


在CVPR2022中,一篇专注于优化卷积核大小的分类网络论文吸引了大量的关注,这就是由清华和旷视提出的RepLKNet[1]。RepLKNet与目前流行的CNN模型背道而驰,其核心模块由31×31的大卷积核构成。在Vision Transformer (ViT) 流行的大背景下,RepLKNet以纯CNN的架构获得了超过Swin Transformer( Top-1 acc: 87.3%)的性能。今天就来深入解读下这篇被CVPR2022收录的论文,以及使用飞桨框架实现RepLKNet。
介绍
卷积神经网络曾是现代计算机视觉系统里编码器的常见选择。然而近两年,Vision Transformer在图像分类任务及其下游任务(如目标检测和语义分割等任务)中不断冲击着CNN的地位。
为什么ViTs如此强大?一些研究认为,多头自注意(MHSA)机制在ViTs中起着关键作用。一些工作认为MHSA具有CNN缺乏的获取长期依赖的能力,能够对输入的特征进行全局建模,因此单个MHSA层的每个输出都能够获取全局信息。但是CNN中,除了第一层外很少会采用较大的卷积核,一般都是通过多个小卷积核叠加来增加感受野,只有一些比较老的网络和采用神经网络搜索搜索出来的网络结构会使用较大的卷积核(大于5x5)。
那么问题来了:如果使用大卷积核而不是小卷积核会怎么样呢?在这个问题的基础上,作者系统地研究了CNN的大卷积核设计方式。遵循了一个非常简单的理论:只需将具有从3×3到31×31不等大小的大卷积核的深度可分离卷积(DepthWise convolution) 引入到CNN模型中即可。
