
Hbase入门篇03---Java API使用,HBase高可用配置和架构设计
需求
某某自来水公司,需要存储大量的缴费明细数据。以下截取了缴费明细的一部分内容。
用户id姓名用户地址性别缴费时间表示数(本次)表示数(上次)用量(立方)合计金额查表日期最迟缴费日期4944191登卫红贵州省铜仁市德江县7单元267室男2020-05-10308.1283.1251502020-04-252020-06-09
因为缴费明细的数据记录非常庞大,该公司的信息部门决定使用HBase来存储这些数据。并且,他们希望能够通过Java程序来访问这些数据。
环境搭建
- 引入依赖
<repositories><repository><id>aliyun</id><url>http://maven.aliyun.com/nexus/content/groups/public/</url><releases><enabled>true</enabled></releases><snapshots><enabled>false</enabled><updatePolicy>never</updatePolicy></snapshots></repository></repositories><dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.1.0</version></dependency><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency><groupId>org.testng</groupId><artifactId>testng</artifactId><version>6.14.3</version><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.1</version><configuration><target>1.8</target><source>1.8</source></configuration></plugin></plugins></build>
- 如果在 settings.xml 文件和当前项目的 pom.xml 文件中都指定了同一个 repository 配置,那么 pom.xml 中的配置会覆盖 settings.xml 中的配置。
- 这意味着,如果在 pom.xml 中定义了特定的存储库,Maven 将会使用 pom.xml 中指定的配置,而不是 settings.xml 中的配置。
- 但是,如果在 pom.xml 中没有指定,Maven 会尝试在 settings.xml 中查找相应的配置。
- 如果在settings.xml 中也没有找到,则 Maven 将默认使用 Maven 中央存储库。
- 复制HBase和Hadoop配置文件 - 将以下三个配置文件复制到resource目录中 - hbase-site.xml - 从Linux中下载:sz /export/server/hbase-2.1.0/conf/hbase-site.xml- core-site.xml - 从Linux中下载:sz /export/server/hadoop-2.7.5/etc/hadoop/core-site.xml- log4j.properties
注意:请确认配置文件中的服务器节点hostname/ip地址配置正确
在访问HBase时,需要使用HBase和Hadoop的相关配置信息来与集群进行通信。通常情况下,这些配置文件位于集群中的节点上,Java应用程序需要知道这些配置信息才能连接到HBase集群。因此,将这些配置文件复制到Java项目中可以方便Java应用程序获取配置信息,从而连接到HBase集群。如果不将这些配置文件复制到Java项目中,则需要手动配置Java应用程序中的相关配置信息。
sz 命令是一种用于从远程服务器下载文件的命令。在该命令中,/export/server/hbase-2.1.0/conf/hbase-site.xml 是要下载的文件的路径。该命令会将文件下载到当前目录中。通常,sz 命令需要在客户端终端中运行,以从远程服务器下载文件。
- 创建HBase连接及Admin管理对象
importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.hbase.HBaseConfiguration;importorg.apache.hadoop.hbase.client.Admin;importorg.apache.hadoop.hbase.client.Connection;importorg.apache.hadoop.hbase.client.ConnectionFactory;importorg.testng.annotations.AfterTest;importorg.testng.annotations.BeforeTest;importjava.io.IOException;publicclassTableAmdinTest{privateConfiguration configuration;privateConnection connection;privateAdmin admin;@BeforeTestpublicvoidbeforeTest()throwsIOException{
configuration =HBaseConfiguration.create();//可以不引入hbase-site.xml配置文件,手动指定zk地址,客户端从zk拉取,获取master和regionServer的地址
configuration.set("hbase.zookeeper.quorum","node1");
connection =ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();}@AfterTestpublicvoidafterTest()throwsIOException{
admin.close();
connection.close();}}
表的CRUD
创建表:
创建一个名为WATER_BILL的表,包含一个列蔟C1。
- 调用tableExists判断表是否存在
- 在HBase中,要去创建表,需要构建TableDescriptor(表描述器)、ColumnFamilyDescriptor(列蔟描述器),这两个对象不是直接new出来,是通过builder来创建的
- 将列蔟描述器添加到表描述器中
- 使用admin.createTable创建表
/**
* 创建一个名为WATER_BILL的表,包含一个列蔟C1
*/@TestpublicvoidcreateTableTest()throwsIOException{// 表名String TABLE_NAME ="WATER_BILL";// 列蔟名String COLUMN_FAMILY ="C1";// 1. 判断表是否存在if(admin.tableExists(TableName.valueOf(TABLE_NAME))){return;}// 2. 构建表描述构建器TableDescriptorBuilder tableDescriptorBuilder =TableDescriptorBuilder.newBuilder(TableName.valueOf(TABLE_NAME));// 3. 构建列蔟描述构建器ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder =ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(COLUMN_FAMILY));// 4. 构建列蔟描述ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build();// 5. 构建表描述// 添加列蔟
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);TableDescriptor tableDescriptor = tableDescriptorBuilder.build();// 6. 创建表
admin.createTable(tableDescriptor);}
注意:
- 在HBase中所有的数据都是以byte[]形式来存储的,所以需要将Java的数据类型进行转换
