
前置配置:
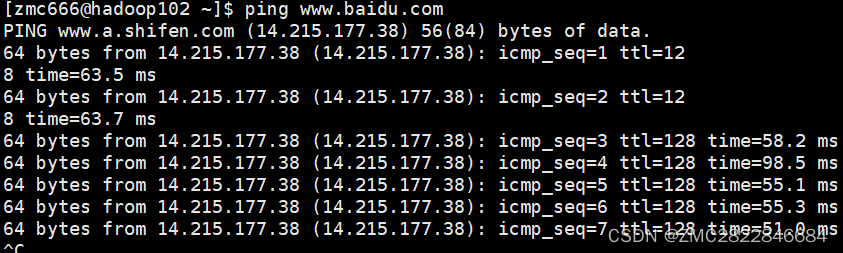
1.保证虚拟机网络畅通:ping www.baidu.com
2. 在root模式下创建一个hadoop(名字随便取【本人取的zmc666】)用户
useradd hadoop(自己取一个名字)
passwd hadoop
会让你设置密码:两次输入一致的密码即可(不用管提示密码长度)

3.配置完密码接着输入:
vim /etc/sudoers
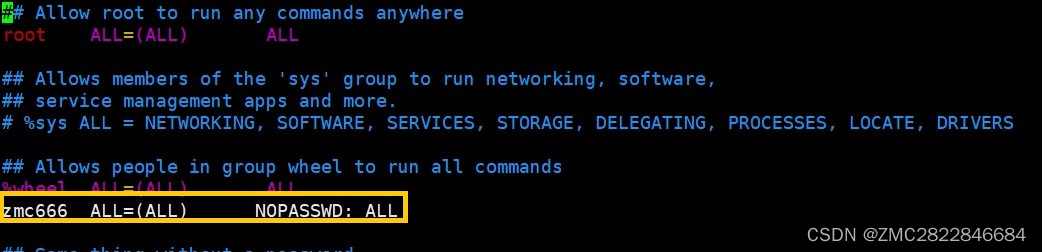
4. 在图示金色框位置加上一行:再强调一下这里(zmc666)是上面自己创建的用户(hadoop是比喻)
zmc666 ALL=(ALL) NOPASSWD: ALL
按Esc 输入(:wq!)保存退出
reboot重启虚拟机切换到(你刚创建)的用户 进入下一阶段配置

第一步:下载本次安装所需要的软件包
创建目录:进入opt目录创建 module 和software 两个文件夹
cd /opt
mkdir module
mkdir software
software:下载的文件压缩包存放位置
module : 解压后文件所在位置
下载python:
cd software
wget https://www.python.org/ftp/python/3.10.4/Python-3.10.4.tgz
下载hadoop:
wget https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
下载spark:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.2.2/spark-3.2.2-bin-without-hadoop.tgz
下载java-jdk:(需要登陆才可下载)
点击此处跳转Java官网
https://www.oracle.com/java/technologies/downloads/#java8

因为官网要登陆才可以下载,所以推荐几个镜像网址:
https://repo.huaweicloud.com/java/jdk/
下载方法 wget +jdk文件路径
或者进入百度网盘直接下载四个压缩包:(如果直接点击打不开,可以试试复制在微信中打开随便发给一个好友[例如:微信传输助手打开]),** 再打不开就没办法了(老老实实自己下吧)**
链接:https://pan.baidu.com/s/1s2Saq7VJm2l-qyK3KS3EgQ?pwd=9zxk
提取码:9zxk
第二步:解压下载的文件至module文件夹
tar -zxvf java压缩包名 -C /opt/module
tar -zxvf spark压缩包名 -C /opt/module
tar -zxvf hadoop 压缩包名 -C /opt/module
例如:

tar -zxvf python压缩包名 -C /usr/local/src
**如果提示没有权限之类的:可以试试 **
cd /opt
sudo chmod 777 module
sudo chmod 777 software
sudo chmod 777 /usr/local/src
第三步:配置环境变量
Java环境变量配置
1.卸载原linux系统Java环境
#su 进入root模式
su root
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps

reboot 重启虚拟机
2.新建一个sh文件:
sudo vim /etc/profile.d/my_env.sh

3.将以下内容粘贴进去
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212 #java解压在什么路径就怎么写,不要硬套
export PATH=$PATH:$JAVA_HOME/bin

4.source 一下/etc/profile
source /etc/profile
5.查看Java是否安装正确

hadoop环境变量配置
1.编辑刚刚新建的my_env.sh
sudo vim /etc/profile.d/my_env.sh
- 加入以下内容
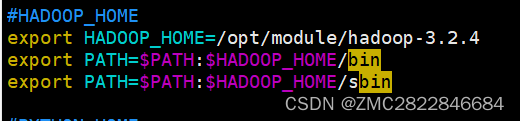
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.2.4 #同理,这里是解压后hadoop文件所在位置
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
3.source 一下/etc/profile
source /etc/profile
4.输入hadoop查看是否有反应:出现如下图就说明没问题

