
引入jar
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.8.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>1.8.0</version></dependency><!-- flink整合kafka_2.11--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>1.10.0</version></dependency>
二、处理逻辑
//2、定义环境 => EnvStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(9);
env.enableCheckpointing(1000);FlinkKafkaConsumer<String> consumer =this.getConsumer();//调用下面的方法获取数据源
consumer.setStartFromLatest();//消费最新数据//2、绑定数据源=> resourceDataStream<String> stream = env.addSource(consumer);//3、批量读取的方法=>
stream.timeWindowAll(Time.milliseconds(500))//timeWindowAll:时间滚动窗口,滑动窗口会有数据元素重叠可能,而滚动窗口不存在元素重叠.apply(newReadKafkaFlinkWindowFunction())//使用自己定义的apply来收集.addSink(newKafkaBatchSink());//批量的sink方法
env.execute();
2、定义消费者,并且将消费者consumer转成FlinkKafkaConsumer
publicFlinkKafkaConsumer<String>getConsumer(){//定义消费者信息Properties properties =newProperties();
properties.put("bootstrap.servers","192.168.131.147:9092");
properties.put("group.id","flink-consumer-kafka-group");
properties.put("auto.offset.reset","latest");
properties.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");FlinkKafkaConsumer<String> consumer =newFlinkKafkaConsumer<>("demo",newSimpleStringSchema(), properties);return consumer;}
3、收集数据ReadKafkaFlinkWindowFunction的实现类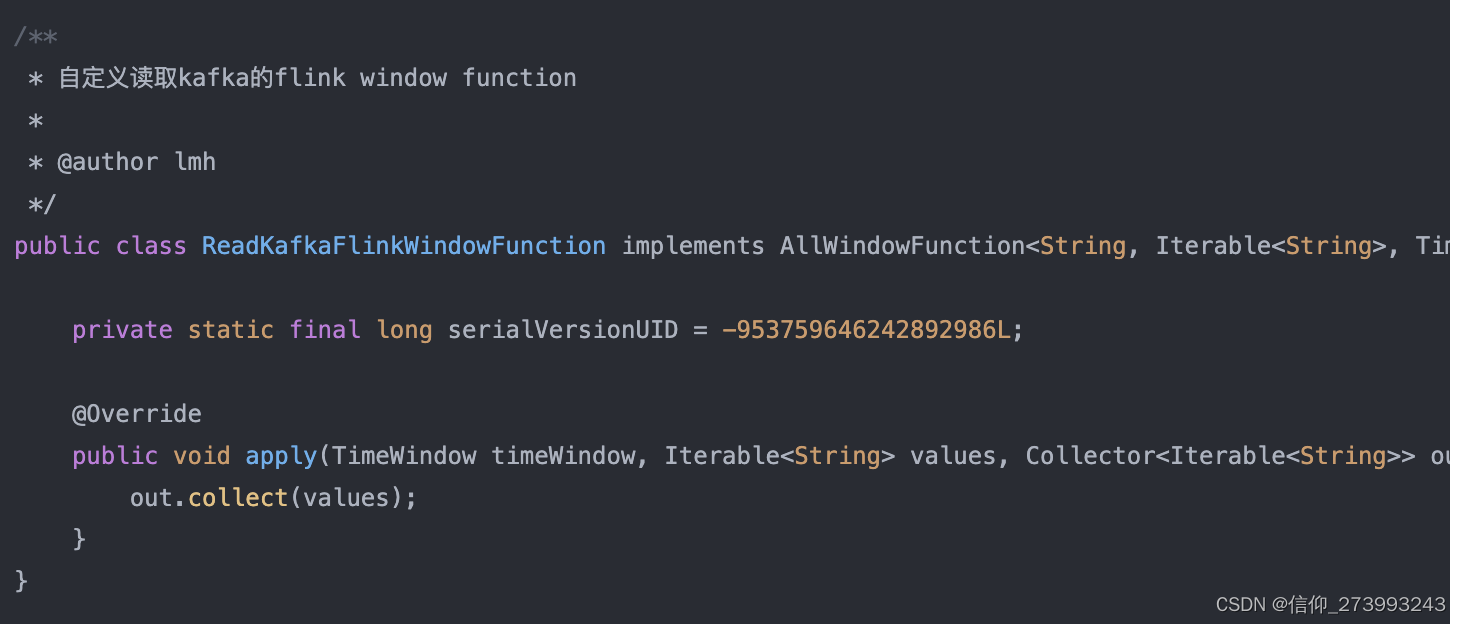 4、KafkaBatchSink的实现逻辑
4、KafkaBatchSink的实现逻辑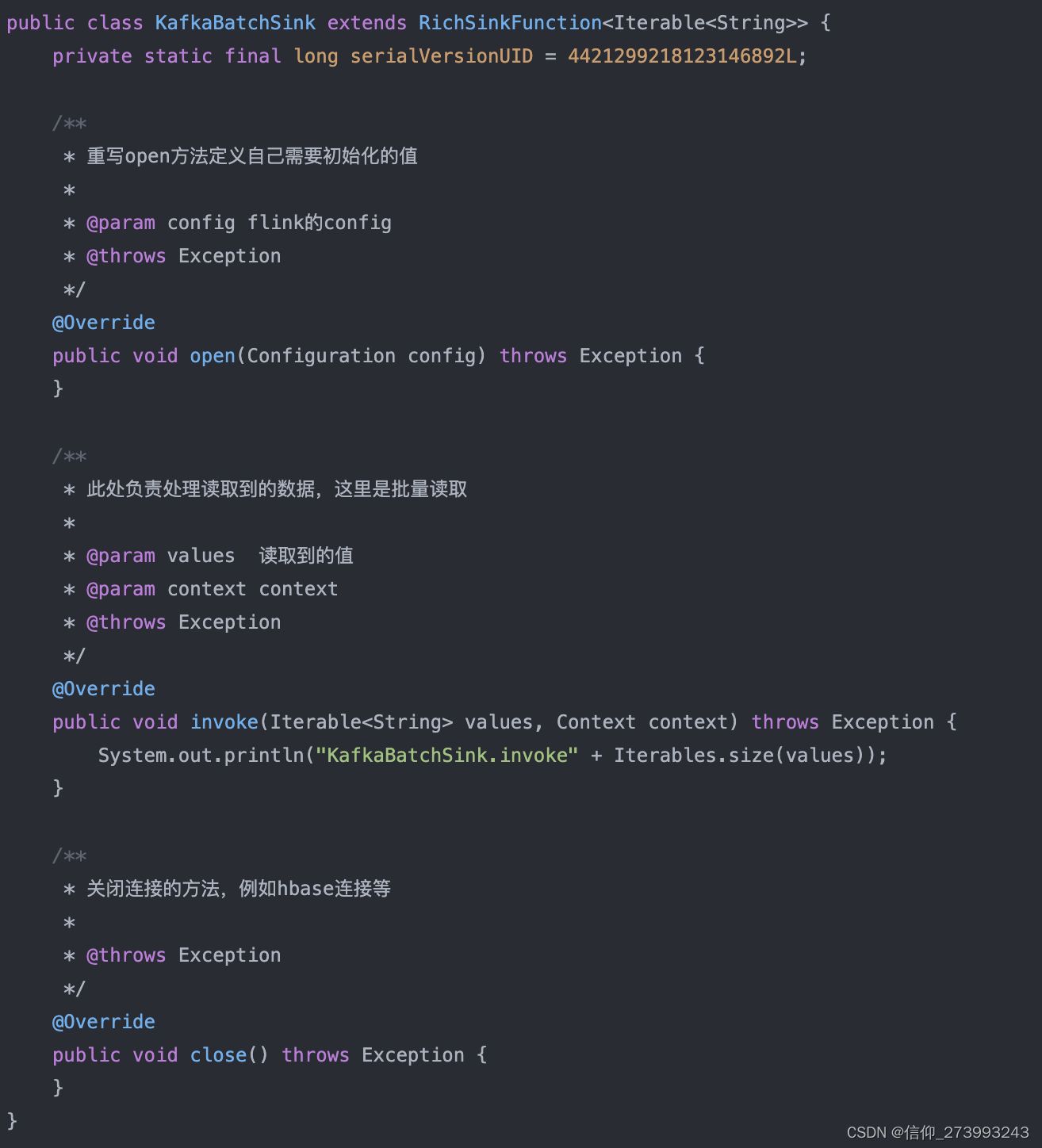
总结
分布式处理引擎Flink使用至少一个【job】调度和至少一个【task】实现分布式处理
有界:就是指flink【消费指定范围内】的数据。例如我定义某个作业间隔时间为0.5秒,则flink已0.5秒为界,进行数据处理。有界数据用在离线数据的处理场景较多
无界:就是指flink始终【监听数据源】里的数据,获取到就处理。无界数据往往用在【实时数据】处理下的场景较多。
我这里结合我们项目的场景来给各位说一下该选那种处理。我们的场景为:
1:尽量支持最多的数据落地
2:数据必须要准确。所以我们最终了有界处理,将flink的界限设置为0.5秒,0.5秒内收集的所有数据整体使用一个算
子消费。保证数据的准确和消费高效性。
1、一定要有抛出异常的机制
我们都知道抛出异常会终止消费,但是为什么要抛出异常呢?这注意是因为如果用户不抛出异常的话,flink会认为当前的数据时正常消费的,这就造成了我们的kafka数据误消费
2、关于并行度parallelism
并行度的配置都是setParallelism,对于env和stream来说,stream的优先级比env高
3、关于checkpoint