作者通过一系列实验,总结了五条有效使用大卷积核的经验准则。
大的卷积核也可以很有效的进行计算
大卷积核首先带来的问题就是大量的参数和浮点运算量,大多数现有的深度学习框架对大卷积核的支持很差,无法有效率地进行卷积运算。为了解决参数量和浮点运算量的问题,作者运用了深度可分离卷积。
深度可分离卷积分为DepthWise(DW) convolution、PointWise(PW) convolution两部分。DepthWise(DW) convolution是输入通道和输出通道以及分组数都相同的卷积形式,与传统的卷积不同的是,DW卷积的每一个卷积核只计算对应的一张特征图,参数量和计算量是原来的1/n(n为输入通道数)。虽然DW卷积能够减少大量的参数,但会减少不同层特征像素点之间的信息交互,最终会带来精度上的损失。PointWise(PW) convolution是输出为n通道的1×1卷积,用来尽量弥补DW卷积缺少的特征交互过程,PW实际上对所有的特征图进行了点对点的乘加运算,尽量地结合不同特征图的信息。
残差结构对于大卷积核模型至关重要
大卷积核需要依靠残差连接。作者使用MobileNetV2作为基线网络进行实验。将基线网络中深度可分离卷积的3×3大小的卷积核替换为13×13大小的卷积核,重新训练后分类准确率增加了0.77%。但是在去掉模型中的残差结构后,准确率只有53.98%。可以得出结论:残差结构对大卷积核的收益远大于小卷积核,因此在具有大卷积核的模型中,残差结构至关重要。

使用小卷积核重参数化来补优化问题
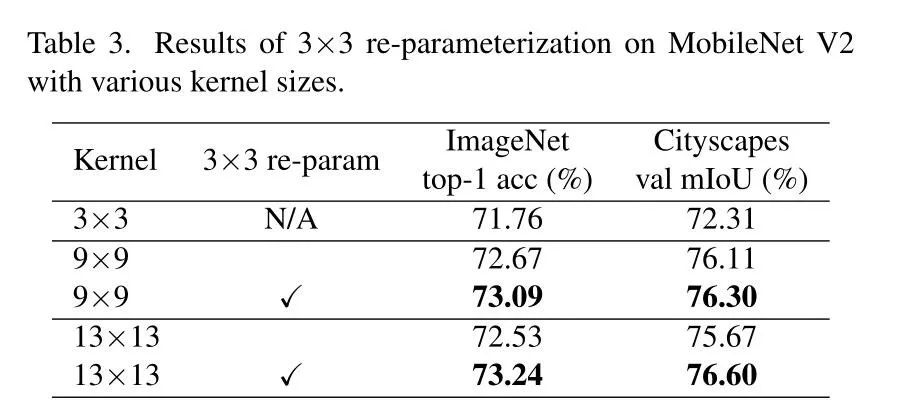