- 经常会使用到一个工具类:Bytes(hbase包下的Bytes工具类)
- 这个工具类可以将字符串、long、double类型转换成byte[]数组
- 也可以将byte[]数组转换为指定类型
删除表:
@TestpublicvoiddropTable()throwsIOException{// 表名TableName tableName =TableName.valueOf("WATER_BILL");// 1. 判断表是否存在if(admin.tableExists(tableName)){// 2. 禁用表
admin.disableTable(tableName);// 3. 删除表
admin.deleteTable(tableName);}}
坑
此处列举HBase Java客户端使用过程中可能会遇到的一些坑:
命令执行卡住不动 ?
HBase Java客户端在调用相关方法时,会自动进行重试和超时机制,如果一直无法建立连接或响应,则可能会导致方法一直卡住。
为了避免这种情况,可以设置一个较短的超时时间或者关闭自动重试机制。可以使用以下方法实现:
- 设置超时时间: - 可以通过调用HBase Configuration对象的set方法设置“
hbase.client.operation.timeout”参数的值,以毫秒为单位。- 例如,设置为1秒钟:
Configuration conf =HBaseConfiguration.create();
conf.setInt("hbase.client.operation.timeout",1000);
- 关闭自动重试: - 可以通过调用HBase Configuration对象的set方法设置“
hbase.client.retries.number”参数的值为0,表示关闭自动重试机制。- 例如:
Configuration conf =HBaseConfiguration.create();
conf.setInt("hbase.client.retries.number",0);
但是需要注意,关闭自动重试机制可能会导致某些操作失败。因此,需要根据实际情况选择适当的配置。
上面的配置只是为了让客户端出现连接异常时,能够快速失败,而不是不断的重试和超时等待,导致我们无法及时感知错误发生。
当异常抛出来之后,下面就是根据异常分类处理了,下面我列举我遇到的一些异常情况:
RegionServer只在本地127.0.0.1监听16020端口导致外网连接被拒
Caused by:java.net.ConnectException:Calltonode2/xxx:16020 failed on connection exception:org.apache.hbase.thirdparty.io.netty.channel.ConnectTimeoutException: connection timed out: node2/123.60.166.193:16020
at org.apache.hadoop.hbase.ipc.IPCUtil.wrapException(IPCUtil.java:165)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient.onCallFinished(AbstractRpcClient.java:390)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient.access$100(AbstractRpcClient.java:95)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient$3.run(AbstractRpcClient.java:410)
at org.apache.hadoop.hbase.ipc.AbstractRpcClient$3.run(AbstractRpcClient.java:406)
解决方法,在hbase-site.xml配置文件中配置RegionServer在0.0.0.0地址上监听16020端口:
<property><name>hbase.regionserver.ipc.address</name><value>0.0.0.0</value></property>
RegionServer所在主机的/etc/hosts文件存在额外的回环地址映射信息,导致客户端拿到无法识别的主机名
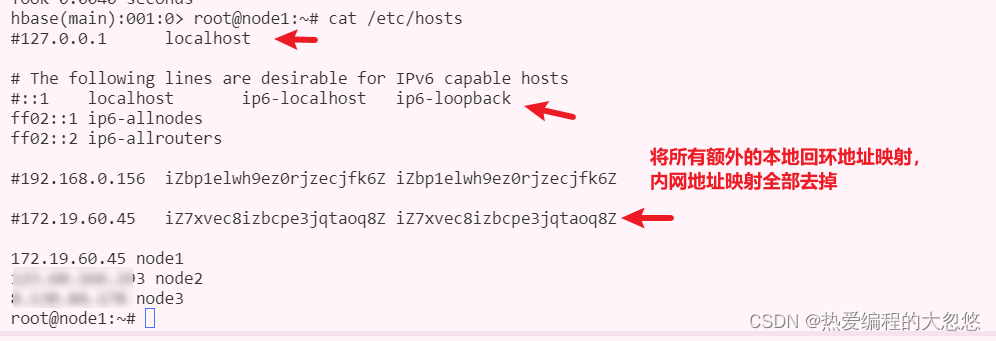
数据的CRUD
插入姓名列数据 - 在表中插入一个行,该行只包含一个列。
ROWKEY姓名(列名:NAME)4944191登卫红首先要获取一个Table对象,这个对象是要和HRegionServer节点连接,所以将来HRegionServer负载是比较高的
HBase的connection对象是一个重量级的对象,将来编写代码(Spark、Flink)的时候,避免频繁创建,使用一个对象就OK,因为它是线程安全的
Connection creation is a heavy-weight operation. Connection implementations are thread-safe
- Table这个对象是一个轻量级的,用完Table需要close,因为它是非线程安全的
Lightweight. Get as needed and just close when done.
- 需要构建Put对象,然后往Put对象中添加列蔟、列、值
- 当执行一些繁琐重复的操作用列标记:- ctrl + shift + ←/→,可以按照单词选择,非常高效
@TestpublicvoidaddTest()throwsIOException{// 1.使用Hbase连接获取HtableTableName waterBillTableName =TableName.valueOf("WATER_BILL");Table waterBillTable = connection.getTable(waterBillTableName);// 2.构建ROWKEY、列蔟名、列名String rowkey ="4944191";String cfName ="C1";String colName ="NAME";// 3.构建Put对象(对应put命令)Put put =newPut(Bytes.toBytes(rowkey));// 4.添加姓名列
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colName),Bytes.toBytes("登卫红"));// 5.使用Htable表对象执行put操作
waterBillTable.put(put);// 6. 关闭表
waterBillTable.close();}
- 插入其他列
列名说明值ADDRESS用户地址贵州省铜仁市德江县7单元267室SEX性别男PAY_DATE缴费时间2020-05-10NUM_CURRENT表示数(本次)308.1NUM_PREVIOUS表示数(上次)283.1NUM_USAGE用量(立方)25TOTAL_MONEY合计金额150RECORD_DATE查表日期2020-04-25LATEST_DATE最迟缴费日期2020-06-09
@TestpublicvoidaddTest1()throwsIOException{// 1.使用Hbase连接获取HtableTableName waterBillTableName =TableName.valueOf("WATER_BILL");Table waterBillTable = connection.getTable(waterBillTableName);// 2.构建ROWKEY、列蔟名、列名String rowkey ="4944191";String cfName ="C1";String colName ="NAME";String colADDRESS ="ADDRESS";String colSEX ="SEX";String colPAY_DATE ="PAY_DATE";String colNUM_CURRENT ="NUM_CURRENT";String colNUM_PREVIOUS ="NUM_PREVIOUS";String colNUM_USAGE ="NUM_USAGE";String colTOTAL_MONEY ="TOTAL_MONEY";String colRECORD_DATE ="RECORD_DATE";String colLATEST_DATE ="LATEST_DATE";// 3.构建Put对象(对应put命令)Put put =newPut(Bytes.toBytes(rowkey));// 4.添加姓名列
