
简介
Alluxio 是世界上第一个虚拟的分布式存储系统,以内存速度统一了数据访问。
它为计算框架和存储系统构建了桥梁,使应用程序能够通过一个公共接口连接到许多存储系统。 Alluxio以内存为中心的架构使得数据的访问速度能比现有方案快几个数量级。 简单来说,Alluxio是一个分布式文件系统,是数据驱动框架或应用如
Apache Spark、Presto、Tensorflow、Apache HBase、Apache Hive 或 Apache
Flink)和持久化存储系统(如 Amazon S3、Google Cloud Storage、OpenStack
Swift、HDFS、GlusterFS、IBM Cleversafe、EMC ECS、Ceph、NFS 、Minio和 Alibaba OSS)的连接纽带。
下图就很清晰的解释了Alluxio和数据驱动以及存储系统之间的关系。
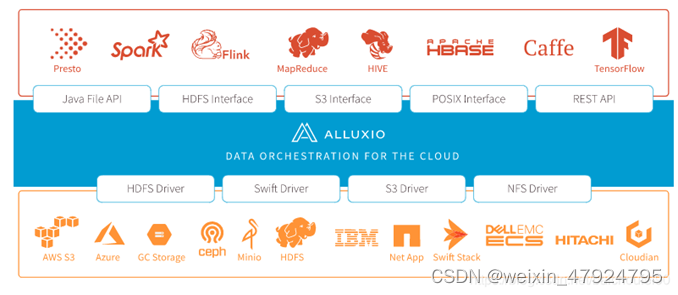
一、安装约定
- 采用CentOS的Linux操作系统,运行在3台虚拟机上,其配置如下: 1、ALLUXIO_001 2、ALLUXIO_002 3、ALLUXIO_003
- 基础软件版本约定 1、JDK Jdk_1.8.16 + 不建议使用Open JDK 2、Alluxio 2.8.0 3、Zookeeper 3.6.3 4、Hadoop 3.1.4 5、MinIO
二、 安装部署
2.1 下载
Alluxio官网下载链接:https://www.alluxio.io/download/
2.2 ssh免密登录
2.2.1 在ALLUXIO_001机器上依次执行以下命令:
ssh-keygen -t rsa #生成免密登录公私钥,根据提示按回车或y
2.2.2
ls-lha #.ssh目录默认隐藏,可使用ls -lha 查看
2.2.3
cd /root/.ssh/ #进入.ssh 公私钥存放目录
2.2.4
ll #查看目录文件
id_rsa #生成的私钥文件 id_rsa.pub #生成的公钥文件
authorized_keys #存放远程免密登录的公钥,主要通过这个文件记录多台机器的公钥(如没有,可touch 创建)
know_hosts #已知的主机公钥清单 (默认没有,上传公钥后自动生成)
2.2.5上传公钥至ALLUXIO_002和ALLUXIO_003,实现免密登录
ssh-copy-id-i ~/.ssh/id_rsa.pub [email protected] (x.x.x.x 为远程系统的IP地址,根据自己远程机器的IP填写)#将本机的公钥上传至 x.x.x.x 机器上,实现对x.x.x.x 机器免密登录
2.3 安装Alluxio
tar –zxvf alluxio-2.8.0-bin.tar.gz -C /opt/bigdata/
三、 配置Alluxio
3.1 修改配置文件
$$ cd /opt/bigdata/
$$ mv alluxio-2.8.0 alluxio
$$ cd alluxio
$$ cd conf
$$ alluxio-site.properties.template alluxio-site.properties
$$ vim alluxio-site.properties
修改内容如下:
alluxio.master.mount.table.root.ufs=hdfs://HADOOP_001:9090/alluxio
master配置属性alluxio.master.mount.table.root.ufs指定的目录挂载到Alluxio命名空间根目录(指Alluxio的基础存储空间),该目录代表Alluxio的”primary storage”。在此基础上,用户可以通过挂载API添加和删除(指挂载多个底层存储)
3.2 HA配置
Alluxio的高可用需要配置 $ALLUXIO_HOME/conf/ 下的3个文件,alluxio-env.sh 和masters、worker三个文件。
3.2.1 主机和角色分布:机器够用的话可以适当的把master和worker分开,后续配置上修改即可,角色如下:
编号 主机名 角色
1 ALLUXIO_001 master、worker
2 ALLUXIO_001 master、worker
3 ALLUXIO_001 worker
3.2.2 配置masters、workers
- 配置文件 : masters
ALLUXIO_001
ALLUXIO_002
- 配置文件 : workers
ALLUXIO_001
ALLUXIO_002
ALLUXIO_003
3.2.3 节点同步设置
(base)[root@clu00 bin]./alluxio copyDir /root/alluxio-2.8.0
RSYNC'ing /root/alluxio-2.6.0 to masters...