如下表所示,用9×9和13×13的卷积核代替MobileNet V2中的3×3卷积核后效果下降,于是使用小卷积核进行重参数化,模型性能有了显著的提高(13好于9)。
大卷积核在下游任务中表现更加优秀
重参数化后的mIoU提升幅度大于分类的幅度,这可以总结为以下的几点:
- 像分割这种需要精细化像素级切割的任务,感受野越大越好,大卷积核可以带来更大的感受野。
- 大的卷积核可以提取到更加深层的语义信息,这有助于确定目标的位置,所以在像素级分割的任务上表现会更好。
大卷积核在小特征图上依然效果显著
在MobileNetV2的模型中,将224×224尺寸的图像作为输入,MobileNetV2中由bottleneck组成的stage层会对图像进行特征提取以及尺寸缩减,最后一个stage层输入的是7×7尺寸的特征,再对这个特征进行卷积、池化、分类的操作就可以得到分类结果。 作者将MobileNetV2结构中最后一个stage层的卷积核变为7×7和13×13的大小。结果如下表所示,发现对比原模型,修改后的模型效果依然有明显的增加。这说明了大卷积核在小特征图同样有效。

RepLKNet网络结构介绍
在上一节所述的5条经验准则的指导下,作者构建如下图所示的RepLKNet。
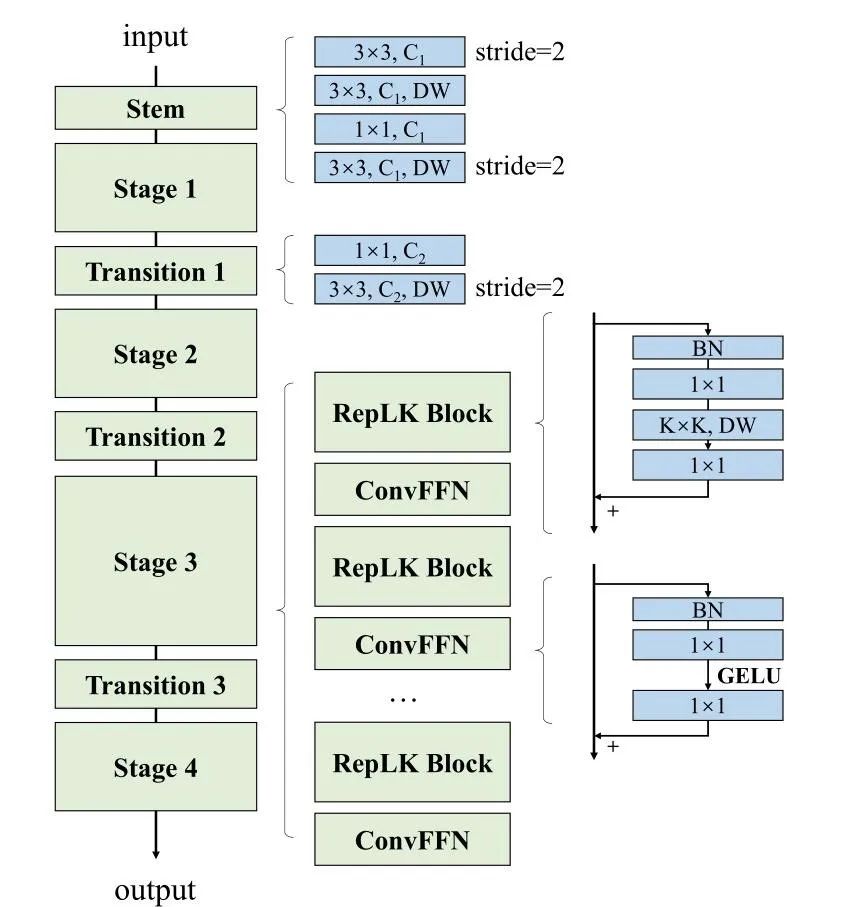
图片处理主要包括三个层次:
Stem层:
对于输入的图像,steam层分别由步长为2的3×3卷积、深度可分离卷积、以及步长为2的DW卷积组成,steam层对输入的图像进行升维以及尺寸缩减。假设输入的尺寸为H和W,H为图像的高,W为图像的宽,steam输出的特征尺寸为H/4×W/4×C1 ,C1为升维后的通道数。
