的Session对象对一个网站发起登录请求,该对象会记录此次登录用到的cookie信息;再次使用该对象对同一网站的其他页面发起请求时,就会直接使用记录下的cookie信息,不再需要额外携带cookie信息参数了。
演示代码如下:
1 import requests
2 s = requests.Session() # 实例化一个Session对象
3 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'} # 验证浏览器身份的信息
4 data = {'email': '15729560000', 'password': '123456'} # 用于登录网站的账号/密码信息
5 response=s.post(url='http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2020451418538', data=data, headers=headers) # 使用Session对象携带前面设置好的浏览器身份信息和账号/密码信息,对人人网中需要登录的一个页面发起请求
6 print(response.cookies) # 查看cookie值
7 response1 = s.get(url='http://www.renren.com/974388972/profile?v=info_timeline', headers=headers).text # 再次使用Session对象对人人网中另一个需要登录的页面发起请求,Session对象会自动使用上次记录的cookie值,所以这次不需要携带账号/密码信息也能登录成功
8 print(response1) # 获取到需要登录后才能查看的页面的源代码
使用这种方式需要设置登录表单中账号和密码的字段名,也就是第4行代码中的'email'和'password'。使用谷歌浏览器的开发者工具可以提取登录表单中的字段名。
在谷歌浏览器中打开人人网首页,输入账号和密码,打开开发者工具,在“Network”选项卡下勾选“Preserve log”复选框,这样就能在登录跳转时保存登录表单的数据包,单击“登录”按钮,如下图所示。
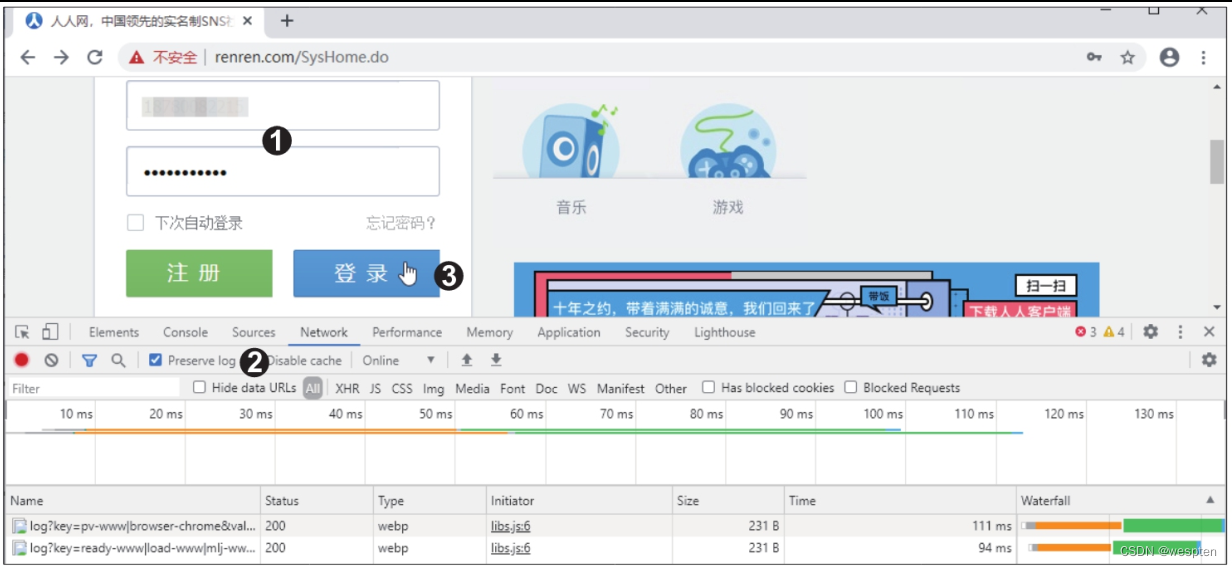
登录成功后,在“Network”选项卡下的“Name”窗格中产生了很多新的数据包,其中就有登录表单的数据包,包名中一般有“login”字样,可在“Filter”筛选器中输入关键词“login”来筛选数据包。
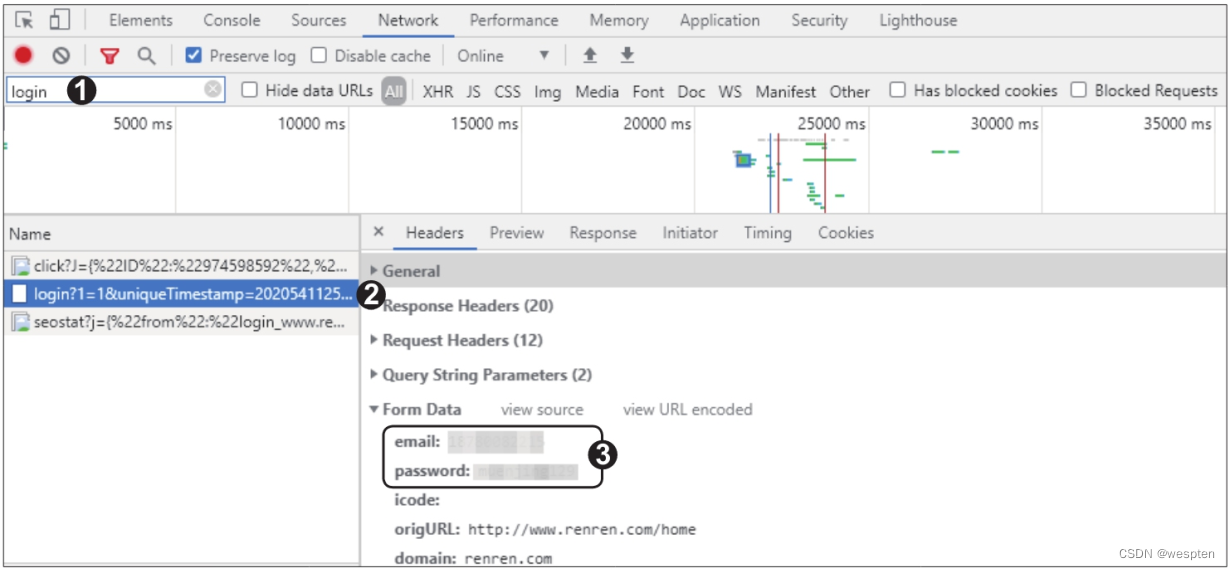
筛选后可在“Name”窗格中看到含有“login”字样的数据包,单击这个包,在“Headers”选项卡下的“Form Data”中可以看到登录时携带的表单信息,一般只需要账号和密码的字段名(这里为“email”和“password”),在发起post请求时携带即可,如下图所示。
二、爬取当当网销售排行榜
代码文件:案例:爬取当当网的图书销售排行榜.py
图书销售排行榜对于出版社编辑制定选题开发方向、图书销售商制定进货计划具有很高的参考价值。实体书店的图书销售排行数据采集难度较大,而电子商务网站的图书销售排行数据则具有真实性高、更新及时、容易获取等优点,是一个相当好的数据来源。
步骤1:先确定需要爬取数据的网址。在谷歌浏览器中打开当当网,进入“图书畅销榜”,网址为http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1。为了增强数据的时效性,选择查看近30日的排行榜数据,发现网址随之变为http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent30-0-0-1-1,该网址显示的是排行榜的第1页内容。
通过观察页面底部的翻页链接可以发现,排行榜共有25页,单击第2页的链接,可以发现网址的最后一个数字变为2,依此类推。根据这一规律,如果要爬取所有页码,只需使用for语句构造循环,按页码依次进行网址的拼接并发起请求即可。
演示代码如下:
1 import requests
2 import pandas as pd
3 from bs4 import BeautifulSoup
4 headers = {'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} # 模拟浏览器的身份验证信息
5 for i in range(1, 26):
6 url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent30-0-0-1-{i}' # 循环生成每一页的网址
步骤2:确定数据是否是动态加载的。打开开发者工具,切换到“Network”选项卡,然后单击“All”按钮,按【F5】键刷新页面,在“Name”窗格中找到主页面的数据包并单击(通常为第一个数据包)。
在“Name”窗格的右侧切换至“Response”选项卡,并在网页源代码的任意处单击,按快捷键【Ctrl+F】调出局部搜索框,输入排行第一的图书名称,如“你当像鸟飞往你的山”,搜索后发现在“Response”选项卡下的网页源代码中有该关键词。这说明数据不是动态加载的,可以用响应对象的text属性获取网页源代码,再从源代码中提取数据。
在步骤1的for语句构造的循环内部继续添加如下代码:
1 response = requests.get(url=url, headers=headers, timeout=10) # 对25页的不同网址循环发起请求,设置超时等待为10秒
2 html_content = response.text # 获取网页源代码
3 soup = BeautifulSoup(html_content, 'lxml') # 将网页源代码实例化为BeautifulSoup对象
4 parse_html(soup) # 调用自定义函数提取BeautifulSoup对象中的数据,该函数的具体代码后面再来编写
5 print(f'第{i}页爬取完毕')
如果用局部搜索找不到关键词,则说明数据是动态加载的,需要携带动态参数发送请求,再使用json()函数提取数据。
步骤3:分析要提取的数据位于哪些标签中。利用开发者工具可看到要提取的排行榜数据位于class属性值为bang_list的
- 标签下的多个
- 标签中,如下图所示。
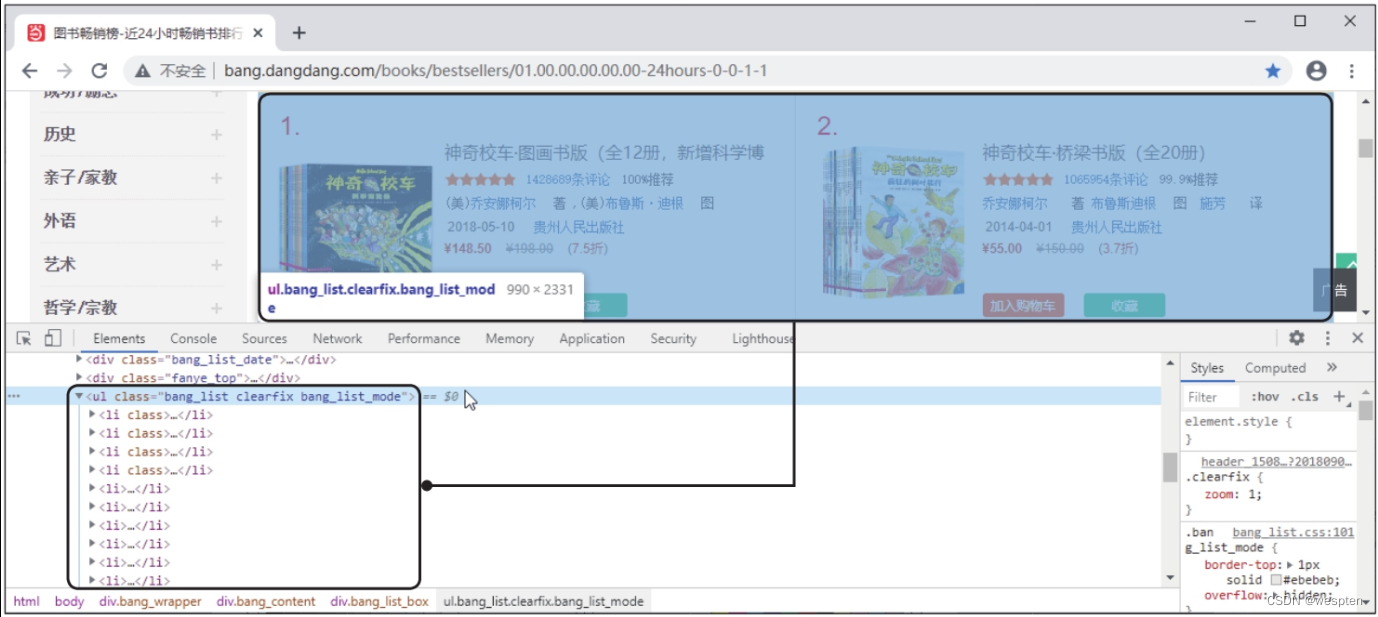
每个
- 标签中存储着一本图书的详细数据,包括排名、书名、作者、出版时间、出版社、价格等。还需要继续利用开发者工具更细致地剖析源代码,定位这些数据所在的标签。具体方法和前面类似,这里就不展开讲解了,留给读者自己练习。
步骤4:编写提取数据的代码。先创建一个字典data_info,然后根据上一步的分析结果编写自定义函数parse_html(),从BeautifulSoup对象中提取数据并添加到字典中。
演示代码如下:
1 data_info = {'图书排名': [], '图书名称': [], '图书作者': [], '图书出版时间': [], '图书出版社': [], '图书价格': []} # 新建一个空字典 2 def parse_html(soup): # 解析每一个BeautifulSoup对象 3 li_list = soup.select('.bang_list li') # 通过层级选择器定位class属性值为bang_list的标签下的所有<li>标签 4 for li in li_list: # 将从每一个<li>标签中解析到的数据添加到字典data_info相应键的对应列表中 5 data_info['图书排名'].append(li.select('.list_num ')[0].text.replace('.', '')) 6 data_info['图书名称'].append(li.select('.name a')[0].text) 7 data_info['图书作者'].append(li.select('.publisher_info ')[0].select('a')[0].text) 8 data_info['图书出版时间'].append(li.select('.publisher_info span')[0].text) 9 data_info['图书出版社'].append(li.select('.publisher_info ')[1].select('a')[0].text) 10 data_info['图书价格'].append(float(li.select('.price .price_n')[0].text.replace('¥', '')))第7、8、9行代码使用层级选择器通过class属性值publisher_info进行标签定位,因为有两个
标签的class属性都是这个值,所以先做列表切片再使用select()函数进行定位,才能获得准确的数据。总体来说,如果多个标签的属性值一样,可以多次使用select()函数进行定位,这样获得的数据更准确。第10行代码是为后面的数据清洗做准备,将“¥”替换为空值(即删除),再用float()函数将字符串转换为浮点型数字,以方便比较数据大小。
需要注意的是,在最终的代码文件中,定义parse_html()函数的代码需位于调用该函数的代码之前。步骤5:缺失值和重复值的处理。获取了每一页的数据并存储到字典data_info中后,还需要进行数据清洗。先用pandas模块将字典转换为DataFrame对象格式,再判断缺失值和重复值。
演示代码如下:
1 book_info = pd.DataFrame(data_info) 2 print(book_info.isnull()) # 缺失值判断 3 print(book_info.duplicated()) # 重复值判断第3行代码中的duplicated()函数用于判断是否有重复行,如果有,则返回True。运行后,结果全为False,说明代码没有问题,获取到的数据也没有重复值和缺失值,接着进行异常值的处理。
步骤6:异常值的处理。假定本案例只研究价格在100元以下的图书,所以需要将价格高于100元的图书删除。
演示代码如下:
1 book_info['图书价格'][book_info['图书价格'] > 100] = None # 将大于100的图书价格替换为空值 2 book_info = book_info.dropna() # 删除有空值的一行数据步骤7:保存爬取的数据。最后,将处理好的数据保存起来,这里存储为csv文件。
演示代码如下:
1 book_info.to_csv('当当网图书销售排行.csv', encoding='utf-8', index=False)三、CSDN数据采集
通过python实现csdn页面的内容采集是相对来说比较容易的,因为csdn不需要登陆,不需要cookie,也不需要设置header。
本案例使用python实现csdn文章数据采集,获取我的博客下每篇文章的链接、标题、阅读数目。
需要安装BeautifulSoup包(点击下载)
python3.6下:
#coding:utf-8 #本实例用于获取指定用户csdn的文章名称、连接、阅读数目 import urllib import re from bs4 import BeautifulSoup #csdn不需要登陆,也不需要cookie,也不需要设置header print('=======================csdn数据挖掘==========================') urlstr="https://blog.csdn.net/qq_35029061?viewmode=contents" host = "https://blog.csdn.net/qq_35029061" #根目录 alllink=[urlstr] #所有需要遍历的网址 data={} def getdata(html,reg): #从字符串中安装正则表达式获取值 pattern = re.compile(reg) items = re.findall(pattern, html) for item in items: urlpath = urllib.parse.urljoin(urlstr,item[0]) #将相对地址,转化为绝对地址 if not hasattr(object, urlpath): data[urlpath] = item print(urlpath,' ', end=' ') #python3中end表示结尾符,这里不换行 print(item[2], ' ', end=' ') print(item[1]) #根据一个网址获取相关连接并添加到集合中 def getlink(url,html): soup = BeautifulSoup(html,'html5lib') #使用html5lib解析,所以需要提前安装好html5lib包 for tag in soup.find_all('a'): #从文档中找到所有<a>标签的内容 link = tag.get('href') newurl = urllib.parse.urljoin(url, link) #在指定网址中的连接的绝对连接 if host not in newurl: # 如果是站外连接,则放弃 continue if newurl in alllink: #不添加已经存在的网址 continue if not "https://blog.csdn.net/qq_35029061/article/list" in newurl: #自定义添加一些链接限制 continue # if not "https://blog.csdn.net/qq_35029061/category_10969287" in newurl: #必须是python类目下的列表 # continue # if not "https://blog.csdn.net/qq_35029061/category_11852875" in newurl: # 必须是K8s类目下的列表 # continue alllink.append(newurl) #将地址添加到链接集合中 #根据一个网址,获取该网址中符合指定正则表达式的内容 def craw(url): try: request = urllib.request.Request(url) #创建一个请求 response = urllib.request.urlopen(request) #获取响应 html = str(response.read(),'utf-8') #读取返回html源码,,python2里面读取的是字节数组 # reg = r'"link_title"><a href="(.*?)">\r\n(.*?)\n.*?</a>' #只匹配文章地址和名称 reg = r'"link_title"><a href="(.*?)">\r\n (.*?) \r\n.*?</a>[\s\S]*?阅读</a>\((.*?)\)</span>' # 匹配地址、名称、阅读数目 getdata(html,reg) getlink(url,html) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) for url in alllink: craw(url)python2.7下:
#coding:utf-8 #本实例用于获取指定用户csdn的文章名称、连接、阅读数目 import urllib2 import re from bs4 import BeautifulSoup #csdn不需要登陆,也不需要cookie,也不需要设置header print('=======================csdn数据挖掘==========================') urlstr="http://blog.csdn.net/luanpeng825485697?viewmode=contents" host = "http://blog.csdn.net/luanpeng825485697" #根目录 alllink=[urlstr] #所有需要遍历的网址 data={} def getdata(html,reg): #从字符串中安装正则表达式获取值 pattern = re.compile(reg) items = re.findall(pattern, html) for item in items: urlpath = urllib2.urlparse.urljoin(urlstr,item[0]) #将相对地址,转化为绝对地址 if not hasattr(object, urlpath): data[urlpath] = item print urlpath,' ', #print最后有个逗号,表示输出不换行 print item[2], ' ', print item[1] #根据一个网址获取相关连接并添加到集合中 def getlink(url,html): soup = BeautifulSoup(html,'html.parser') #使用html5lib解析,所以需要提前安装好html5lib包 for tag in soup.find_all('a'): #从文档中找到所有<a>标签的内容 link = tag.get('href') newurl = urllib2.urlparse.urljoin(url, link) #在指定网址中的连接的绝对连接 if host not in newurl: # 如果是站外连接,则放弃 continue if newurl in alllink: #不添加已经存在的网址 continue if not "http://blog.csdn.net/luanpeng825485697/article/list" in newurl: #自定义添加一些链接限制 continue alllink.append(newurl) #将地址添加到链接集合中 #根据一个网址,获取该网址中符合指定正则表达式的内容 def craw(url): try: request = urllib2.Request(url) #创建一个请求 response = urllib2.urlopen(request) #获取响应 html = response.read() #读取返回html源码 # reg = r'"link_title"><a href="(.*?)">\r\n(.*?)\n.*?</a>' #只匹配文章地址和名称 reg = r'"link_title"><a href="(.*?)">\r\n (.*?) \r\n.*?</a>[\s\S]*?阅读</a>\((.*?)\)</span>' # 匹配地址、名称、阅读数目 getdata(html,reg) getlink(url,html) except urllib2.URLError, e: if hasattr(e,"code"): print e.code if hasattr(e,"reason"): print e.reason for url in alllink: craw(url)四、糗事百科数据采集
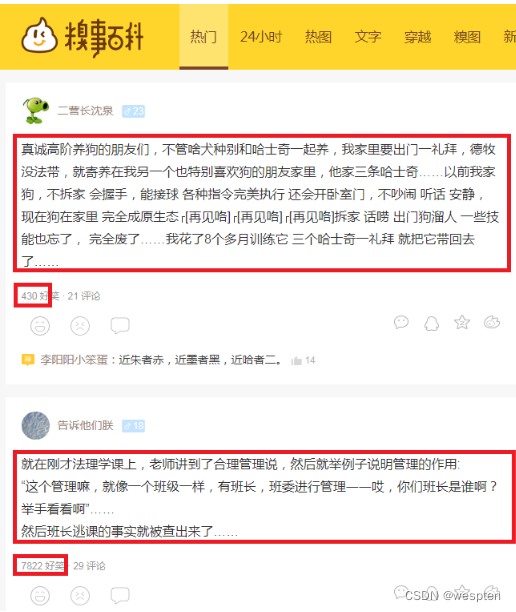
通过python实现糗事百科页面的内容采集是相对来说比较容易的,因为糗事百科不需要登陆,不需要cookie,不过需要设置http的MIME头,模拟浏览器访问才能正常请求
本案例使用python实现糗事百科数据采集,获取糗事百科热门的文章内容和好评数量。
需要安装BeautifulSoup包(点击下载)
python2.7下:
#coding:utf-8 #本实例用于获取糗事百科热门的文章内容和好评数量。 import urllib2 import re from bs4 import BeautifulSoup #糗事百科需要设置MIME头才能正常请求,不需要登陆,也不需要cookie print('=======================糗事百科数据挖掘==========================') urlstr="https://www.qiushibaike.com/8hr/page/%d" data={} def getdata(html): #从字符串中安装正则表达式获取值 soup = BeautifulSoup(html, 'html.parser'); alldiv = soup.find_all("div", class_="content") #内容的外部div allnum = soup.find_all("span", class_="stats-vote") #点赞数量的外部span for i in range(0,len(alldiv)): print str(alldiv[i].find_all('span')[0]).replace('<span>','').replace('</span>','').replace('<br/>','\r\n').strip() #内容文字,使用string在文字里还有<br/>时,无法打印,使用text会省略调用<br/> print allnum[i].find_all('i')[0].string #好评数量 #根据一个网址,获取该网址中符合指定正则表达式的内容 def craw(url): try: user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } #设置MIME头,糗事百科对这个进行了验证 request = urllib2.Request(url,headers = headers) #创建一个请求 response = urllib2.urlopen(request) #获取响应 html = response.read() #读取返回html源码 getdata(html) except urllib2.URLError, e: if hasattr(e,"code"): print e.code if hasattr(e,"reason"): print e.reason for i in range(1,14): url = urlstr % i print(url) craw(url)python3.6下:
#coding:utf-8 #本实例用于获取糗事百科热门的文章内容和好评数量。 import urllib from bs4 import BeautifulSoup #糗事百科需要设置MIME头才能正常请求,不需要登陆,也不需要cookie print('=======================糗事百科数据挖掘==========================') urlstr="https://www.qiushibaike.com/8hr/page/%d" data={} def getdata(html): #从字符串中安装正则表达式获取值 soup = BeautifulSoup(html, 'html.parser'); alldiv = soup.find_all("div", class_="content") #内容的外部div allnum = soup.find_all("span", class_="stats-vote") #点赞数量的外部span for i in range(0,len(alldiv)): print(str(alldiv[i].find_all('span')[0]).replace('<span>','').replace('</span>','').replace('<br/>','\r\n').strip()) #内容文字,使用string在文字里还有<br/>时,无法打印,使用text会省略调用<br/> print(allnum[i].find_all('i')[0].string) #好评数量 #根据一个网址,获取该网址中符合指定正则表达式的内容 def craw(url): try: user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } #设置MIME头,糗事百科对这个进行了验证 request = urllib.request.Request(url,headers = headers) #创建一个请求 response = urllib.request.urlopen(request) #获取响应 html = response.read() #读取返回html源码 getdata(html) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) for i in range(1,14): url = urlstr % i print(url) craw(url)五、百度贴吧数据采集
通过python实现百度贴吧页面的内容采集是相对来说比较容易的,因为百度贴吧不需要登陆,不需要cookie,不需要设置http的MIME头
本案例使用python实现百度贴吧数据采集,获取百度贴吧的文章内容,楼层
百度贴吧网址比如:http://tieba.baidu.com/p/3138733512?see_lz=1&pn=1,这是一个关于NBA50大的盘点,分析一下这个地址。
http:// 代表资源传输使用http协议 tieba.baidu.com 是百度的二级域名,指向百度贴吧的服务器。 /p/3138733512 是服务器某个资源,即这个帖子的地址定位符 see_lz和pn是该URL的两个参数,分别代表了只看楼主和帖子页码,等于1表示该条件为真所以我们可以把URL分为两部分,一部分为基础部分,一部分为参数部分。
例如,上面的URL我们划分基础部分是 http://tieba.baidu.com/p/3138733512,参数部分是 ?see_lz=1&pn=1
爬虫过程比较简单,基本还是围绕:请求、正则解析、打印存储。
注意:python3.4以后中,将urllib2、urlparse、robotparser并入了urllib模块,并且修改了urllib模块,其中包含了5个子模块,每个子模块中的常用方法如下:
python3中的库 包含了子类(python2中) urllib.error: ContentTooShortError;URLError;HTTPError urllib.parse: urlparse;_splitparams;urlsplit;urlunparse;urlunsplit;urljoin;urldefrag;unquote_to_bytes;unquote;parse_qs;parse_qsl;unquote_plus;quote;quote_plus;quote_from_bytes;urlencode;to_bytes;unwrap;splittype;splithost;splituser;splitpasswd;splitport等; urllib.request: urlopen; install_opener; urlretrieve; urlcleanup; request_host; build_opener; _parse_proxy; parse_keqv_list; parse_http_list; _safe_gethostbyname; ftperrors; noheaders; getproxies_environment; proxy_bypass_environment; _proxy_bypass_macosx_sysconf; Request urllib.response: addbase; addclosehook; addinfo;addinfourl; urllib.robotparser: RobotFileParserpython2.7下:
# -*- coding:utf-8 -*- import urllib import urllib2 import re #处理页面标签类 class Tool: #去除img标签,7位长空格 removeImg = re.compile('<img.*?>| {7}|') #删除超链接标签 removeAddr = re.compile('<a.*?>|</a>') #把换行的标签换为\n replaceLine = re.compile('<tr>|<div>|</div>|</p>') #将表格制表<td>替换为\t replaceTD= re.compile('<td>') #把段落开头换为\n加空两格 replacePara = re.compile('<p.*?>') #将换行符或双换行符替换为\n replaceBR = re.compile('<br><br>|<br>') #将其余标签剔除 removeExtraTag = re.compile('<.*?>') def replace(self,x): x = re.sub(self.removeImg,"",x) x = re.sub(self.removeAddr,"",x) x = re.sub(self.replaceLine,"\n",x) x = re.sub(self.replaceTD,"\t",x) x = re.sub(self.replacePara,"\n ",x) x = re.sub(self.replaceBR,"\n",x) x = re.sub(self.removeExtraTag,"",x) #strip()将前后多余内容删除 return x.strip() #百度贴吧爬虫类 class BDTB: #初始化,传入基地址,是否只看楼主的参数 def __init__(self,baseUrl,seeLZ,floorTag): #base链接地址 self.baseURL = baseUrl #是否只看楼主 self.seeLZ = '?see_lz='+str(seeLZ) #HTML标签剔除工具类对象 self.tool = Tool() #全局file变量,文件写入操作对象 self.file = None #楼层标号,初始为1 self.floor = 1 #默认的标题,如果没有成功获取到标题的话则会用这个标题 self.defaultTitle = u"百度贴吧" #是否写入楼分隔符的标记 self.floorTag = floorTag #传入页码,获取该页帖子的代码 def getPage(self,pageNum): try: #构建URL url = self.baseURL+ self.seeLZ + '&pn=' + str(pageNum) request = urllib2.Request(url) response = urllib2.urlopen(request) #返回UTF-8格式编码内容 return response.read().decode('utf-8') #无法连接,报错 except urllib2.URLError, e: if hasattr(e,"reason"): print u"连接百度贴吧失败,错误原因",e.reason return None #获取帖子标题 def getTitle(self,page): #得到标题的正则表达式 pattern = re.compile('<h1 class="core_title_txt.*?>(.*?)</h1>',re.S) result = re.search(pattern,page) if result: #如果存在,则返回标题 return result.group(1).strip() else: return None #获取帖子一共有多少页 def getPageNum(self,page): #获取帖子页数的正则表达式 pattern = re.compile('<li class="l_reply_num.*?</span>.*?<span.*?>(.*?)</span>',re.S) result = re.search(pattern,page) if result: return result.group(1).strip() else: return None #获取每一层楼的内容,传入页面内容 def getContent(self,page): #匹配所有楼层的内容 pattern = re.compile('<div id="post_content_.*?>(.*?)</div>',re.S) items = re.findall(pattern,page) contents = [] for item in items: #将文本进行去除标签处理,同时在前后加入换行符 content = "\n"+self.tool.replace(item)+"\n" contents.append(content.encode('utf-8')) return contents def setFileTitle(self,title): #如果标题不是为None,即成功获取到标题 if title is not None: self.file = open(title + ".txt","w+") else: self.file = open(self.defaultTitle + ".txt","w+") def writeData(self,contents): #向文件写入每一楼的信息 for item in contents: if self.floorTag == '1': #楼之间的分隔符 floorLine = "\n" + str(self.floor) + u"-----------------------------------------------------------------------------------------\n" self.file.write(floorLine) self.file.write(item) self.floor += 1 print(item) def start(self): indexPage = self.getPage(1) pageNum = self.getPageNum(indexPage) title = self.getTitle(indexPage) self.setFileTitle(title) if pageNum == None: print "URL已失效,请重试" return try: print "该帖子共有" + str(pageNum) + "页" for i in range(1,int(pageNum)+1): print "正在写入第" + str(i) + "页数据" page = self.getPage(i) contents = self.getContent(page) self.writeData(contents) #出现写入异常 except IOError,e: print "写入异常,原因" + e.message finally: print "写入任务完成" print u"请输入帖子代号" baseURL = 'http://tieba.baidu.com/p/' + str(raw_input(u'http://tieba.baidu.com/p/')) seeLZ = raw_input("是否只获取楼主发言,是输入1,否输入0\n") floorTag = raw_input("是否写入楼层信息,是输入1,否输入0\n") bdtb = BDTB(baseURL,seeLZ,floorTag) bdtb.start()python3.6下:
# -*- coding:utf-8 -*- import urllib.error import urllib.parse import urllib.request import re #处理页面标签类 class Tool: #去除img标签,7位长空格 removeImg = re.compile('<img.*?>| {7}|') #删除超链接标签 removeAddr = re.compile('<a.*?>|</a>') #把换行的标签换为\n replaceLine = re.compile('<tr>|<div>|</div>|</p>') #将表格制表<td>替换为\t replaceTD= re.compile('<td>') #把段落开头换为\n加空两格 replacePara = re.compile('<p.*?>') #将换行符或双换行符替换为\n replaceBR = re.compile('<br><br>|<br>') #将其余标签剔除 removeExtraTag = re.compile('<.*?>') def replace(self,x): x = re.sub(self.removeImg,"",x) x = re.sub(self.removeAddr,"",x) x = re.sub(self.replaceLine,"\n",x) x = re.sub(self.replaceTD,"\t",x) x = re.sub(self.replacePara,"\n ",x) x = re.sub(self.replaceBR,"\n",x) x = re.sub(self.removeExtraTag,"",x) #strip()将前后多余内容删除 return x.strip() #百度贴吧爬虫类 class BDTB: #初始化,传入基地址,是否只看楼主的参数 def __init__(self,baseUrl,seeLZ,floorTag): #base链接地址 self.baseURL = baseUrl #是否只看楼主 self.seeLZ = '?see_lz='+str(seeLZ) #HTML标签剔除工具类对象 self.tool = Tool() #全局file变量,文件写入操作对象 self.file = None #楼层标号,初始为1 self.floor = 1 #默认的标题,如果没有成功获取到标题的话则会用这个标题 self.defaultTitle = u"百度贴吧" #是否写入楼分隔符的标记 self.floorTag = floorTag #传入页码,获取该页帖子的代码 def getPage(self,pageNum): try: #构建URL url = self.baseURL+ self.seeLZ + '&pn=' + str(pageNum) request = urllib.request.Request(url) response = urllib.request.urlopen(request) #返回UTF-8格式编码内容 return response.read().decode('utf-8') #无法连接,报错 except urllib.error.URLError as e: if hasattr(e,"reason"): print(u"连接百度贴吧失败,错误原因",e.reason) return None #获取帖子标题 def getTitle(self,page): #得到标题的正则表达式 pattern = re.compile('<h1 class="core_title_txt.*?>(.*?)</h1>',re.S) result = re.search(pattern,page) if result: #如果存在,则返回标题 return result.group(1).strip() else: return None #获取帖子一共有多少页 def getPageNum(self,page): #获取帖子页数的正则表达式 pattern = re.compile('<li class="l_reply_num.*?</span>.*?<span.*?>(.*?)</span>',re.S) result = re.search(pattern,page) if result: return result.group(1).strip() else: return None #获取每一层楼的内容,传入页面内容 def getContent(self,page): #匹配所有楼层的内容 pattern = re.compile('<div id="post_content_.*?>(.*?)</div>',re.S) items = re.findall(pattern,page) contents = [] for item in items: #将文本进行去除标签处理,同时在前后加入换行符 content = "\n"+self.tool.replace(item)+"\n" contents.append(content.encode('utf-8')) return contents def setFileTitle(self,title): #如果标题不是为None,即成功获取到标题 if title is not None: self.file = open(title + ".txt","w+") else: self.file = open(self.defaultTitle + ".txt","w+") def writeData(self,contents): #向文件写入每一楼的信息 for item in contents: if self.floorTag == '1': #楼之间的分隔符 floorLine = "\n" + str(self.floor) + u"-----------------------------------------------------------------------------------------\n" self.file.write(floorLine) self.file.write(str(item,'utf-8')) self.floor += 1 print(str(item,'utf-8')) def start(self): indexPage = self.getPage(1) pageNum = self.getPageNum(indexPage) title = self.getTitle(indexPage) self.setFileTitle(title) if pageNum == None: print("URL已失效,请重试") return try: print("该帖子共有" + str(pageNum) + "页") for i in range(1,int(pageNum)+1): print("正在写入第" + str(i) + "页数据") page = self.getPage(i) contents = self.getContent(page) self.writeData(contents) #出现写入异常 except IOError as e: print("写入异常,原因" + e.message) finally: print("写入任务完成") print("请输入帖子代号") baseURL = 'http://tieba.baidu.com/p/' + str(input(u'http://tieba.baidu.com/p/')) seeLZ = input("是否只获取楼主发言,是输入1,否输入0\n") floorTag = input("是否写入楼层信息,是输入1,否输入0\n") bdtb = BDTB(baseURL,seeLZ,floorTag) bdtb.start()六、爬取西刺免费代理服务器IP等信息
在使用python爬取网络数据时,网络需要设置代理服务器,防止目标网站对IP的限制。
http://www.xicidaili.com/
网站实现了众多可以使用的代理服务器,这里写了一个爬虫,爬取其中 国内高匿代理IP。使用python3.6环境:
#coding:utf-8 #本实例用于获取国内高匿免费代理服务器 import urllib from bs4 import BeautifulSoup def getdata(html): #从字符串中安装正则表达式获取值 allproxy = [] # 所有的代理服务器信息 soup = BeautifulSoup(html, 'html.parser') alltr = soup.find_all("tr", class_="")[1:] #获取tr ,第一个是标题栏,去除 for tr in alltr: alltd =tr.find_all('td') oneproxy ={ 'IP地址':alltd[1].get_text(), '端口号': alltd[2].get_text(), # '服务器地址': alltd[3].a.get_text(), '是否匿名': alltd[4].get_text(), '类型': alltd[5].get_text(), '速度': alltd[6].div['title'], '连接时间': alltd[7].div['title'], '存活时间': alltd[8].get_text(), '验证时间': alltd[9].get_text(), } allproxy.append(oneproxy) alltr = soup.find_all("tr", class_="odd")[1:] # 获取tr ,第一个是标题栏,去除 for tr in alltr: alltd = tr.find_all('td') oneproxy = { 'IP地址': alltd[1].get_text(), '端口号': alltd[2].get_text(), # '服务器地址': alltd[3].a.get_text(), '是否匿名': alltd[4].get_text(), '类型': alltd[5].get_text(), '速度': alltd[6].div['title'], '连接时间': alltd[7].div['title'], '存活时间': alltd[8].get_text(), '验证时间': alltd[9].get_text(), } allproxy.append(oneproxy) return allproxy #根据一个网址,获取该网址中符合指定正则表达式的内容 def getallproxy(url='http://www.xicidaili.com/nn'): try: # 构造 Request headers agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER' headers = { # 这个http头,根据审查元素,监听发包,可以查看 "Host": "www.xicidaili.com", "Referer": "http://www.xicidaili.com/", 'User-Agent': agent } request = urllib.request.Request(url, headers=headers) # 创建一个请求 response = urllib.request.urlopen(request) # 获取响应 html = response.read() #读取返回html源码 return getdata(html) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) return [] # allproxy = getallproxy() # print(allproxy)七、根据网址爬取中文网站
获取标题、子连接、子连接数目、连接描述、中文分词列表。
其中使用到了urllib、BeautifulSoup爬虫和结巴中文分词的相关知识。
调试环境python3.6:
# 根据连接爬取中文网站,获取标题、子连接、子连接数目、连接描述、中文分词列表, import urllib from bs4 import BeautifulSoup import bs4 import jieba #对中文进行分词 # 分词时忽略下列词 ignorewords=[',','。','?','“','”','!',';',':','\n','、','-',',','.','?','\r\n','_',' '] # 定义爬虫类。获取链接的题目、描述、分词、深度 class crawler: def __init__(self,url): self.url = url self.urls={} self.urls[url]={ 'num':1, #连接被引用的次数 'title':'', #连接的标题 'text':'', #连接的描述 'allword':[], #连接的所有分词列表 } def getword(self,soup): # 获取每个单词 text=self.gettextonly(soup) #提取所有显示出来的文本 words=self.separatewords(text) #使用分词器进行分词 allword=[] for word in words: if word not in ignorewords: allword.append(word) # print(allword) return allword # 根据一个网页源代码提取文字(不带标签的)。由外至内获取文本元素。style和script内不要 def gettextonly(self,soup): v=soup.string if v==None: c=soup.contents # 直接子节点的列表,将<tag>所有儿子节点存入列表 resulttext='' for t in c: if t.name=='style' or t.name=='script': #当元素为style和script和None时不获取内容 continue subtext=self.gettextonly(t) resulttext+=subtext+'\n' return resulttext else: if isinstance(v,bs4.element.Comment): #代码中的注释不获取 return '' return v.strip() # 利用正则表达式提取单词(不能区分中文)。会将任何非字母非数字字符看做分隔符 def separatewords(self,text): seg_list = jieba.cut(text, cut_all=False) #使用结巴进行中文分词 return seg_list # splitter=re.compile('\\W*') # return [s.lower() for s in splitter.split(text) if s!=''] #爬虫主函数 def crawl(self): try: response=urllib.request.urlopen(self.url) except: print("Could not open %s" % self.url) return try: text = str(response.read(),encoding='utf-8') soup=BeautifulSoup(text,'html.parser') title = soup.title self.urls[self.url]['title'] = title.get_text() # 将标题加入到属性中 links=soup('a') for link in links: if ('href' in dict(link.attrs)): newurl=urllib.parse.urljoin(self.url,link['href']) if newurl.find("'")!=-1: continue newurl=newurl.split('#')[0] # 去掉位置部分 if newurl[0:4]=='http': if newurl not in self.urls: linkText = self.gettextonly(link) #获取连接的描述 self.urls[newurl]={ 'num':1, #连接被引用的次数 'text':linkText #链接描述 } else: self.urls[newurl]['num']+=1 #连接数+1,这里有算法只算一次 allword = self.getword(soup.body) # 获取分词 self.urls[self.url]['allword'] = allword # 将分词加入到属性中 except: print("Could not parse page %s" % self.url) if __name__ == '__main__': url='http://blog.csdn.net/luanpeng825485697/article/details/78378653' mycrawler = crawler(url) mycrawler.crawl() print(mycrawler.urls[url]['allword'])八、爬取百度新闻RSS数据
各RSS网站参考http://blog.csdn.net/luanpeng825485697/article/details/78737510
今天我们使用python3.6来爬去百度新闻RSS中的数据,有了数据集,这样可以对样本数据集进行分类、聚类、推荐算法的学习
调试环境python3.6:
# 获取百度新闻数据集 import urllib import re from bs4 import BeautifulSoup import json import io feedlist=[ 'http://news.baidu.com/n?cmd=1&class=civilnews&tn=rss&sub=0', #国内焦点 'http://news.baidu.com/n?cmd=1&class=shizheng&tn=rss&sub=0', #时政焦点 'http://news.baidu.com/n?cmd=1&class=gangaotai&tn=rss&sub=0', #港澳台焦点 'http://news.baidu.com/n?cmd=1&class=internews&tn=rss&sub=0', #国际焦点 'http://news.baidu.com/n?cmd=1&class=mil&tn=rss&sub=0', #军事焦点 'http://news.baidu.com/n?cmd=1&class=hqsy&tn=rss&sub=0', #环球视野焦点 'http://news.baidu.com/n?cmd=1&class=finannews&tn=rss&sub=0', #财经焦点 'http://news.baidu.com/n?cmd=1&class=stock&tn=rss&sub=0', #股票焦点 'http://news.baidu.com/n?cmd=1&class=money&tn=rss&sub=0', #理财焦点 'http://news.baidu.com/n?cmd=1&class=financialnews&tn=rss&sub=0', #金融观察焦点 'http://news.baidu.com/n?cmd=1&class=internet&tn=rss&sub=0', #互联网焦点 'http://news.baidu.com/n?cmd=1&class=rwdt&tn=rss&sub=0', #人物动态焦点 'http://news.baidu.com/n?cmd=1&class=gsdt&tn=rss&sub=0', #公司动态焦点 'http://news.baidu.com/n?cmd=1&class=housenews&tn=rss&sub=0', #房产焦点 'http://news.baidu.com/n?cmd=1&class=gddt&tn=rss&sub=0', #各地动态焦点 'http://news.baidu.com/n?cmd=1&class=zcfx&tn=rss&sub=0', #政策风向焦点 'http://news.baidu.com/n?cmd=1&class=fitment&tn=rss&sub=0', #家居焦点 'http://news.baidu.com/n?cmd=1&class=autonews&tn=rss&sub=0', #汽车焦点 'http://news.baidu.com/n?cmd=1&class=autobuy&tn=rss&sub=0', #新车导购焦点 'http://news.baidu.com/n?cmd=1&class=autoreview&tn=rss&sub=0', #试驾焦点 'http://news.baidu.com/n?cmd=1&class=sportnews&tn=rss&sub=0', #体育焦点 'http://news.baidu.com/n?cmd=1&class=nba&tn=rss&sub=0', #NBA焦点 'http://news.baidu.com/n?cmd=1&class=worldsoccer&tn=rss&sub=0', #国际足球焦点 'http://news.baidu.com/n?cmd=1&class=chinasoccer&tn=rss&sub=0', #国内足球焦点 'http://news.baidu.com/n?cmd=1&class=cba&tn=rss&sub=0', #国内篮球焦点 'http://news.baidu.com/n?cmd=1&class=othersports&tn=rss&sub=0', #综合体育焦点 'http://news.baidu.com/n?cmd=1&class=olympic&tn=rss&sub=0', #奥运焦点 'http://news.baidu.com/n?cmd=1&class=enternews&tn=rss&sub=0', #娱乐焦点 'http://news.baidu.com/n?cmd=1&class=star&tn=rss&sub=0', #明星焦点 'http://news.baidu.com/n?cmd=1&class=film&tn=rss&sub=0', #电影焦点 'http://news.baidu.com/n?cmd=1&class=tv&tn=rss&sub=0', #电视焦点 'http://news.baidu.com/n?cmd=1&class=music&tn=rss&sub=0', #音乐焦点 'http://news.baidu.com/n?cmd=1&class=gamenews&tn=rss&sub=0', #游戏焦点 'http://news.baidu.com/n?cmd=1&class=netgames&tn=rss&sub=0', #网络游戏焦点 'http://news.baidu.com/n?cmd=1&class=tvgames&tn=rss&sub=0', #电视游戏焦点 'http://news.baidu.com/n?cmd=1&class=edunews&tn=rss&sub=0', #教育焦点 'http://news.baidu.com/n?cmd=1&class=exams&tn=rss&sub=0', #考试焦点 'http://news.baidu.com/n?cmd=1&class=abroad&tn=rss&sub=0', #留学焦点 'http://news.baidu.com/n?cmd=1&class=healthnews&tn=rss&sub=0', #健康焦点 'http://news.baidu.com/n?cmd=1&class=baojian&tn=rss&sub=0', #保健养生焦点 'http://news.baidu.com/n?cmd=1&class=yiyao&tn=rss&sub=0', #寻医问药焦点 'http://news.baidu.com/n?cmd=1&class=technnews&tn=rss&sub=0', #科技焦点 