
Unity开发项目总结的几项优化点,比较适合中小项目优化,拿来即用,大型项目需要考虑定制化渲染管线、剔除、光照等。针对优化更多的还是需要结合项目去考虑。
一、模型

Read/Write:同Texture,若开启,Unity会存储两份Mesh,导致运行时的内存用量变成两倍。
Compression:Mesh Compression是使用压缩算法,将Mesh数据进行压缩,结果是会减少占用硬盘的空间,但是在Runtime的时候会被解压为原始精度的数据,因此内存占用并不会减少。
需要注意的是有些版本开了,实际解压之后内存占用大小会更严重。
Rig:如果没有使用动画,请关闭Rig,例如房子,石头这些。
Blendshapes:如果没有用到Blendshapes,也关闭。
如果Material没有用到法向量和切线信息,关闭可以减少额外信息。
Humanoid:人型骨骼动画会生成一份骨骼绑点,增加内存,非必要可以不使用。
每个角色尽量使用一个Skinned Mesh Renderer,因为当角色仅有一个Skinned Mesh Renderer 时,Unity会使用可见性裁剪和包围体更新的方法来优化角色的运动,而这种优化只有在角色仅含有一个Skinned Mesh Renderer 时才会启动
人型动画根据需求可以进行节点对象优化:Rig中--Optimize Game Objects,选择需要保留的节点---Extra Transforms to Expose
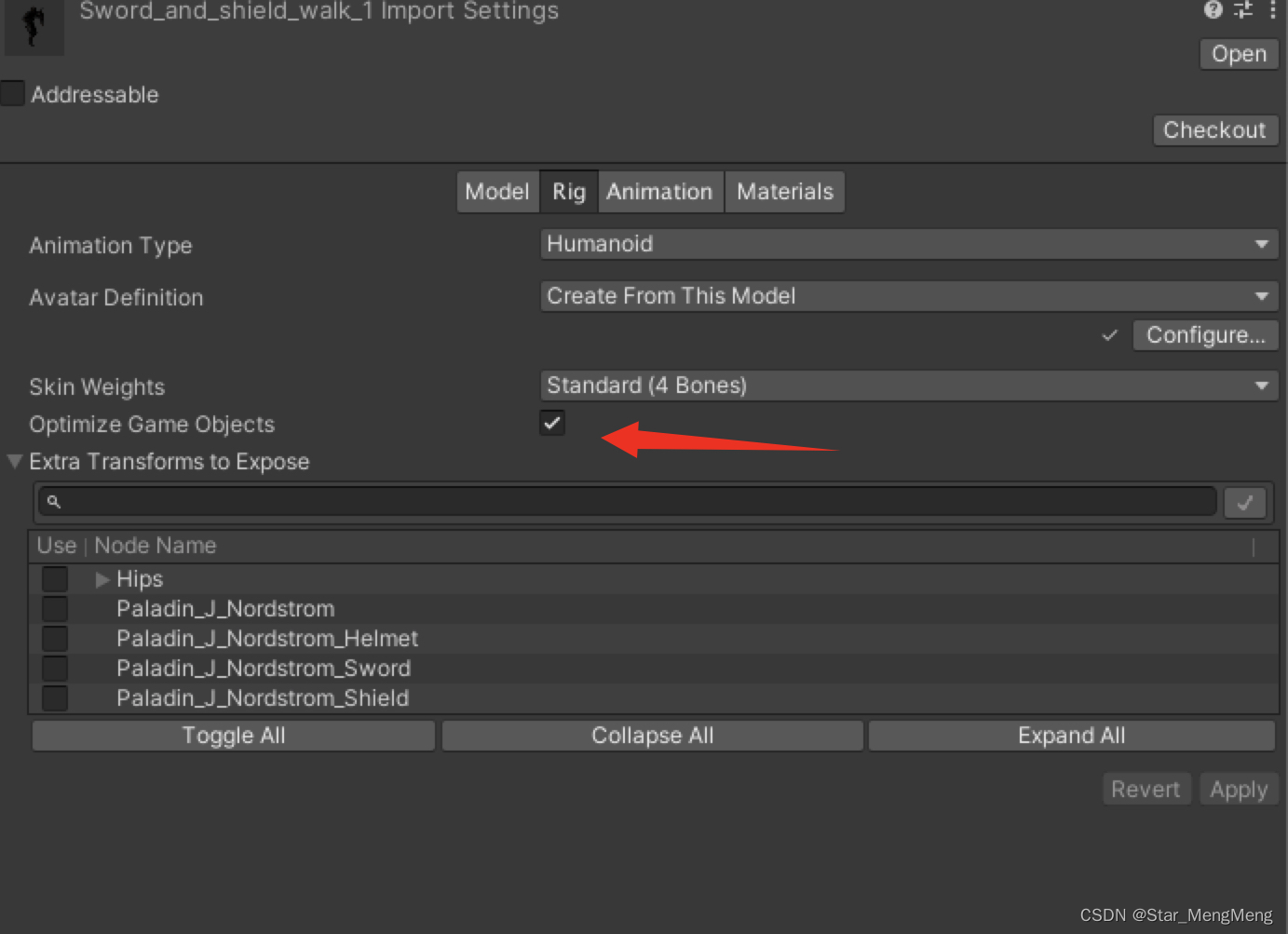
优化前后节点对比:
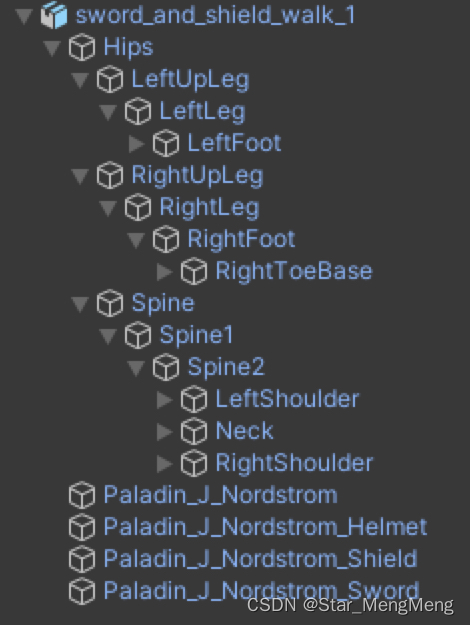

当勾选了该选项后,FBX中的骨骼节点,如果只有Transform组件,会被剔除不导入,
如果需要某些骨骼节点不被剔除,例如需要挂点,则需要在Extra Transform Paths中勾选对应的骨骼名称。
注意:不剔除的节点会被移到根节点之下,因此代码中不能通过原有路径查找(transform.Find(“Bip001/Bip001 Spine”))
Unity会将骨骼信息映射到avatar中,这样,unity在更新骨骼矩阵时,不再考虑场景中的Transform节点,也不用更新它的坐标,而是直接通过获取avatar骨骼信息来更新蒙皮,表现动画,从而节省了cpu计算
避免模型重叠面、重叠边,对于遮挡的地方,尽量简化模型细节,降低Overdraw
对于看不到的地方,如房子内部,使用单面模型,不需要双面都渲染
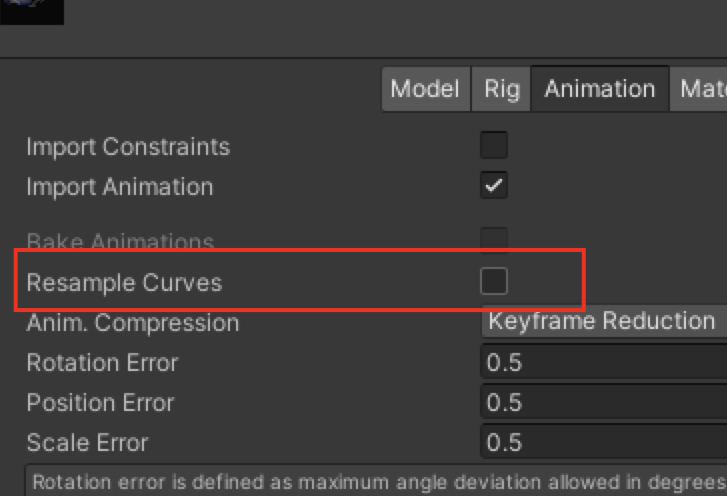
Resample Curves(根据项目实际CPU和内存瓶颈考虑,建议不勾选)
将动画中的 Euler 数据转换为 Quaternion,动画更新时使用 Quaternion,减少了计算转换,插值更平滑,较少的性能提升,10%-20%左右的内存增加。
Scale曲线删除
在资源导入脚本中加逻辑去掉 Scale 曲线,若某个动画对 Scale 曲线进行了操作,在文件命名上告诉脚本,跳过处理
压缩动画数据浮点数精度
当浮点数精度超过3位时,绝大部分人眼感知不到差别,过高的浮点数精度造成了存储上的浪费,在资源导入脚本中加逻辑去进行浮点数精度的压缩。
具体实现可以看我另一遍文章:
