
kafka-python:https://github.com/dpkp/kafka-python
kafka-python 文档:https://kafka-python.readthedocs.io/en/master/apidoc/modules.html
kafka 官方文档:http://kafka.apache.org/documentation.html
Python 操作 Kafka 的通俗总结(kafka-python):https://zhuanlan.zhihu.com/p/279784873
译:Kafka 和 Unix 管道的示例:http://zqhxuyuan.github.io/2016/01/05/2016-01-05-Kafka-Unix/
一、基本概念
- Topic:一组消息数据的标记符;
- Producer:生产者,用于生产数据,可将生产后的消息送入指定的 Topic;
- Consumer:消费者,获取数据,可消费指定的 Topic 里面的数据
- Group:消费者组,同一个 group 可以有多个消费者,一条消息在一个 group 中,只会被一个消费者 获取;
- Partition:分区,为了保证 kafka 的吞吐量,一个 Topic 可以设置多个分区。同一分区只能被一个消费者订阅。
二、安装 kafka-python
pip 命令:pip install kafka-python
三、生产者(Producer)与 消费者(Consumer)
生产者 示例:
# -*- coding: utf-8 -*-
import json
import json
import msgpack
from loguru import logger
from kafka import KafkaProducer
from kafka.errors import KafkaError
def kfk_produce_1():
"""
发送 json 格式数据
:return:
"""
producer = KafkaProducer(
bootstrap_servers='ip:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
producer.send('test_topic', {'key1': 'value1'})
def kfk_produce_2():
"""
发送 string 格式数据
:return:
"""
producer = KafkaProducer(bootstrap_servers='xxxx:x')
data_dict = {
"name": 'king',
'age': 100,
"msg": "Hello World"
}
msg = json.dumps(data_dict)
producer.send('test_topic', msg, partition=0)
producer.close()
def kfk_produce_3():
producer = KafkaProducer(bootstrap_servers=['broker1:1234'])
# Asynchronous by default ( 默认是异步发送 )
future = producer.send('my-topic', b'raw_bytes')
# Block for 'synchronous' sends
try:
record_metadata = future.get(timeout=10)
except KafkaError:
# Decide what to do if produce request failed...
logger.error(KafkaError)
pass
# Successful result returns assigned partition and offset
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
# produce keyed messages to enable hashed partitioning
producer.send('my-topic', key=b'foo', value=b'bar')
# encode objects via msgpack
producer = KafkaProducer(value_serializer=msgpack.dumps)
producer.send('msgpack-topic', {'key': 'value'})
# produce json messages
producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii'))
producer.send('json-topic', {'key': 'value'})
# produce asynchronously
for _ in range(100):
producer.send('my-topic', b'msg')
def on_send_success(record_metadata=None):
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
def on_send_error(excp=None):
logger.error('I am an errback', exc_info=excp)
# handle exception
# produce asynchronously with callbacks
producer.send('my-topic', b'raw_bytes').add_callback(on_send_success).add_errback(on_send_error)
# block until all async messages are sent
producer.flush()
# configure multiple retries
producer = KafkaProducer(retries=5)
if __name__ == '__main__':
kfk_produce_1()
