
文章目录
概要
项目要求
根据电商日志文件,分析:
- 统计页面浏览量(每行记录就是一次浏览)
- 统计各个省份的浏览量 (需要解析IP)
- 日志的ETL操作(ETL:数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程)
为什么要ETL:没有必要解析出所有数据,只需要解析出有价值的字段即可。本项目中需要解析出:ip、url、pageId(topicId对应的页面Id)、country、province、city
整体架构流程
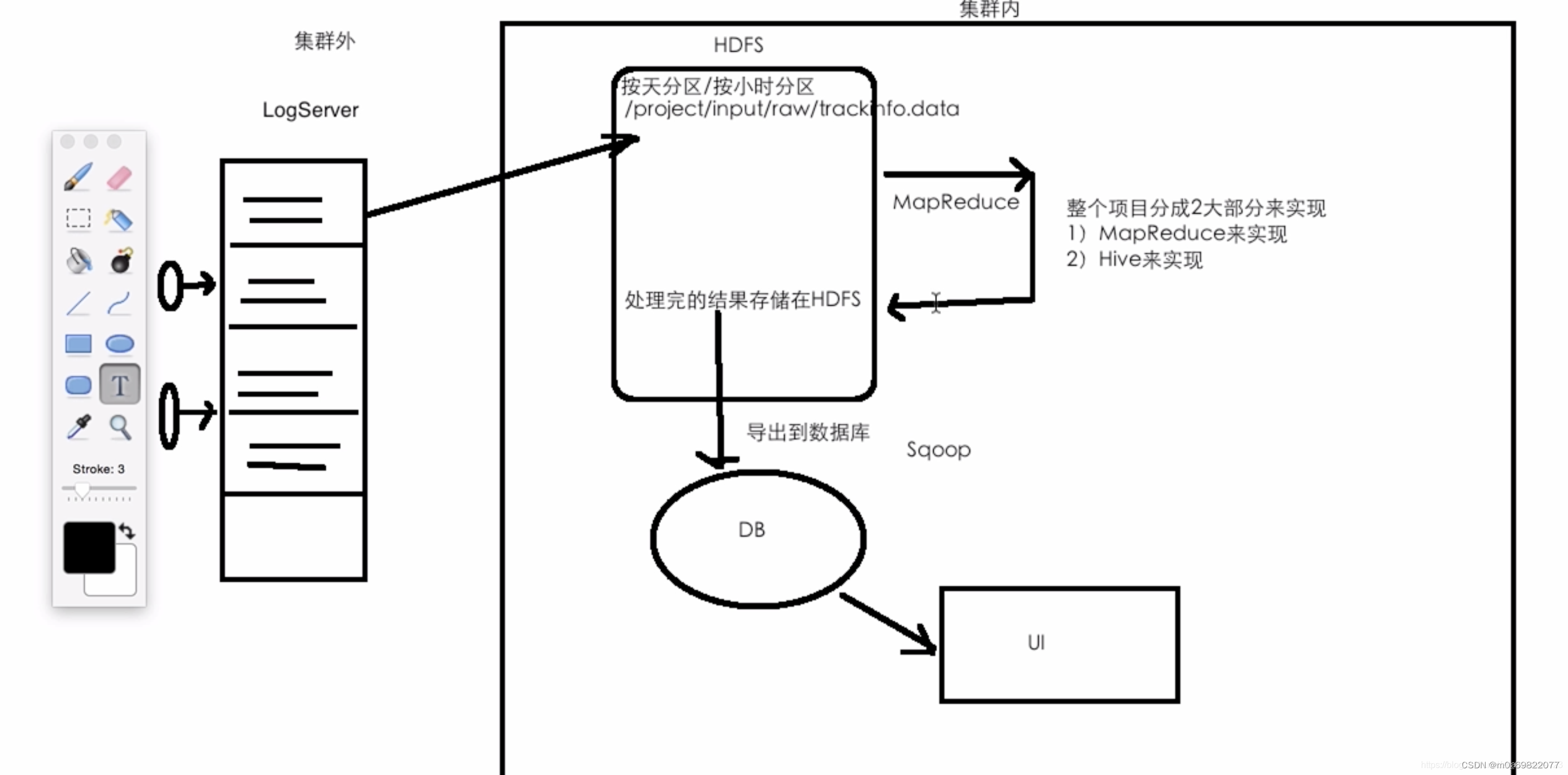
技术
- Hadoop
- Idea,MapReduce
问题分析
问题1
Map阶段,对于每一条数据,设置一个默认键(只用于标记该行),值设置为1。Reduce阶段,获得所有的值的和即可。
问题2
我们需要提取每一条数据中的ip,在Map阶段使用ip解析的工具类,将每个ip对应到所属省份,将未知ip设置为默认值,得到的省份作为键,值设置为1。Reduce阶段合并相同的键并将对应值求和。
问题3
这里我们需要提取每一条数据中的ip、url、pageId、contry、province、city字段。其中ip、url 和 pageId可以直接通过字符串的处理得到。contry、province 和 city 通过定义的工具类进行处理后得到。
代码
问题一.统计页面浏览量
总体思路:
1.Mapper阶段:P1Mapper 对每一行输入数据输出键值对 (“line”, 1)。
2.Shuffle和Sort阶段:框架会自动将具有相同键的值聚集到一起。
3.Reducer阶段:P1Reducer 接收键 (“line”) 和所有的 1,并将这些值累加,最终输出键值对 (“line”, 总行数)
Mapper
package mr1;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;publicclassP1MapperextendsMapper<LongWritable, Text, Text, IntWritable>{
@Override
protectedvoidmap(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(newText("line"),newIntWritable(1));}}
extends Mapper<LongWritable, Text, Text, IntWritable>:表明这个类继承了 Mapper 类,其中泛型参数指定了输入和输出类型:
输入键类型:LongWritable(每行文本的偏移量)。
输入值类型:Text(一行文本内容)。
输出键类型:Text(这里用作标记字符串 "line")。
输出值类型:IntWritable(这里用作计数,值为1)
Reducer
package mr1;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;publicclassP1ReducerextendsReducer<Text, IntWritable, Text, IntWritable>{private IntWritable result =newIntWritable();
@Override
protectedvoidreduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum =0;for(IntWritable val : values){
sum += val.get();}
result.set(sum);
context.write(key, result);}}
P1Reducer extends Reducer<Text, IntWritable, Text, IntWritable>:表明这个类继承了 Reducer 类,其中泛型参数指定了输入和输出类型:
输入键类型:Text(Mapper输出的键)。
输入值类型:IntWritable(Mapper输出的值)。
输出键类型:Text(Reducer的输出键)。
输出值类型:IntWritable(Reducer的输出值)。
Reduce方法重写父类:
protected void reduce(Text key, Iterable<IntWritable> values, Context context):
key:输入键,来自Mapper的输出键。
values:输入值的可迭代集合,包含所有与该键相关的值。
context:MapReduce框架提供的上下文对象,用于与框架进行交互,输出键值对等。
Driver
package mr1;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;publicclassP1Driver{publicstaticvoidmain(String[] args) throws Exception {if(args.length !=2){
System.err.println("Usage: PageViewDriver <input path> <output path>");
System.exit(-1);}
Configuration conf =newConfiguration();
Job job = Job.getInstance(conf,"Page View Count");
job.setJarByClass(P1Driver.class);//设置作业的Jar包
job.setMapperClass(P1Mapper.class);
job.setCombinerClass(P1Reducer.class);
job.setReducerClass(P1Reducer.class);//设置Combiner类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,newPath(args[0]));
FileOutputFormat.setOutputPath(job,newPath(args[1]));
System.exit(job.waitForCompletion(true)?0:1);}}
问题二.统计各个省份的浏览量
输入:一个包含日志信息的文本文件,其中每条记录包含一个IP地址。
Mapper阶段:解析每条日志记录,提取IP地址,并通过IP地址获取对应的省份信息,然后输出键值对(省份,1)。
Reducer阶段:接收Mapper输出的键值对,统计每个省份的访问次数,然后输出结果。
整个过程实现了从日志文件中提取IP地址,转换为地理位置,并统计每个省份的访问次数。
Mapper
import utils.LogParser;import org.apache.commons.lang3.StringUtils;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import utils.IPParser;import utils.LogParser;import java.io.IOException;import java.util.Map;publicclassP2MapperextendsMapper<LongWritable, Text, Text, IntWritable>{privatestatic final IntWritable one =newIntWritable(1);private Text city =newText();
@Override
protectedvoidmap(LongWritable key, Text value, Context context) throws IOException, InterruptedException, IOException {// 将输入的Text对象value转换为字符串,并使用特定的分隔符(这里是\u0001,即ASCII码中的开始信息字符)来分割字符串,得到一个字段数组。
String[] fields = value.toString().split("\u0001");if(fields.length >13){// 检查分割后的字段数组长度是否大于13,确保第14个字段(索引为13)存在。