(Unity AssetPostProcessor资源导入规范自动化脚本(Presets))
二、贴图

Upload Buffer:在Unity 的 Quality 里设置如图,和声音的Buffer类似,填满后向GPU push 一次。
Read/Write:没必要的话就关闭,正常情况,Texture读进内存解析完了搁到Upload Buffer里之后,内存里那部分就会delete掉。除非开了Read/Write,那就不会delete了,会在显存和内存里各一份。前面说过手机内存显存通用的,所以内存里会有两份。
Mip Maps:例如UI元素这类相对于相机Z轴的值不会有任何变化的纹理,关闭该选项,场景中的模型切图可设置streaming Mipmaps,。
Format:选择合适的Format,可减少占用的空间。
alpha:对于不透明纹理,关闭其alpha通道。
Max Size:根据平台不同,纹理的Max Size设成该平台最小值。
Use Crunch Compression:紧致压缩,会降低图片质量,但会大大减小图片大小。
对于分辨率要求不高的贴图,限制maxSize的同时,压缩质量选择Low Quality,开启Compressor Quality
场景中的模型注意UV重合问题,同时删除多余的UV
注意模型点面数,可以采用增加细节贴图来优化模型减面造成的模糊问题;或者对细节要求不高的模型,可以删除法线贴图。
Android设备运行平台要求支持OpenGL ES 3.0的使用ETC2,RGB压缩为RGB Compressed ETC2 4bits,RGBA压缩为RGBA Compressed ETC2 8bits。需要兼容OpenGL ES 2.0的使用ETC,RGB压缩为RGB Compressed ETC 4bits,RGBA压缩为RGBA 16bits。(压缩大小不能接受的情况下,压缩为2张RGB Compressed ETC 4bits)
IOS设备运行平台要求支持OpenGL ES 3.0的使用ASTC,RGB压缩为RGB CompressedASTC 6x6 block,RGBA压缩为RGBA Compressed ASTC 4x4 block。对于法线贴图的压缩精度较高可以选择RGB CompressedASTC 5x5 block。需要兼容OpenGLES 2.0的使用PVRTC,RGB压缩为PVRTC 4bits,RGBA压缩为RGBA 16bits。(压缩大小不能接受的情况下,压缩为2张RGB Compressed PVRTC 4bits)
对需要合批的材质,Materials中勾选GPU Instancing。
注意:优先级Static Batching>SRP Batcher>GPU Instancing。GPU Instancing适合大量重复的模型,如树木、草等,此时其性能优于SRP Batcher。
字体:
游戏中使用的不同字体,根据需要进行裁剪,可以找一些字体裁剪软件处理。
对于半透明及透明物体,注意material上的渲染队列Render Queue,一般透明物体渲染队列2500+(默认是2000)。
渲染顺序:
(1)先渲染所有不透明物体,并开启它们的深度测试和深度写入。
(2)把半透明物体按它们距离摄像机的远近进行排序,然后按照从后往前的顺序渲染这些半透明物体,并开启它们的深度测试,但关闭深度写入。