clu00
RSYNC'ing /root/alluxio-2.6.0 to workers...
clu01
clu02
注:master和worker的alluxio-env.sh文件不同,需单独配置。
3.2.4 ALLUXIO_001的master配置,配置文件 alluxio-env.sh
export JAVA_HOME=/home/softwares/jdk1.8.0_202
export ALLUXIO_MASTER_HOSTNAME= ALLUXIO_001
export ALLUXIO_WORKER_MEMORY_SIZE=10240M
export ALLUXIO_JAVA_OPTS+=”
-Dalluxio.zookeeper.enabled=true
-Dalluxio.zookeeper.address=zookeeper01:2181,zookeeper02:2182,zookeeper03:2181
- Dalluxio.master.journal.folder=
注:alluxio.master.journal.folder=为共享日志位置的URI,以供Alluxio leading master写入日志,以及做为standby masters重播日志条目依据。
3.2.5 ALLUXIO_002的master配置,配置文件 alluxio-env.sh
export JAVA_HOME=/home/softwares/jdk1.8.0_202
export ALLUXIO_MASTER_HOSTNAME= ALLUXIO_002
export ALLUXIO_WORKER_MEMORY_SIZE=10240M
export ALLUXIO_JAVA_OPTS+=”
-Dalluxio.zookeeper.enabled=true
-Dalluxio.zookeeper.address=zookeeper01:2181,zookeeper02:2182,zookeeper03:2181
- Dalluxio.master.journal.folder=
3.2.6 ALLUXIO_003 worker节点,无需配置ALLUXIO_MASTER_HOSTNAME,配置文件 alluxio-env.sh
export JAVA_HOME=/home/softwares/jdk1.8.0_202
export ALLUXIO_WORKER_MEMORY_SIZE=10240M
export ALLUXIO_JAVA_OPTS+=”
-Dalluxio.zookeeper.enabled=true
-Dalluxio.zookeeper.address=zookeeper01:2181,zookeeper02:2182,zookeeper03:2181
- Dalluxio.master.journal.folder=
3.3 在master节点上,使用以下命令格式化Alluxio
./bin/alluxio format
3.4 挂载
#(仅仅初次启动需要挂载)./bin/alluxio-start.sh all SudoMount
$$ all 将启动master节点和所有workers节点
$$ SudoMount 参数将帮助workers节点挂载到RamFS上,仅仅初次启动需要挂载
四、常用命令
4.1 启动、停止集群
# ./bin/alluxio-start.sh all# ./bin/alluxio-stop.sh all# ./bin/alluxio-start.sh masters# ./bin/alluxio-start.sh workers # ./bin/alluxio-start.sh master# ./bin/alluxio-start.sh worker
4.2 验证集群
http://<alluxio_master_hostname>:19999 #查看master节点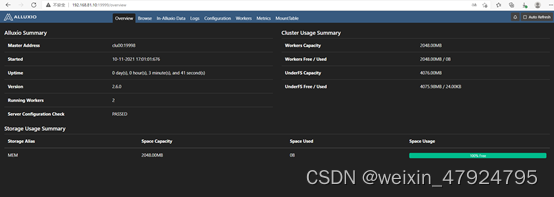
http://<alluxio_worker_hostname>:30000 #查看worker节点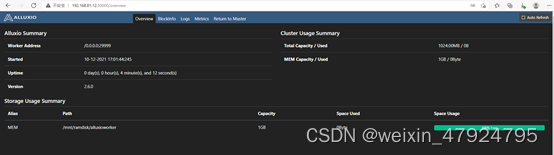
Master上能看到AlluxioMaster、AlluxioJobMaster、AlluxioProxy
# jps
26578 AlluxioProxy
27190 Jps
15670 NameNode
25515 AlluxioMaster
26014 AlluxioJobMaster
Worker上能看到AlluxioWorker、AlluxioJobWorker、AlluxioProxy