String ip = fields[13];//从字段数组中获取第14个字段,假设这是IP地址字段,并将其存储在字符串变量ip中。
String log = value.toString();
LogParser parser =newLogParser();
Map<String, String> logInfo = parser.parse(log);//调用LogParser实例的parse方法来解析日志字符串,得到一个包含日志信息的键值对映射。if(StringUtils.isNotBlank(logInfo.get("ip"))){
IPParser.RegionInfo regionInfo = IPParser.getInstance().analyseIp(logInfo.get("ip"));
String province = regionInfo.getProvince();//判断是否为空if(StringUtils.isNotBlank(province)){
context.write(newText(province),newIntWritable(1));}else{
context.write(newText("-"),newIntWritable(1));//如果省份名称无效或为空,输出一个特殊标记"-"作为键和数值1作为值。}}else{
context.write(newText("+"),newIntWritable(1));//如果解析出的IP地址无效或为空,输出特殊标记"+"作为键和数值1作为值。}}}}
将输入的 Text 值按照特定分隔符拆分为字段数组。
然后进行一系列处理,包括解析日志信息、获取 IP 地址、解析省份信息等。
最后,根据处理结果,通过 context.write 方法输出中间键值对,其中键为省份名称或特定符号,值为1。
context.write(new Text(province), new IntWritable(1));:如果省份名称有效,
使用context的write方法输出省份名称作为键和数值1作为值。
输入键类型:LongWritable(每行文本的偏移量)。
输入值类型:Text(一行文本内容)。
输出键类型:Text(省份(有效时),无效时输出特殊记号)。
输出值类型:IntWritable(这里用作计数,值为1)
Reduce
import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;classP2ReducerextendsReducer<Text, IntWritable, Text, IntWritable>{private IntWritable result =newIntWritable();
@Override
protectedvoidreduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum =0;for(IntWritable val : values){
sum += val.get();}
result.set(sum);
context.write(key, result);}}
reduce方法的含义同第一问
通过遍历 values,将每个值累加到 sum 中。
然后,将累加结果设置到 result 中,并通过 context.write 方法输出最终的键值对
Driver
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;publicclassP2Driver{publicstaticvoidmain(String[] args) throws Exception {if(args.length !=2){
System.err.println("Usage: P2Driver <input path> <output path>");
System.exit(-1);}
Configuration conf =newConfiguration();
Job job = Job.getInstance(conf,"Page View Count");
job.setJarByClass(P2Driver.class);
job.setMapperClass(P2Mapper.class);
job.setCombinerClass(P2Reducer.class);
job.setReducerClass(P2Reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,newPath(args[0]));
FileOutputFormat.setOutputPath(job,newPath(args[1]));
System.exit(job.waitForCompletion(true)?0:1);}}
IP解析的工具类
1.GetPageId
package com.bigdata.hadoop.project.utils;import org.apache.commons.lang.StringUtils;import java.util.regex.Matcher;import java.util.regex.Pattern;publicclassGetPageId{publicstatic String getPageId(String url){
String pageId ="";if(StringUtils.isBlank(url)){return pageId;}
Pattern pat = Pattern.compile("topicId=[0-9]+");
Matcher matcher = pat.matcher(url);if(matcher.find()){
pageId = matcher.group().split("topicId=")[1];}return pageId;}publicstaticvoidmain(String[] args){
System.out.println(getPageId("http://www.yihaodian.com/cms/view.do?topicId=14572"));
System.out.println(getPageId("http://www.yihaodian.com/cms/view.do?topicId=22372&merchant=1"));}}
2.IPParser
package com.bigdata.hadoop.project.utils;publicclassIPParserextendsIPSeeker{// 地址 仅仅只是在ecplise环境中使用,部署在服务器上,需要先将qqwry.dat放在集群的各个节点某个有读取权限目录,// 然后在这里指定全路径//private static final String ipFilePath = "ip/qqwry.dat";// 部署在服务器上privatestatic final String ipFilePath ="/export/data/qqwry.dat";privatestatic IPParser obj =newIPParser(ipFilePath);protectedIPParser(String ipFilePath){super(ipFilePath);}publicstatic IPParser getInstance(){return obj;}/**
* 解析ip地址
*
* @param ip
* @return
*/public RegionInfo analyseIp(String ip){if(ip ==null||"".equals(ip.trim())){returnnull;}
RegionInfo info =newRegionInfo();try{
String country =super.getCountry(ip);if("局域网".equals(country)|| country ==null|| country.isEmpty()|| country.trim().startsWith("CZ88")){// 设置默认值
info.setCountry("中国");