对于透明渲染较多的项目,可以考虑开启URP 管线设置中的Depth Priming,半透明较多的情况下,在手机端同样有提升。
(Depth Priming对即使渲染有较好的效果,如一般的pc端游戏,对基于图块的渲染(tile-base)酌情使用,可能会导致负提升,如一般基于OpenGL或Vulkan安卓机或Metal)
三、音频

Force To Mono:这个选项作用是强制单声道,很多声音为了追求质量会设置成双声道,导致声音在包体和内存中,占用的空间加倍,但是95%以上的声音,两个声道是完全一样的数据。因此对声音不是很敏感的项目建议勾选此项,来降低内存的占用。
Compression Format:不同的平台有不同的声音格式的支持,IOS对MP3有硬件支持,Android暂时没有硬件支持。建议IOS适合使用ADPCM和MP3格式,Android适合使用Vorbis格式。
Load Type:决定声音在内存中的存在形态:
Decompress On Load当audio clip被加载时,解压声音数据适用于小型音频文件(< 200kb)Compressed In Memory声音数据将以压缩的形式保存在内存当中适用于中型音频文件(>= 200kb)Streaming从磁盘读取声音数据适用于大型音频文件,例如背景音
注:例如Decompress On Load,要求文件必须小于200kb,因为内部内存管理的问题,如果是大于200kb的文件,那么也还是只会被分配到不足200kb的内存。
我们可以对音频文件本身进行压缩,降低文件的比特率(bitrate),前提音频品质不会被破坏太严重。
四、UGUI

该组件是用来处理输入事件,默认挂载在每个Canvas上。有时不能互动的对象仍是canvas中的一部分,并附带了该组件,所以当每次鼠标或触控点击时,系统就要遍历所有可能接受输入事件的UI元素,就会造成多次的 “点落在矩形中” 的检查,来判断对象是否该作出反应。在UI很复杂的情况下,这个运算成本就会很高。因此建议确保只有可互动的Canvas才有该组件,节省CPU运行时间。

对于不需要接受射线检测的UI,关闭raycast target。
如果UI元素会改变数值或是位置,会影响批处理,导致向GPU发送更多的drawcall。
因此建议: 1、将更新频率不同的UI放在不同的Canvas上。 2、相同Canvas中的UI元素的Z值要相同,这样才不会打断批处理draw call。 3、相同Canvas中的UI元素要使用相同的材质和纹理,材质或着色器可以有动态变换(例如一些特效),这不会影响批处理。 4、相同Canvas中的UI元素要使用相同裁剪矩阵。
游戏中可能会有些全屏UI(例如一些设置界面),会遮挡住场景物体或其他UI元素。然而它们即使被遮挡看不见,CPU和GPU还是会有消耗。
因此建议: 1、3D场景完全被遮挡的话,关闭渲染3D场景的摄像机。 2、被遮蔽的UI,Disable这些Canvas,注意不是SetActive(false)。 3、尽可能的降低帧率,因为这些UI一般不需要刷新那么频繁,如果有个静态的UI画面 或者画面帧率只有15 那游戏的帧率就没必要到60。
能进行打包的图片,尽量打包成图集Altas。(UGUI的话需要导入2D Sprite,NGUI自带Altas maker)
尽量减少有透明通道的图片,如果有尽量保持透明通道的区域不要过大,注意overdraw