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colName),Bytes.toBytes("登卫红"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colADDRESS),Bytes.toBytes("贵州省铜仁市德江县7单元267室"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colSEX),Bytes.toBytes("男"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colPAY_DATE),Bytes.toBytes("2020-05-10"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colNUM_CURRENT),Bytes.toBytes("308.1"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colNUM_PREVIOUS),Bytes.toBytes("283.1"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colNUM_USAGE),Bytes.toBytes("25"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colTOTAL_MONEY),Bytes.toBytes("150"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colRECORD_DATE),Bytes.toBytes("2020-04-25"));
put.addColumn(Bytes.toBytes(cfName),Bytes.toBytes(colLATEST_DATE),Bytes.toBytes("2020-06-09"));// 5.使用Htable表对象执行put操作
waterBillTable.put(put);// 6. 关闭表
waterBillTable.close();}
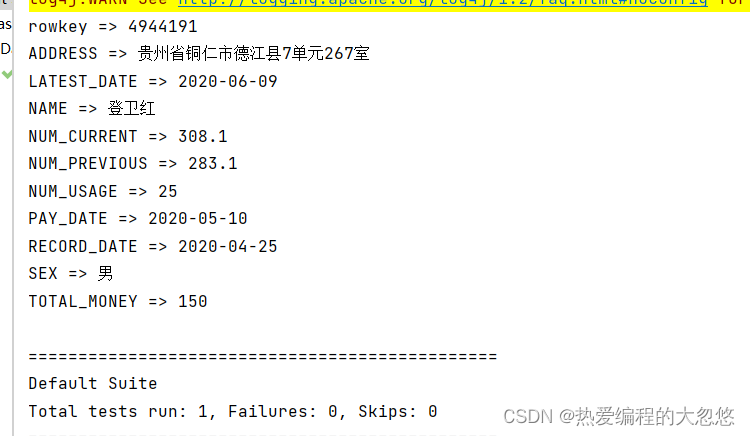
- 查看一条数据
@TestpublicvoidgetOneTest()throwsIOException{// 1. 获取HTableTableName waterBillTableName =TableName.valueOf("WATER_BILL");Table waterBilltable = connection.getTable(waterBillTableName);// 2. 使用rowkey构建Get对象Get get =newGet(Bytes.toBytes("4944191"));// 3. 执行get请求Result result = waterBilltable.get(get);// 4. 获取所有单元格List<Cell> cellList = result.listCells();// 打印rowkeySystem.out.println("rowkey => "+Bytes.toString(result.getRow()));// 5. 迭代单元格列表for(Cell cell : cellList){// 打印列蔟名System.out.print(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()));System.out.println(" => "+Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));}// 6. 关闭表