Stage层:
RepLKNet的核心层,由RepLK Block以及ConvFFN堆叠而成。RepLK Block 包含了归一化层、1×1卷积和深度可分离卷积。以及最重要的残差连接。FFN是在Transformer中常用的操作:包括了两个全连接层。这里的ConvFFN则是使用了1×1卷积替代全连接层。同样的ConvFFN也使用了层间的残差连接。
Transition层:
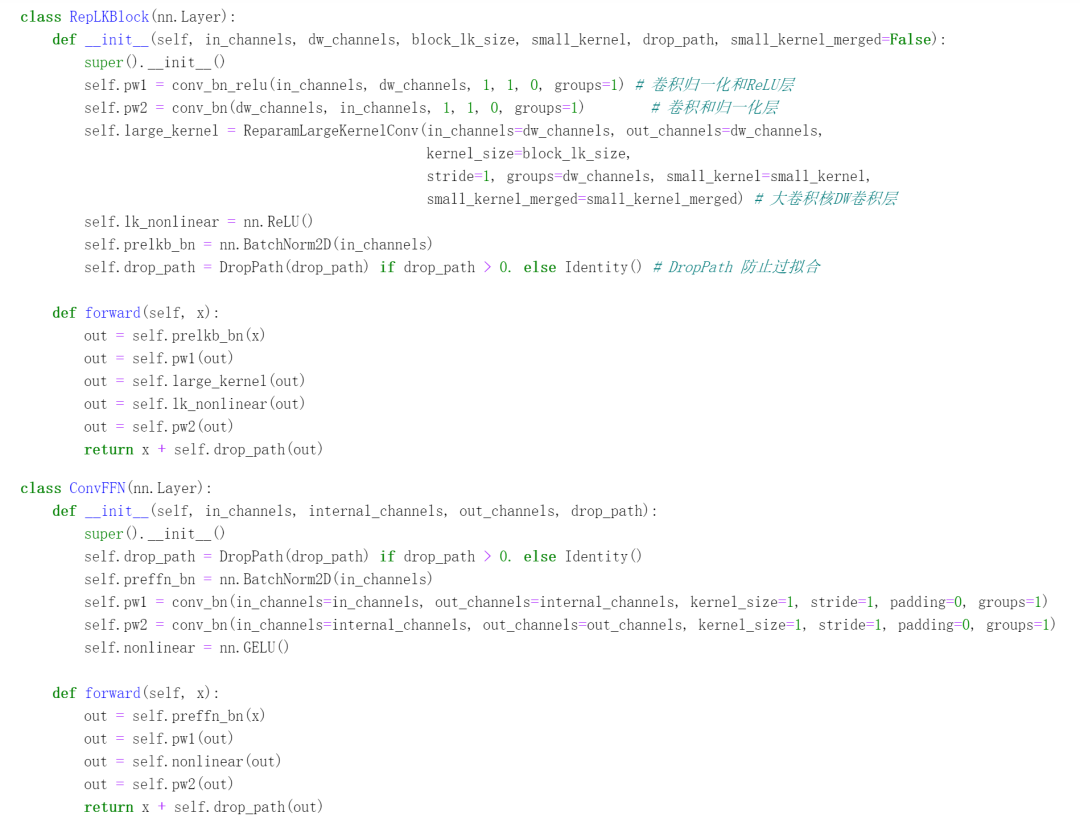
结构简单,主要为PW卷积以及步长为2的DW卷积,用于图像下采样。以下是用飞桨框架来实现的RepLK Block和ConvFFN层演示。
如下表所示,用于分类和分割的RepLK Blocks的数量为[2, 2, 18, 2], 通道数分别为[128, 256, 512, 1024],采用不同大小的卷积核来测试不同的性能。不同层RepLK Blocks的数量比为1:1:9:1,与ConvNeXt和Swin Transformer的配置保持一致,通道数则是采取了经典了尺寸缩减,通道数翻倍的思想。Stage1-4分别为128, 256, 512, 1024。为了性能与参数量的平衡,作者选择了128作为RepLKNet-B第一个stage的通道数。
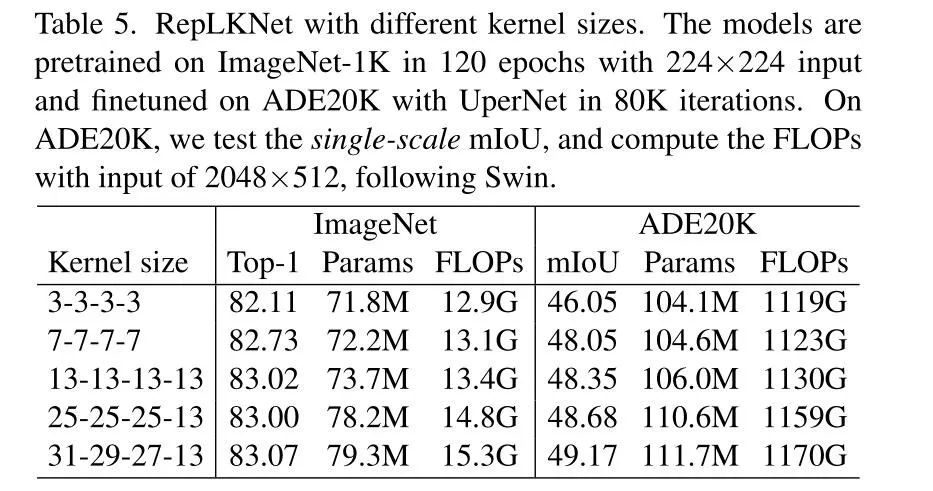
随着卷积核变大,ADE20K的mIoU在逐渐变高,因此作者采用了31组作为最终模型,即RepLKNet-B。此外,作者通过增加通道数设计了不同版本的RepLKNet,即四个stage分别为192,384,768,1536通道数的RepLKNet-L以及有着256,512,1024,2048通道数的RepLKNet-XL。