我们如果定义程序运行在SPring Boot时,一定要配置检查点这个是flink实现容错的核心配置!
4、关于并行度
我们在设置并行度的时候,将里边的数字设置为多少,最终就会有多少个线程来执行任务。
所以大家一定要清楚对于数据准确性高的数据来说,宁愿牺牲多线程带来的效率提升也要只设置一个线程来执行消费。
可能大家没有注意,如果你不设置flink的并行度为1时。它是以的是系统的线程数来作为并行度!这样顺序是会乱的。
5、saveBatch很好
但是我建议你先封装一下或者改为批量的保存。可能大家都知道或者说都用过mybatis plus的saveBatch,它能将一个列表的inseert封装为一条sql(insert into a values(a1),(a2),(a3)),但是我们一条sql的长度过长的话会存在性能问题。建议在批量处理的时候每隔1000条记录saveBatch一次
为什么flink消费kafka比官方的listener都要快
1、并行度和分区处理: Flink 具有高度的并行度支持
可以为每个 Kafka 分区创建独立的消费者实例,以便并行地处理多个分区。这使得 Flink能够更有效地利用资源,并提高整体的消费速度。相比之下,一些官方 Kafka Consumer 实现可能没有明确的并行度配置或并行处理策略。
2、事件时间处理
Flink 强调【事件时间】处理,支持按照事件的实际发生时间进行【有序处理】。这对于一些需要处理时间相关业务逻辑的应用来说很重要。Flink 可以轻松处理乱序事件,并确保事件按照正确的顺序进行处理。官方 Kafka Consumer 也提供了类似的功能,但 Flink在这方面的设计更加深入和专注。
状态管理
Flink 提供了强大的状态管理机制,对于需要在处理过程中保持状态的任务,这一点非常重要。在消费 Kafka消息时,可能需要追踪某些状态,例如记录已处理的偏移量。Flink 的状态管理可以更好地支持这种场景,而官方 Kafka Consumer可能没有提供类似的状态管理机制。
异步处理模型:
Flink 使用异步处理模型,这使得在处理一条消息时,可以同时进行其他处理而无需等待。这有助于提高整体的处理效率。
版权归原作者 信仰_273993243 所有, 如有侵权,请联系我们删除。