
1.下载安装所需要的软件
https://www.aliyundrive.com/s/t6fuxPvqdDX 提取码: 3p6t
2.前置安装
在我们真正准备安装之前,需要提前安装好anaconda、jdk1.8,并配置好环境环境变量。
3.安装scala
一直进行Next操作,选择安装路径时,尽量选择安在C盘;




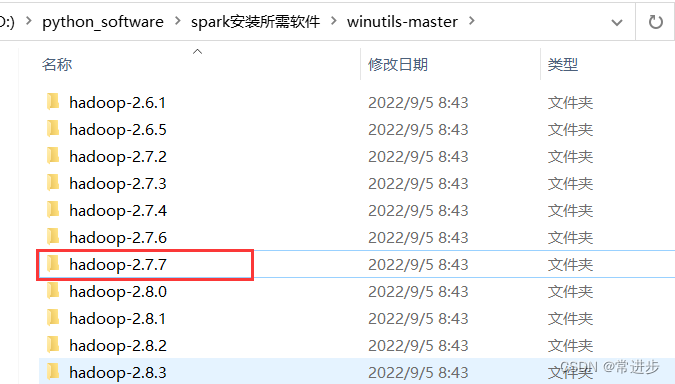
4.安装windows版****hadoop
- 解压winutils-master.zip⽂件,选择hadoop-2.7.7,复制到合适的目录,尽量将所需要的一些文件放到统一目录下。
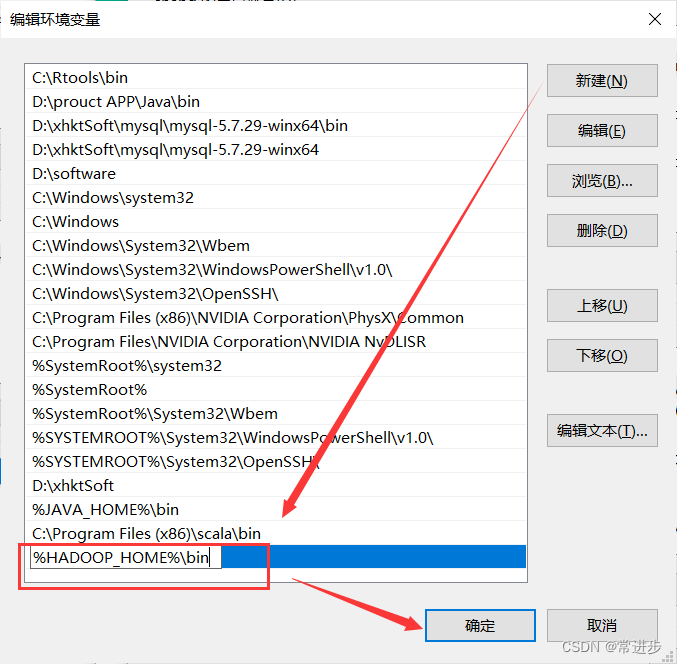
- 为hadoop配置环境变量
系统变量-新建-变量名(HADOOP_HOME)-选择刚刚的hadoop-2.7.7路径


- 编辑Path变量-新建(%HADOOP_HOME%\bin)
5.安装****spark
- 解压spark-2.4.8-bin-hadoop2.7.tgz到一个目录下
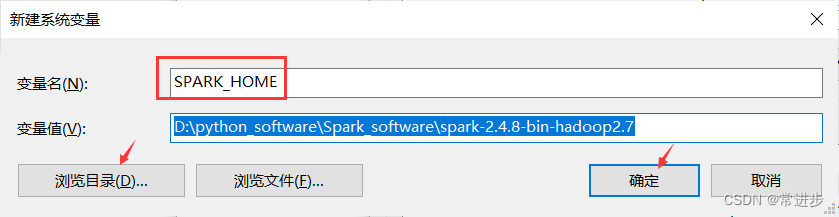
- 新建环境变量-变量名SPARK_HOME(路径为刚解压的目录)
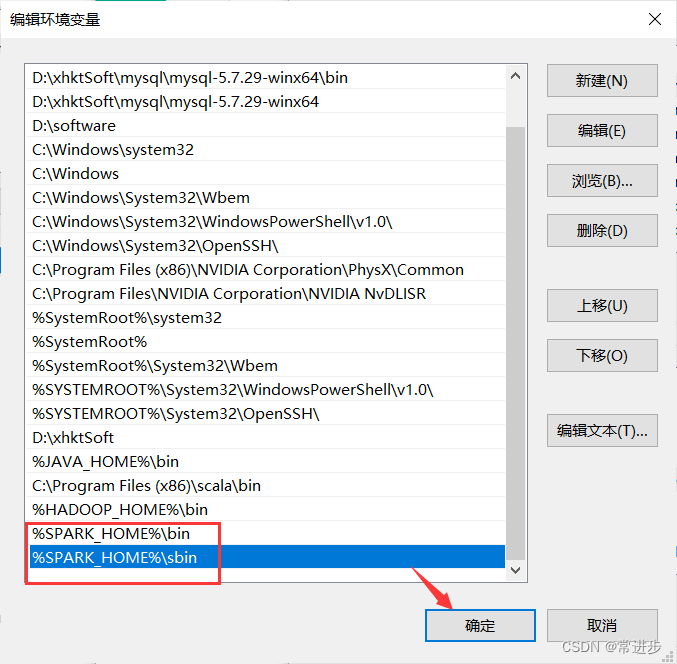
- 编辑PATH环境变量-新建(%HADOOP_HOME%\bin)