# jps
22657 DataNode
25250 AlluxioWorker
25477 AlluxioJobWorker
26151 Jps
25759 AlluxioProxy
4.3 添加新的worker节点
动态添加worker到Alluxio集群就像通过适当配置启动新Alluxio worker进程一样简单。 在大多数情况下,新worker配置应与所有其他worker配置相同。 在新worker上运行以下命令,以将其添加到集群
./bin/alluxio-start.sh worker SudoMount
一旦worker启动,它将在Alluxio master上注册,并成为Alluxio集群的一部分。
减少worker只需要简单停止一个worker进程。(停止本地 worker)
./bin/alluxio-stop.sh worker
一旦worker被停止,master将在预定的超时值(通过master参数
alluxio.master.worker.timeout
配置)后将此worker标记为缺失。 主机视worker为“丢失”,并且不再将其包括在集群中。
五、Alluxio应用场景配置
5.1 与HDFS配置

5.1.1
将hadoop安装目录下的hdfs-site.xml和core-site.xml文件拷贝或者符号连接到${ALLUXIO_HOME}/conf目录下。确保在所有正在运行Alluxio的服务端上设置了。
5.1.2
修改conf/alluxio-site.properties文件,将底层存储系统的地址设置为HDFS
namenode的地址以及你想挂载到Alluxio根目录下的HDFS目录。
alluxio.master.mount.table.root.ufs=hdfs://HADOOP_001:9090/alluxio
5.1.3 Kerberos认证
1)可选配置项,你可以为自定义的Kerberos配置设置jvm级别的系统属性:java.security.krb5.realm和java.security.krb5.kdc。这些Kerberos配置将Java库路由到指定的Kerberos域和KDC服务器地址。如果两者都设置为空,Kerberos库将遵从机器上的默认Kerberos配置。例如:
- 如果使用的是Hadoop,你可以将这两项配置添加到
${HADOOP_CONF_DIR}/hadoop-env.sh文件的HADOOP_OPTS配置项。
$ export HADOOP_OPTS="$HADOOP_OPTS -Djava.security.krb5.realm=<YOUR_KERBEROS_REALM> -Djava.security.krb5.kdc=<YOUR_KERBEROS_KDC_ADDRESS>"
- 如果你使用的是Spark,你可以将这两项配置添加到
${SPARK_CONF_DIR}/spark-env.sh文件的SPARK_JAVA_OPTS配置项
SPARK_JAVA_OPTS+=" -Djava.security.krb5.realm=<YOUR_KERBEROS_REALM> -Djava.security.krb5.kdc=<YOUR_KERBEROS_KDC_ADDRESS>"
- 如果你使用的是Alluxio Shell,你可以将这两项配置添加到
conf/alluxio-env.sh文件的ALLUXIO_JAVA_OPTS配置项。
ALLUXIO_JAVA_OPTS+=" -Djava.security.krb5.realm=<YOUR_KERBEROS_REALM> -Djava.security.krb5.kdc=<YOUR_KERBEROS_KDC_ADDRESS>"
2)Alluxio服务器Kerberos认证
在
alluxio-site.properties
文件配置下面的Alluxio属性:
alluxio.master.keytab.file=<YOUR_HDFS_KEYTAB_FILE_PATH>
alluxio.master.principal=hdfs/<_HOST>@<REALM>
alluxio.worker.keytab.file=<YOUR_HDFS_KEYTAB_FILE_PATH>
alluxio.worker.principal=hdfs/<_HOST>@<REALM>
5.1.4 挂载HDFS目录
bin/alluxio fs mount/hdfs hdfs://HADOOP_001:8082/user
注:该命令将 HDFS 的 /user 目录挂载到 alluxio 的 /hdfs 子目录下。
挂载成功后,通过
alluxio fs ls