UI的隐藏我们可以使用将其移到Canvas外的方法,而不是利用SetActive(false)的方法来隐藏。
五、场景常用优化手段
1.批处理
我们可以使用批处理来尽量减少drawcall,使用批处理需要满足一些情况,例如,要批处理的对象必须引用一样的材质,并使用相同的纹理(纹理合并在这就很重要),但是使用的模型可以不一样。
动态批处理:可以减少对于移动对象的drawcall。只能用于少于900个顶点信息的情况,包含坐标、法线、uv0、uv1、切线。动态批处理每帧评估一次,由CPU负责。
静态批处理:即对开启 **static **标记的对象做批处理,在构建期完成。适用于绝大部分的静态Mesh,因此任何不会动的对象都应标记为静态的。如果我们在运行时要添加静态对象,可以看一下 StaticBatchUtility.Combine() 的API。
2.阴影
Cast Shadows
默认情况下,MeshRenderder组件的Cast Shadows是开启的。
阴影的渲染可以让游戏的光线增加真实度和深度感,但是某些情况下可能并不需要。在复杂场景中,可能会造成多余的阴影计算,阴影效果最后也看不见。因此若场景有的对象是否有阴影对整体效果没有影响的话,就关闭这个选项。不计算阴影可以省下CPU时间。
(小技巧:可以将阴影烘焙到光照贴图中,再关闭场景中的阴影,以减少点面数的渲染;对与阴影精度要求不高的物体或动态的人物等,可以采用“假”阴影的方式,如使用贴图模拟阴影,如使用低模物体渲染阴影等方式)
3.LOD(多层次细节)
会导致内存增加,酌情设置其LOD级别数量。
其LOD中的百分比数值代表屏占比
对于LOD的设置,如果模型存在缩放,需要先调整好Scale再将模型加入LOD Group,否则会导致LOD比例错误
根据相机距离GameObject或模型距离,切换模型精度。
要实现淡入淡出的切换,需要在shader里实现,添加lod切换
不同透明度的混合,是由于加个这些代码:
Tags { "RenderType"="Transparent" "Queue"="Transparent" }
LOD 200
#pragma surface surf Standard alpha fade
#pragma multi_compile _ LOD_FADE_CROSSFADE
还有阿尔法的设置代码
#ifdef LOD_FADE_CROSSFADE
o.Alpha = c.a * unity_LODFade.x;
//o.Albedo = o.Alpha;
#else
o.Alpha = c.a;
#endif

4.Light

Light Culling Mask
在复杂场景中,许多光线紧靠彼此,你可能觉得光线不能影响特定对象。根据渲染流程的设置,场景中越多的光照,性能可能就会越差。因此我们要确保光照只影响特定的对象层(例如专门给角色打光的光源,设置成只影响角色),尤其是多光源和多对象彼此紧靠的时候。
使用光照贴图、光照探针(设置探针范围,对动态物体模拟光照效果)、反射探针(模拟场景中光的反射效果)
物体勾选静态Contribute GI--Light可以使用Baked或Mixed--烘焙时光照可以适当提亮些
(如果是多场景,会使用ActiveScene的环境光)