kfk_produce_2()
pass
消费者 示例:
# -*- coding: utf-8 -*-
import json
import msgpack
from kafka import KafkaConsumer
# To consume latest messages and auto-commit offsets
consumer = KafkaConsumer(
'my-topic', group_id='my-group',
bootstrap_servers=['localhost:9092']
)
for message in consumer:
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
info = f'{message.topic}:{message.partition}:{message.offset}: key={message.key}, value={message.value}'
print(info)
# consume earliest available messages, don't commit offsets
KafkaConsumer(auto_offset_reset='earliest', enable_auto_commit=False)
# consume json messages
KafkaConsumer(value_deserializer=lambda m: json.loads(m.decode('ascii')))
# consume msgpack
KafkaConsumer(value_deserializer=msgpack.unpackb)
# StopIteration if no message after 1sec ( 没有消息时,1s后停止消费 )
KafkaConsumer(consumer_timeout_ms=1000)
# Subscribe to a regex topic pattern
consumer = KafkaConsumer()
consumer.subscribe(pattern='^awesome.*')
# Use multiple consumers in parallel w/ 0.9 kafka brokers
# typically you would run each on a different server / process / CPU
consumer1 = KafkaConsumer(
'my-topic', group_id='my-group',
bootstrap_servers='my.server.com'
)
consumer2 = KafkaConsumer(
'my-topic', group_id='my-group',
bootstrap_servers='my.server.com'
)
简单封装:
# -*- coding: utf-8 -*-
import time
import json
import ujson
import random
from loguru import logger
from kafka import KafkaProducer, KafkaConsumer
class KafkaOperate(object):
def __init__(self, bootstrap_servers=None):
if not bootstrap_servers:
raise Exception('bootstrap_servers is None')
self.__bootstrap_servers = None
if isinstance(bootstrap_servers, str):
ip_port_string = bootstrap_servers.strip()
if ',' in ip_port_string:
self.__bootstrap_servers = ip_port_string.replace(' ', '').split(',')
else:
self.__bootstrap_servers = [ip_port_string]
self.kafka_producer = None
self.kafka_consumer = None
pass
def __del__(self):
pass
def kfk_consume(self, topic_name=None, group_id='my_group'):
if not self.kafka_consumer:
self.kafka_consumer = KafkaConsumer(
topic_name, group_id=group_id,
bootstrap_servers=self.__bootstrap_servers,
auto_offset_reset='earliest',
)
count = 0
for msg in self.kafka_consumer:
count += 1
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
info = f'[{count}] {msg.topic}:{msg.partition}:{msg.offset}: key={msg.key}, value={msg.value.decode("utf-8")}'
logger.info(info)
time.sleep(1)
def __kfk_produce(self, topic_name=None, data_dict=None, partition=None):
"""
如果想要多线程进行消费,可以设置 发往不通的 partition
有多少个 partition 就可以启多少个线程同时进行消费,
:param topic_name:
:param data_dict:
:param partition:
:return:
"""
if not self.kafka_producer:
self.kafka_producer = KafkaProducer(
bootstrap_servers=self.__bootstrap_servers,
