
没错这又是一次血案,不过是在测试环境发现的,还好不是上次线上导致的CPU300%,这次及时发现,避免了线上血案,不过我还是要复盘一下的,下面就看看我的分析,看看有没有什么错误的地方
场景描述
场景很简单,就是把我MySQL中一个表的数据全部迁移到ElasticSearch的一个新索引上(因为老的索引字段匹配不上,随着业务迭代MySQL的字段类型发生了变化,ES又没有办法动态更新,所以最简单的方法就是同步一次数据啦)
然后我就想当然的写了一段同步脚本,然后满怀信心的去开发环境自测,没问题啊,10W多条数据很快啊,当时直接就同步完了,一条数据不差,心里暗想,这次真简单,然后就提测,去测试环境跑数据了,然后血案就发生了~~~~~~
跑着跑着,测试姐姐就说测试环境不能用了,我想着我只是同步一个表的数据,就算有错应该也只是影响那个页面的查询吧,然后我就打开了测试环境页面,好家伙,每个页面都报错了,都是can not found url,再结合我们的ShenYU网关,就想到应该是节点崩了,没有Controller注册到网关上,所以请求就没办法映射。然后我就去容器里面看报错嘛,但是错误显示的是超时:ElasticSearch连接超时,ZK连接超时等等等等。比较茫然,这个错误没有太大的信息呀,师兄提醒我是不是内存崩了,但是我并没有看到OOM的提醒呀,所以我就顺着这个思路开始了排查
思路验证
想到可能是OOM的原因,为了测验,我就把代码的异步批量处理改成了同步单条索引,然后去测试环境验证(为什么不去开发环境?我下面会说到)
发现如果是同步单条跑的话,一点问题没有就是速度有点慢,那不行,生产几千万呢,算下来的话,几天也同步不完,但是我从这就确定了应该是内存的问题:是内存溢出了?还是内存泄漏了?接下来,看看我经过排查过后得到的重点代码(罪魁祸首)