info.setProvince("上海市");}else{
int length = country.length();
int index = country.indexOf('省');if(index >0){// 表示是国内的某个省
info.setCountry("中国");
info.setProvince(country.substring(0, Math.min(index +1, length)));
int index2 = country.indexOf('市', index);if(index2 >0){// 设置市
info.setCity(country.substring(index +1, Math.min(index2 +1, length)));}}else{
String flag = country.substring(0,2);switch(flag){case"内蒙":
info.setCountry("中国");
info.setProvince("内蒙古自治区");
country = country.substring(3);if(country !=null&&!country.isEmpty()){
index = country.indexOf('市');if(index >0){// 设置市
info.setCity(country.substring(0, Math.min(index +1, length)));}// TODO:针对其他旗或者盟没有进行处理}break;case"广西":case"西藏":case"宁夏":case"新疆":
info.setCountry("中国");
info.setProvince(flag);
country = country.substring(2);if(country !=null&&!country.isEmpty()){
index = country.indexOf('市');if(index >0){// 设置市
info.setCity(country.substring(0, Math.min(index +1, length)));}}break;case"上海":case"北京":case"重庆":case"天津":
info.setCountry("中国");
info.setProvince(flag +"市");
country = country.substring(3);if(country !=null&&!country.isEmpty()){
index = country.indexOf('区');if(index >0){// 设置市
char ch = country.charAt(index -1);if(ch !='小'|| ch !='校'){
info.setCity(country.substring(0, Math.min(index +1, length)));}}if("unknown".equals(info.getCity())){// 现在city还没有设置,考虑县
index = country.indexOf('县');if(index >0){// 设置市
info.setCity(country.substring(0, Math.min(index +1, length)));}}}break;case"香港":case"澳门":
info.setCountry("中国");
info.setProvince(flag +"特别行政区");break;default:
info.setCountry(country);// 针对其他国外的ip}}}}catch(Exception e){// nothing}return info;}/**
* ip地址对应的info类
*
*/publicstaticclassRegionInfo{private String country ;private String province ;private String city ;public String getCountry(){return country;}publicvoidsetCountry(String country){this.country = country;}public String getProvince(){return province;}publicvoidsetProvince(String province){this.province = province;}public String getCity(){return city;}publicvoidsetCity(String city){this.city = city;}
@Override
public String toString(){return"RegionInfo [country="+ country +", province="+ province +", city="+ city +"]";}}}
注意这里的dat文件地址需要根据剧情情况进行修改,由于作者是在虚拟机里搭建的Idea环境,所以将qqwry.dat放在集群的各个节点某个有读取权限目录,并修改dat文件对应的地址代码
3.IPSeeker
package com.bigdata.hadoop.project.utils;import java.io.FileNotFoundException;import java.io.IOException;import java.io.RandomAccessFile;import java.io.UnsupportedEncodingException;import java.nio.ByteOrder;import java.nio.MappedByteBuffer;import java.nio.channels.FileChannel;import java.util.ArrayList;import java.util.Hashtable;import java.util.List;publicclassIPSeeker{publicstatic final String ERROR_RESULT="错误的IP数据库文件";// 一些固定常量,比如记录长度等等privatestatic final int IP_RECORD_LENGTH=7;privatestatic final byte AREA_FOLLOWED=0x01;privatestatic final byte NO_AREA=0x2;// 用来做为cache,查询一个ip时首先查看cache,以减少不必要的重复查找private Hashtable ipCache;// 随机文件访问类private RandomAccessFile ipFile;// 内存映射文件private MappedByteBuffer mbb;// 单一模式实例privatestatic IPSeeker instance =null;// 起始地区的开始和结束的绝对偏移private long ipBegin, ipEnd;// 为提高效率而采用的临时变量private IPLocation loc;private byte[] buf;private byte[] b4;private byte[] b3;/** *//**
* 私有构造函数
*/protectedIPSeeker(String ipFilePath){
ipCache =newHashtable();
loc =newIPLocation();
buf =newbyte[100];
b4 =newbyte[4];
b3 =newbyte[3];try{
ipFile =newRandomAccessFile(ipFilePath,"r");}catch(FileNotFoundException e){
System.out.println("IP地址信息文件没有找到,IP显示功能将无法使用");
ipFile =null;}// 如果打开文件成功,读取文件头信息if(ipFile !=null){try{
ipBegin =readLong4(0);
ipEnd =readLong4(4);if(ipBegin ==-1|| ipEnd ==-1){
ipFile.close();