'http://news.baidu.com/n?cmd=1&class=mobile&tn=rss&sub=0', #手机焦点 'http://news.baidu.com/n?cmd=1&class=digi&tn=rss&sub=0', #数码焦点 'http://news.baidu.com/n?cmd=1&class=computer&tn=rss&sub=0', #电脑焦点 'http://news.baidu.com/n?cmd=1&class=discovery&tn=rss&sub=0', #科普焦点 'http://news.baidu.com/n?cmd=1&class=socianews&tn=rss&sub=0', #社会焦点 'http://news.baidu.com/n?cmd=1&class=shyf&tn=rss&sub=0', #社会与法焦点 'http://news.baidu.com/n?cmd=1&class=shwx&tn=rss&sub=0', #社会万象焦点 'http://news.baidu.com/n?cmd=1&class=zqsk&tn=rss&sub=0', #真情时刻焦点 ] def getrss1(feedlist): for url in feedlist: info={} info[url]={ 'title':'', 'allitem':[] } try: response=urllib.request.urlopen(url) text = str(response.read(), encoding='utf-8') soup = BeautifulSoup(text, 'lxml') title = soup.title info[url]['title']=title for item in soup('item'): try: print(item) suburl={ 'title':item('title').replace(']]>','').replace('<![CDATA[',''), 'link': item('link').replace(']]>', '').replace('<![CDATA[', ''), 'source': item('source').replace(']]>', '').replace('<![CDATA[', ''), 'text': item('description').get_text().replace(']]>',''), 'type':title } print(suburl) info[url]['allitem'].append(suburl) except: print('无法匹配'+item) except: print("error: %s" % url) def getrss(feedlist): rss = {} for url in feedlist: rss[url] = { 'title': '', 'allitem': [] } try: response = urllib.request.urlopen(url) text = str(response.read(), encoding='utf-8') soup = BeautifulSoup(text, 'lxml') title = soup.title.get_text() rss[url]['title'] = title patterstr = r'<item>.*?' \ r'<title>(.*?)</title>.*?' \ r'<link>(.*?)</link>.*?' \ r'<source>(.*?)</source>.*?' \ r'<description>.*?<br>(.*?)<br.*?' \ r'</item>' pattern = re.compile(patterstr,re.S) #使用多行模式 results = re.findall(pattern, text) #如何查询多次 if results!=None or len(results)==0: for result in results: suburl = { 'title': result[0].replace(']]>', '').replace('<![CDATA[', ''), 'link': result[1].replace(']]>', '').replace('<![CDATA[', ''), 'source': result[2].replace(']]>', '').replace('<![CDATA[', ''), 'text': result[3].replace(']]>', ''), 'type': title } print(suburl) rss[url]['allitem'].append(suburl) except: print("error: %s" % url) return rss # 形成一个文本描述和分类的数据集。 if __name__ == '__main__': rss = getrss(feedlist) jsonstr = json.dumps(rss,ensure_ascii=False) f = io.open('rss.json', 'w', encoding='utf-8') f.writelines(jsonstr) f.close()九、多线程+队列:爬取某网站所有图片
实现思路:
- **download_image(url, image_dir, image_no)**:将图片下载页的主图下载到本地。
- **get_image_url(url)**:拼接图片下载的 url(绝对路径)。由于网站中的图片 src 都是相对路径,因此需要在此函数中拼接图片的绝对路径。
- **get_page_url(url)**:获取图片浏览页中的图片下载页 url 和翻页 url。
- **task(queue)**:多线程的任务函数,调用上述 3 个函数。
代码:
下载地址:https://github.com/juno3550/Crawler
import requests import re import os import threading import queue # Python的queue模块中提供了同步的、线程安全的队列类 from bs4 import BeautifulSoup import traceback # 队列,用来存放图片下载页url和翻页url queue = queue.Queue() # 种子url result_urls = [] # 图片命名的起始编号 image_no = 0 # 图片存储路径 image_dir = "e:\\crawl_image" if not os.path.exists(image_dir): os.makedirs(image_dir) # 将图片下载到本地 def download_image(url, image_dir, image_no): try: # 访问图片并设置超时时间 r = requests.get(url, timeout=60) # 获取图片的后缀名 image_ext = url.split(".")[-1] # 设置下载路径与图片名称 image_name = str(image_no) + "." + image_ext image_path = os.path.join(image_dir, image_name) # 保存图片到本地 with open(image_path, "wb") as f: f.write(r.content) print("图片【%s】下载成功,保存路径【%s】" % (url, image_path)) except: print("图片下载失败【%s】" % url) traceback.print_exc() # 获取图片下载url(绝对路径) def get_image_url(url): # 由于网站中的图片url都是相对路径,因此需要在此函数中拼接图片的绝对路径 # 获取网站首页链接 try: home_page = re.match(r"http[s]?://\w+.\w+\.com", url).group() r = requests.get(url, timeout=60) r.encoding = "gbk" # 通过a标签获取其中的src下载路径 # 通过BeautifulSoup解析网页内容 soup = BeautifulSoup(r.text, "html.parser") image_a = soup.find_all("a", attrs={"id": "img"}) # 找出id属性值为img的a标签,即主图 if image_a: # 获得图片的相对路径 image_relative_url = re.search(r'src="(.+?)"', str(image_a[0])).group(1) # 拼接绝对路径 image_abs_url = home_page + image_relative_url return image_abs_url except: print("获取图片下载url失败【%s】" % url) traceback.print_exc() # 获取图片浏览页中的图片下载页url和翻页url def get_page_url(url): try: home_page = re.match(r"http[s]?://\w+.\w+\.com", url).group() r = requests.get(url, timeout=60) r.encoding = "gbk" soup = BeautifulSoup(r.text, "html.parser") # 存储所有图片的a标签跳转url及翻页url image_page_urls = [] image_a_lists = soup.find_all("a") for image_a in image_a_lists: # 获取a标签中的相对url relative_url = image_a["href"] # 根据url特征,只需要图片跳转页url和翻页url if relative_url.startswith("/tupian") and relative_url.endswith(".html") or "/index_" in relative_url: # 拼接绝对路径 image_or_index_abs_url = home_page + relative_url image_page_urls.append(image_or_index_abs_url) return image_page_urls except: print("获取图片下载页url和翻页url失败【%s】" % url) traceback.print_exc() # 任务函数 def task(queue): global result_urls global image_dir global image_no while not queue.empty(): url = queue.get() try: # 如果该页为主图页,则下载图片 image_download_url = get_image_url(url) if image_download_url and image_download_url not in result_urls: image_no += 1 # 下载图片到本地 download_image(image_download_url, image_dir, image_no) result_urls.append(image_download_url) except: traceback.print_exc() try: # 获取图片下载页url和翻页url,加入队列中 image_page_urls = get_page_url(url) while image_page_urls: image_page_url = image_page_urls.pop() if image_page_url not in result_urls: queue.put(image_page_url) result_urls.append(image_page_url) except: traceback.print_exc() if __name__ == "__main__": # 将种子页面放入队列中 image_resource_url = "http://pic.netbian.com" queue.put(image_resource_url) # 开启100个线程,执行任务函数 t_list = [] for i in range(100): t = threading.Thread(target=task, args=(queue,)) t_list.append(t) t.start() # 等待所有子线程结束后,主线程才结束 for t in t_list: t.join()执行结果:

十、多线程+队列+入库:根据关键字筛选爬取网页
实现思路:
多线程爬取网页信息,从一个页面为起点,爬取其包含的所有链接,并根据关键字筛选,将符合的网页入库。
- 访问首页(种子页),获取源码 html;
- 使用正则或者其他方式获取所有的绝对地址链接,存到一个 list 里面;
- 遍历 list,加入到队列中;
- 多线程从队列中取数据,一次取一个绝对地址链接,并重复上面 1-3 步。
代码:
下载地址:https://github.com/juno3550/Crawler
- MysqlTool 类:将 mysql 的初始化及操作进行封装。
- **get_page_message()**:获取当前网页的所需信息(标题、正文、包含的所有链接)。
- **get_html()**:多线程任务函数,将包含关键字的当前页面进行入库,并将包含的所有链接放入队列中,以此循环。
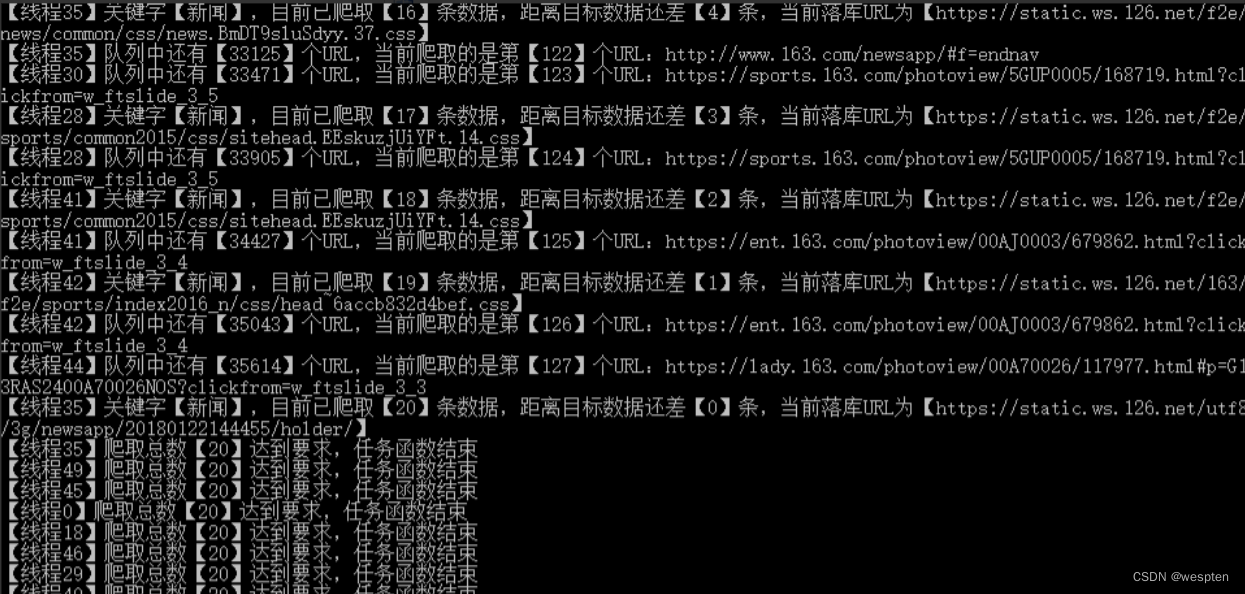