client_id='my_group',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# data_dict = {
# "name": 'king',
# 'age': 100,
# "msg": "Hello World"
# }
if partition:
self.kafka_producer.send(
topic=topic_name,
value=data_dict,
# key='count_num', # 同一个key值,会被送至同一个分区
partition=partition
)
else:
self.kafka_producer.send(topic_name, data_dict)
pass
def kfk_produce_one(self, topic_name=None, data_dict=None, partition=None, partition_count=1):
partition = partition if partition else random.randint(0, partition_count-1)
self.__kfk_produce(topic_name=topic_name, data_dict=data_dict, partition=partition)
self.kafka_producer.flush()
def kfk_produce_many(self, topic_name=None, data_dict_list=None, partition=None, partition_count=1, per_count=100):
count = 0
for data_dict in data_dict_list:
partition = partition if partition else count % partition_count
self.__kfk_produce(topic_name=topic_name, data_dict=data_dict, partition=partition)
if 0 == count % per_count:
self.kafka_producer.flush()
count += 1
self.kafka_producer.flush()
pass
@staticmethod
def get_consumer(group_id: str, bootstrap_servers: list, topic: str, enable_auto_commit=True) -> KafkaConsumer:
topics = tuple([x.strip() for x in topic.split(',') if x.strip()])
if enable_auto_commit:
return KafkaConsumer(
*topics,
group_id=group_id,
bootstrap_servers=bootstrap_servers,
auto_offset_reset='earliest',
# fetch_max_bytes=FETCH_MAX_BYTES,
# connections_max_idle_ms=CONNECTIONS_MAX_IDLE_MS,
# max_poll_interval_ms=KAFKA_MAX_POLL_INTERVAL_MS,
# session_timeout_ms=SESSION_TIMEOUT_MS,
# max_poll_records=KAFKA_MAX_POLL_RECORDS,
# request_timeout_ms=REQUEST_TIMEOUT_MS,
# auto_commit_interval_ms=AUTO_COMMIT_INTERVAL_MS,
value_deserializer=lambda m: ujson.loads(m.decode('utf-8'))
)
else:
return KafkaConsumer(
*topics,
group_id=group_id,
bootstrap_servers=bootstrap_servers,
auto_offset_reset='earliest',
# fetch_max_bytes=FETCH_MAX_BYTES,
# connections_max_idle_ms=CONNECTIONS_MAX_IDLE_MS,
# max_poll_interval_ms=KAFKA_MAX_POLL_INTERVAL_MS,
# session_timeout_ms=SESSION_TIMEOUT_MS,
# max_poll_records=KAFKA_MAX_POLL_RECORDS,
# request_timeout_ms=REQUEST_TIMEOUT_MS,
enable_auto_commit=enable_auto_commit,
value_deserializer=lambda m: ujson.loads(m.decode('utf-8'))
)
@staticmethod
def get_producer(bootstrap_servers: list):
return KafkaProducer(bootstrap_servers=bootstrap_servers, retries=5)
if __name__ == '__main__':
bs = '10.10.10.10:9092'
kafka_op = KafkaOperate(bootstrap_servers=bs)
kafka_op.kfk_consume(topic_name='001_test')
pass
示例:
# -*- coding:utf-8 -*-
import json
from kafka import KafkaConsumer, KafkaProducer
class KProducer:
def __init__(self, bootstrap_servers, topic):
"""
kafka 生产者
:param bootstrap_servers: 地址