ipFile =null;}}catch(IOException e){
System.out.println("IP地址信息文件格式有错误,IP显示功能将无法使用");
ipFile =null;}}}/** *//**
* @return 单一实例
*/publicstatic IPSeeker getInstance(String ipFilePath){if(instance ==null){
instance =newIPSeeker(ipFilePath);}return instance;}/** *//**
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
*
* @param s
* 地点子串
* @return 包含IPEntry类型的List
*/public List getIPEntriesDebug(String s){
List ret =newArrayList();
long endOffset = ipEnd +4;for(long offset = ipBegin +4; offset <= endOffset; offset +=IP_RECORD_LENGTH){// 读取结束IP偏移
long temp =readLong3(offset);// 如果temp不等于-1,读取IP的地点信息if(temp !=-1){
IPLocation loc =getIPLocation(temp);// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续if(loc.country.indexOf(s)!=-1|| loc.area.indexOf(s)!=-1){
IPEntry entry =newIPEntry();
entry.country = loc.country;
entry.area = loc.area;// 得到起始IPreadIP(offset -4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);// 得到结束IPreadIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);// 添加该记录
ret.add(entry);}}}return ret;}/** *//**
* 给定一个地点的不完全名字,得到一系列包含s子串的IP范围记录
*
* @param s
* 地点子串
* @return 包含IPEntry类型的List
*/public List getIPEntries(String s){
List ret =newArrayList();try{// 映射IP信息文件到内存中if(mbb ==null){
FileChannel fc = ipFile.getChannel();
mbb = fc.map(FileChannel.MapMode.READ_ONLY,0, ipFile.length());
mbb.order(ByteOrder.LITTLE_ENDIAN);}
int endOffset =(int) ipEnd;for(int offset =(int) ipBegin +4; offset <= endOffset; offset +=IP_RECORD_LENGTH){
int temp =readInt3(offset);if(temp !=-1){
IPLocation loc =getIPLocation(temp);// 判断是否这个地点里面包含了s子串,如果包含了,添加这个记录到List中,如果没有,继续if(loc.country.indexOf(s)!=-1|| loc.area.indexOf(s)!=-1){
IPEntry entry =newIPEntry();
entry.country = loc.country;
entry.area = loc.area;// 得到起始IPreadIP(offset -4, b4);
entry.beginIp = IPSeekerUtils.getIpStringFromBytes(b4);// 得到结束IPreadIP(temp, b4);
entry.endIp = IPSeekerUtils.getIpStringFromBytes(b4);// 添加该记录
ret.add(entry);}}}}catch(IOException e){
System.out.println(e.getMessage());}return ret;}/** *//**
* 从内存映射文件的offset位置开始的3个字节读取一个int
*
* @param offset
* @return
*/private int readInt3(int offset){
mbb.position(offset);return mbb.getInt()&0x00FFFFFF;}/** *//**
* 从内存映射文件的当前位置开始的3个字节读取一个int
*
* @return
*/private int readInt3(){return mbb.getInt()&0x00FFFFFF;}/** *//**
* 根据IP得到国家名
*
* @param ip
* ip的字节数组形式
* @return 国家名字符串
*/public String getCountry(byte[] ip){// 检查ip地址文件是否正常if(ipFile ==null)returnERROR_RESULT;// 保存ip,转换ip字节数组为字符串形式
String ipStr = IPSeekerUtils.getIpStringFromBytes(ip);// 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件if(ipCache.containsKey(ipStr)){
IPLocation loc =(IPLocation) ipCache.get(ipStr);return loc.country;}else{
IPLocation loc =getIPLocation(ip);
ipCache.put(ipStr, loc.getCopy());return loc.country;}}/** *//**
* 根据IP得到国家名
*
* @param ip
* IP的字符串形式
* @return 国家名字符串
*/public String getCountry(String ip){returngetCountry(IPSeekerUtils.getIpByteArrayFromString(ip));}/** *//**
* 根据IP得到地区名
*
* @param ip
* ip的字节数组形式
* @return 地区名字符串
*/public String getArea(byte[] ip){// 检查ip地址文件是否正常if(ipFile ==null)returnERROR_RESULT;// 保存ip,转换ip字节数组为字符串形式
String ipStr = IPSeekerUtils.getIpStringFromBytes(ip);// 先检查cache中是否已经包含有这个ip的结果,没有再搜索文件if(ipCache.containsKey(ipStr)){
IPLocation loc =(IPLocation) ipCache.get(ipStr);return loc.area;}else{
IPLocation loc =getIPLocation(ip);
ipCache.put(ipStr, loc.getCopy());return loc.area;}}/**
* 根据IP得到地区名
*
* @param ip
* IP的字符串形式
* @return 地区名字符串
*/public String getArea(String ip){returngetArea(IPSeekerUtils.getIpByteArrayFromString(ip));}/** *//**
* 根据ip搜索ip信息文件,得到IPLocation结构,所搜索的ip参数从类成员ip中得到
*
* @param ip