命令,查看挂载内容。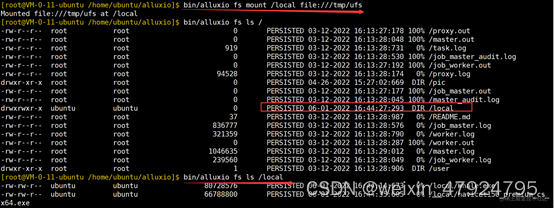
5.1.5 加载数据
把 Alluxio 中的某个文件加载到 Alluxio 空间中。当使用 fs mount 挂载后,只是相当于把 Alluxio 和底层存储系统连接起来。可以使用 fs load 将文件(数据)加载到 Alluxio 的空间中,也就是把文件(数据)移到 worker 节点。
bin/alluxio fs load /hdfs
5.2 与MinIO配置

5.2.1
第一个修改是指定一个现存MinIO存储桶和目录作为底层存储系统。 由于Minio支持s3协议,因此可以将Alluxio配置为 仿佛指向一个AWS S3 endpoint。
vim alluxio-site.properties
添加以下内容:
alluxio.master.mount.table.root.ufs=s3://state/alluxio
alluxio.underfs.s3.endpoint= http://10.238.222.22:9000
alluxio.underfs.s3.disable.dns.buckets=true
alluxio.underfs.s3.inherit.acl=false
s3a.accessKeyId=admin
s3a.secretKey=minio@123
5.2.2 挂载
./bin/alluxio fs mount
\ --option s3a.accessKeyId=<admin>
--option s3a.secretKey=<minio@123> \
/s3 s3://data-bucket/
5.2.3 确认挂载后的目录在Alluxio中存在:
./bin/alluxio fs ls-R /
5.3 与Flink配置

5.3.1 在hadoop的core-site.xml中设置属性
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
5.3.2 将alluxio-2.8.0-client.jar文件放在Flink的lib目录下
5.3.3 将Alluxio额外属性转化为Flink属性
如果
conf/alluxio-site.properties
和客户端相关的配置文件中有任何指定的属性,请在
{FLINK_HOME}/conf/flink-conf .yaml
文件中将这些属性转化为
env.java.opts
,从而方便Flink使用Alluxio的配置。例如,如果你想要将CACHE_THROUGH作为Alluxio客户端的写文件方式 ,你应该在
{FLINK_HOME}/conf/flink-conf.yaml
增加如下配置
env.java.opts: -Dalluxio.user.file.writetype.default=CACHE_THROUGH
注:如果有正在运行的Flink集群,需要将该集群停止并重新运行以应用更改后的配置。
5.3.4 在Flink中使用Alluxio
有效路径类似于:
alluxio:// ALLUXIO_001:19998/user/hduser/gutenberg
5.4 与Trino(Presto)配置

Trino是一个开源的分布式SQL查询引擎,用于大规模运行交互式数据分析查询。本指南介绍了如何使用Alluxio作为分布式缓存层,针对Alluxio支持的任何数据存储系统(AWS S3、HDFS、Azure Blob Store、NFS等),对Trino运行查询。Alluxio允许Trino访问数据,而不考虑数据源,并将频繁访问的数据(例如,常用的表)透明地缓存到Alluxio分布式存储中。当其他存储系统处于远程或网络缓慢或拥塞状态时,将Alluxio工作人员与Trino工作人员合用可提高数据的本地性并减少I/O访问延迟。
5.4.1 使用Trino与Alluxio目录服务
1、 目前,有两种方式可以让Trino与Alluxio交互:
- Trino与Alluxio目录服务交互
- Trino直接与Hive Metastore交互(更新表定义以使用Alluxio路径)
2、使用Trino与Alluxio目录服务的主要好处是:
- 使用Trino简化Alluxio的部署(无需修改Hive Metastore)启用模式感知优化(转换,如合并和文件转换)。
- 目前,目录服务仅限于只读工作负载。
5.4.2 基础设置
(1)配置 Trino 连接到 Hive Metastore
Trino通过Trino的Hive连接器从Hive Metastore获取数据库和表元数据信息(包括文件系统位置)。下面是一个示例Trino配置文件