** 配置python环境变量:要麻烦一些**
cd /usr/local/src
ls

会显示我们刚刚解压到这里的python文件 cd 进去
cd Python-3.10.4
1.安装python所需要的依赖包
sudo yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make
2.配置python的安装路径:/usr/local/python3
sudo yum install libffi-devel -y #如果没有这一步python没问题,但后面spark用起来有问题
./configure --prefix=/usr/local/python3 #这里我选择将python安装到/usr/local/python3中
make && make install #如果提示没有权限 可以输入: sudo chmod 777 local
3.继续编辑之前创建的my_env.sh
sudo vim /etc/profile.d/my_env.sh
加上
#PYTHON_HOME
export PYTHON_HOME=/usr/local/python3 #刚刚“安装”python3的路径:
#注意不是解压的位置,和java不同
export PATH=$PATH:$PYTHON_HOME/bin

spark环境变量配置
**1.**修改Spark的配置文件spark-env.sh
cd /opt/module
ln -s spark -3.2.2-bin-without-hadoop/ /opt/module/spark #创建软连接,文件名太长不方便
cd /opt/module/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh #这里很重要,没有这一步spark启动不了

编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/opt/module/hadoop-3.2.4/bin/hadoop classpath)
#这里的(/opt/module/hadoop-3.2.4/)部分是Hadoop解压后的路径,至于后面的(/bin/hadoop classpath)不用改
2.继续编辑之前创建的my_env.sh
sudo vim /etc/profile.d/my_env.sh
加上
#SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.5-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop

这里的(export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.5-src.zip:$PYTHONPATH )红色字体部分视自己情况而定,可以输入以下命令查看
cd /opt/module/spark/python/lib/
ls

3.source 一下/etc/profile
source /etc/profile
4.看看 /opt/module/spark/bin 下 ./pyspark 命令是否可用
cd /opt/module/spark/bin
./pyspark
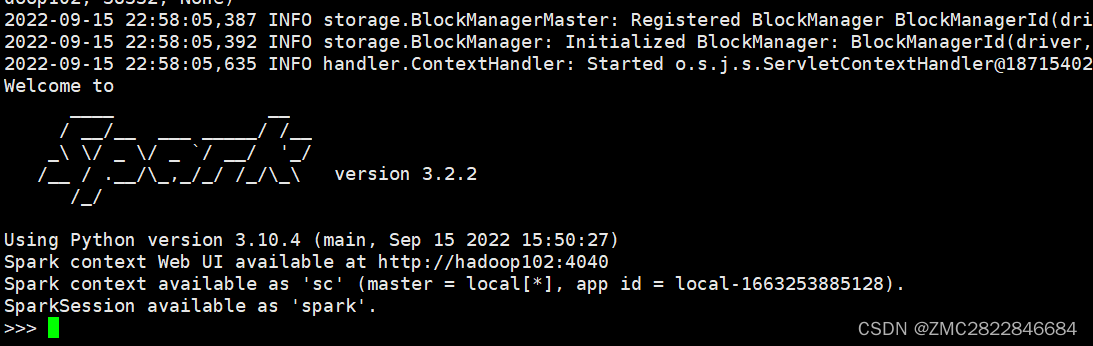
5.出现下图所示即表示配置完成
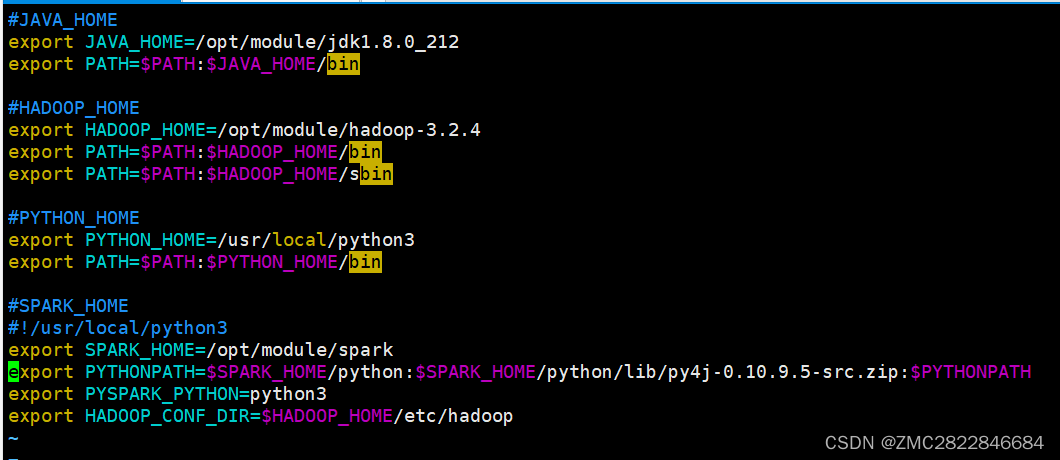
完整版my_env.sh环境配置一览
配置完成
exit()退出
运行一下如下代码
cd /opt/module/spark
bin/run-example SparkPi 2>&1 | grep "Pi is"
会出现:

** 到这里配置环境变量就完成了**
版权归原作者 ZMC2822846684 所有, 如有侵权,请联系我们删除。