
下载
idea
Download IntelliJ IDEA: The Capable & Ergonomic Java IDE by JetBrains
企业版适用
一、使用IDEA创建项目

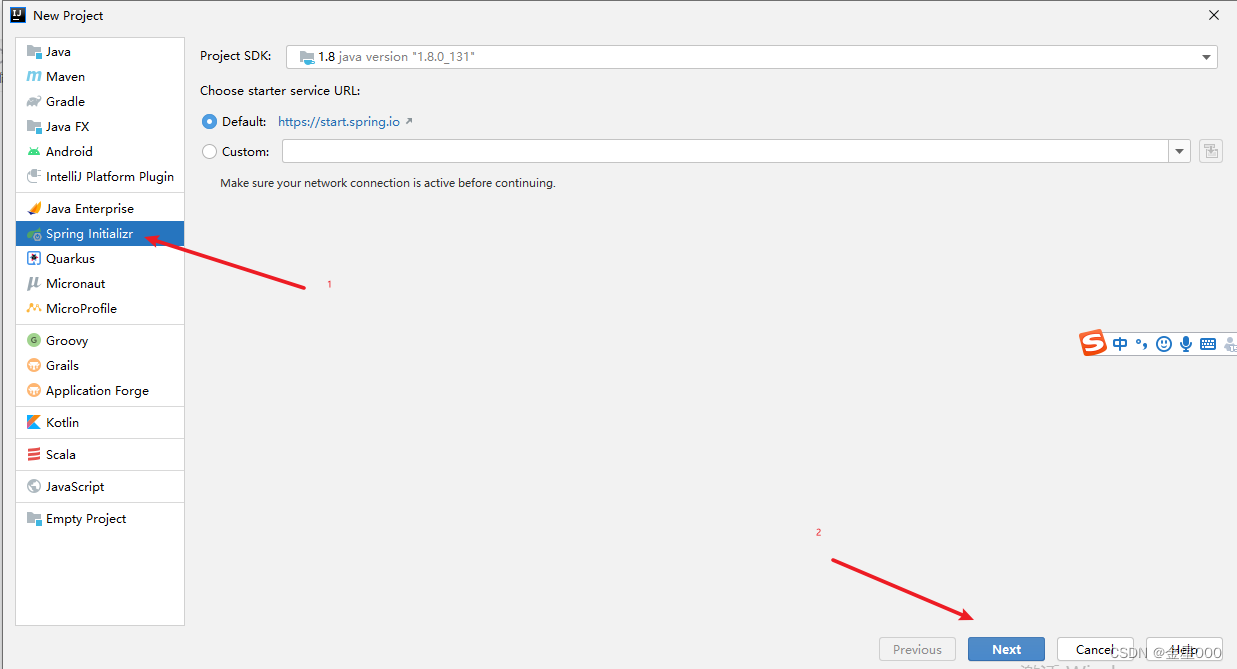
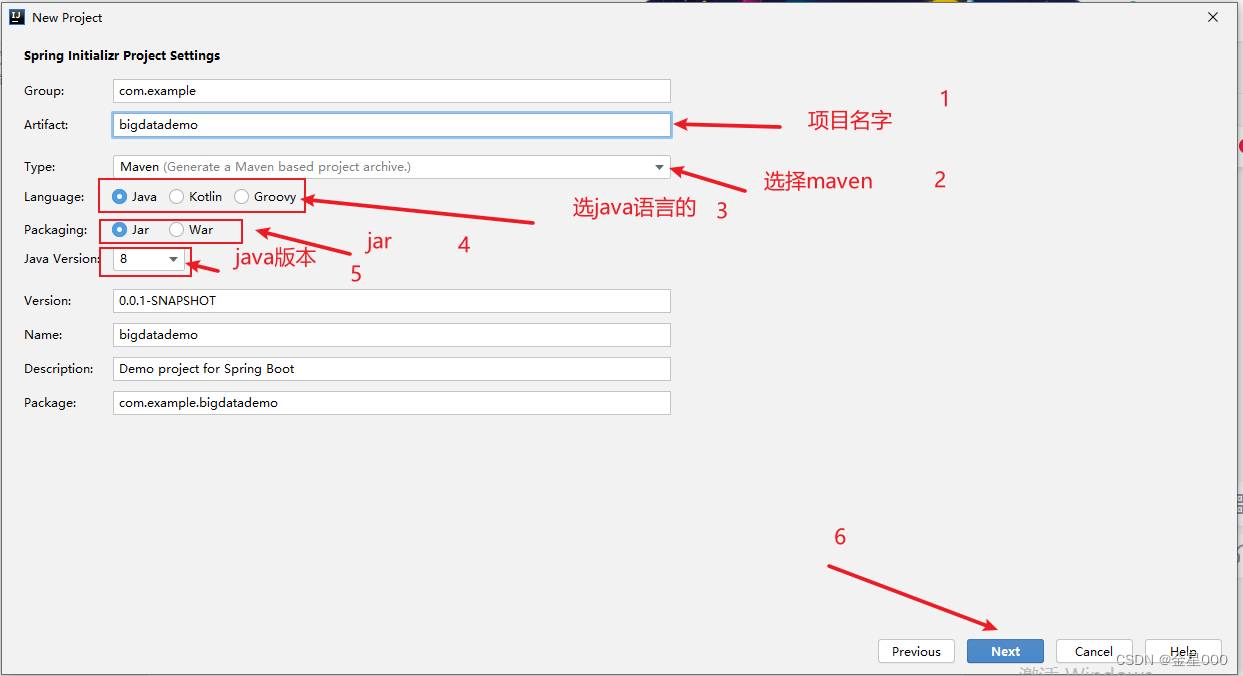
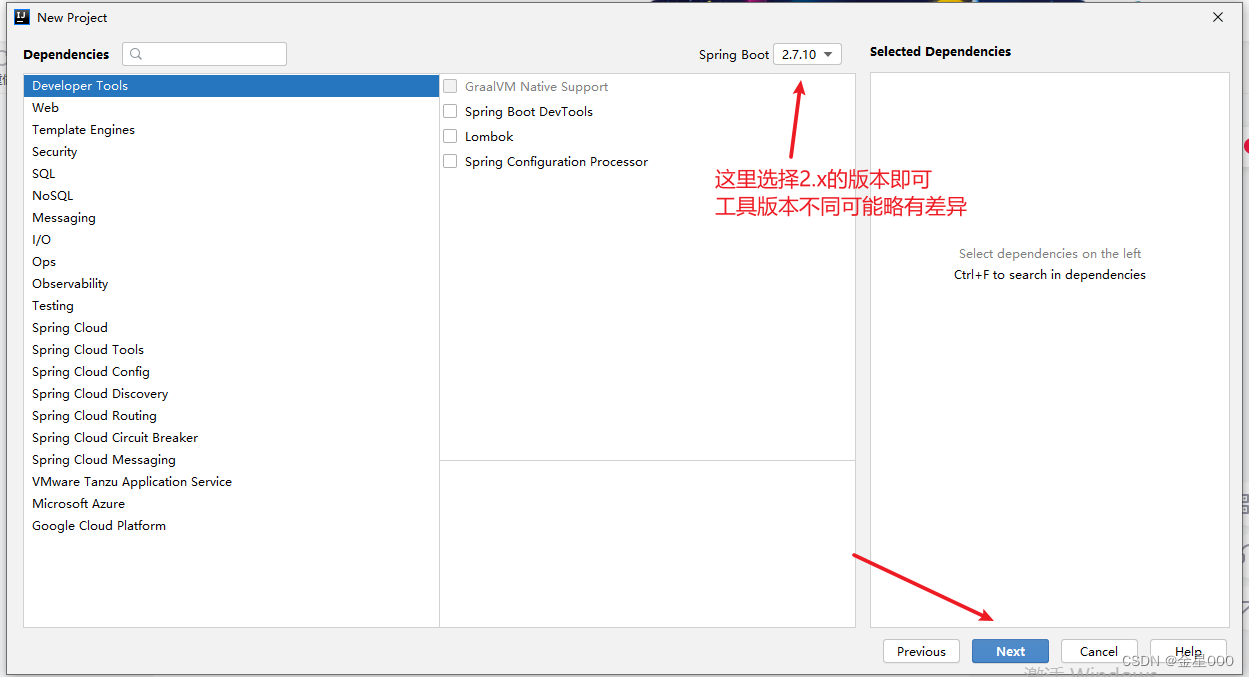
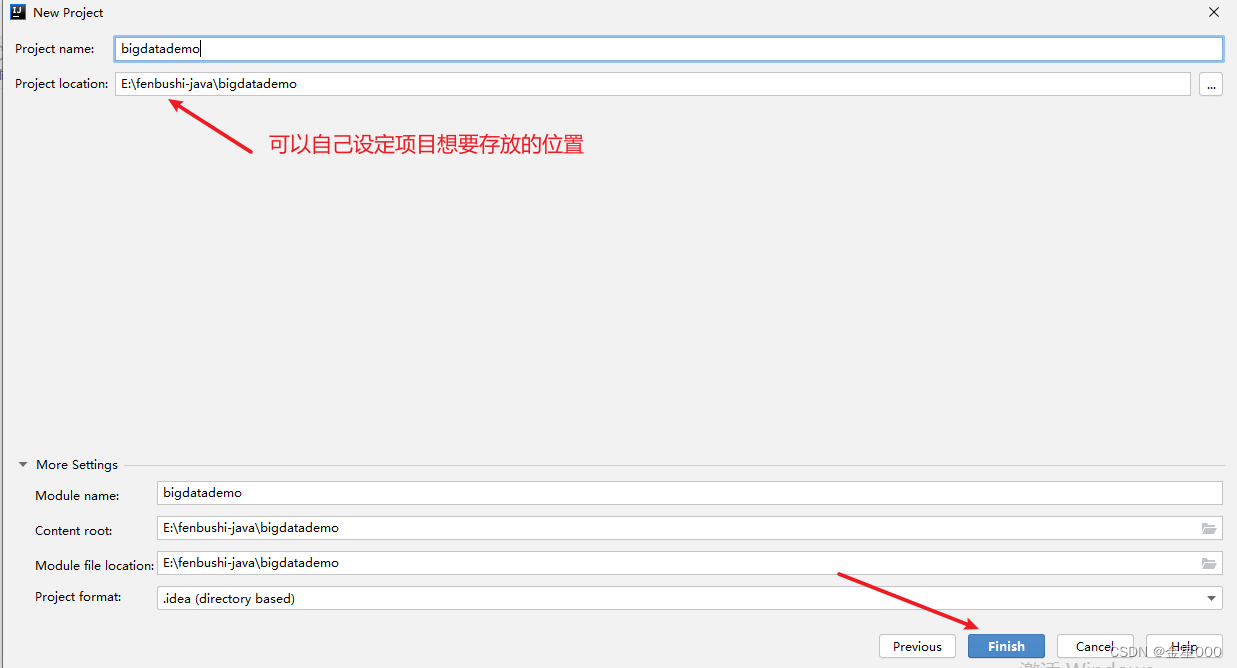

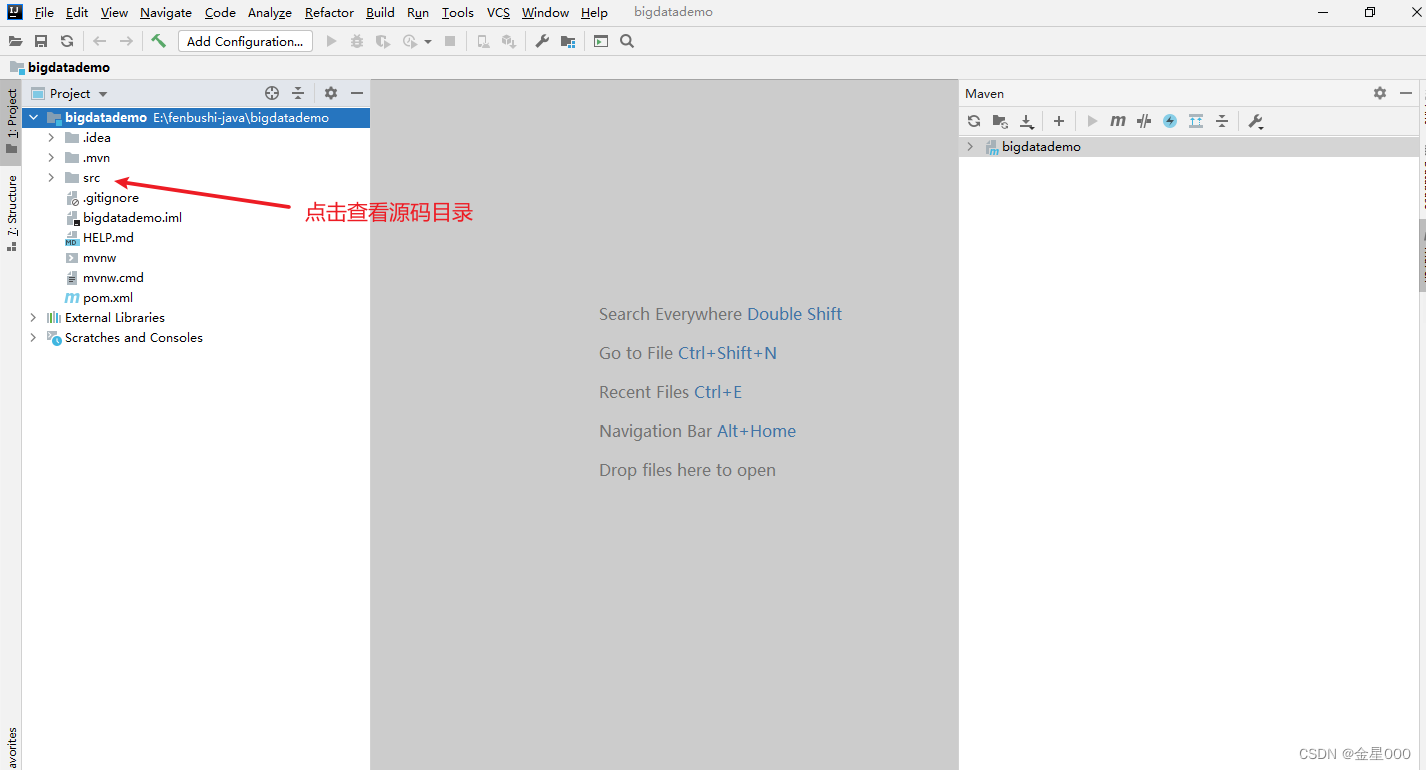
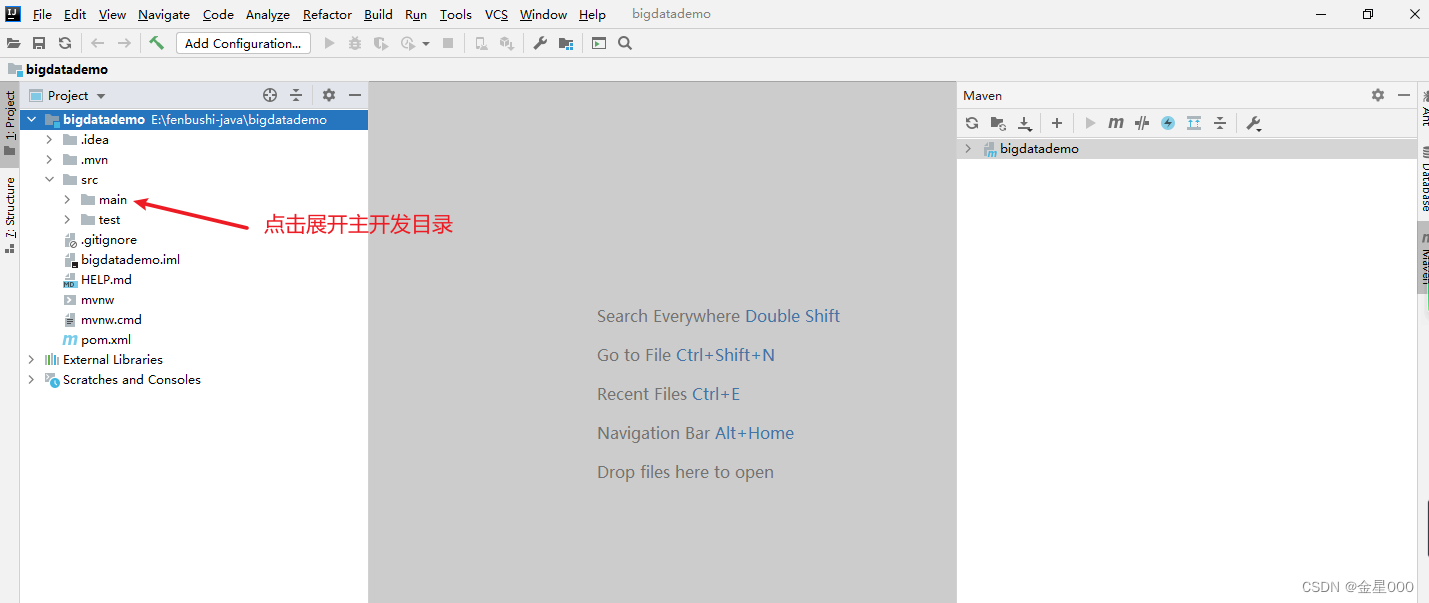
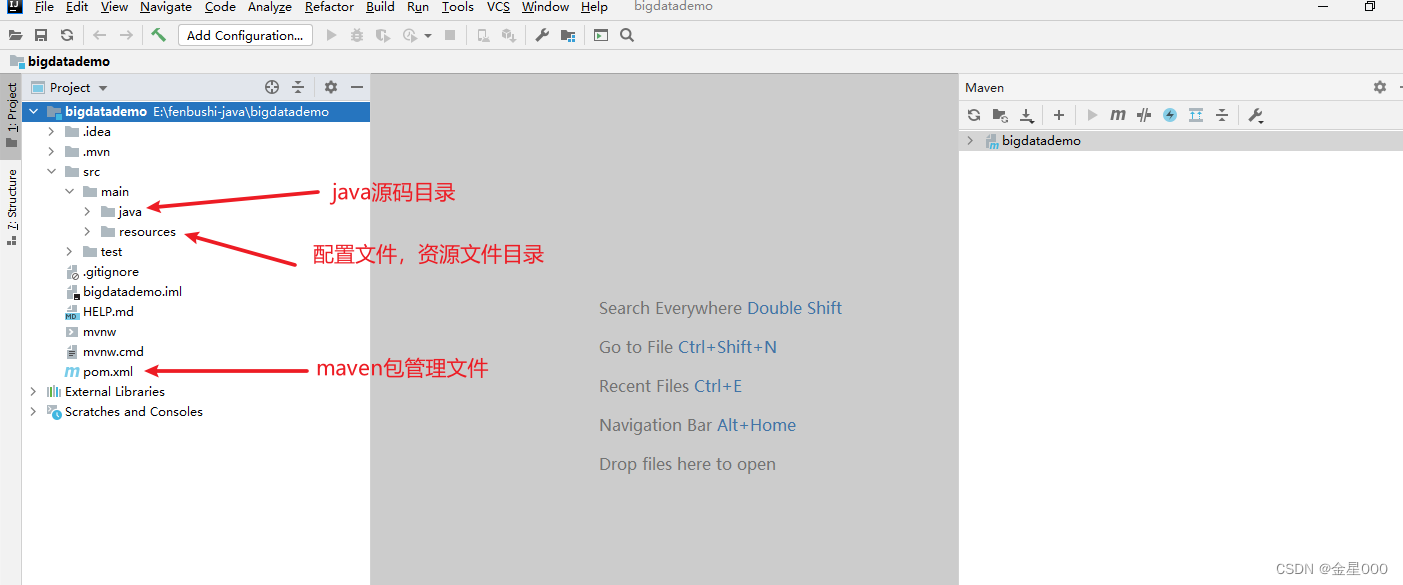
二、使用maven管理jar包
双击打开pom.xml文件 这里把springboot 版本更换为2.3.5.RELEASE
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>bigdatademo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>bigdatademo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.3.5.RELEASE</version>
</plugin>
</plugins>
</build>
</project>
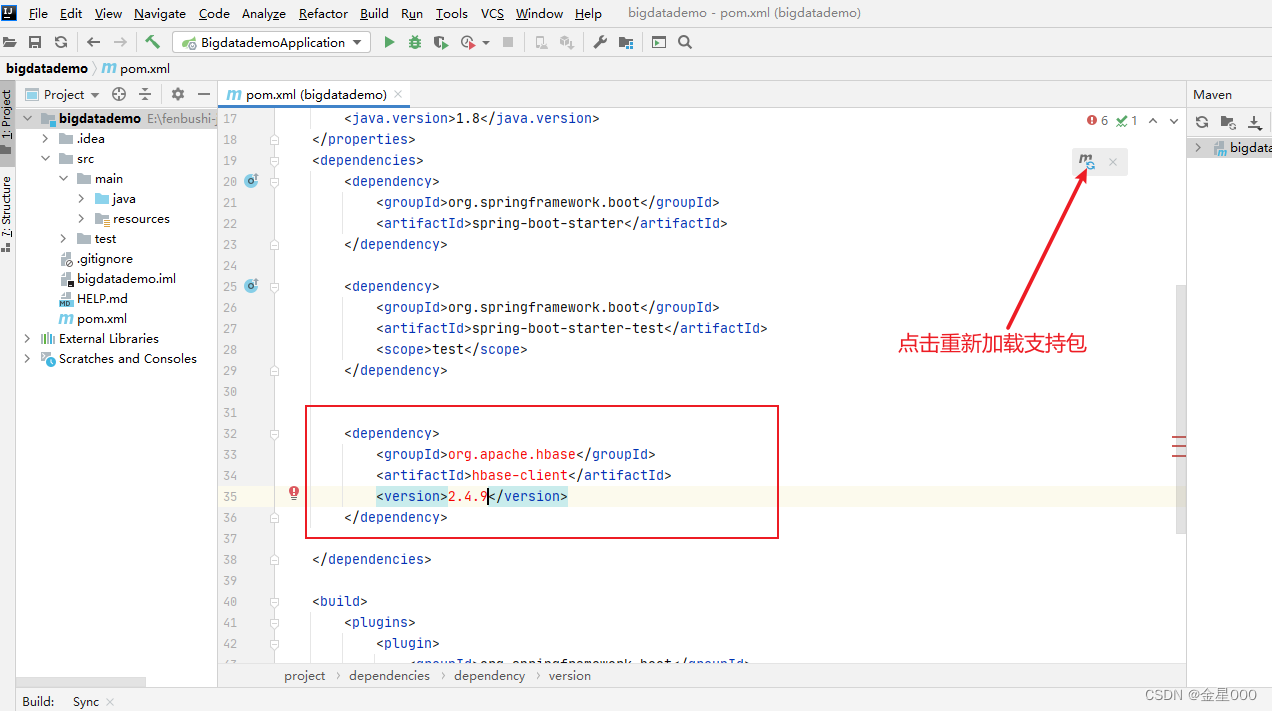
加入hbase client 的支持包,这里版本需要跟服务器上安装的版本号一致
加入其他需要的包
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.0</version>
</dependency>
<!--zookeeper-->
<!-- https://mvnrepository.com/artifact/org.apache.zookeeper/zookeeper-client -->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.3</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.20.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.20.0</version>
</dependency>
<!--hbase-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-shaded-client</artifactId>
<version>2.4.9</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.4.9</version>
</dependency>
<!--mapreduce 写入数据到Hbase-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.4.9</version>
</dependency>