性能介绍
分类性能
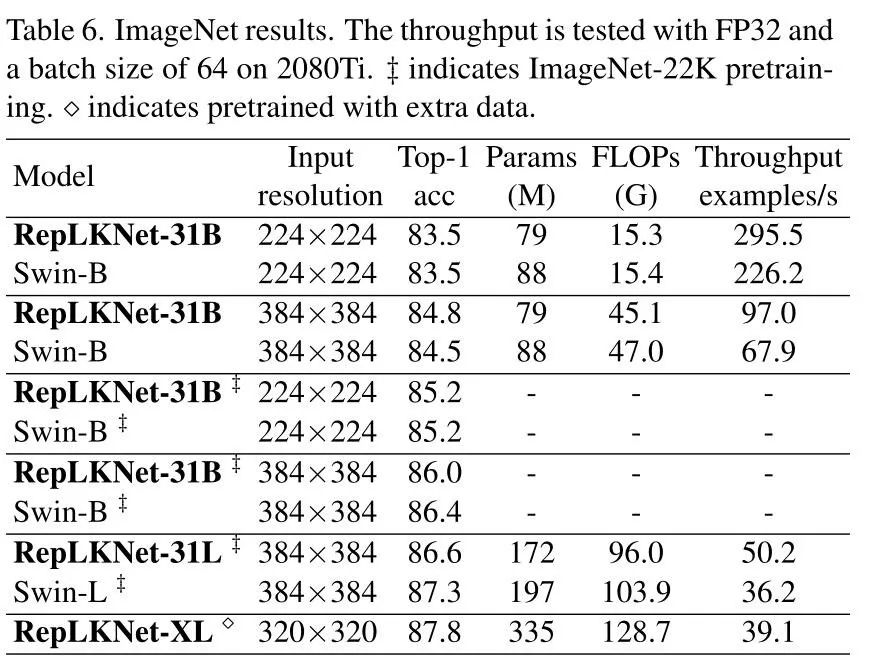
将RepLKNet与Swin Transfomer进行全方面的比较,如下表所示,可以看到,RepLKNet系列无论是在准确率上还是参数量上都略优于Swin Transformer系列。RepLKNet-XL虽然计算量和参数量都大于Swin-L,但也取得了87.8%的Top-1准确率。
检测与分割性能
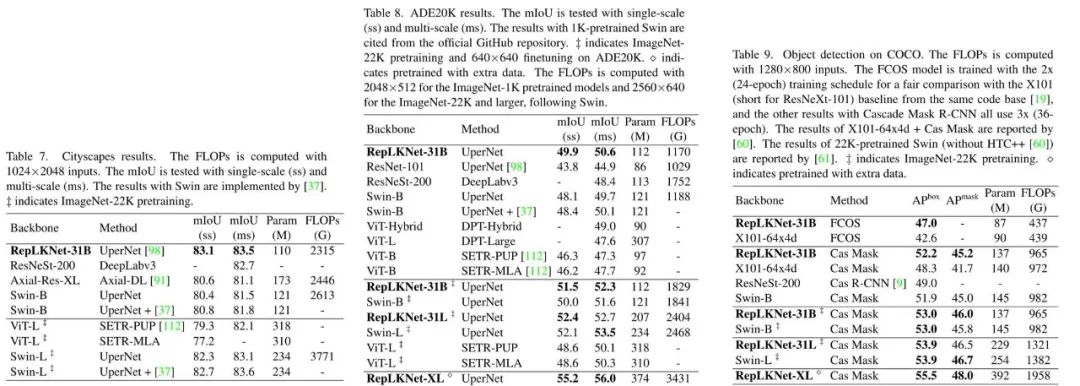
语义分割数据集为Cityscapes和ADE20K。RepLKNet以UperNet的经典分割模型作为网络结构,与多种模型进行了对比,并取得了state-of-the-art的效果。目标检测数据集为COCO,RepLKNet以Cascaded Maks R-CNN的经典目标检测模型作为网络结构。在于其他模型的对比下,同样达到了SOTA的效果。
讨论
讨论一:大卷积核拥有更大的感受野
感受野是一个在分割和检测领域上备受关注的概念,正如人的视野一样,感受野体现的是卷积核对当前输入特征图的感知范围,如果范围很小,那么接收的信息是片面的、局部的。如果增大感受野,那么就可以获得更多的全局信息,从而更有利于对当前局面的判断。现有的CNN模型都通过堆叠的卷积核与池化层来扩充感受野的大小,有些模型甚至有成百上千个卷积,那么为什么这么多的小卷积,比不过大卷积核呢?