import requests import re from threading import Thread, Lock import queue import pymysql import traceback import time # 线程同步锁 lock = Lock() queue = queue.Queue() # 设定需要爬取的网页数 crawl_num = 20 # 存储已爬取的url result_urls = [] # 当前已爬取的网页个数 current_url_count = 0 # 爬取的关键字 key_word = "新闻" # mysql操作封装 class MysqlTool(): def __init__(self, host, port, db, user, passwd, charset="utf8"): self.host = host self.port = port self.db = db self.user = user self.passwd = passwd self.charset = charset def connect(self): '''创建数据库连接与执行对象''' try: self.conn = pymysql.connect(host=self.host, port=self.port, db=self.db, user=self.user, passwd=self.passwd, charset=self.charset) self.cursor = self.conn.cursor() except Exception as e: print(e) def close(self): '''关闭数据库连接与执行对象''' try: self.cursor.close() self.conn.close() except Exception as e: print(e) def __edit(self, sql): '''增删改查的私有方法''' try: execute_count = self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) else: return execute_count def insert(self, sql): '''插入数据''' self.connect() self.__edit(sql) self.close() # 获取URL的所需信息 def get_page_message(url): try: if ".pdf" in url or ".jpg" in url or ".jpeg" in url or ".png" in url or ".apk" in url or "microsoft" in url: return r = requests.get(url, timeout=5) # 获取该URL的源码内容 page_content = r.text # 获取页面标题 page_title = re.search(r"<title>(.+?)</title>", page_content).group(1) # 使用正则提取该URL中的所有URL page_url_list = re.findall(r'href="(http.+?)"', page_content) # 过滤图片、pdf等链接 # 获取URL中的正文内容 page_text = "".join(re.findall(r"<p>(.+?)</p>", page_content)) # 将正文中的标签去掉 page_text = "".join(re.split(r"<.+?>", page_text)) # 将正文中的双引号改成单引号,以防落库失败 page_text = page_text.replace('"', "'") return page_url_list, page_title, page_text except: print("获取URL所需信息失败【%s】" % url) traceback.print_exc() # 任务函数:获取本url中的所有链接url def get_html(queue, lock, mysql, key_word, crawl_num, threading_no): global current_url_count try: while not queue.empty(): # 已爬取的数据量达到要求,则结束爬虫 lock.acquire() if len(result_urls) >= crawl_num: print("【线程%d】爬取总数【%d】达到要求,任务函数结束" % (threading_no, len(result_urls))) lock.release() return else: lock.release() # 从队列中获取url url = queue.get() lock.acquire() current_url_count += 1 lock.release() print("【线程%d】队列中还有【%d】个URL,当前爬取的是第【%d】个URL:%s" % (threading_no, queue.qsize(), current_url_count, url)) # 判断url是否已爬取过,以防止重复落库 if url not in result_urls: page_message = get_page_message(url) page_url_list = page_message[0] page_title = page_message[1] page_text = page_message[2] if not page_message: continue # 将源码中的所有URL放到队列中 while page_url_list: url = page_url_list.pop() lock.acquire() if url not in result_urls: queue.put(url.strip()) lock.release() # 标题或正文包含关键字,才会入库 if key_word in page_title or key_word in page_text: lock.acquire() if not len(result_urls) >= crawl_num: sql = 'insert into crawl_page(url, title, text) values("%s", "%s", "%s")' % (url, page_title, page_text) mysql.insert(sql) result_urls.append(url) print("【线程%d】关键字【%s】,目前已爬取【%d】条数据,距离目标数据还差【%d】条,当前落库URL为【%s】" % (threading_no, key_word, len(result_urls), crawl_num-len(result_urls), url)) lock.release() else: # 已爬取的数据量达到要求,则结束爬虫 print("【线程%d】爬取总数【%d】达到要求,任务函数结束" % (threading_no, len(result_urls))) lock.release() return print("【线程%d】队列为空,任务函数结束" % threading_no) except: print("【线程%d】任务函数执行失败" % threading_no) traceback.print_exc() if __name__ == "__main__": # 爬取的种子页 home_page_url = "https://www.163.com" queue.put(home_page_url) mysql = MysqlTool("127.0.0.1", 3306, "test", "root", "admin") t_list = [] for i in range(50): t = Thread(target=get_html, args=(queue, lock, mysql, key_word, crawl_num, i)) time.sleep(0.05) t.start() t_list.append(t) for t in t_list: t.join()执行结果:
十一、量化金融案例
量化金融是目前比较热门的一个多学科跨界融合领域,它综合运用金融知识、数学和统计知识、计算机信息技术来解决金融问题。
主要介绍Python在量化金融中的应用,包括股票数据的爬取、分析和可视化。
1、案例介绍
本案例涵盖了量化金融的以下几个方面:
- 大数据采集:通过爬虫获取特定行业(如汽车行业)股票的基本信息,并获取单只股票的历史行情数据。
- 大数据存储:根据自定义的时间间隔定时获取涨幅前60名股票的实时行情数据,并存储在数据库中。
- 大数据分析:计算股票的月涨跌幅,对股票进行相关性分析,并预测股票行情的未来走势。
2、获取汽车行业股票的基本信息
代码文件:获取汽车行业股票的股票代码和股票名称.py、
获取汽车行业股票的上市日期.py
要获取汽车行业股票的基本信息,包括股票代码、股票名称、上市日期。股票代码和股票名称从东方财富网爬取,上市日期则利用Tushare模块获取。
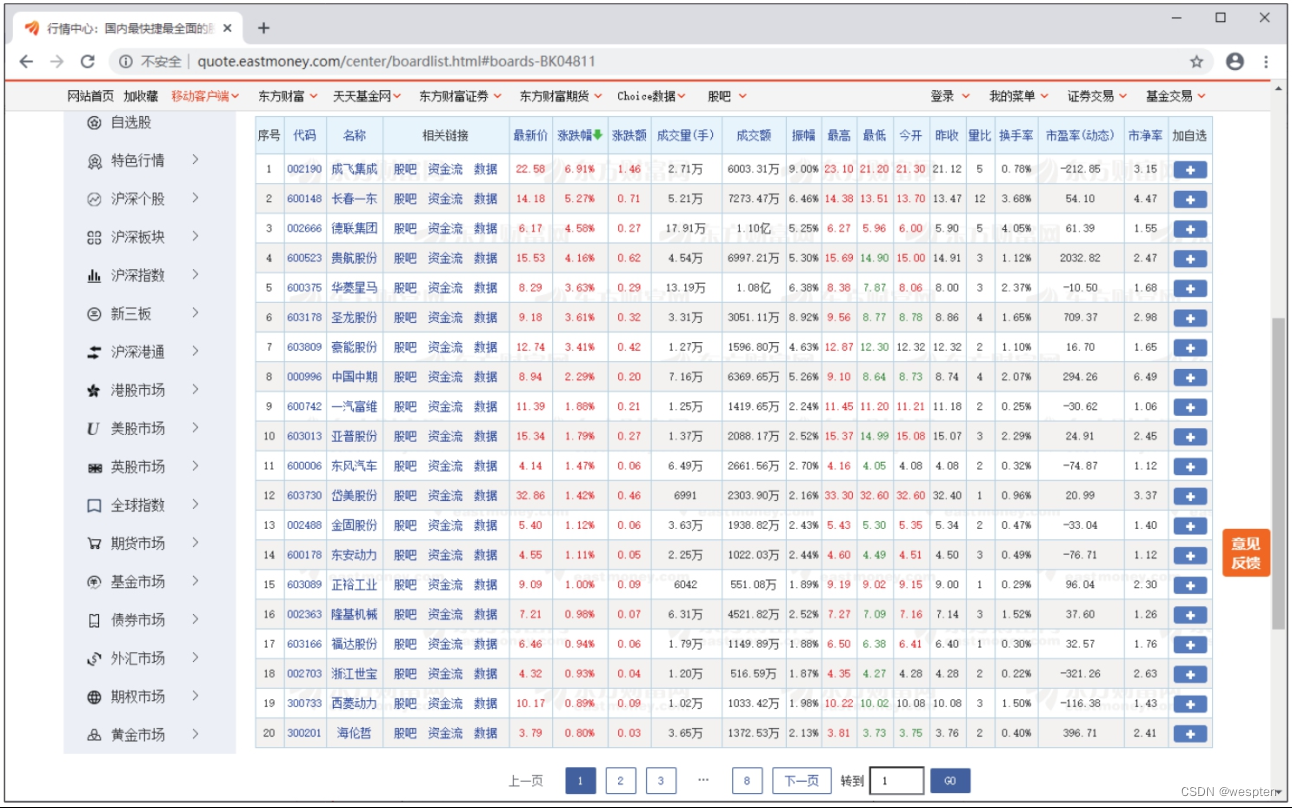
步骤1:首先确定爬取方案。在浏览器中打开东方财富网的汽车行业股票行情页面,网址为http://quote.eastmoney.com/center/boardlist.html#boards-BK04811。可以看到股票信息展示页面共8页,如下图所示。单击“下一页”按钮,发现网页并没有整体刷新,但是股票信息展示区的数据却刷新了,说明这部分数据是动态加载的,且页面使用的是局部刷新技术,因此,数据要么存储在JSON格式数据包中,要么存储在JS(JavaScript)文件中。
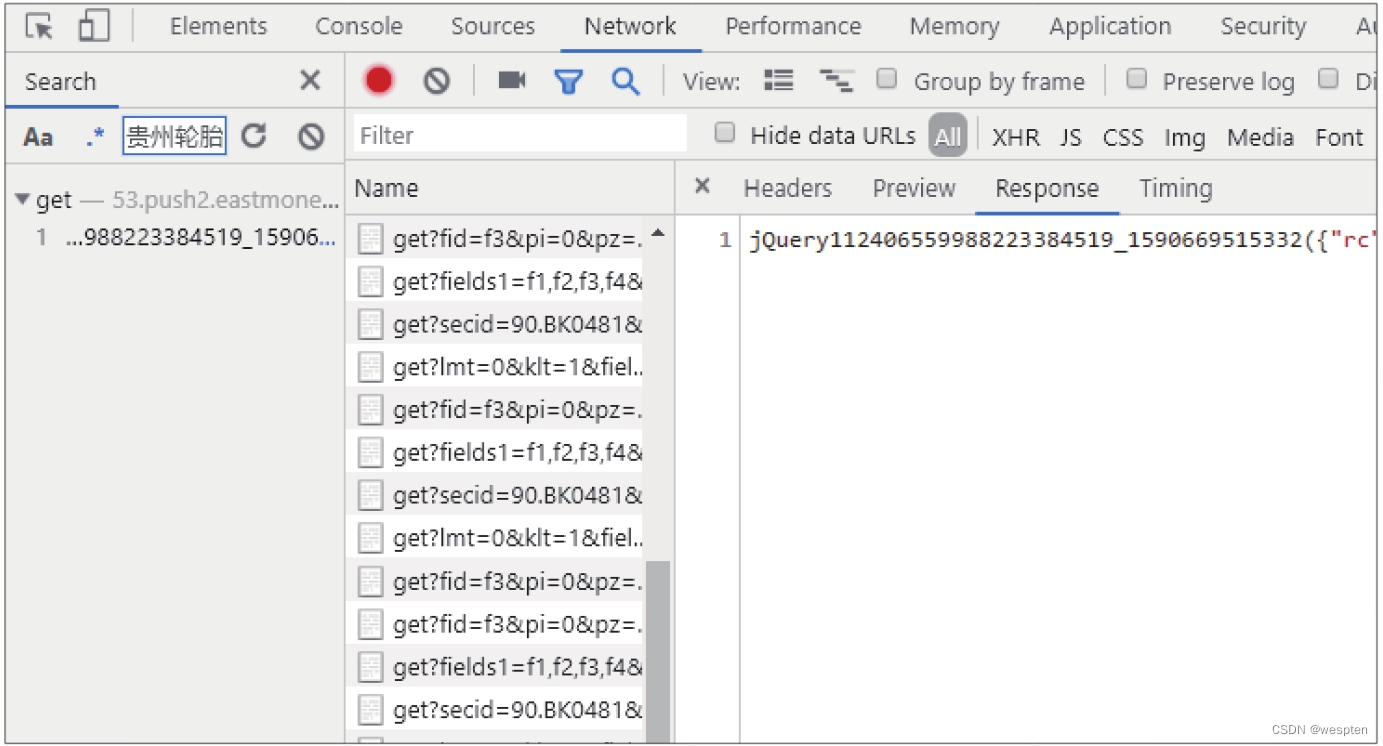
使用开发者工具进行全局搜索和数据定位,如搜索股票名称关键词“贵州轮胎”,会定位到一个JS文件,如下图所示。选择其他页码中的股票名称作为关键词进行搜索,则会定位到另一个JS文件。由此可知,每一页数据存储在不同的JS文件中。
针对这种情况,可以使用requests模块发起携带动态参数的请求来获取数据,也可以使用Selenium模块模拟用户操作来获取数据。后一种方法更方便,所以这里使用后一种方法。
步骤2:Selenium模块所起的作用主要是模拟用户操作浏览器对指定页面发起请求,并依次单击“下一页”按钮,从而获取所有页面的股票信息。
(1)向页面发起请求
实例化一个浏览器对象,对汽车行业股票行情页面发起请求。
代码如下:
1 from selenium import webdriver 2 import time 3 import pandas as pd 4 browser = webdriver.Chrome(executable_path='chromedriver.exe') # 实例化浏览器对象 5 url = 'http://quote.eastmoney.com/center/boardlist.html#boards-BK04811' 6 browser.get(url) # 对指定页面发起请求(2)获取单个页面的股票信息
先用开发者工具查看股票信息在网页源代码中的位置,可以发现表格数据存储在一个id属性值为table_wrapper-table的
标签中,股票代码在每一个
标签下的第2个 标签中,股票名称在每一个 标签下的第3个 标签中,如下图所示。 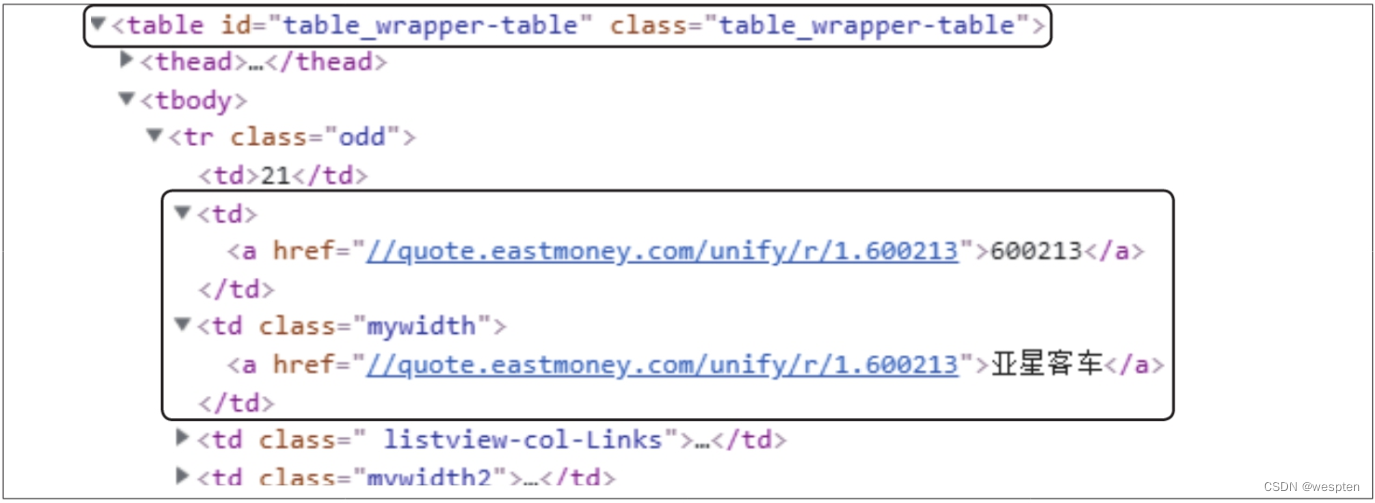
根据上述分析,写出相应的XPath表达式来定位这两个标签,并将标签中的数据提取出来,保存在一个字典中。
代码如下:
1 data_dt = {'股票代码':[], '股票名称':[]} # 用于存储爬取结果的字典 2 def get_data(): # 获取每一页表格数据的自定义函数 3 code_list = browser.find_elements_by_xpath('//*[@id='table_wrapper-table']/tbody/tr/td[2]') # 获取所有包含股票代码的<td>标签,注意函数名中是“elements”而不是“element” 4 name_list = browser.find_elements_by_xpath('//*[@id='table_wrapper-table']/tbody/tr/td[3]') # 获取所有包含股票名称的<td>标签,注意函数名中是“elements”而不是“element” 5 for code in code_list: 6 data_dt['股票代码'].append(code.text) # 将<td>标签中的股票代码依次提取出来并添加到字典中 7 for name in name_list: 8 data_dt['股票名称'].append(name.text) # 将<td>标签中的股票名称依次提取出来并添加到字典中(3)获取所有页面的股票信息
要获取所有页面的股票信息,需要知道总页数,以及如何定位“下一页”按钮。总页数最好不要直接使用在页面中看到的最后一页的页码,因为每天都可能有股票上市或退市,所以这个数字会变化。
用开发者工具查看页码和“下一页”按钮在网页源代码中的位置,可发现总页数位于class属性值为paginate_page的标签下的最后一个标签中,而“下一页”按钮可通过其class属性值next来定位,如下图所示。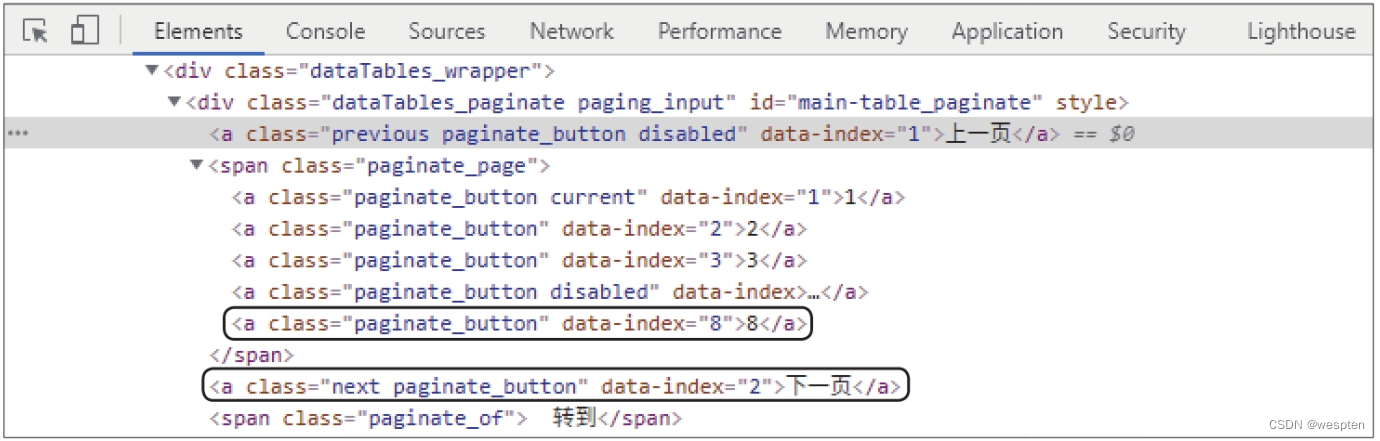
根据上述分析编写代码,先获取总页数,再利用for语句构造循环,在每次循环中先调用前面编写的自定义函数获取当前页面的股票信息,再利用Selenium模块模拟用户操作单击“下一页”按钮,最终获取所有页面的股票信息。
代码如下:
1 pn_list = browser.find_elements_by_css_selector('.paginate_page>a') # 定位class属性值为paginate_page的标签下的所有<a>标签 2 pn = int(pn_list[-1].text) # 选取最后一个<a>标签,提取其文本,再转换为整型数字,得到总页数 3 for i in range(pn): # 根据获取的总页数设定循环次数 4 get_data() # 调用自定义函数获取当前页面的股票信息 5 a_btn = browser.find_element_by_css_selector('.next') # 通过class属性值定位“下一页”按钮 6 a_btn.click() # 模拟单击“下一页”按钮 7 time.sleep(5) # 因为是局部刷新,当前页面相当于未加载其他元素,用显式等待或隐式等待都比较麻烦,所以采用time模块进行简单的等待操作 8 browser.quit() # 关闭浏览器窗口(4)输出爬取结果
将字典转换为DataFrame,再存储为csv文件。
代码如下:
1 data_df = pd.DataFrame(data_dt) 2 print(data_df) 3 data_df.to_csv('汽车股票基本信息test.csv', index=False)运行代码后,打开生成的csv文件,结果如下图所示。

步骤3:因为东方财富网的股票基本信息不包含上市日期,所以接着利用Tushare模块获取所有股票的基本信息,再将两部分信息依据股票代码进行合并,得到完整的汽车行业股票基本信息。
(1)获取所有股票的基本信息
使用Tushare模块中的get_stock_basics()函数可获取所有股票的基本信息。该函数返回的是一个DataFrame,其结构如下所示:
1 name industry area ... timeToMarket ... 2 code 3 688788 N科思 通信设备 深圳 ... 20201022 ... 4 003013 N地铁 建筑工程 广东 ... 20201022 ... 5 300849 锦盛新材 塑料 浙江 ... 20200710 ... 6 300582 英飞特 半导体 浙江 ... 20161228 ... 7 300279 和晶科技 元器件 江苏 ... 20111229 ... 8 ......可以看到,作为行标签的code列中的数据是股票代码,timeToMarket列中的数据是上市日期。只需保留timeToMarket列,然后将code列转换为普通的数据列。
代码如下:
1 import tushare as ts 2 import pandas as pd 3 data1 = pd.read_csv('汽车股票基本信息test.csv', converters={'股票代码': str}) # 读取从东方财富网爬取的股票基本信息,将“股票代码”列的数据类型转换为字符串,让以0开头的股票代码保持完整 4 data2 = ts.get_stock_basics() # 获取所有股票的基本信息 5 data2 = data2[['timeToMarket']].astype(str).reset_index() # 只保留timeToMarket列(即上市日期),并将其数据类型转换为字符串,然后重置索引,将行标签列转换为普通的数据列(2)依据股票代码合并DataFrame
使用pandas模块中的merge()函数将data1和data2这两个DataFrame依据股票代码进行合并。代码如下:
1 data = pd.merge(data1, data2, how='left', left_on='股票代码', right_on='code') # 依据股票代码合并data1和data2 2 data = data.drop(['code'], axis=1) # 删除多余的列 3 data = data.rename(columns={'timeToMarket': '上市日期'}) # 重命名列第1行代码中,参数how设置为'left',表示在合并时完整保留data1的内容,并且依据股票代码如果能匹配到data2中的内容则合并进来,如果匹配不到则赋为空值;参数left_on和right_on分别用于指定data1和data2中股票代码所在的列。
(3)存储结果
将合并后的DataFrame存储为csv文件,并写入MySQL数据库。
代码如下:
1 from sqlalchemy import create_engine, types 2 data.to_csv('汽车股票基本信息.csv', index=False) 3 code_name_time_info.to_csv('汽车股票上市时间对照表.csv', index=False) 4 con = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') # 创建数据库连接引擎 5 data.to_sql('car_stock', con=con, index_label=['id'], if_exists='replace', dtype={'id': types.BigInteger(), '股票代码': types.VARCHAR(10), '股票名称': types.VARCHAR(10), '上市日期': types.DATETIME})运行代码后,在MySQL的命令行窗口中查询数据表car_stock的所有数据记录,结果如下图所示。

至此,获取汽车行业股票基本信息的任务就完成了。
3、获取单只股票的历史行情数据
代码文件:获取单只股票的历史行情数据.py
使用Tushare模块中的get_k_data()函数能获取单只股票的历史行情数据。下面使用该函数获取“拓普集团”(股票代码601689)的历史行情数据,并将数据按年份写入MySQL数据库。
步骤1:已将股票基本信息写入MySQL数据库,这里从数据库中查询“拓普集团”的股票基本信息,并从中提取上市年份。当前年份则利用datetime模块获取。
代码如下:
1 import tushare as ts 2 from datetime import datetime 3 from sqlalchemy import create_engine, types 4 con = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') # 创建数据库连接引擎 5 connection = con.connect() # 创建connection对象来操作数据库 6 data = connection.execute("SELECT * FROM car_stock WHERE 股票代码='601689';") # 查询“股票代码”字段值为'601689'的数据记录 7 data_info = data.fetchall() # 提取查询到的数据,返回一个元组列表 8 start_year = int(str(data_info[0][3])[:4]) # 从列表中取出第1个元组,再取出元组的第4个元素(即上市日期),然后通过切片提取前4个字符(即上市年份) 9 end_year = datetime.now().year # 利用datetime模块获取当前年份步骤2:使用get_k_data()函数获取每年的历史行情数据。
代码如下:
1 for year_num in range(start_year, end_year + 1): 2 tuopu_info = ts.get_k_data('601689', start=f'{year_num}-01-01', end=f'{year_num}-12-31', autype='qfq') # 将参数autype指定为向前复权步骤3:最后将获取的每年历史行情数据写入MySQL数据库。代码如下:
1 tuopu_info.to_sql(f'{year_num}_stock_data', con=con, index_label=['id'], if_exists='replace', dtype={'id': types.BigInteger(), 'date': types.DATETIME, 'open': types.VARCHAR(10), 'close': types.FLOAT(), 'high': types.FLOAT(), 'low': types.FLOAT(), 'volume': types.FLOAT(), 'code': types.INT()})4、获取沪深A股涨幅前60名的信息
代码文件:获取沪深A股涨幅前60名的信息.py、将前60名的信息写入数据库.py
主要从东方财富网爬取沪深A股的实时行情信息,网址为http://quote.eastmoney.com/center/gridlist.html#hs_a_board。沪深A股的开盘时间为交易日的9:15—11:30和13:00—15:00。从13:00开始爬取,每爬取一次后间隔3分钟再爬取一次,如此循环往复,直到15:00为止。行情页面的行情信息是按照涨幅降序排列的,每页20条数据,因此,只需爬取前3页就能获取涨幅前60名的股票信息。
步骤1:导入需要用到的模块。
代码如下:
1 from selenium import webdriver 2 import time 3 import numpy as np 4 import pandas as pd步骤2:编写一个自定义函数top60()用于完成数据的爬取。用Selenium实例化一个浏览器对象,对行情页面发起请求,然后提取页面中表格的表头文本,在后续代码中作为数据的列标签。代码如下:
1 def top60(): 2 browser = webdriver.Chrome(executable_path='chromedriver.exe') 3 url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board' 4 browser.get(url) # 对行情页面发起请求 5 col_name = [] # 用于存储表头文本的列表 6 col_tag = browser.find_elements_by_xpath('//*[@id="table_wrapper-table"]/thead/tr/th') # 定位表头中的所有单元格 7 for i in col_tag: 8 col_name.append(i.text) # 依次提取表头中每个单元格的文本并添加到列表中步骤3:接着提取表格主体中所有单元格的文本,得到当前页面的表格数据,再切换页面,继续提取表格数据。这一系列操作需要重复3次。
代码如下:
1 data_ls = [] # 用于存储表格数据的列表 2 for i in range(3): # 爬取前3页数据 3 td_list = browser.find_elements_by_xpath('//*[@id="table_wrapper-table"]/tbody/tr/td') # 定位表格主体中的所有单元格 4 for j in td_list: 5 data_ls.append(j.text) # 依次提取表格主体中每个单元格的文本并添加到列表中 6 a_btn = browser.find_element_by_css_selector('.next') # 定位“下一页”按钮 7 a_btn.click() # 模拟单击“下一页”按钮 8 time.sleep(2) # 等待2秒 9 browser.quit() # 关闭浏览器窗口步骤4:先利用NumPy模块将包含所有表格数据的列表转换为二维数组,再利用pandas模块将二维数组转换为DataFrame,并存储为Excel工作簿。
代码如下:
1 data_ar = np.array(data_ls).reshape(-1, len(col_name)) # 将包含所有表格数据的列表转换为一维数组,再使用reshape()函数将一维数组转换为二维数组,二维数组的列数设置为步骤2中提取的表头文本的个数,行数设置为-1,表示根据列数自动计算行数 2 data_df = pd.DataFrame(data_ar, columns=col_name) # 将二维数组转换为DataFrame,使用步骤2中提取的表头文本作为列标签 3 data_df.drop(['序号', '相关链接', '加自选'], axis=1, inplace=True) # 删除不需要的列 4 data_df.rename(columns={'成交量(手)': '成交量', '市盈率(动态)': '市盈率'}, inplace=True) # 对部分列进行重命名 5 now = time.strftime('%Y_%m_%d-%H_%M_%S', time.localtime(time.time())) # 生成当前日期和时间的字符串,用于命名Excel工作簿 6 data_df.to_excel(f'涨幅排行top60-{now}.xlsx', index=False) # 将DataFrame存储为Excel工作簿步骤5:编写一个自定义函数trade_time()用于判断股市当前是开市状态还是休市状态,判断的条件是当前星期是否在星期一到星期五之间,并且当前时间是否在13:00到15:00之间。
代码如下:
1 def trade_time(): 2 now = time.localtime(time.time()) # 获取当前日期和时间 3 now_weekday = time.strftime('%w', now) # 获取当前星期 4 now_time = time.strftime('%H:%M:%S', now) # 获取当前时间 5 if ('1' <= now_weekday <= '5') and ('13:00:00' <= now_time <= '15:00:00'): # 判断股市状态的条件 6 return True # 满足条件则返回True,表示当前处于开市状态 7 else: 8 return False # 否则返回False,表示当前处于休市状态需要说明的是,要确定当天是否为交易日,除了要考虑当天是否为工作日(星期一到星期五),还要考虑当天是否为国家法定节假日。限于篇幅,上述代码只考虑了当天是否为工作日,感兴趣的读者可以利用搜索引擎查找判断当天是否为国家法定节假日的方法。
步骤6:用while语句构造一个条件循环,如果股市当前是开市状态,则爬取数据,如果是休市状态,则结束爬取。
代码如下:
1 while trade_time(): # 调用自定义函数trade_time()判断股市状态 2 top60() # 如果是开市状态,则调用自定义函数top60()爬取数据 3 time.sleep(180) # 等待3分钟后再重复操作 4 print('股市已休市,结束爬取') # 如果是休市状态,则输出结束爬取的信息步骤7:读取Excel工作簿,将数据写入MySQL数据库。代码如下: 1 from pathlib import Path 2 import pandas as pd 3 from sqlalchemy import create_engine, types 4 file_list = Path(Path.cwd()).rglob('*.xlsx') # 列出当前文件夹下的所有Excel工作簿 5 con = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8') # 创建数据库连接引擎 6 for file in file_list: 7 data = pd.read_excel(file, converters={'代码': str}) # 读取Excel工作簿 8 data.to_sql(file.stem, con=con, index_label=['id'], if_exists='replace', dtype={'id': types.BigInteger(), '代码': types.VARCHAR(10), '名称': types.VARCHAR(10), '最新价': types.FLOAT, '涨跌幅': types.VARCHAR(10), '涨跌额': types.FLOAT, '成交量': types.VARCHAR(20), '成交额': types.VARCHAR(20), '振幅': types.VARCHAR(10), '最高': types.FLOAT, '最低': types.FLOAT, '今开': types.FLOAT, '昨收': types.FLOAT, '量比': types.VARCHAR(10), '换手率': types.VARCHAR(10), '市盈率': types.FLOAT, '市净率': types.FLOAT}) # 将数据写入数据库主要介绍的爬虫程序都是在开发者自己的计算机上运行的,一旦计算机关机或出现故障,程序就停止运行了。如果要让程序24小时无间断运行,就要借助云服务器。云服务器可以24小时不关机,而且基本不会出现故障。将爬虫程序部署在云服务器上,就能实现数据的无间断自动定时爬取。