三、编写Hbase操作工具类(创建表空间,表,添加数据,查询数据,修改数据,删除数据)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.io.compress.Compression;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
/**
* HBase操作的工具类,封装了一下操作
* 1.
*/
public class HBaseUtil<T> {
/**
* 配置对象
*/
public static Configuration conf=null;
public static Connection conn=null;
public static Admin admin=null;
/**
* 初始化 conf
*/
static{
conf= HBaseConfiguration.create();
conf.addResource("core-site.xml");
conf.addResource("hbase-site.xml");
try {
conn = ConnectionFactory.createConnection(conf);
admin = conn.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 创建多列簇
* @param tableName
* @param columnFamilies
* @throws IOException
*/
public static void createTable(String tableName, String[] columnFamilies) throws IOException {
TableName table = TableName.valueOf(tableName);
if (admin.tableExists(table)) {
System.out.println("表已存在!");
return;
}
List<ColumnFamilyDescriptor> columnFamilyDescriptors = new ArrayList<>();
for (String columnFamily : columnFamilies) {
columnFamilyDescriptors.add(ColumnFamilyDescriptorBuilder.newBuilder(columnFamily.getBytes()).build());
}
TableDescriptor tableDescriptor =
TableDescriptorBuilder.newBuilder(table).setColumnFamilies(columnFamilyDescriptors).build();
admin.createTable(tableDescriptor);
System.out.println("表创建成功!");
}
/**
* 创建表
*/
public static void createMyTable(String tableName,String[] columnFamilies) {
try {
conn= ConnectionFactory.createConnection(conf);
admin= conn.getAdmin();
List<ColumnFamilyDescriptor> columnFamilyDescriptorList=new ArrayList<>();
//构建列簇
for(String columnFamily:columnFamilies){