:param topic: topic
"""
self.producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
value_serializer=lambda m: json.dumps(m).encode('ascii'), ) # json 格式化发送的内容
self.topic = topic
def sync_producer(self, data_li: list):
"""
同步发送 数据
:param data_li: 发送数据
:return:
"""
for data in data_li:
future = self.producer.send(self.topic, data)
record_metadata = future.get(timeout=10) # 同步确认消费
partition = record_metadata.partition # 数据所在的分区
offset = record_metadata.offset # 数据所在分区的位置
print('save success, partition: {}, offset: {}'.format(partition, offset))
def asyn_producer(self, data_li: list):
"""
异步发送数据
:param data_li:发送数据
:return:
"""
for data in data_li:
self.producer.send(self.topic, data)
self.producer.flush() # 批量提交
def asyn_producer_callback(self, data_li: list):
"""
异步发送数据 + 发送状态处理
:param data_li:发送数据
:return:
"""
for data in data_li:
self.producer.send(self.topic, data).add_callback(self.send_success).add_errback(self.send_error)
self.producer.flush() # 批量提交
def send_success(self, *args, **kwargs):
"""异步发送成功回调函数"""
print('save success')
return
def send_error(self, *args, **kwargs):
"""异步发送错误回调函数"""
print('save error')
return
def close_producer(self):
try:
self.producer.close()
except:
pass
if __name__ == '__main__':
send_data_li = [{"test": 1}, {"test": 2}]
kp = KProducer(topic='topic', bootstrap_servers='127.0.0.1:9001,127.0.0.1:9002')
# 同步发送
kp.sync_producer(send_data_li)
# 异步发送
# kp.asyn_producer(send_data_li)
# 异步+回调
# kp.asyn_producer_callback(send_data_li)
kp.close_producer()
KafkaConsumer 的 构造参数:
- *topics ,要订阅的主题
- *auto_offset_reset:总共3种值:earliest 、latest、none earliest : 当各分区下有已提交的 offset 时,从提交的 offset 开始消费; 无提交的 offset时,从头开始消费latest :当各分区下有已提交的offset时,从提交的offset开始消费; 无提交的offset时,消费新产生的该分区下的数据***none : topic 各分区都存在已提交的 offset 时,从 offset 后开始消费; 只要有一个分区不存在已提交的 offset,则抛出异常
- bootstrap_servers :kafka节点或节点的列表,不一定需要罗列所有的kafka节点。格式为: ‘host[:port]’ 。默认值是:localhost:9092
- client_id (str) : 客户端id,默认值: ‘kafka-python-{version}’
- group_id (str or None):分组id
- key_deserializer (callable) :key反序列化函数
- value_deserializer (callable):value反序列化函数
- fetch_min_bytes:服务器应每次返回的最小数据量
- fetch_max_wait_ms (int): 服务器应每次返回的最大等待时间
- fetch_max_bytes (int) :服务器应每次返回的最大数据量
- max_partition_fetch_bytes (int) :
- request_timeout_ms (int) retry_backoff_ms (int)
- reconnect_backoff_ms (int)
- reconnect_backoff_max_ms (int)
- max_in_flight_requests_per_connection (int)
- auto_offset_reset (str) enable_auto_commit (bool)
- auto_commit_interval_ms (int)
- default_offset_commit_callback (callable)
- check_crcs (bool)
- metadata_max_age_ms (int)
- partition_assignment_strategy (list)
- max_poll_records (int)
- max_poll_interval_ms (int)
- session_timeout_ms (int)
- heartbeat_interval_ms (int)