* 要查询的IP
* @return IPLocation结构
*/public IPLocation getIPLocation(byte[] ip){
IPLocation info =null;
long offset =locateIP(ip);if(offset !=-1)
info =getIPLocation(offset);if(info ==null){
info =newIPLocation();
info.country ="未知国家";
info.area ="未知地区";}return info;}/**
* 从offset位置读取4个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换
*
* @param offset
* @return 读取的long值,返回-1表示读取文件失败
*/private long readLong4(long offset){
long ret =0;try{
ipFile.seek(offset);
ret |=(ipFile.readByte()&0xFF);
ret |=((ipFile.readByte()<<8)&0xFF00);
ret |=((ipFile.readByte()<<16)&0xFF0000);
ret |=((ipFile.readByte()<<24)&0xFF000000);return ret;}catch(IOException e){return-1;}}/**
* 从offset位置读取3个字节为一个long,因为java为big-endian格式,所以没办法 用了这么一个函数来做转换
*
* @param offset
* @return 读取的long值,返回-1表示读取文件失败
*/private long readLong3(long offset){
long ret =0;try{
ipFile.seek(offset);
ipFile.readFully(b3);
ret |=(b3[0]&0xFF);
ret |=((b3[1]<<8)&0xFF00);
ret |=((b3[2]<<16)&0xFF0000);return ret;}catch(IOException e){return-1;}}/**
* 从当前位置读取3个字节转换成long
*
* @return
*/private long readLong3(){
long ret =0;try{
ipFile.readFully(b3);
ret |=(b3[0]&0xFF);
ret |=((b3[1]<<8)&0xFF00);
ret |=((b3[2]<<16)&0xFF0000);return ret;}catch(IOException e){return-1;}}/**
* 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是
* 文件中是little-endian形式,将会进行转换
*
* @param offset
* @param ip
*/privatevoidreadIP(long offset, byte[] ip){try{
ipFile.seek(offset);
ipFile.readFully(ip);
byte temp = ip[0];
ip[0]= ip[3];
ip[3]= temp;
temp = ip[1];
ip[1]= ip[2];
ip[2]= temp;}catch(IOException e){
System.out.println(e.getMessage());}}/**
* 从offset位置读取四个字节的ip地址放入ip数组中,读取后的ip为big-endian格式,但是
* 文件中是little-endian形式,将会进行转换
*
* @param offset
* @param ip
*/privatevoidreadIP(int offset, byte[] ip){
mbb.position(offset);
mbb.get(ip);
byte temp = ip[0];
ip[0]= ip[3];
ip[3]= temp;
temp = ip[1];
ip[1]= ip[2];
ip[2]= temp;}/**
* 把类成员ip和beginIp比较,注意这个beginIp是big-endian的
*
* @param ip
* 要查询的IP
* @param beginIp
* 和被查询IP相比较的IP
* @return 相等返回0,ip大于beginIp则返回1,小于返回-1。
*/private int compareIP(byte[] ip, byte[] beginIp){for(int i =0; i <4; i++){
int r =compareByte(ip[i], beginIp[i]);if(r !=0)return r;}return0;}/**
* 把两个byte当作无符号数进行比较
*
* @param b1
* @param b2
* @return 若b1大于b2则返回1,相等返回0,小于返回-1
*/private int compareByte(byte b1, byte b2){if((b1 &0xFF)>(b2 &0xFF))// 比较是否大于return1;elseif((b1 ^ b2)==0)// 判断是否相等return0;elsereturn-1;}/**
* 这个方法将根据ip的内容,定位到包含这个ip国家地区的记录处,返回一个绝对偏移 方法使用二分法查找。
*
* @param ip
* 要查询的IP
* @return 如果找到了,返回结束IP的偏移,如果没有找到,返回-1
*/private long locateIP(byte[] ip){
long m =0;
int r;// 比较第一个ip项readIP(ipBegin, b4);
r =compareIP(ip, b4);if(r ==0)return ipBegin;elseif(r <0)return-1;// 开始二分搜索for(long i = ipBegin, j = ipEnd; i < j;){
m =getMiddleOffset(i, j);readIP(m, b4);
r =compareIP(ip, b4);// log.debug(Utils.getIpStringFromBytes(b));if(r >0)
i = m;elseif(r <0){if(m == j){
j -=IP_RECORD_LENGTH;
m = j;}else
j = m;}elsereturnreadLong3(m +4);}// 如果循环结束了,那么i和j必定是相等的,这个记录为最可能的记录,但是并非// 肯定就是,还要检查一下,如果是,就返回结束地址区的绝对偏移
m =readLong3(m +4);readIP(m, b4);
r =compareIP(ip, b4);if(r <=0)return m;elsereturn-1;}/**
* 得到begin偏移和end偏移中间位置记录的偏移
*
* @param begin
* @param end
* @return
*/private long getMiddleOffset(long begin, long end){
long records =(end - begin)/IP_RECORD_LENGTH;
records >>=1;if(records ==0)
records =1;return begin + records *IP_RECORD_LENGTH;}/**
* 给定一个ip国家地区记录的偏移,返回一个IPLocation结构
*
* @param offset
* @return
*/private IPLocation getIPLocation(long offset){try{// 跳过4字节ip
ipFile.seek(offset +4);// 读取第一个字节判断是否标志字节
byte b = ipFile.readByte();if(b ==AREA_FOLLOWED){// 读取国家偏移
long countryOffset =readLong3();// 跳转至偏移处