有效感受野(Effective Receptive Field ,ERF)的大小与卷积核的大小K和模型深度L有关,与K成正比,与L成反比:
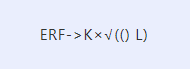
可以看到,ERF对K的大小更敏感,增加深度没有增加卷积核大小直观。另外,增加深度还会引起优化问题。虽然ResNet解决了网络退化的问题,但是ResNet的有效感受野仍不一定很大。
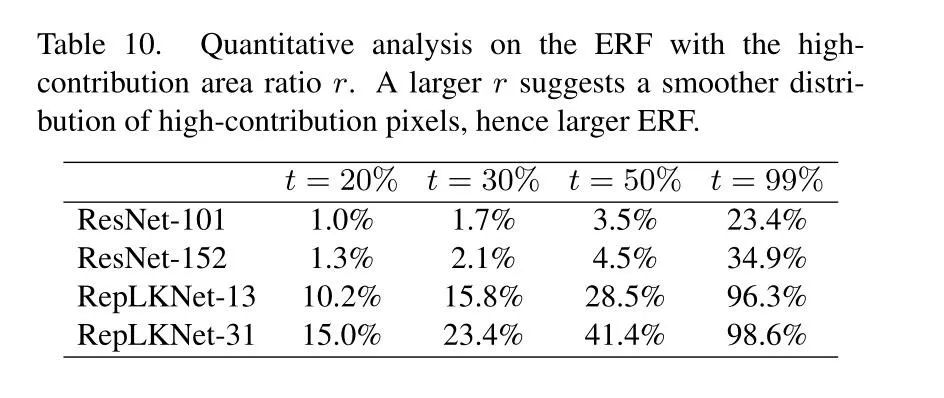
如上表所示,RepLKNet的感受野是远大于ResNet的,这也是为什么RepLKNet效果好于ResNet的原因。作者在ImageNet上选取了50张图像,并且缩放到1024×1024的大小,然后测试模型输出最后特征中心点和输入图像相关区域点的比例,发现随着ResNet深度的增加,有效感受野并未发生显著变化(如下图所示)。

****讨论二:大卷积 ****VS 空洞卷积
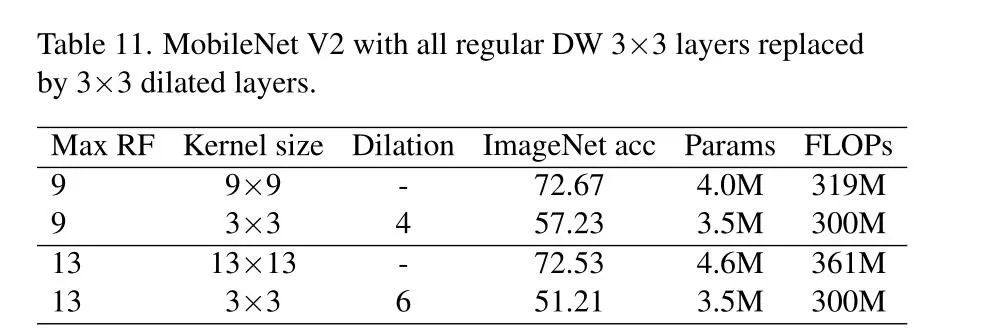
空洞卷积在相邻的卷积核中插入孔洞,使得原卷积核拥有了更大的感受野。ASPP模块堆叠了多种具有不同大小孔洞率的空洞卷积,从而获取到具有不同感受野的多级特征,多级特征有助于模型更好地理解输入的特征信息。然而,空洞卷积会造成不可避免的局部特征损失,从而导致预测图出现网格状的缺失。RepLKNet用深度可分离卷积重新思考了大卷积核的使用,同样是扩大感受野,RepLKNet则取得了更好的效果。如下表所示,纯空洞卷积组成的MobileNet V2效果比原模型更差。
讨论三:局限性
尽管大卷积核的设计可以改善模型在ImageNet和下游任务的效果,但是随着数据和模型规模的增加,RepLKNet的效果开始落后于Transformer,例如,RepLKNet-31L在ImageNet 的Top-1 比Swin-L低0.7%(虽然在分割和检测数据集上的效果仍具有可比性)。作者仍在探索这方面的原因并且提出解决方法,例如,研究一个更强大的CNN基线(例如ConvNeXt)是否有助于在大卷积核的设计中超越ViT的上限。
参考文献:
[1] Ding X , Zhang X , Zhou Y , et al. Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs[J]. arXiv e-prints, 2022.

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
版权归原作者 飞桨PaddlePaddle 所有, 如有侵权,请联系我们删除。