- receive_buffer_bytes (int)
- send_buffer_bytes (int)
- socket_options (list)
- consumer_timeout_ms (int)
- skip_double_compressed_messages (bool)
- security_protocol (str)
- ssl_context (ssl.SSLContext)
- ssl_check_hostname (bool)
- ssl_cafile (str) –
- ssl_certfile (str)
- ssl_keyfile (str)
- ssl_password (str)
- ssl_crlfile (str)
- api_version (tuple)
KafkaConsumer 的 函数
- assign(partitions):手动为该消费者分配一个topic分区列表。
- assignment():获取当前分配给该消费者的topic分区。
- beginning_offsets(partitions):获取给定分区的第一个偏移量。
- close(autocommit=True):关闭消费者
- commit(offsets=None):提交偏移量,直到成功或错误为止。
- commit_async(offsets=None, callback=None):异步提交偏移量。
- committed(partition):获取给定分区的最后一个提交的偏移量。
- end_offsets(partitions):获取分区的最大偏移量
- highwater(partition):分区最大的偏移量
- metrics(raw=False):返回消费者性能指标
- next():返回下一条数据
- offsets_for_times(timestamps):根据时间戳获取分区偏移量
- partitions_for_topic(topic):返回topic的partition列表,返回一个set集合
- pause(*partitions):停止获取数据paused():返回停止获取的分区poll(timeout_ms=0, max_records=None):获取数据
- position(partition):获取分区的偏移量
- resume(*partitions):恢复抓取指定的分区
- seek(partition, offset):seek偏移量
- seek_to_beginning(*partitions):搜索最旧的偏移量
- seek_to_end(*partitions):搜索最近可用的偏移量
- subscribe(topics=(), pattern=None, listener=None):订阅topics
- subscription():返回当前消费者消费的所有topic
- topics():返回当前消费者消费的所有topic,返回的是unicode
- unsubscribe():取消订阅所有的topic
简单的消费者代码:
from kafka import KafkaConsumer
consumer = KafkaConsumer('test_rhj', bootstrap_servers=['xxxx:x'])
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (
msg.topic, msg.partition, msg.offset, msg.key, msg.value
)
print(recv)

kafka 的 分区机制
如果想要完成负载均衡,就需要知道 kafka 的分区机制,
- 同一个 主题** ( topic )** ,可以为其分区,
- 生产者在不指定分区的情况,kafka 会将多个消息分发到不同的分区,
消费者订阅时候
- 如果 不指定服务组,会收到所有分区的消息,
- 如果 指定了服务组,则同一服务组的消费者会消费不同的分区,
- 如果2个分区两个消费者的消费者组消费,则每个消费者消费一个分区,
- 如果有三个消费者的服务组,则会出现一个消费者消费不到数据;如果想要消费同一分区,则需要用不同的服务组。
以此为原理,我们对消费者做如下修改:
from kafka import KafkaConsumer
consumer = KafkaConsumer(
'test_rhj',
group_id='123456',
bootstrap_servers=['10.43.35.25:4531']
)
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (
msg.topic, msg.partition, msg.offset, msg.key, msg.value
)
print(recv)
开两个消费者进行消费,生产者分别往 0分区 和 1分区 发消息结果如下,可以看到,一个消费者只能消费0分区,另一个只能消费1分区:


偏移量
kafka 提供了 "偏移量" 的概念,允许消费者根据偏移量消费之前遗漏的内容,这基于 kafka 名义上的全量存储,可以保留大量的历史数据,历史保存时间是可配置的,一般是7天,如果偏移量定位到了已删除的位置那也会有问题,但是这种情况可能很小;每个保存的数据文件都是以偏移量命名的,当前要查的偏移量减去文件名就是数据在该文件的相对位置。要指定偏移量消费数据,需要指定该消费者要消费的分区,否则代码会找不到分区而无法消费,代码如下:
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
consumer = KafkaConsumer(
group_id='123456', bootstrap_servers=['10.43.35.25:4531']
)
consumer.assign(
[
TopicPartition(topic='test_rhj', partition=0),
TopicPartition(topic='test_rhj', partition=1)
]
)
print(consumer.partitions_for_topic("test_rhj")) # 获取test主题的分区信息