ColumnFamilyDescriptor familyDescriptor=ColumnFamilyDescriptorBuilder.newBuilder(columnFamily.getBytes()).build();
columnFamilyDescriptorList.add(familyDescriptor);
}
//构建表
TableDescriptor table=TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName)).setColumnFamilies(columnFamilyDescriptorList).build();
//真正的创建表
admin.createTable(table);
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(admin!=null){
admin.close();
}
if(conn!=null){
conn.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 删除HBase表
*
* @param tableName 表名
*/
public static void deleteTable(String tableName) throws IOException {
Admin admin = conn.getAdmin();
TableName tn = TableName.valueOf(tableName);
if (admin.tableExists(tn)) {
admin.disableTable(tn);
admin.deleteTable(tn);
System.out.println("表删除成功!");
} else {
System.out.println("表不存在!");
}
admin.close();
}
/**
* 插入数据
*
* @param tableName 表名
* @param rowkey 行键
* @param columnFamily 列族名
* @param qualifier 列名
* @param value 列值
*/
public static void insertData(String tableName, String rowkey, String columnFamily, String qualifier,
String value) throws IOException {
Table table = conn.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowkey));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier), Bytes.toBytes(value));
table.put(put);
System.out.println("数据插入成功!");
table.close();
}
/**
* 批量插入数据
*
* @param tableName 表名
* @param rows 批量数据
*/
public static void batchInsertData(String tableName, List<Put> rows) throws IOException {
Table table = conn.getTable(TableName.valueOf(tableName));
table.put(rows);