Multiple Importance Sampling 多重重要采样,可以在生成灯光图时加快融合,但是在使用低频的天空盒时,这个选项会产生噪点,所以我们在预览烘焙时勾选,最终烘焙时取消。
DirectSamples :直接采样数 ,影响直接光照烘焙质量,数值越大效果越好,烘焙越慢,建议预览时用小值,最终烘焙时用大值
IndirectSamples :简介光采样数 ,影响简介光照烘焙质量,数值越大效果越好,烘焙越慢,这个值一般是 DirectSamples 的10倍,建议预览时用小值,最终烘焙时用大值
EnvironmentSamples:环境光采样数,建议预览时用小值,最终烘焙时用大值
LightProbeSampleMultiplier :烘焙灯光探头时使用的采样倍乘系数,这个一般是不可编辑的,如果想修改需要在 Edit->ProjectorSettings->Editor->Use legacy Light Probe sample counts 取消掉勾选
Bounces :光线弹射次数,即光线次数越多,环境光会相对越亮。
Filtering :有Auto自动模式和Advanced模式,一般刚开始建议直接使用Auto模式,主要用来处理噪点。高级模式的参数主要有
1. DirectDenoiser 直接光除噪器的选择 2. DirectFilter 直接光滤波器,主要就是gaussian(高斯模糊的模式),高斯模糊会导致部分 细节的丢失,下面的Radius 就是高斯模糊的半径 3. Radius 高斯模糊的半径 4. IndirectDenoiser 间接光除噪器 5. IndirectFilter 间接光滤波器 6. AmbientOcclusion 环境遮蔽除噪器 7. AmbientOcclusion Filter 环境遮蔽滤波器LightmapResolution :灯光图的分辨率,这里是指一个unity单位(一米)内需要使用多少个灯光图的像素,这个值越大,灯光图就会越大越多。这个需要根据场景的整体大小比例来确定,原则上灯光图的分辨率不需要太清晰,不是太清晰反而会使效果更柔和。
LightmapPadding:灯光的padding值,指各 UV 块之间的间隔距离
LightmapSize: 最大的灯光图尺寸,最大值4096,当一张不够时会增加灯光图的数量
CompressLightmaps :烘焙后自动压缩灯光图,可以减少存储空间,如果灯光不多,不大,可以不开启,来提升一定的灯光图细腻程度
AmbientOcclusion:环境遮蔽,开启后烘焙时会烘焙AO效果。
1. MaxDistance 超过这个距离的物体不会产生 AO 2. IndirectContribution 对间接光效果的影响程度 3. DirectContribution 对直接光照的影响程度 建议一直用0DirectionalMode:开启后烘焙后的物体在没有直接光影响的情况下,例如物体的暗部,会有法线效果,否则,物体的暗部会没有法线效果,建议开启为 Directional模式。Non-Directional 就是关闭模式
IndirectIntensity:烘焙时间接光的强度,建议使用默认值1 ,大于1会增强环境亮度,小于1会减弱环境光亮度。
AlbedoBoost : 漫反射增强,值越大漫反射颜色对光线的影响越大,最大为白色,建议使用默认值1,这样更科学准确.