waterBilltable.close();}
- 删除一条数据
// 删除rowkey为4944191的整条数据@TestpublicvoiddeleteOneTest()throwsIOException{// 1. 获取HTable对象Table waterBillTable = connection.getTable(TableName.valueOf("WATER_BILL"));// 2. 根据rowkey构建delete对象Delete delete =newDelete(Bytes.toBytes("4944191"));// 3. 执行delete请求
waterBillTable.delete(delete);// 4. 关闭表
waterBillTable.close();}
数据的导入导出
Import JOB
在HBase中,有一个Import的MapReduce作业,可以专门用来将数据文件导入到HBase中。
- 用法:
hbase org.apache.hadoop.hbase.mapreduce.Import 表名 HDFS数据文件路径
导入数据演示:
- 将文件上传到hdfs中
hadoop fs -mkdir -p /water_bill/output_ept_10W
hadoop fs -put part-m-00000_10w /water_bill/output_ept_10W
- 启动YARN集群
start-yarn.sh
- 使用以下方式来进行数据导入
hbase org.apache.hadoop.hbase.mapreduce.Import WATER_BILL /water_bill/output_ept_10W
导出数据演示:
hbase org.apache.hadoop.hbase.mapreduce.Export WATER_BILL /water_bill/output_ept_10W_export
数据查询
需求: 查询2020年6月份所有用户的用水量
- 需求分析 - 在Java API中,我们也是使用scan + filter来实现过滤查询。2020年6月份其实就是从2020年6月1日到2020年6月30日的所有抄表数据。
注意:
- ResultScanner需要手动关闭,这个操作是比较消耗资源的,用完就应该关掉,不能一直都开着
- 扫描使用的是Scan对象
- SingleColumnValueFilter——过滤单列值的过滤器
- FilterList——是可以用来组合多个过滤器
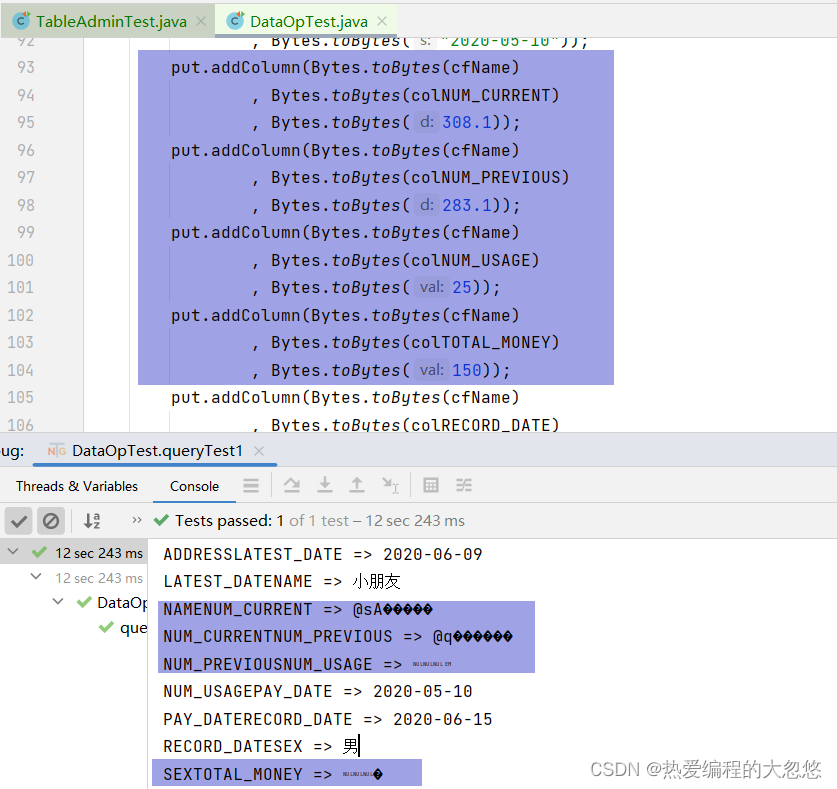
// 查询2020年6月份所有用户的用水量数据@TestpublicvoidqueryTest1()throwsIOException{// 1. 获取表Table waterBillTable = connection.getTable(TableName.valueOf("WATER_BILL"));// 2. 构建scan请求对象Scan scan =newScan();// 3. 构建两个过滤器// 3.1 构建日期范围过滤器(注意此处请使用RECORD_DATE——抄表日期比较SingleColumnValueFilter startDateFilter =newSingleColumnValueFilter(Bytes.toBytes("C1"),Bytes.toBytes("RECORD_DATE"),CompareOperator.GREATER_OR_EQUAL
,Bytes.toBytes("2020-06-01"));SingleColumnValueFilter endDateFilter =newSingleColumnValueFilter(Bytes.toBytes("C1"),Bytes.toBytes("RECORD_DATE"),CompareOperator.LESS_OR_EQUAL
,Bytes.toBytes("2020-06-30"));// 3.2 构建过滤器列表FilterList filterList =newFilterList(FilterList.Operator.MUST_PASS_ALL