System.out.println("数据插入成功!");
table.close();
}
/**
* 批量插入数据
* @param tableName 表名
* @param dataMap 待插入数据Map,其中key为行键,value为列值Map,列值Map中的key为列族名,value为列值
*
* @throws IOException
*/
public static void batchPut(String tableName, Map<String, Map<String, String>> dataMap) throws IOException {
// 获取表对象
Table table = conn.getTable(TableName.valueOf(tableName));
// 创建Put对象列表
List<Put> puts = new ArrayList<>();
for (String rowKey : dataMap.keySet()) {
Map<String, String> columnMap = dataMap.get(rowKey);
for (String columnFamily : columnMap.keySet()) {
String value = columnMap.get(columnFamily);
if (value != null) {
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(columnFamily), null, Bytes.toBytes(value));
puts.add(put);
}
}
}
// 插入数据
table.put(puts);
// 关闭表对象
table.close();
}
/**
根据行键获取数据
@param tableName 表名
@param rowkey 行键
@return Result 查询结果
*/
public static Result getDataByRowkey(String tableName, String rowkey) throws IOException {
Table table = conn.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowkey));
Result result = table.get(get);
if (!result.isEmpty()) {
System.out.println("查询结果:" + result.toString());
} else {
System.out.println("数据不存在!");
}
table.close();
return result;
}
/**
全表扫描
@param tableName 表名
@return List<Result> 查询结果列表
*/
public static List<Result> scanTable(String tableName) throws IOException {
List<Result> results = new ArrayList<>();
Table table = conn.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
results.add(result);
System.out.println("查询结果:" + result.toString());
}