技巧:结合使用Selenium模块和pandas模块快速爬取表格数据
要爬取的行情数据是标准的表格数据,很适合使用pandas模块中的read_html()函数来提取。但是东方财富网的数据大多是动态加载的,read_html()函数无法直接处理。这里提供一种解决问题的思路:先用Selenium模块获取动态加载的网页源代码,再用read_html()函数从网页源代码中提取表格数据。
根据这一思路,将自定义函数top60()的代码修改如下:
1 def top60(): 2 browser = webdriver.Chrome(executable_path='chromedriver.exe') 3 url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board' 4 browser.get(url) # 对行情页面发起请求 5 data = pd.read_html(browser.page_source, converters={'代码': str})[0] # 利用page_source属性获取行情页面的网页源代码,传给read_html()函数,提取出第1页的表格数据,参数converters用于将“代码”列的数据类型转换为字符串,让以0开头的股票代码保持完整 6 for i in range(2): # 前面已提取了第1页的表格数据,所以只需再循环2次 7 time.sleep(2) # 等待2秒 8 a_btn = browser.find_element_by_css_selector('.next') # 定位“下一页”按钮 9 a_btn.click() # 模拟单击“下一页”按钮 10 df = pd.read_html(browser.page_source, converters={'代码': str})[0] # 提取下一页的表格数据 11 data = data.append(df, ignore_index=True) # 将提取的数据追加到data中 12 browser.quit() 13 data.drop(['序号', '相关链接', '加自选'], axis=1, inplace=True) 14 data.rename(columns={'成交量(手)': '成交量', '市盈率(动态)': '市盈率'}, inplace=True) 15 now = time.strftime('%Y_%m_%d-%H_%M_%S', time.localtime(time.time())) 16 data.to_excel(f'涨幅排行top60-{now}.xlsx', index=False)5、计算股票的月涨跌幅
代码文件:计算股票的月涨跌幅.py
一只股票一天的涨跌幅只能说明这只股票短期内的行情,要想分析一只股票的稳定性,还需要计算这只股票在较长一段时期内的涨跌幅。将获取“长城影视”(股票代码002071)在一年内的历史行情数据并计算月涨跌幅。
步骤1:利用Tushare模块获取“长城影视”从2019年6月1日到2020年5月31日的历史行情数据。
代码如下:
1 import tushare as ts 2 import pandas as pd 3 data_info = ts.get_hist_data(code='002071', start='2019-06-01', end='2020-05-31') # 获取一年的股票历史行情数据步骤2:获取的数据是一个DataFrame,其行标签为交易日期,将行标签中交易日期的数据类型转换为datetime,方便进行数据的重新取样。
代码如下:
1 data_info.index = pd.to_datetime(data_info.index, format='%Y-%m-%d')步骤3:对数据进行重新取样,获取每月第一天的数据和最后一天的数据。
代码如下:
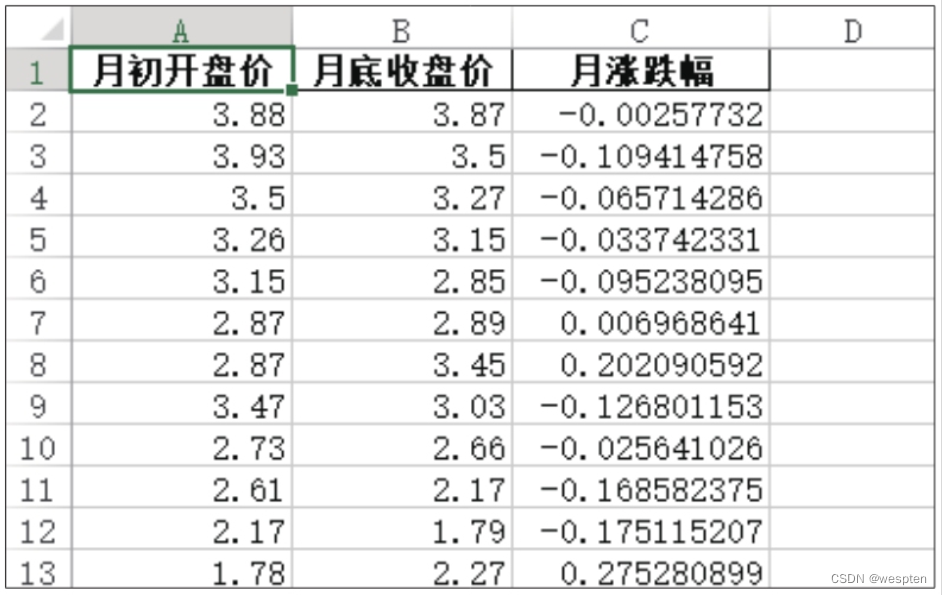
1 month_first = data_info.resample('M').first() # 获取每月第一天的数据 2 month_last = data_info.resample('M').last() # 获取每月最后一天的数据步骤4:获取月初开盘价和月底收盘价,合并为一个新的DataFrame,然后计算出月涨跌幅。代码如下:
1 month_first = month_first['open'] # 获取月初开盘价 2 month_last = month_last['close'] # 获取月底收盘价 3 new_info = pd.DataFrame(list(zip(month_first, month_last)), columns=['月初开盘价', '月底收盘价'], index=month_last.index) # 合并月初开盘价和月底收盘价 4 new_info['月涨跌幅'] = (new_info['月底收盘价'] - new_info['月初开盘价']) / new_info['月初开盘价'] # 计算月涨跌幅步骤5:将最终结果存储为Excel工作簿。
代码如下:
1 new_info.to_excel('月涨跌幅.xlsx', index=False)打开生成的Excel工作簿,其内容如下图所示。
6、股票相关性分析
代码文件:股票相关性分析.py
在股票投资中,有一种交易策略称为“配对交易”:找出历史股价走势相近的股票进行配对,当配对的股票价格差偏离历史均值时,在抛出股价高的股票的同时买进股价低的股票,等待配对的股票回归到长期的均衡关系,由此获利。
而衡量不同股票能否配对的关键就是股票之间的相关性是否足够大。下面就以“浦东金桥”(股票代码600639)和“新黄浦”(股票代码600638)这两只股票为例分析它们的相关性。
步骤1:获取“浦东金桥”和“新黄浦”从2019年6月1日到2020年5月31日的历史行情数据,并按日期排序(行标签为日期)。
代码如下:
1 import tushare as ts 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] 5 plt.rcParams['axes.unicode_minus'] = False 6 pd_code = '600639' # “浦东金桥”的股票代码 7 xhp_code = '600638' # “新黄浦”的股票代码 8 pd_data = ts.get_hist_data(pd_code, start='2019-06-01', end='2020-05-31').sort_index() # 获取“浦东金桥”的历史行情数据并按日期排序 9 xhp_data = ts.get_hist_data(xhp_code, start='2019-06-01', end='2020-05-31').sort_index() # 获取“新黄浦”的历史行情数据并按日期排序步骤2:将不同股票每一天的收盘价合并为一个DataFrame。代码如下:
1 df = pd.concat([pd_data['close'], xhp_data['close']], axis=1, keys=['浦东金桥', '新黄埔']) # 提取收盘价并拼接成DataFrame 2 print(df)代码运行结果如下:
1 浦东金桥 新黄埔 2 date 3 2019-06-03 14.13 8.28 4 2019-06-04 14.16 8.37 5 2019-06-05 14.05 8.37 6 ... ... ... 7 2020-05-27 14.69 5.48 8 2020-05-28 14.87 5.41 9 2020-05-29 14.56 5.45步骤3:使用corr()函数计算皮尔逊相关系数,判断收盘价的相关性。
代码如下:
1 corr = df.corr() 2 print(corr)代码运行结果如下:
1 浦东金桥 新黄埔 2 浦东金桥 1.000000 0.636778 3 新黄埔 0.636778 1.000000可以看到,近一年两只股票收盘价的皮尔逊相关系数约为0.64,说明两只股票的相关性较弱,不满足做匹配交易的条件。
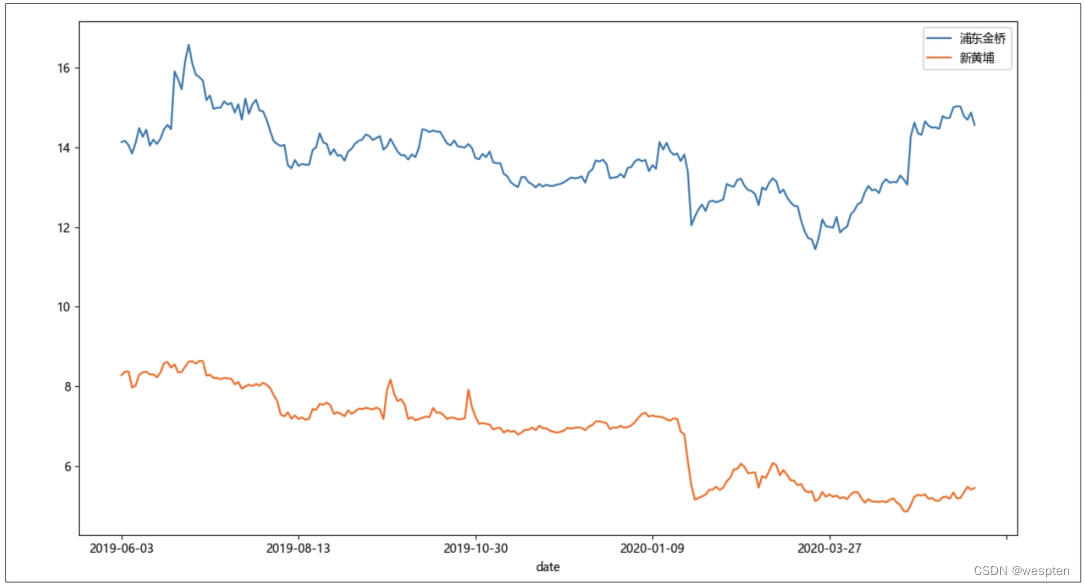
步骤4:绘制收盘价走势图,将数据可视化。
代码如下:
1 df.plot() 2 plt.show()代码运行结果如下图所示。可以看到,在2019年8月到2020年1月,这两只股票的收盘价走势比较相似,这时进行配对交易,盈利的可能性更大。
7、股票价格预测
代码文件:股票价格预测.py、stocker.py、预测模型结果图.tif
将利用stocker模块根据一只股票的历史行情数据预测这只股票未来的行情。需要说明的是,证券市场变幻莫测,预测结果只能大致反映股价走势,并不能作为证券交易的依据。
下面以“酒鬼酒”(股票代码000799)为例讲解具体操作。
步骤1:stocker模块是用于预测股票行情的Python第三方开源模块,项目网址为https://github.com/WillKoehrsen/Data-Analysis/tree/master/stocker。该模块的安装不是通过pip命令,而是从项目网址下载stocker.py文件后放到项目文件夹中,或者在项目文件夹中新建stocker.py文件,再在网页中打开stocker.py,复制其中的代码,将其粘贴到新建的stocker.py文件中。
准备好stocker.py文件后,还要通过pip命令安装stocker模块需要调用的其他Python第三方模块,包括quandl 3.3.0、Matplotlib 2.1.1、NumPy 1.14.0、fbprophet 0.2.1、pystan 2.17.0.0、pandas 0.22.0、pytrends 4.3.0。
步骤2:stocker模块默认使用quandl模块获取股票数据。因为quandl模块获取数据不太方便,所以这里通过修改stocker模块的代码,使用pandas_datareader模块获取股票数据。
先用pip命令安装好pandas_datareader模块,然后在PyCharm中打开stocker.py文件,在开头添加代码,导入pandas_datareader模块中的data子模块,具体如下:
1 from pandas_datareader import data接下来修改Stocker类的构造函数__init__()的代码,更改Stocker类接收的参数。通过搜索关键词“__init__”定位到如下所示的代码:
1 class Stocker(): 2 # Initialization requires a ticker symbol 3 def __init__(self, ticker, exchange='WIKI'):删除上述第3行代码中的参数exchange,保留参数ticker,添加两个新参数start_date和end_date,分别代表股票数据的开始日期和结束日期。
修改后的代码如下:
1 class Stocker(): 2 # Initialization requires a ticker symbol 3 def __init__(self, ticker, start_date, end_date):接下来使用pandas_datareader模块中的data子模块替换原来的quandl模块获取股票数据。通过搜索关键词“quandl”定位到如下所示的代码:
1 try: 2 stock = quandl.get('%s/%s' % (exchange, ticker)) 3 except Exception as e: 4 print('Error Retrieving Data.')将上述第2行代码注释掉,在其下方添加一行代码,获取雅虎财经的股票行情数据。
修改后的代码如下:
1 try: 2 # stock = quandl.get('%s/%s' % (exchange, ticker)) 3 stock = data.get_data_yahoo(ticker, start_date, end_date) 4 except Exception as e: 5 print('Error Retrieving Data.')这样就完成了对stocker模块的代码的修改。
步骤3:新建一个Python文件,开始编写预测股票价格的代码。先实例化一个Stocker对象,再使用该对象获取“酒鬼酒”的历史行情数据,并将数据绘制成图表。
代码如下:
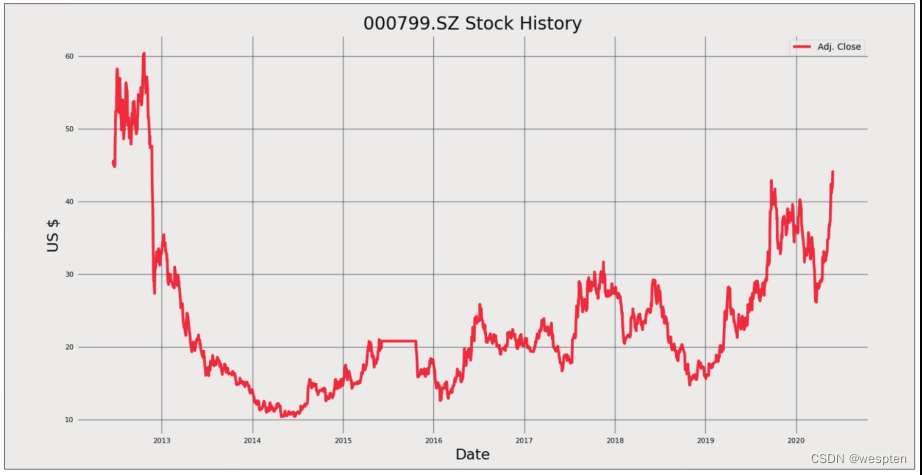
1 from stocker import Stocker 2 alcoholic = Stocker('000799.SZ', start_date='2000-01-01', end_date='2020-05-31') # 获取历史行情数据 3 alcoholic.plot_stock() # Stocker内部封装的画图方法需要注意第2行代码中股票代码的书写格式“股票代码.交易所缩写”。上海证券交易所的缩写为“SS”,深圳证券交易所的缩写为“SZ”。代码运行结果如下图所示,因为数据是从雅虎财经获取的,所以货币单位为美元。
步骤4:使用create_prophet_model()函数生成一个预测模型结果图。
代码如下:
1 model, model_data = alcoholic.create_prophet_model(days=90)代码运行结果如下图所示:
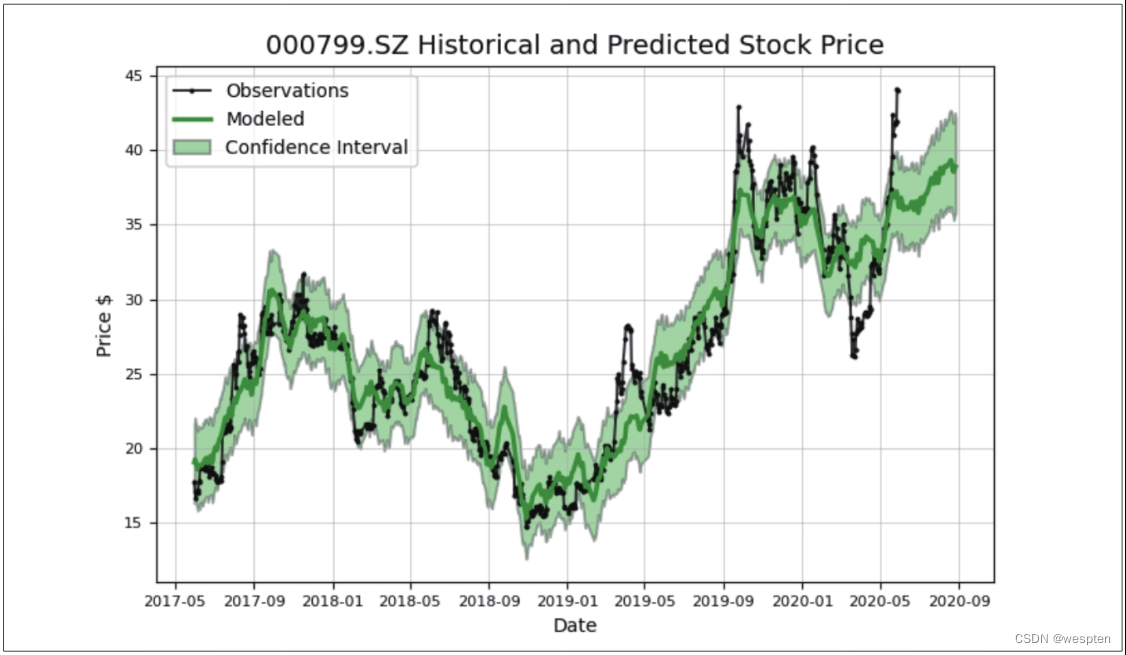
图中黑色的线是观察线(Observations),是根据股票的真实行情数据绘制的;绿色的线是根据模型预测的行情数据绘制的;浅绿色的图形代表置信区间,表示预测结果会在这个区间内波动。
通过分析预测模型结果图可知,模型预测股价在6月左右会下降一点,在7—9月会缓慢上升。但是在5月底,真实股价的涨势很快,超出了模型预测的置信区间,说明当时可能发生了影响股价的特殊事件。通过搜索新闻可知,当时“酒鬼酒”公司调整了酒价,导致股价上涨。这也说明了影响股市的因素很多,模型的预测结果不能作为交易的依据。
步骤5:预测30天后的股价。
代码如下:
1 alcoholic.predict_future(days=30)代码运行结果如下图所示。
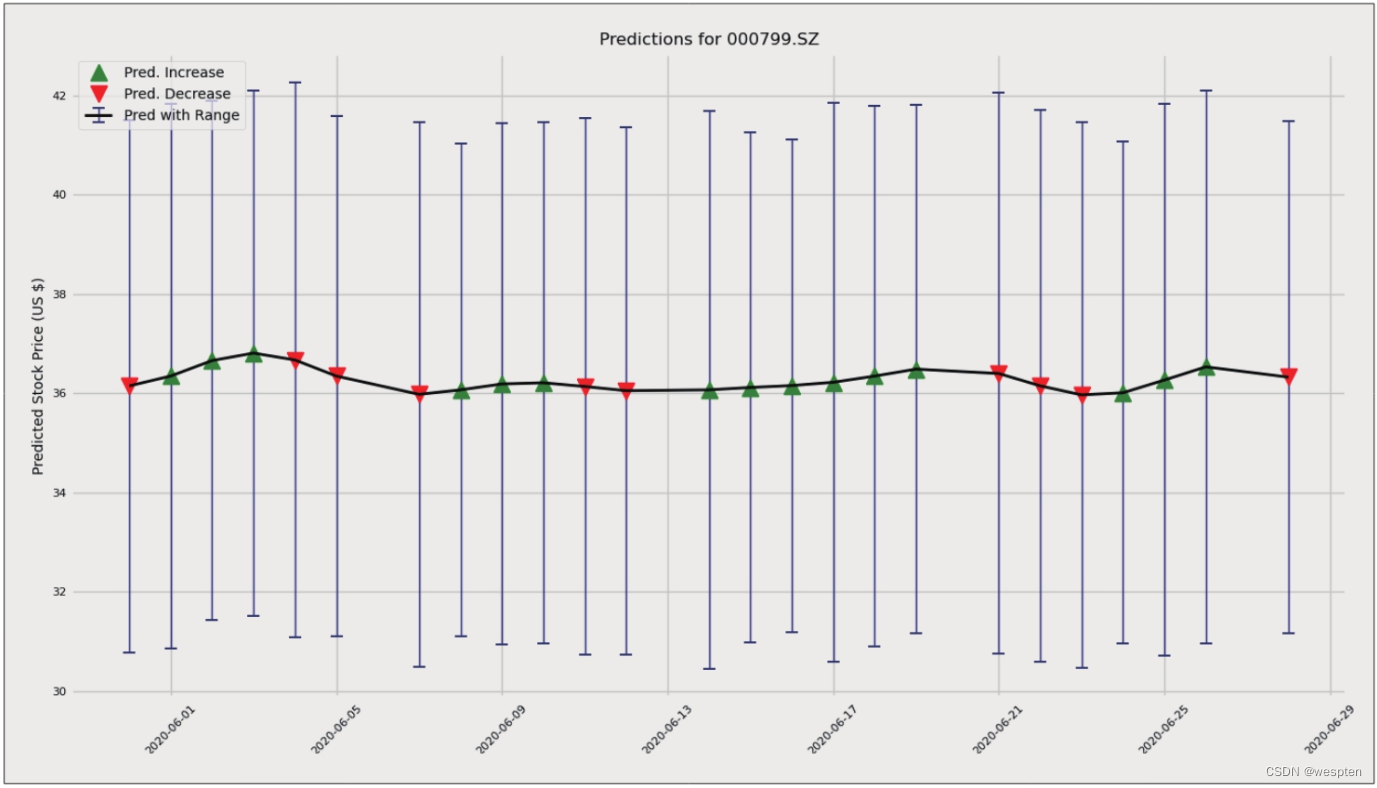
可以看到,由于酒价调整,预测结果并不准确。
本文转载自: https://blog.csdn.net/qq_35029061/article/details/127400065
版权归原作者 wespten 所有, 如有侵权,请联系我们删除。发表评论
“Python 爬虫案例”的评论:
还没有评论