//拉取5000条数据//这条SQL就是查询主键id > redis中已经同步过后的ID 的后5000条数据//为了减轻MySQL压力List<xxxDO> aDOS = xxxRepository.selectById(Integer.valueOf(redisService.get(idKey)));//同步数据中间逻辑省略//开始索引
xxxxEsService.indexEs(aDOS);//再来看看这个indexEs方法
aDOS.forEach(aDO ->{EsABO esABO =newEsABO();//把aDO转换成esABO然后
esHighLevelRestClient.bulkIndexAsync(Arrays.asList(esABO));}//罪魁祸手就是这个bulkIndexAsync接下来看看这个方法
publicvoidbulkIndexAsync(List<IDocument> dataList){if(CollectionUtils.isEmpty(dataList)){return;}BulkRequest request =newBulkRequest();
dataList.forEach(data ->{IndexRequest indexRequest =newIndexRequest(indexName,
mappingTypeName, data.documentId()).source(JSON.toJSONString(data),XContentType.JSON).routing(data.routing());
request.add(indexRequest);});long startTime =System.currentTimeMillis();
client.bulkAsync(request,RequestOptions.DEFAULT,newActionListener(){@OverridepublicvoidonResponse(Object o){
log.info("es index cost time:{}",System.currentTimeMillis()- startTime);}@OverridepublicvoidonFailure(Exception e){
log.error("es index fail, cost time:{}, Exception:",System.currentTimeMillis()- startTime, e);}});}
解释下,这个方法:就是传过来一条记录,然后这个记录就会被add方法添加到这个BulkRequest里面,然后ESClient会执行这个bulkAsync就去异步的同步数据了。这样看起来没啥问题啊,我下面再放一下这个bulkAsync方法的源码
publicfinalvoidbulkAsync(BulkRequest bulkRequest,RequestOptions options,ActionListener<BulkResponse> listener){performRequestAsyncAndParseEntity(bulkRequest,RequestConverters::bulk, options,BulkResponse::fromXContent, listener,emptySet());}
它里面就是对我们提交的这个bulkRequest处理的逻辑,看上去没什么问题,我再放一张图,大家看看能不能察觉到什么:
这是我本地跑Jprofiler存储到快照中的几张图
1.同步数据接口未开启的时候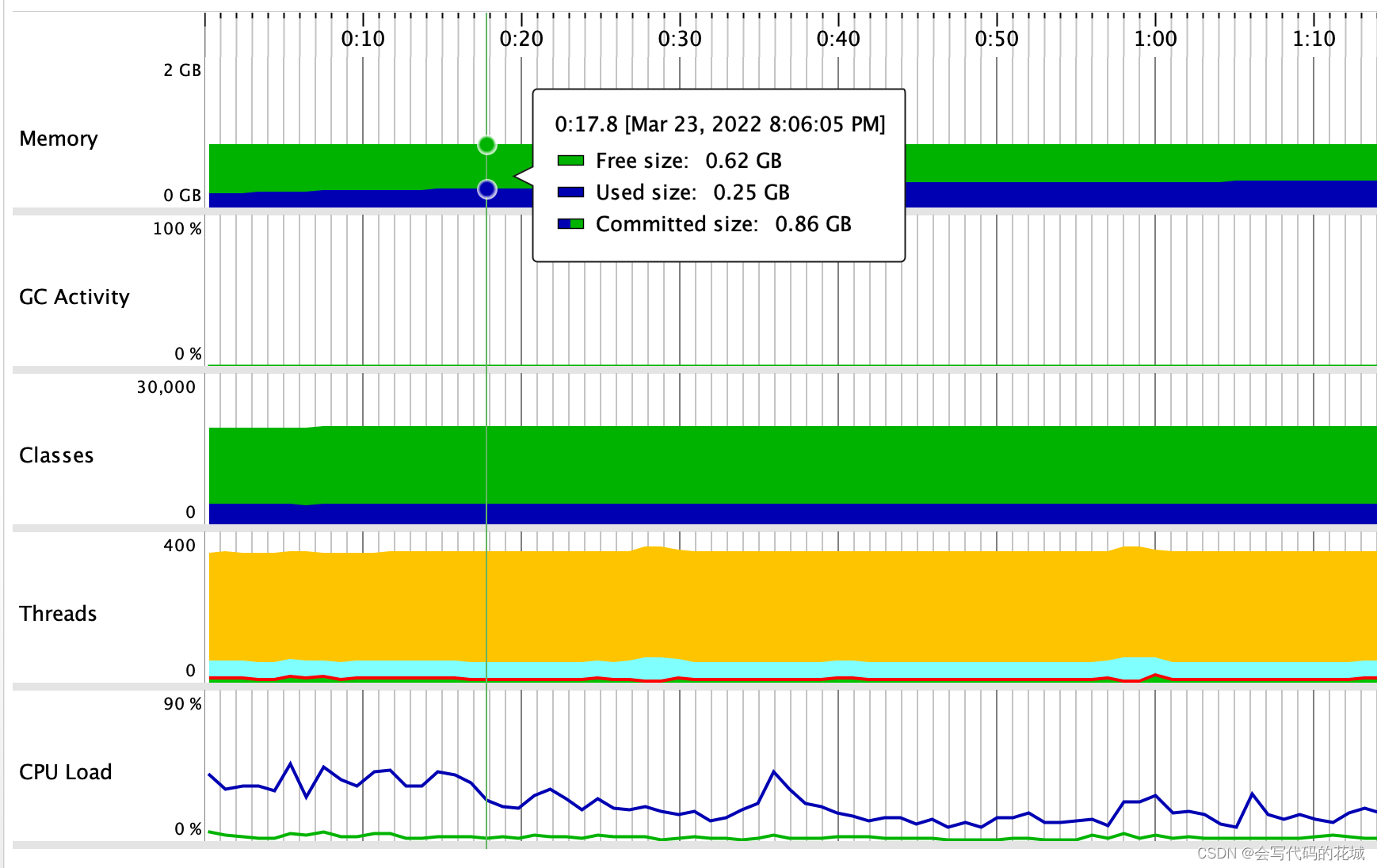
2. 同步数据开启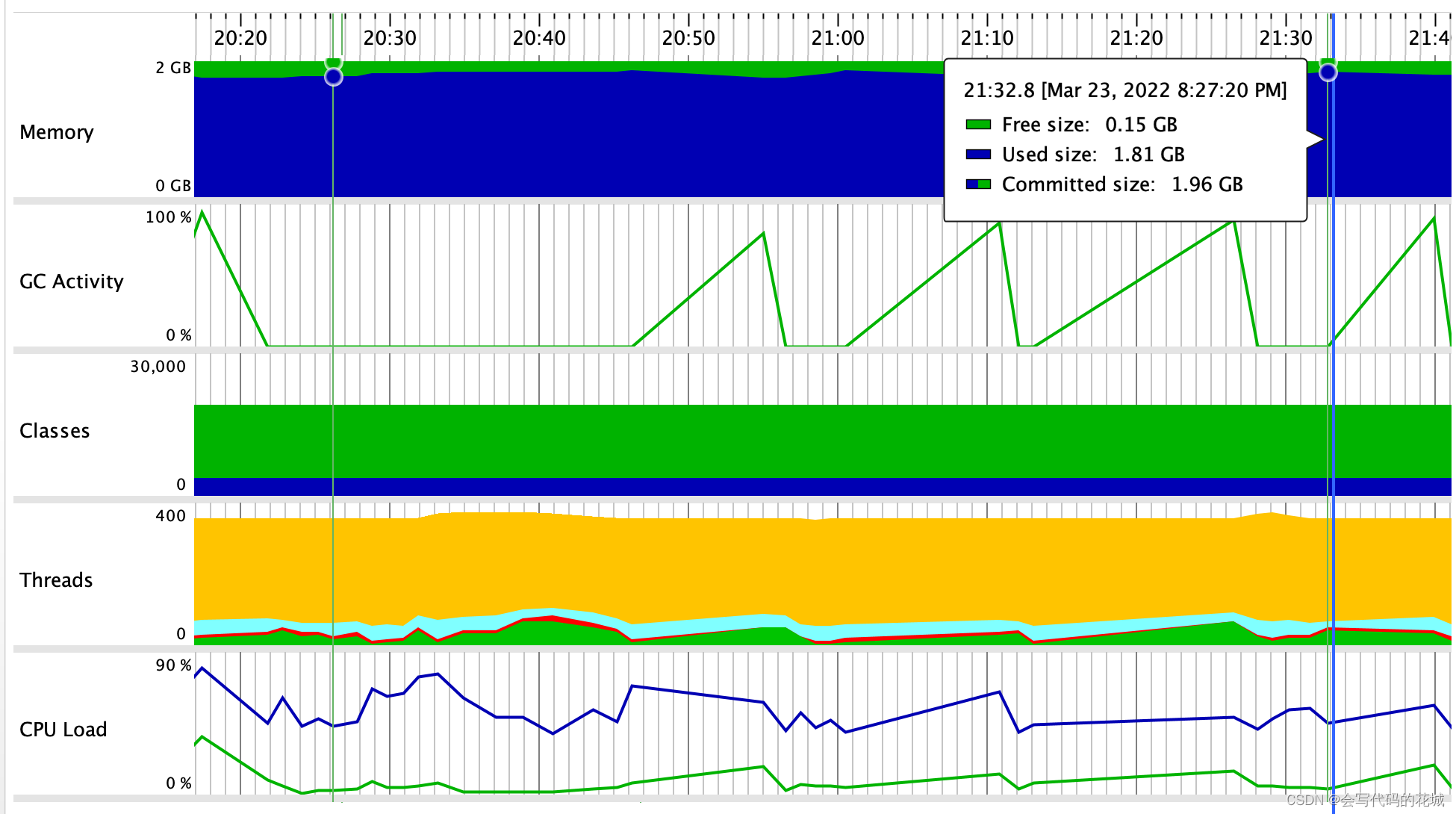
大家发现什么问题了么?