table.close();
return results;
}
/**
* 分页扫描表
* @param tableName 表名
* @param startRowKey 起始行键
* @param stopRowKey 终止行键
* @param pageSize 页大小
* @return 分页扫描的结果列表
* @throws IOException
*/
public static List<Result> scan(String tableName, String startRowKey, String stopRowKey, int pageSize) throws IOException {
// 获取表对象
Table table = conn.getTable(TableName.valueOf(tableName));
// 创建Scan对象
Scan scan = new Scan();
// 设置起始行键
if (startRowKey != null && !startRowKey.equals("")) {
scan.withStartRow(Bytes.toBytes(startRowKey));
}
// 设置终止行键
if (stopRowKey != null && !stopRowKey.equals("")) {
scan.withStopRow(Bytes.toBytes(stopRowKey));
}
// 存储结果的列表
List<Result> resultList = new ArrayList<Result>();
// 获取结果扫描器
ResultScanner scanner = table.getScanner(scan);
// 当前添加的结果数
int count = 0;
// 遍历扫描器的每个结果
Result result;
while ((result = scanner.next()) != null) {
// 如果添加的结果数超过了所需的页大小,就退出循环
if (++count > pageSize) {
break;
}
// 将结果添加到列表中
resultList.add(result);
}
// 关闭扫描器和表对象
scanner.close();
table.close();
// 返回结果列表
return resultList;
}
/**
* 条件查询
* @param tableName 表名
* @param columnFamily 列族名
* @param column 列名
* @param operator 操作符,例如"==","!=",">","<",">=","<="
* @param value 值
* @return 结果集列表
* @throws IOException
*/
public static List<Result> filter(String tableName, String columnFamily, String column, String operator, String value) throws IOException {
// 获取表对象
Table table = conn.getTable(TableName.valueOf(tableName));
// 创建Scan对象
Scan scan = new Scan();
// 创建SingleColumnValueFilter对象