print(consumer.assignment())
print(consumer.beginning_offsets(consumer.assignment()))
consumer.seek(TopicPartition(topic='test_rhj', partition=0), 0)
for msg in consumer:
recv = "%s:%d:%d: key=%s value=%s" % (
msg.topic, msg.partition, msg.offset, msg.key, msg.value
)
print(recv)
因为指定的偏移量为 0,所以从一开始插入的数据都可以查到,而且因为指定了分区,指定的分区结果都可以消费,结果如下:
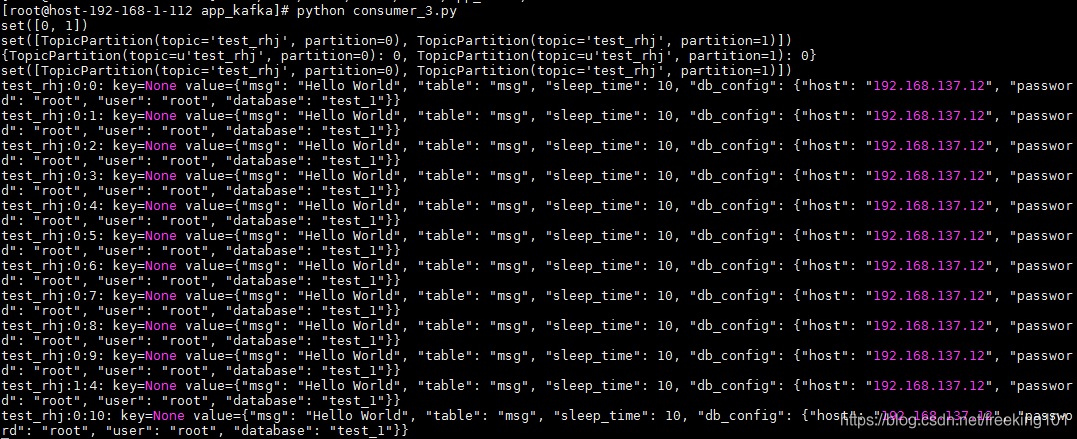
有时候,我们并不需要实时获取数据,因为这样可能会造成性能瓶颈,我们只需要定时去获取队列里的数据然后批量处理就可以,这种情况,我们可以选择主动拉取数据
from kafka import KafkaConsumer
import time
consumer = KafkaConsumer(group_id='123456', bootstrap_servers=['10.43.35.25:4531'])
consumer.subscribe(topics=('test_rhj',))
index = 0
while True:
msg = consumer.poll(timeout_ms=5) # 从kafka获取消息
print(msg)
time.sleep(2)
index += 1
print('--------poll index is %s----------' % index)
结果如下,可以看到,每次拉取到的都是前面生产的数据,可能是多条的列表,也可能没有数据,如果没有数据,则拉取到的为空:
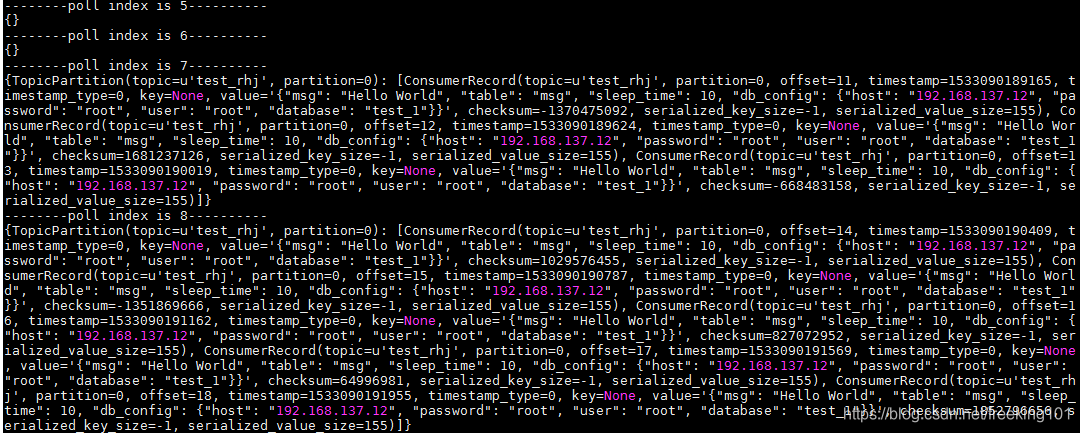
消费者 示例
# coding:utf8
from kafka import KafkaConsumer
# 创建一个消费者,指定了topic,group_id,bootstrap_servers
# group_id: 多个拥有相同group_id的消费者被判定为一组,
# 一条数据记录只会被同一个组中的一个消费者消费
# bootstrap_servers:kafka的节点,多个节点使用逗号分隔
# 这种方式只会获取新产生的数据
bootstrap_server_list = [
'192.168.70.221:19092',
'192.168.70.222:19092',
'192.168.70.223:19092'
]
consumer = KafkaConsumer(
# kafka 集群地址
bootstrap_servers=','.join(bootstrap_server_list),
group_id="my.group", # 消费组id
enable_auto_commit=True, # 每过一段时间自动提交所有已消费的消息(在迭代时提交)
auto_commit_interval_ms=5000, # 自动提交的周期(毫秒)
)
consumer.subscribe(["my.topic"]) # 消息的主题,可以指定多个
for msg in consumer: # 迭代器,等待下一条消息
print(msg) # 打印消息
多线程 消费
# coding:utf-8
import os
import sys
import threading
from kafka import KafkaConsumer, TopicPartition, OffsetAndMetadata
from collections import OrderedDict
threads = []
class MyThread(threading.Thread):
def __init__(self, thread_name, topic, partition):
threading.Thread.__init__(self)
self.thread_name = thread_name
self.partition = partition
self.topic = topic
def run(self):
print("Starting " + self.name)
consumer(self.thread_name, self.topic, self.partition)
def stop(self):
sys.exit()
def consumer(thread_name, topic, partition):
broker_list = 'ip1:9092,ip2:9092'
'''
fetch_min_bytes(int) - 服务器为获取请求而返回的最小数据量,否则请等待
fetch_max_wait_ms(int) - 如果没有足够的数据立即满足fetch_min_bytes给出的要求,服务器在回应提取请求之前将阻塞的最大时间量(以毫秒为单位)
fetch_max_bytes(int) - 服务器应为获取请求返回的最大数据量。这不是绝对最大值,如果获取的第一个非空分区中的第一条消息大于此值,
则仍将返回消息以确保消费者可以取得进展。注意:使用者并行执行对多个代理的提取,因此内存使用将取决于包含该主题分区的代理的数量。
支持的Kafka版本> = 0.10.1.0。默认值:52428800(50 MB)。
enable_auto_commit(bool) - 如果为True,则消费者的偏移量将在后台定期提交。默认值:True。
max_poll_records(int) - 单次调用中返回的最大记录数poll()。默认值:500
max_poll_interval_ms(int) - poll()使用使用者组管理时的调用之间的最大延迟 。这为消费者在获取更多记录之前可以闲置的时间量设置了上限。
如果 poll()在此超时到期之前未调用,则认为使用者失败,并且该组将重新平衡以便将分区重新分配给另一个成员。默认300000
'''
consumer_1 = KafkaConsumer(