开启同步数据后,我的堆越来越大,这些也没什么,关键是经过GC之后,堆的大小并没有明显变化,问题就在这了,也就是说我的一个大对象并没有进行GC回收,是那个对象呢?没错就是那个bulkRequest
分析
一开始我拉出来5000条数据塞给这个bulkRequest,可能刚开始他能处理过来,并且进行了GC回收直接回收掉了,看下图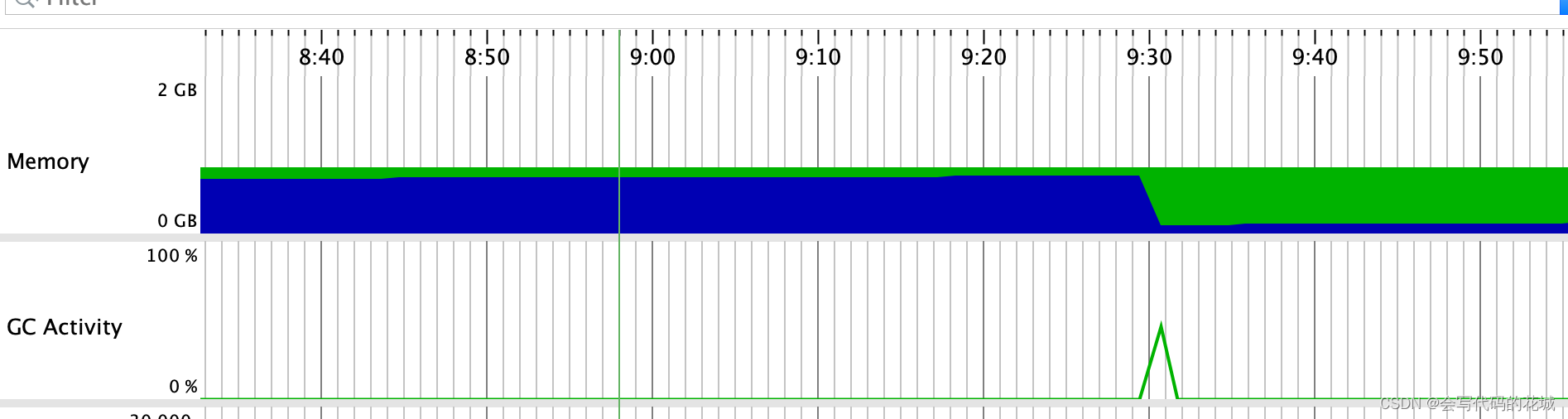
这个时候我们的速度应该能跟得上,但是我们的MySQL源源不断的塞给他5000,很快这个堆就又满了,但是我们的这个bulkRequest还没有同步完,还有强引用(可能现在这个bulkRequest里面有10W数据,但是前5W已经处理完了),也就是说随着速度跟不上来,导致这个bulkRequest越来愈大,而且以前处理过的也无法销毁,所以导致内存泄漏,进而系统内存OOM崩溃,但是为什么没有OOM,这个我只能猜测可能是速度太快,根本就没来得及然后系统就僵死了,一行日志都没有了,整个系统直接崩溃了
怎么解决?
关键原因就在于及时的回收已经处理过的request,所以采用另外一种批量处理方式
publicvoidbulkProcessorBatchInsert(List<EsUpdateEntityBO<T>> entityBOList){if(entityBOList.size()==0){return;}List<IndexRequest> indexRequests=newArrayList<>();//更新的数据
entityBOList.forEach(e->{//获取idIndexRequest indexRequest =newIndexRequest();
indexRequest.routing(e.getRouting());
indexRequest.index(indexName);
indexRequest.type(mappingTypeName);//更新的id
indexRequest.id(e.getDocumentId());//更新的数据String jsonString = JSON.toJSONString(e.getT());
indexRequest.source(jsonString,XContentType.JSON);
indexRequests.add(indexRequest);});
indexRequests.forEach(bulkProcessor::add);}
这不是和刚才的一样么?其实不一样,因为关键代码在下面
我在建立ES客户端的时候是这样的
privateBulkProcessorcreateBulkProcessor(RestHighLevelClient restHighLevelClient,Boolean async){//中间很多逻辑BulkProcessor.Builder builder;if(async){//异步//这里也有很多逻辑}//到达1000条时刷新
builder.setBulkActions(2000);//内存到达8M时刷新
builder.setBulkSize(newByteSizeValue(8L,ByteSizeUnit.MB));//设置的刷新间隔1s
builder.setFlushInterval(TimeValue.timeValueSeconds(1));//设置允许执行的并发请求数。
builder.setConcurrentRequests(8);//设置重试策略
builder.setBackoffPolicy(BackoffPolicy.constantBackoff(TimeValue.timeValueSeconds(1),3));return builder.build();}
关键点就在于,我不无限制的处理请求,每当我的bucket攒够2000条,或者我的内存达到了8M,或者已经距离上次处理间隔了1S了我就主动进行刷盘(同步数据)操作,这样的话就能避免上面那种情况了
难道ES官方不知道这个问题么?我看了官方文档,确实没找到他这个 bulkAsync中这个BulkRequest bulkRequest有什么刷盘策略,难道就是无限制增长么?这个我还没有看完他的源码,可能自己的能力也不够,如果有老哥知道,评论区留言
至此用了新的异步批量请求的操作,测试环境很快很安全的同步了数据,而且预发环境的上千万的数据也很快很安全的同步完成,我心中的大石头终于放下来了
分享就到这了,如果有什么不对的地方,请大佬指出,我也好改正学习下
好了,写代码去了
版权归原作者 会写代码的花城 所有, 如有侵权,请联系我们删除。