SingleColumnValueFilter filter = new SingleColumnValueFilter(Bytes.toBytes(columnFamily), Bytes.toBytes(column), getCompareOperator(operator), Bytes.toBytes(value));
filter.setFilterIfMissing(true);
scan.setFilter(filter);
// 获取结果集
List<Result> results = new ArrayList<>();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] resultValue = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
if (resultValue != null) {
results.add(result);
}
}
// 关闭表对象
table.close();
return results;
}
/**
删除数据
@param tableName 表名
@param rowkey 行键
@param columnFamily 列族名
@param qualifier 列名
*/
public static void deleteData(String tableName, String rowkey, String columnFamily, String qualifier)
throws IOException {
Table table = conn.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowkey));
if (qualifier != null) {
delete.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(qualifier));
}
table.delete(delete);
System.out.println("数据删除成功!");
table.close();
}
/**
* 多版本查询
* @param tableName 表名
* @param rowKey 行键
* @param columnFamily 列族名
* @param column 列名
* @param maxVersions 最大版本数
* @return 结果集列表
* @throws IOException
*/
public static List<Result> getVersion(String tableName, String rowKey, String columnFamily, String column, int maxVersions) throws IOException {
// 获取表对象
Table table = conn.getTable(TableName.valueOf(tableName));
// 创建Get对象
Get get = new Get(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
get.setMaxVersions(maxVersions);
// 获取结果集
List<Result> results = new ArrayList<>();
Result result = table.get(get);
Cell[] cells = result.rawCells();
for (Cell cell : cells) {