ipFile.seek(countryOffset);// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = ipFile.readByte();if(b ==NO_AREA){
loc.country =readString(readLong3());
ipFile.seek(countryOffset +4);}else
loc.country =readString(countryOffset);// 读取地区标志
loc.area =readArea(ipFile.getFilePointer());}elseif(b ==NO_AREA){
loc.country =readString(readLong3());
loc.area =readArea(offset +8);}else{
loc.country =readString(ipFile.getFilePointer()-1);
loc.area =readArea(ipFile.getFilePointer());}return loc;}catch(IOException e){returnnull;}}/**
* @param offset
* @return
*/private IPLocation getIPLocation(int offset){// 跳过4字节ip
mbb.position(offset +4);// 读取第一个字节判断是否标志字节
byte b = mbb.get();if(b ==AREA_FOLLOWED){// 读取国家偏移
int countryOffset =readInt3();// 跳转至偏移处
mbb.position(countryOffset);// 再检查一次标志字节,因为这个时候这个地方仍然可能是个重定向
b = mbb.get();if(b ==NO_AREA){
loc.country =readString(readInt3());
mbb.position(countryOffset +4);}else
loc.country =readString(countryOffset);// 读取地区标志
loc.area =readArea(mbb.position());}elseif(b ==NO_AREA){
loc.country =readString(readInt3());
loc.area =readArea(offset +8);}else{
loc.country =readString(mbb.position()-1);
loc.area =readArea(mbb.position());}return loc;}/**
* 从offset偏移开始解析后面的字节,读出一个地区名
*
* @param offset
* @return 地区名字符串
* @throws IOException
*/private String readArea(long offset) throws IOException {
ipFile.seek(offset);
byte b = ipFile.readByte();if(b ==0x01|| b ==0x02){
long areaOffset =readLong3(offset +1);if(areaOffset ==0)return"未知地区";elsereturnreadString(areaOffset);}elsereturnreadString(offset);}/**
* @param offset
* @return
*/private String readArea(int offset){
mbb.position(offset);
byte b = mbb.get();if(b ==0x01|| b ==0x02){
int areaOffset =readInt3();if(areaOffset ==0)return"未知地区";elsereturnreadString(areaOffset);}elsereturnreadString(offset);}/**
* 从offset偏移处读取一个以0结束的字符串
*
* @param offset
* @return 读取的字符串,出错返回空字符串
*/private String readString(long offset){try{
ipFile.seek(offset);
int i;for(i =0, buf[i]= ipFile.readByte(); buf[i]!=0; buf[++i]= ipFile.readByte());if(i !=0)return IPSeekerUtils.getString(buf,0, i,"GBK");}catch(IOException e){
System.out.println(e.getMessage());}return"";}/**
* 从内存映射文件的offset位置得到一个0结尾字符串
*
* @param offset
* @return
*/private String readString(int offset){try{
mbb.position(offset);
int i;for(i =0, buf[i]= mbb.get(); buf[i]!=0; buf[++i]= mbb.get());if(i !=0)return IPSeekerUtils.getString(buf,0, i,"GBK");}catch(IllegalArgumentException e){
System.out.println(e.getMessage());}return"";}public String getAddress(String ip){
String country =getCountry(ip).equals(" CZ88.NET")?"":getCountry(ip);
String area =getArea(ip).equals(" CZ88.NET")?"":getArea(ip);
String address = country +" "+ area;return address.trim();}/**
* * 用来封装ip相关信息,目前只有两个字段,ip所在的国家和地区
*
*
* @author swallow
*/publicclassIPLocation{public String country;public String area;publicIPLocation(){
country = area ="";}public IPLocation getCopy(){
IPLocation ret =newIPLocation();
ret.country = country;
ret.area = area;return ret;}}/**
* 一条IP范围记录,不仅包括国家和区域,也包括起始IP和结束IP *
*
*
* @author gerry liu
*/publicclassIPEntry{public String beginIp;public String endIp;public String country;public String area;publicIPEntry(){
beginIp = endIp = country = area ="";}public String toString(){returnthis.area +" "+this.country +"IP Χ:"+this.beginIp +"-"+this.endIp;}}/**
* 操作工具类
*
* @author gerryliu
*
*/publicstaticclassIPSeekerUtils{/**
* 从ip的字符串形式得到字节数组形式
*
* @param ip
* 字符串形式的ip
* @return 字节数组形式的ip
*/publicstatic byte[]getIpByteArrayFromString(String ip){
byte[] ret =newbyte[4];
java.util.StringTokenizer st =newjava.util.StringTokenizer(ip,".");try{