Lightmap Parameter :静态物体参与烘焙时的参数设置,系统自带了高、中、低、极低四套,做视频基本够用
5.遮挡剔除
设置物体静态标签occluder static、occludee static(遮挡物,被遮挡物)。
bake烘焙数据。可根据实际需要烘焙的场景大小及范围,设置烘焙区域。
与之类似的是相机的视椎体剔除,默认是自动的
六、内存分析

截取当前帧内存使用情况。如分析Texture图片使用内存大小,进行针对优化设置。
- Other

System.ExecutableAndDlls:系统可执行程序和DLL,是只读的内存,用来执行所有的脚本和DLL引用。不同平台和不同硬件得到的值会不一样,可以通过修改Player Setting的Stripping Level来调节大小。
我试着修改了一下Stripping Level似乎没什么改变,感觉虽占用内存大但不会影响游戏运行。我们暂时忽略它吧(- -)!GfxClientDevice:GFX(图形加速\图形加速器\显卡 (GraphicsForce Express))客户端设备。
虽占用较大内存,但这也是必备项,没办法优化。继续忽略吧(- -)!!ManagedHeap.UsedSize:托管堆使用大小。
重点监控对象,不要让它超过**20MB**,否则可能会有性能问题!ShaderLab:Unity自带的着色器语言工具相关资源。
这个东西大家都比较熟悉了,忽略它吧。SerializedFile:序列化文件,把显示中的Prefab、Atlas和metadata等资源加载进内存。
重点监控对象,这里就是你要监控的哪些预设在序列化中在内存中占用大小,根据需求进行优化。PersistentManager.Remapper:持久化数据重映射管理相关
与持久化数据相关,比如AssetBundle之类的。注意监控相关的文件。ManagedHeap.ReservedUnusedSize:托管堆预留不使用内存大小,只由Mono使用。
无法优化。
** Assets——Texture2D**
- 许多贴图采用的Format格式是ARGB 32 bit所以保真度很高但占用的内存也很大。在不失真的前提下,适当压缩贴图,使用ARGB 16 bit就会减少一倍,如果继续Android采用RGBA Compressed ETC2 8 bits(iOS采用RGBA Compressed PVRTC 4 bits),又可以再减少一倍。把不需要透贴但有alpha通道的贴图,全都转换格式Android:RGB Compressed ETC 4 bits,iOS:RGB Compressed PVRTC 4 bits。
- 当加载一个新的Prefab或贴图,不及时回收,它就会永驻在内存中,就算切换场景也不会销毁。应该确定物体不再使用或长时间不使用就先把物体制空(null),然后调用Resources.UnloadUnusedAssets(),才能真正释放内存。
- 有大量空白的图集贴图,可以用TexturePacker等工具进行优化或考虑合并到其他图集中。
- Profiler内存重点关注优化项目
1)ManagedHeap.UsedSize: 移动游戏建议不要超过20MB.
2)SerializedFile: 通过异步加载(LoadFromCache、WWW等)的时候留下的序列化文件,可监视是否被卸载.
3)WebStream: 通过异步WWW下载的资源文件在内存中的解压版本,比SerializedFile大几倍或几十倍,不过我们现在项目中展示没有。
4)Texture2D: 重点检查是否有重复资源和超大Memory是否需要压缩等.
5)AnimationClip: 重点检查是否有重复资源.
6)Mesh: 重点检查是否有重复资源.