- 测试安装
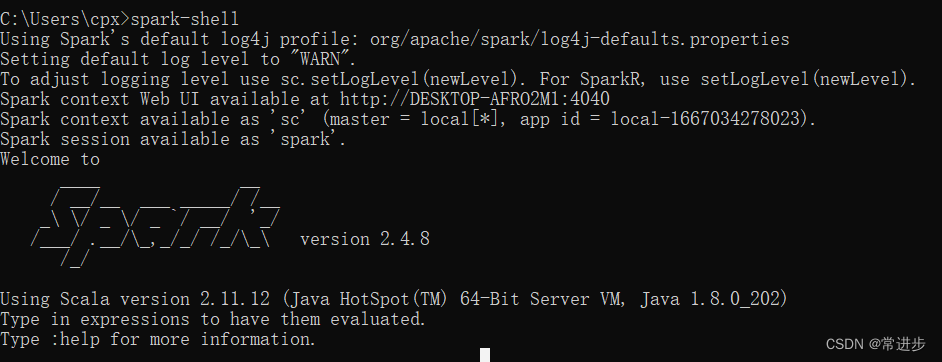
打开命令行,输入spark-shell,出现下图所示,则说明安装成功
6.安装****pyspark
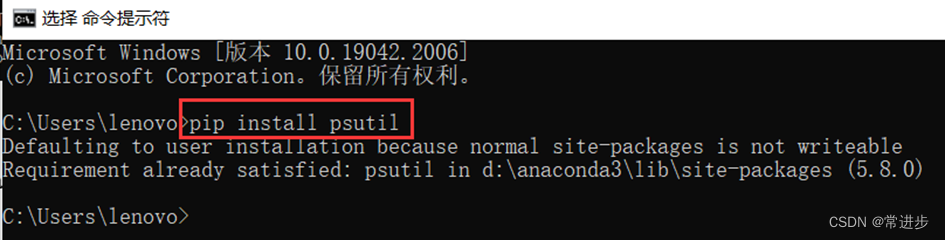
- 安装psutil:pip install pustil
可以在anaconda Prompt或者命令行操作,先忽略不可写问题,下行提示已经安装完成。
- 解压pyspark-3.3.0.tar.gz,⾄⽬标⽬录
打开cmd命令行,进入解压目录,输入python .\setup.py install
注:如果拒绝访问,则以管理员身份进入。

anaconda创建环境,打开anaconda prompt,执行:
conda create -n spark python=3.6.8activate spark验证pyspark


7.使⽤jupyter notebook
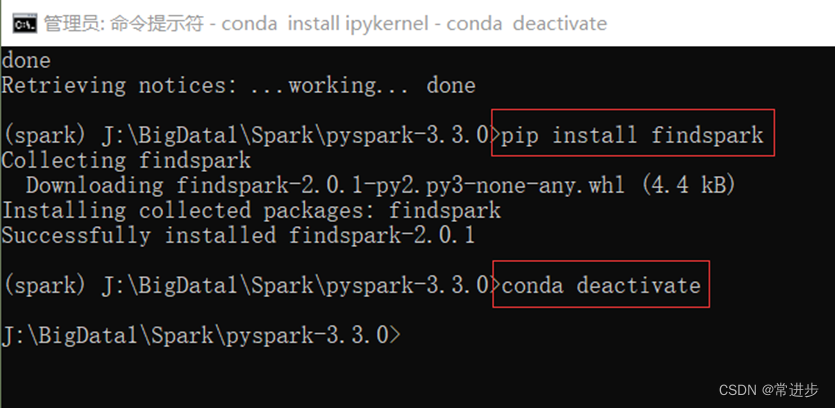
- 安装ipykernel,py4j,findspark,nb_conda_kernels。这步可提前先安装。
直接在命令行安装:
pip install ipykernel
pip install py4j==0.10.9.5
conda install nb_conda_kernels
以及:
conda activate spark
conda install ipykernel
pip install findspark
conda deactivate
- 创建jupyter notebook,选择对应环境
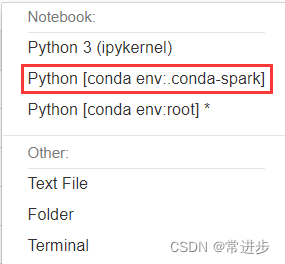
- 测试一下

8.在实验中出现的一系列问题, 我遇到了下面两个,不会改之前我试了重置、重装系统等等,结果其实是很简单的问题。
- 针对于不可写问题,只要它下面已经说明已经安装或安装成功便可忽略;
Defaulting to user instrallation because normal site-packages is not writeable.

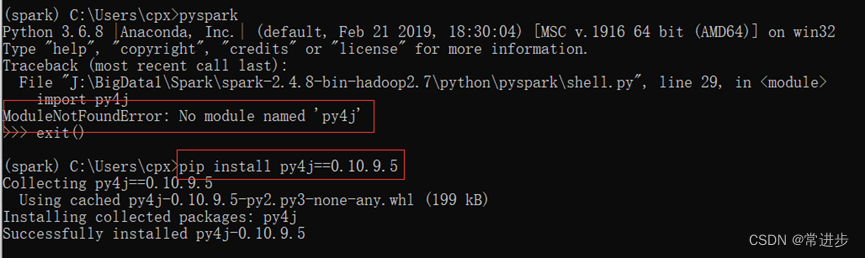
- 对于没有“py4j”库的问题,通过pip install py4j==0.10.9.5 即可添加。换句话说,就是可以选择先安库,然后再进行上面的操作。
版权归原作者 lambda33 所有, 如有侵权,请联系我们删除。