ret[0]=(byte)(Integer.parseInt(st.nextToken())&0xFF);
ret[1]=(byte)(Integer.parseInt(st.nextToken())&0xFF);
ret[2]=(byte)(Integer.parseInt(st.nextToken())&0xFF);
ret[3]=(byte)(Integer.parseInt(st.nextToken())&0xFF);}catch(Exception e){
System.out.println(e.getMessage());}return ret;}/**
* 对原始字符串进行编码转换,如果失败,返回原始的字符串
*
* @param s
* 原始字符串
* @param srcEncoding
* 源编码方式
* @param destEncoding
* 目标编码方式
* @return 转换编码后的字符串,失败返回原始字符串
*/publicstatic String getString(String s, String srcEncoding, String destEncoding){try{returnnewString(s.getBytes(srcEncoding), destEncoding);}catch(UnsupportedEncodingException e){return s;}}/**
* 根据某种编码方式将字节数组转换成字符串
*
* @param b
* 字节数组
* @param encoding
* 编码方式
* @return 如果encoding不支持,返回一个缺省编码的字符串
*/publicstatic String getString(byte[] b, String encoding){try{returnnewString(b, encoding);}catch(UnsupportedEncodingException e){returnnewString(b);}}/**
* 根据某种编码方式将字节数组转换成字符串
*
* @param b
* 字节数组
* @param offset
* 要转换的起始位置
* @param len
* 要转换的长度
* @param encoding
* 编码方式
* @return 如果encoding不支持,返回一个缺省编码的字符串
*/publicstatic String getString(byte[] b, int offset, int len, String encoding){try{returnnewString(b, offset, len, encoding);}catch(UnsupportedEncodingException e){returnnewString(b, offset, len);}}/**
* @param ip
* ip的字节数组形式
* @return 字符串形式的ip
*/publicstatic String getIpStringFromBytes(byte[] ip){
StringBuffer sb =newStringBuffer();
sb.append(ip[0]&0xFF);
sb.append('.');
sb.append(ip[1]&0xFF);
sb.append('.');
sb.append(ip[2]&0xFF);
sb.append('.');
sb.append(ip[3]&0xFF);return sb.toString();}}/**
* 获取全部ip地址集合列表
*
* @return
*/public List<String>getAllIp(){
List<String> list =newArrayList<String>();
byte[] buf =newbyte[4];for(long i = ipBegin; i < ipEnd; i +=IP_RECORD_LENGTH){try{this.readIP(this.readLong3(i +4), buf);// 读取ip,最终ip放到buf中
String ip = IPSeekerUtils.getIpStringFromBytes(buf);
list.add(ip);}catch(Exception e){// nothing}}return list;}}
4.LogParser
package com.bigdata.hadoop.project.utils;import org.apache.commons.lang.StringUtils;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.util.HashMap;import java.util.Map;publicclassLogParser{private Logger logger = LoggerFactory.getLogger(LogParser.class);public Map<String, String>parse2(String log){
Map<String, String> logInfo =newHashMap<String,String>();
IPParser ipParse = IPParser.getInstance();if(StringUtils.isNotBlank(log)){
String[] splits = log.split("\t");
String ip = splits[0];
String url = splits[1];
String sessionId = splits[2];
String time = splits[3];
String country = splits[4];
String province = splits[5];
String city = splits[6];
logInfo.put("ip",ip);
logInfo.put("url",url);
logInfo.put("sessionId",sessionId);
logInfo.put("time",time);
logInfo.put("country",country);
logInfo.put("province",province);
logInfo.put("city",city);}else{
logger.error("日志记录的格式不正确:"+ log);}return logInfo;}public Map<String, String>parse(String log){
Map<String, String> logInfo =newHashMap<String,String>();
IPParser ipParse = IPParser.getInstance();if(StringUtils.isNotBlank(log)){
String[] splits = log.split("\001");
String ip = splits[13];
String url = splits[1];
String sessionId = splits[10];
String time = splits[17];
logInfo.put("ip",ip);
logInfo.put("url",url);
logInfo.put("sessionId",sessionId);
logInfo.put("time",time);
IPParser.RegionInfo regionInfo = ipParse.analyseIp(ip);
logInfo.put("country",regionInfo.getCountry());
logInfo.put("province",regionInfo.getProvince());
logInfo.put("city",regionInfo.getCity());}else{
logger.error("日志记录的格式不正确:"+ log);}return logInfo;}}
问题三.ETL
Mapper类