- 项目中可能遇到的问题
1.Device.Present:
1)GPU的presentdevice确实非常耗时,一般出现在使用了非常复杂的shader.
2)GPU运行的非常快,而由于Vsync的原因,使得它需要等待较长的时间.
3)同样是Vsync的原因,但其他线程非常耗时,所以导致该等待时间很长,比如:过量AssetBundle加载时容易出现该问题.
4)Shader.CreateGPUProgram:Shader在runtime阶段(非预加载)会出现卡顿(华为K3V2芯片).
5)StackTraceUtility.PostprocessStacktrace()和StackTraceUtility.ExtractStackTrace(): 一般是由Debug.Log或类似API造成,游戏发布后需将Debug API进行屏蔽。
2.Overhead:
1)一般情况为Vsync所致.
2)通常出现在Android设备上.
3.GC.Collect:
原因:
1)代码分配内存过量(恶性的)
2)一定时间间隔由系统调用(良性的).
占用时间:
1)与现有Garbage size相关
2)与剩余内存使用颗粒相关(比如场景物件过多,利用率低的情况下,GC释放后需要做内存重排)
4.GarbageCollectAssetsProfile:
1)引擎在执行UnloadUnusedAssets操作(该操作是比较耗时的,建议在切场景的时候进行)。
2)尽可能地避免使用Unity内建GUI,避免GUI.Repaint过渡GCAllow.
3)if(other.tag == a.tag)改为other.CompareTag(a.tag).因为other.tag为产生180B的GC Allow.
4)少用foreach,因为每次foreach为产生一个enumerator(约16B的内存分配),尽量改为for.
5)Lambda表达式,使用不当会产生内存泄漏.
5.尽量少用LINQ:
1)部分功能无法在某些平台使用.
2)会分配大量GC Allow.
6.控制StartCoroutine的次数:
1)开启一个Coroutine(协程),至少分配37B的内存.
2)Coroutine类的实例 -> 21B.
3)Enumerator -> 16B.
7.使用StringBuilder替代字符串直接连接.
8.缓存组件:
1)每次GetComponent均会分配一定的GC Allow.
2)每次Object.name都会分配39B的堆内存.
3)AddComponent
9.对象查找
如果目录结构较深或比较多,尽量少用GameObject.Find。可用Transform.Find,同时它还能找到隐藏gameObject。
10.缓存一些Hash值
在我们想要在运行时修改动画或者材质的时候,可以使用下面方法来实现 animator.SetTrigger("Idle");material.SetColor("Color", Color.white); 这类方法往往也可以通过索引来作为参数,使用字符串只是能显示的更加直观,但是当我们传递字符串时,程序内部会进行一些处理,频繁调用的话可能就会造成性能的消耗。因此我们可以先找到对应的索引,并将其缓存起来,供后续使用, 如下: int idleHash = Animator.StringToHash("Idle");animator.SetTrigger(idleHash); int colorId = Shader.PropertyToID("Color");material.SetColor(colorId, Color.white);
11.使用对象池
12.尽量少用foreach,for循环会更快一些,之前的版本foreach会产生GC,目前已经解决。
13.尽量避免过多的 Update 和 FixedUpdate 存在。可以自行实现计时回调器。
14.每个继承MonoBehaviour的类,都会自动生成Update方法,但很多类是用不到Update的,这时候需要将其删除,毕竟实时调用空方法,多少还是有消耗的。
15.数值计算中使用乘法而不用触发,比如 a / 2, 可以写成 a * 0.5f。
16.比较他Tag值时,使用if(gameObject.CompareTag("Tag")),而不是if(gameObject.tag == "Tag")。
17.注意自己的内存管理,包括GC资源、AssetsBundle资源、Resources资源等按需回收等。
18.代码LOD,不重要的时候使用简单处理。
19.使用 Vector.sqrMagnitude 替代 Vector.magnitude;使用 int 和 float 计算替代 Vector;使用 Transform.localPosition 替代 Transform.position:后者由前者计算转换得到。
20.使用协程代替Update,或者InvokeRepeating也可以。
and so on...... 很多代码优化点,后续再慢慢补充吧
版权归原作者 Star_MengMeng 所有, 如有侵权,请联系我们删除。