${Trino_HOME}/etc/catalog/hive.properties。
connector.name=iceberg
hive.metastore.uri=thrift://10.238.232.211:9083
将Alluxio客户端jar分发到所有Trino服务器
把 Alluxio 客户端 jar 包
/<PATH_TO_ALLUXIO>/client/alluxio-2.8.0-client.jar
放到所有 Trino 服务器的
${PRESTO_HOME}/plugin/hive-hadoop2/
目录(该目录可能会因版本而不同)中。重启 Trino 服务:
bin/launcher restart
(3)启动 Hive metastore
/bin/hive --service metastore
(4)启动 Trino 服务器
/bin/launcher run
(5)使用 Trino查询表
下载
trino-cli-<Trino_VERSION>-executable.jar
重命名为
trino
,(有时
${PRESTO_HOME}/bin/presto
中存在可执行的
trino
,你可以直接使用它)运行简单的查询:
./trino --server localhost:8080 --execute "use default; select * from u_user limit 10;"--catalog hive --debug
5.4.3 高级设置
(1)自定义 Alluxio 用户属性
要配置其他 Alluxio 属性,可以将包含
alluxio-site.properties
的配置路径(即${ALLUXIO_HOME}/conf)追加到 Trino文件夹下的etc/jvm.config的 JVM 配置中。 这种方法的优点是能够在同一个
alluxio-site.properties
文件中设置所有的 Alluxio 属性。
-Xbootclasspath/a:<path-to-alluxio-conf>
或者,将Alluxio属性添加到Hadoop配置文件(
core-site.xml
、
hdfs-site.xml
),并使用Trino属性hive.config。文件
${Trino_HOME}/etc/catalog/hive
中的资源。属性来指向每个Trino工作者的Hadoop资源位置。
hive.config.resources=/<PATH_TO_CONF>/core-site.xml,/<PATH_TO_CONF>/hdfs-site.xml
5.4.4 示例:连接HA模式的Alluxio
要使用容错模式的 Alluxio,需要在 classpath 中的
alluxio-site.properties
文件中适当设置 Alluxio 集群的属性。
alluxio.master.rpc.addresses=master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998
或者,你可以将属性添加到hadoop的
core-site.xml
配置中。
<configuration>
<property>
<name>alluxio.master.rpc.addresses</name>
<value>master_hostname_1:19998,master_hostname_2:19998,master_hostname_3:19998</value>
</property>
</configuration>
5.4.5 示例:更改 Alluxio 默认写类型
例如,更改
alluxio.user.file.writetype.default
,从默认的MUST_CACHE改为CACHE_THROUGH。
一种方法是在
alluxio-site.properties
中设置属性,并将此文件分发到每个 Hive 节点的 classpath:
alluxio.user.file.writetype.default=CACHE_THROUGH
或者,更改
conf/hive-site.xml
:
<property>
<name>alluxio.user.file.writetype.default</name>
<value>CACHE_THROUGH</value>
</property>
5.4.6 避免 Trino 读取大文件超时
建议将
alluxio.user.streaming.data.timeout
增加到较大的值(例如10min),以避免从远程的 worker 读取大文件时超时失败。
版权归原作者 weixin_47924795 所有, 如有侵权,请联系我们删除。