bootstrap_servers=broker_list,
group_id="test000001",
client_id=thread_name,
enable_auto_commit=False,
fetch_min_bytes=1024 * 1024, # 1M
# fetch_max_bytes=1024 * 1024 * 1024 * 10,
fetch_max_wait_ms=60000, # 30s
request_timeout_ms=305000,
# consumer_timeout_ms=1,
# max_poll_records=5000,
)
# 设置topic partition
tp = TopicPartition(topic, partition)
# 分配该消费者的TopicPartition,也就是topic和partition,
# 根据参数,每个线程消费者消费一个分区
consumer_1.assign([tp])
# 获取上次消费的最大偏移量
offset = consumer_1.end_offsets([tp])[tp]
print(thread_name, tp, offset)
# 设置消费的偏移量
consumer_1.seek(tp, offset)
print(u"程序首次运行\t线程:", thread_name, u"分区:", partition, u"偏移量:", offset, u"\t开始消费...")
num = 0 # 记录该消费者消费次数
while True:
msg = consumer_1.poll(timeout_ms=60000)
end_offset = consumer_1.end_offsets([tp])[tp]
'''可以自己记录控制消费'''
print(u'已保存的偏移量', consumer_1.committed(tp), u'最新偏移量,', end_offset)
if len(msg) > 0:
print(u"线程:", thread_name, u"分区:", partition, u"最大偏移量:", end_offset, u"有无数据,", len(msg))
lines = 0
for data in msg.values():
for line in data:
print(line)
lines += 1
'''
do something
'''
# 线程此批次消息条数
print(thread_name, "lines", lines)
if True:
# 可以自己保存在各topic, partition的偏移量
# 手动提交偏移量 offsets格式:{TopicPartition:OffsetAndMetadata(offset_num,None)}
consumer_1.commit(offsets={tp: (OffsetAndMetadata(end_offset, None))})
if not 0:
# 系统退出?这个还没试
os.exit()
'''
sys.exit() 只能退出该线程,也就是说其它两个线程正常运行,主程序不退出
'''
else:
os.exit()
else:
print(thread_name, '没有数据')
num += 1
print(thread_name, "第", num, "次")
if __name__ == '__main__':
try:
t1 = MyThread("Thread-0", "test", 0)
threads.append(t1)
t2 = MyThread("Thread-1", "test", 1)
threads.append(t2)
t3 = MyThread("Thread-2", "test", 2)
threads.append(t3)
for t in threads:
t.start()
for t in threads:
t.join()
print("exit program with 0")
except:
print("Error: failed to run consumer program")
高级用法(消费者)
从指定 offset 开始读取消息,被消费过的消息也可以被此方法读取
创建消费者
- 使用 assign 方法重置指定分区(partition)的读取偏移(fetch offset)的值
- 使用 seek 方法从指定的partition和offset开始读取数据
#encoding:utf8
from kafka import KafkaConsumer, TopicPartition
my_topic = "my.topic" # 指定需要消费的主题
consumer = KafkaConsumer(
# kafka集群地址
bootstrap_servers = "192.168.70.221:19092,192.168.70.222:19092",
group_id = "my.group", # 消费组id
enable_auto_commit = True, # 每过一段时间自动提交所有已消费的消息(在迭代时提交)
auto_commit_interval_ms = 5000, # 自动提交的周期(毫秒)
)
consumer.assign([
TopicPartition(topic=my_topic, partition=0),
TopicPartition(topic=my_topic, partition=1),
TopicPartition(topic=my_topic, partition=2)
])
# 指定起始 offset 为 12
consumer.seek(TopicPartition(topic=my_topic, partition=0), 12)
# 可以注册多个分区,此分区从第一条消息开始接收
consumer.seek(TopicPartition(topic=my_topic, partition=1), 0)
# 没有注册的分区上的消息不会被消费
# consumer.seek(TopicPartition(topic=my_topic, partition=2), 32)
for msg in consumer: # 迭代器,等待下一条消息