byte[] value = CellUtil.cloneValue(cell);
Result r = Result.create(Arrays.asList(cell));
results.add(r);
}
// 关闭表对象
table.close();
return results;
}
/**
* 获取比较操作符
* @param operator 操作符字符串
* @return 比较操作符
*/
private static CompareOperator getCompareOperator(String operator) {
switch (operator) {
case "==":
return CompareOperator.EQUAL;
case "!=":
return CompareOperator.NOT_EQUAL;
case ">":
return CompareOperator.GREATER;
case "<":
return CompareOperator.LESS;
case ">=":
return CompareOperator.GREATER_OR_EQUAL;
case "<=":
return CompareOperator.LESS_OR_EQUAL;
default:
return null;
}
}
/**
* 测试调用
* @param args
*/
public static void main(String[] args) throws IOException {
//创建表格
HBaseUtil.createTable("emp",new String[]{});
//添加单条数据
//批量添加
//
}
}
四、完成需求开发
在真正开发前需要把hadoop下的etc/hadoop/core-site.xml和hbase下的conf/hbase-site.xml配置文件拷贝出来添加到idea项目下的resources目录下
然后再去windows的C:\Windows\System32\drivers\etc\hosts文件下添加服务器主机网络映射
192.168.230.99 master
192.168.230.100 slave01
192.168.230.101 slave02
这样就可以在从配置文件中读取到master,slave01,slave02时找到服务器主机了
1.从windows本地读取文件写入Hbase
import com.example.hb.HBaseUtil;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.List;
/**
* 使用文件流读取文件内容,写入hbase
*/
public class ImportFileToHbase {
public static String fileName="stumer_in_out_details.txt";
public static String tableName="identify_rmb_records";
public static void main(String[] args) throws IOException, ParseException {
SimpleDateFormat format=new SimpleDateFormat("yyyy-MM-dd HH:mm");
List<Put> puts=new ArrayList<>();