packageETL;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import utils.GetPageId;import utils.LogParser;import java.io.IOException;import java.util.Map;publicclassETLMapperextendsMapper<LongWritable, Text, Text, IntWritable>{//解析日志字符串,获取日志信息privatestatic final IntWritable one =newIntWritable(1);private Text outputKey =newText();private LogParser logParser =newLogParser();private Logger logger = LoggerFactory.getLogger(ETLMapper.class);
@Override
protectedvoidmap(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 解析日志记录
Map<String, String> logInfo = logParser.parse(value.toString());if(logInfo ==null){
logger.error("日志记录的格式不正确或解析失败:"+ value.toString());return;}// 获取需要的字段
String ip = logInfo.get("ip");
String url = logInfo.get("url");
String country = logInfo.get("country");
String province = logInfo.get("province");
String city = logInfo.get("city");// 调用 GetPageId 获取 topicId
String topicId = GetPageId.getPageId(url);
logInfo.put("pageId", topicId);// 检查所有字段是否全部为空if(ip !=null|| url !=null|| topicId !=null|| country !=null|| province !=null|| city !=null){
StringBuilder sb =newStringBuilder();if(ip !=null&&!ip.isEmpty()) sb.append("IP: ").append(ip).append(", ");if(url !=null&&!url.isEmpty()) sb.append("URL: ").append(url).append(", ");if(topicId !=null&&!topicId.isEmpty()) sb.append("PageId: ").append(topicId).append(", ");if(country !=null&&!country.isEmpty()) sb.append("Country: ").append(country).append(", ");if(province !=null&&!province.isEmpty()) sb.append("Province: ").append(province).append(", ");if(city !=null&&!city.isEmpty()) sb.append("City: ").append(city);// 移除末尾的逗号和空格
String outputString = sb.toString().replaceAll(", $","");
outputKey.set(outputString);
context.write(outputKey, one);}else{
logger.error("所有字段为空,日志记录:"+ value.toString());}}}
首先,通过调用 logParser.parse 方法解析日志记录,并将解析结果存储在 logInfo 变量中。如果解析失败或者解析结果为空,则记录错误并返回。
然后,从 logInfo 中获取需要的字段,包括 ip、url、country、province、city。
接下来,通过调用 GetPageId.getPageId 方法获取 topicId,并将其存储到 logInfo 中的 "pageId" 键中。
进一步,检查所有字段是否全部为空。如果其中至少有一个字段不为空,则按照一定的格式构建输出字符串,并将其设置为 outputKey 的值。
最后,通过调用 context.write 方法输出键值对,其中键为 outputKey,值为 one
Reduce
packageETL;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;publicclassETLReducerextendsReducer<Text, IntWritable, Text, IntWritable>{private IntWritable result =newIntWritable();
@Override
protectedvoidreduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum =0;for(IntWritable val : values){
sum += val.get();//迭代累加}
result.set(sum);
context.write(key, result);//写出结果}}
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
key: 当前分组的键。
values: 属于当前键的所有值的集合。
context: 用于与 Hadoop 框架进行交互的上下文对象
Driver
packageETL;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;publicclassETLDriver{publicstaticvoidmain(String[] args) throws Exception {if(args.length !=2){
System.err.println("Usage: LogETLDriver <input path> <output path>");
System.exit(-1);}
Configuration conf =newConfiguration();
Job job = Job.getInstance(conf,"Log ETL");
job.setJarByClass(ETLDriver.class);
job.setMapperClass(ETLMapper.class);
job.setCombinerClass(ETLReducer.class);
job.setReducerClass(ETLReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,newPath(args[0]));
FileOutputFormat.setOutputPath(job,newPath(args[1]));
System.exit(job.waitForCompletion(true)?0:1);}}
结果展示
在这里,shangzhan2_jar为问题一的jar包,shangzhan2_jar2为问题二的jar包,shangzhan2_jar3为问题三的jar包,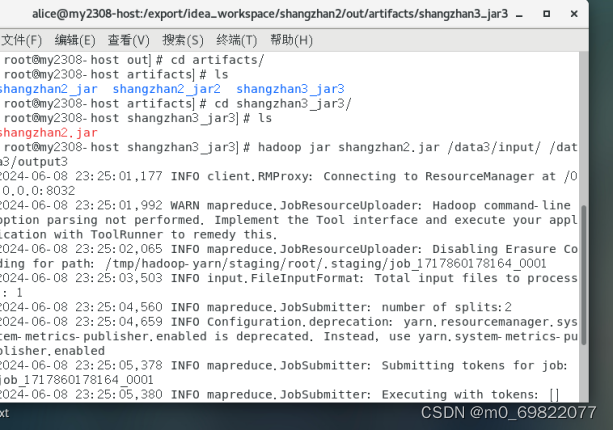
HDFS中的目录: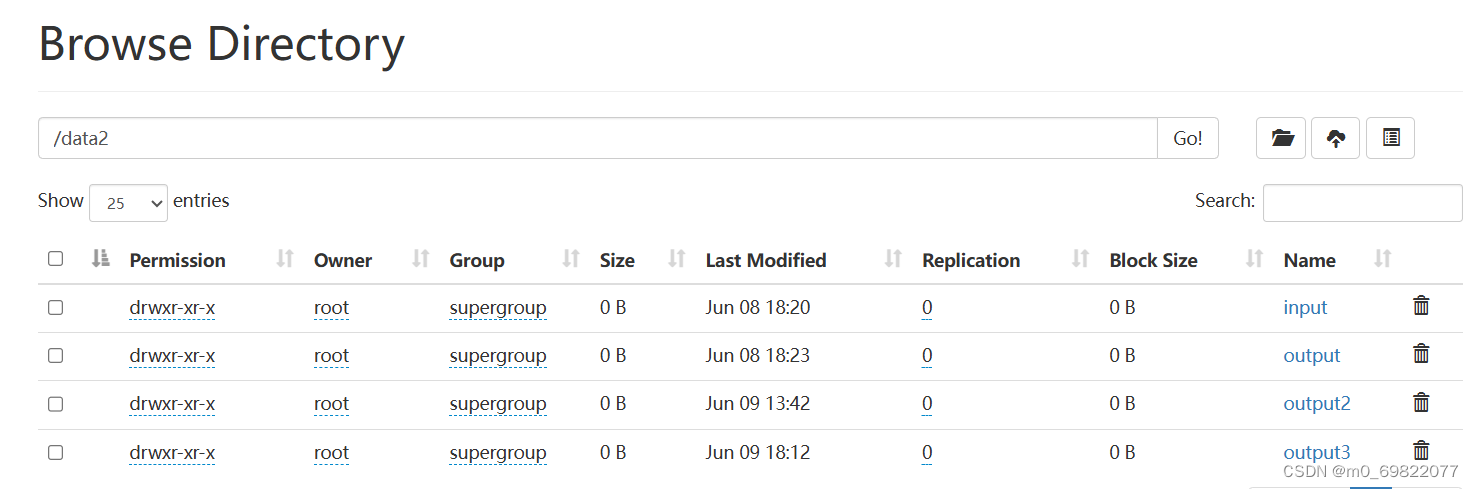
问题一结果图: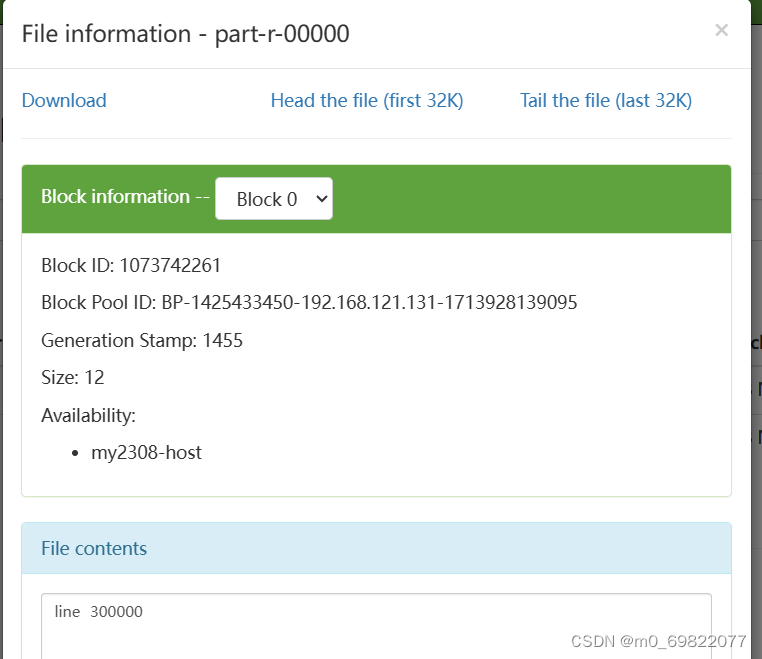
问题二结果图: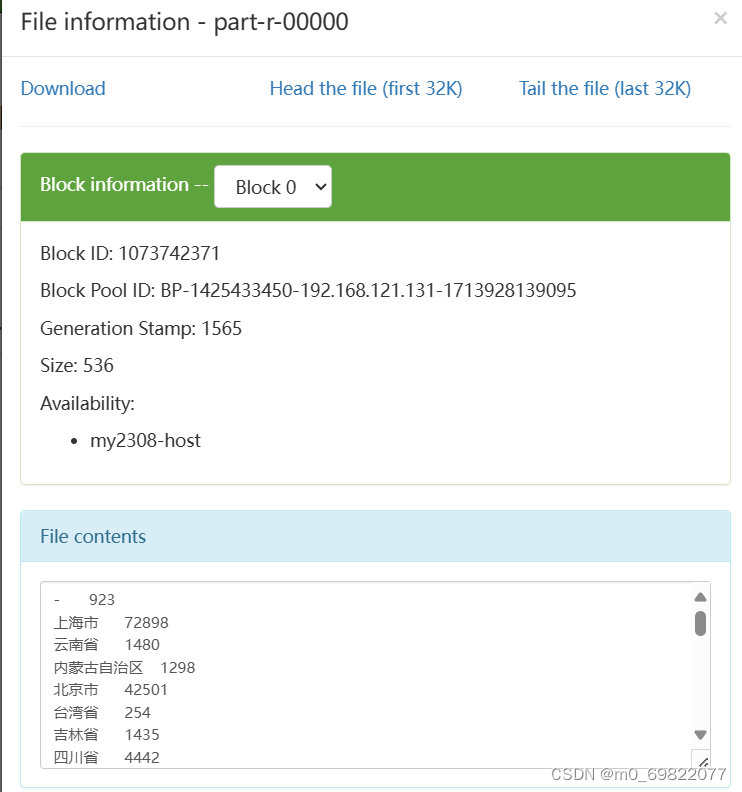
问题三结果图: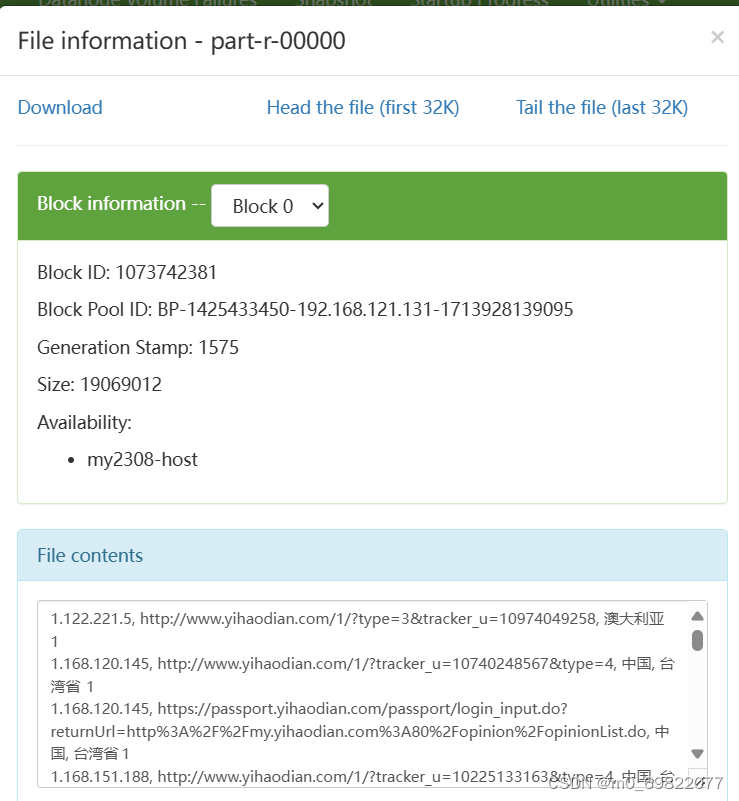
小结
不仅巩固了对 MapReduce 编程模型的理解,还学会了如何结合第三方工具进行数据解析和处理,为电商日志数据分析提供了可靠的方法
版权归原作者 m0_69822077 所有, 如有侵权,请联系我们删除。