print msg # 打印消息
其他用法
# 立刻发送所有数据并等待发送完毕
producer.flush()
# 读取下一条消息
next(consumer)
# 手动提交所有已消费的消息
consumer.commit()
# 手动提交指定的消息
consumer.commit([TopicPartition(my_topic, msg.offset)])
生产者 和 消费者 的 Demo
import json
import traceback
from kafka import KafkaProducer, KafkaConsumer
from kafka.errors import kafka_errors
def producer_demo():
# 假设生产的消息为键值对(不是一定要键值对),且序列化方式为json
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
key_serializer=lambda k: json.dumps(k).encode(),
value_serializer=lambda v: json.dumps(v).encode())
# 发送三条消息
for i in range(0, 3):
future = producer.send(
'kafka_demo',
key='count_num', # 同一个key值,会被送至同一个分区
value=str(i),
partition=1 # 向分区1发送消息
)
print("send {}".format(str(i)))
try:
future.get(timeout=10) # 监控是否发送成功
except kafka_errors: # 发送失败抛出kafka_errors
traceback.format_exc()
def consumer_demo():
consumer = KafkaConsumer(
'kafka_demo',
bootstrap_servers=':9092',
group_id='test'
)
for message in consumer:
print(
f"receive, key: {json.loads(message.key.decode())}, "
f"value: {json.loads(message.value.decode())}"
)
四、消费者进阶操作
(1)初始化参数:
列举一些 KafkaConsumer 初始化时的重要参数:
- group_id :高并发量,则需要有多个消费者协作,消费进度,则由group_id统一。例如消费者A与消费者B,在初始化时使用同一个group_id。在进行消费时,一条消息被消费者A消费后,在kafka中会被标记,这条消息不会再被B消费(前提是A消费后正确commit)。
- key_deserializer, value_deserializer :与生产者中的参数一致,自动解析。
- auto_offset_reset :消费者启动的时刻,消息队列中或许已经有堆积的未消费消息,有时候需求是从上一次未消费的位置开始读(则该参数设置为 earliest ),有时候的需求为从当前时刻开始读之后产生的,之前产生的数据不再消费(则该参数设置为 latest )。
- enable_auto_commit, auto_commit_interval_ms :是否自动commit,当前消费者消费完该数据后,需要commit,才可以将消费完的信息传回消息队列的控制中心。enable_auto_commit 设置为 True 后,消费者将自动 commit,并且两次 commit 的时间间隔为 auto_commit_interval_ms 。
(2)手动 commit
def consumer_demo():
consumer = KafkaConsumer(
'kafka_demo',
bootstrap_servers=':9092',
group_id='test',
enable_auto_commit=False
)
for message in consumer:
print(
f"receive, key: {json.loads(message.key.decode())}, "
f"value: {json.loads(message.value.decode())}"
)
consumer.commit()
(3)查看 kafka 堆积剩余量
在线环境中,需要保证消费者的消费速度大于生产者的生产速度,所以需要检测 kafka 中的剩余堆积量是在增加还是减小。可以用如下代码,观测队列消息剩余量:
consumer = KafkaConsumer(topic, **kwargs)
partitions = [TopicPartition(topic, p) for p in consumer.partitions_for_topic(topic)]
print("start to cal offset:")
# total
toff = consumer.end_offsets(partitions)
toff = [(key.partition, toff[key]) for key in toff.keys()]
toff.sort()
print("total offset: {}".format(str(toff)))
# current
coff = [(x.partition, consumer.committed(x)) for x in partitions]
coff.sort()
print("current offset: {}".format(str(coff)))
# cal sum and left
toff_sum = sum([x[1] for x in toff])
cur_sum = sum([x[1] for x in coff if x[1] is not None])
left_sum = toff_sum - cur_sum
print("kafka left: {}".format(left_sum))
版权归原作者 「已注销」 所有, 如有侵权,请联系我们删除。