String path = Thread.currentThread().getContextClassLoader().getResource(fileName).getPath();
BufferedReader bufferedReader=new BufferedReader(new FileReader(path));
String line;
while((line=bufferedReader.readLine())!=null){
String[] lines=line.split(",");
long timestamp=format.parse(lines[2]).getTime();
Put put=new Put(lines[0].getBytes(StandardCharsets.UTF_8));
put.addColumn("op_www".getBytes(StandardCharsets.UTF_8),"exist".getBytes(StandardCharsets.UTF_8),timestamp,lines[1].getBytes(StandardCharsets.UTF_8));
put.addColumn("op_www".getBytes(StandardCharsets.UTF_8),"Bank".getBytes(StandardCharsets.UTF_8),timestamp,lines[3].getBytes(StandardCharsets.UTF_8));
if (lines.length==4){
put.addColumn("op_www".getBytes(StandardCharsets.UTF_8),"uId".getBytes(StandardCharsets.UTF_8),timestamp,"".getBytes(StandardCharsets.UTF_8));
}else{
put.addColumn("op_www".getBytes(StandardCharsets.UTF_8),"uId".getBytes(StandardCharsets.UTF_8),timestamp,lines[4].getBytes(StandardCharsets.UTF_8));
}
puts.add(put);
}
//写入
HBaseUtil.batchInsertData(tableName,puts);
//读取
List<Result> results=HBaseUtil.scanTable(tableName);
for(Result result:results){
for(Cell cell:result.rawCells()){
System.out.println(new String(CellUtil.cloneRow(cell))+"|");
System.out.println(new String(CellUtil.cloneFamily(cell))+"|");
System.out.println(new String(CellUtil.cloneQualifier(cell))+"|");
System.out.println(new String(CellUtil.cloneValue(cell))+"|");
}
}
}
}
本文转载自: https://blog.csdn.net/jinxing_000/article/details/130039092
版权归原作者 金星000 所有, 如有侵权,请联系我们删除。
版权归原作者 金星000 所有, 如有侵权,请联系我们删除。