, startDateFilter
, endDateFilter);
scan.setFilter(filterList);// 4. 执行scan扫描请求ResultScanner resultScan = waterBillTable.getScanner(scan);// 5. 迭代打印resultfor(Result result : resultScan){System.out.println("rowkey -> "+Bytes.toString(result.getRow()));System.out.println("------");List<Cell> cellList = result.listCells();// 6. 迭代单元格列表for(Cell cell : cellList){// 打印列蔟名System.out.print(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()));System.out.println(" => "+Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));}System.out.println("------");}
resultScan.close();// 7. 关闭表
waterBillTable.close();}
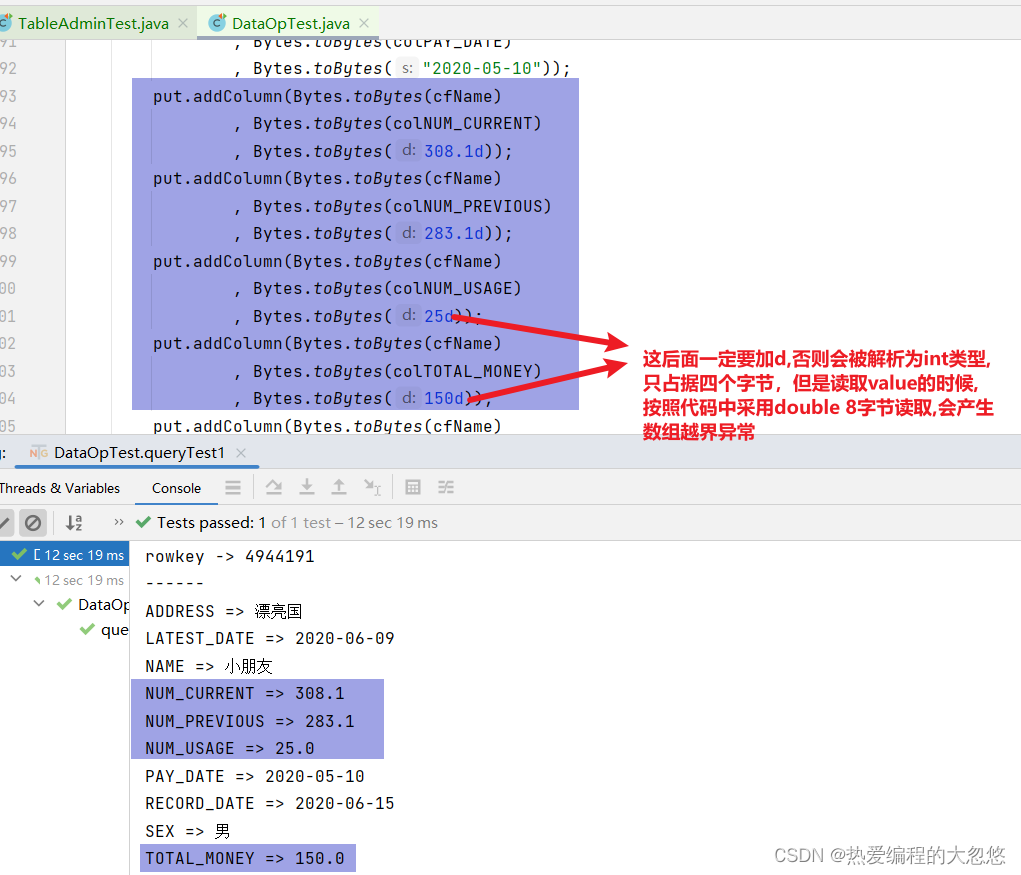
解决中文乱码问题:
- 前面我们的代码,在打印所有的列时,都是使用字符串打印的,Hbase中如果存储的是int、double,那么有可能就会乱码了。
要解决的话,我们可以根据列来判断,使用哪种方式转换字节码。如下:
- NUM_CURRENT
- NUM_PREVIOUS
- NUM_USAGE
- TOTAL_MONEY
这4列使用double类型展示,其他的使用string类型展示
if(colName.equals("NUM_CURRENT")|| colName.equals("NUM_PREVIOUS")|| colName.equals("NUM_USAGE")|| colName.equals("TOTAL_MONEY")){System.out.println(" => "+Bytes.toDouble(cell.getValueArray(), cell.getValueOffset()));}else{System.out.println(" => "+Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));}
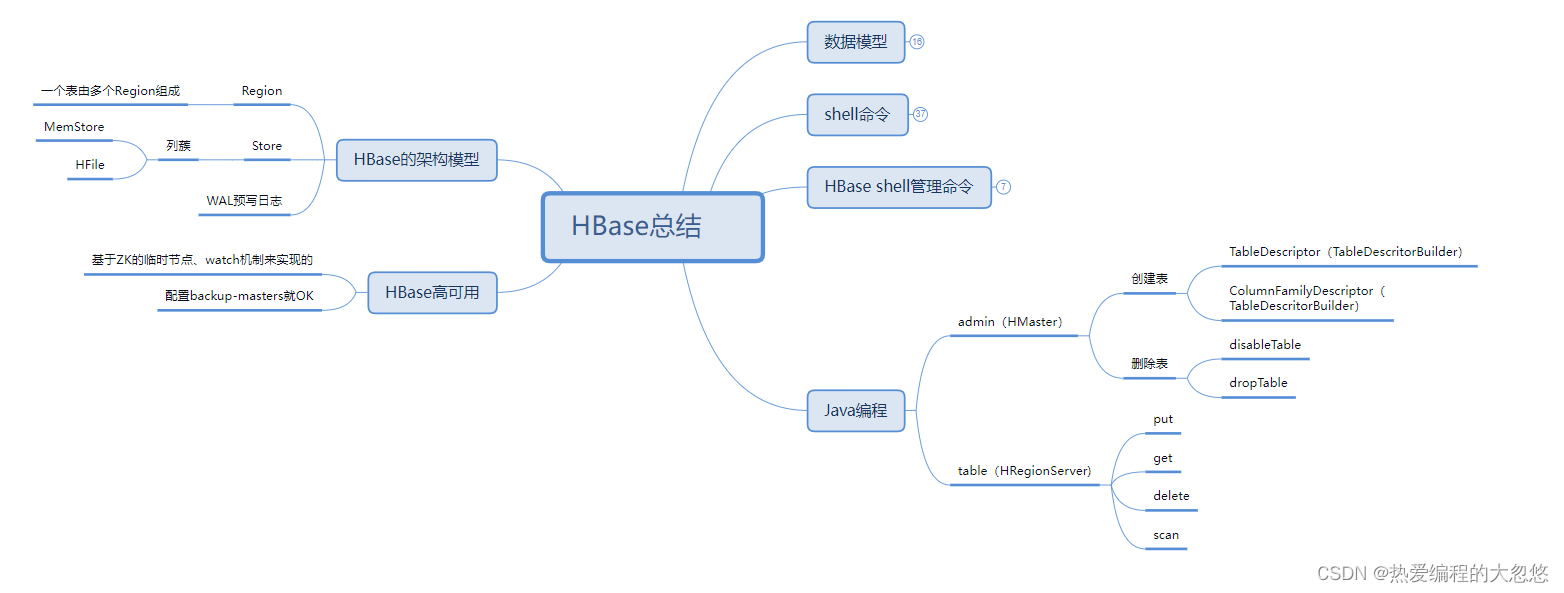
HBase高可用
考虑关于HBase集群的一个问题,在当前的HBase集群中,只有一个Master,一旦Master出现故障,将会导致HBase不再可用。所以,在实际的生产环境中,是非常有必要搭建一个高可用的HBase集群的。
HBase高可用简介
- HBase的高可用配置其实就是HMaster的高可用。要搭建HBase的高可用,只需要再选择一个节点作为HMaster,在HBase的conf目录下创建文件backup-masters,然后再backup-masters添加备份Master的记录。一条记录代表一个backup master,可以在文件配置多个记录。
搭建HBase高可用
- 在hbase的conf文件夹中创建 backup-masters 文件
cd /export/server/hbase-2.1.0/conf
touch backup-masters
- 将node2和node3添加到该文件中
vim backup-masters
node2
node3
- 将backup-masters文件分发到所有的服务器节点中
scp backup-masters node2:$PWDscp backup-masters node3:$PWD
- 重新启动hbase
stop-hbase.sh
start-hbase.sh
- 查看webui,检查Backup Masters中是否有node2,node3
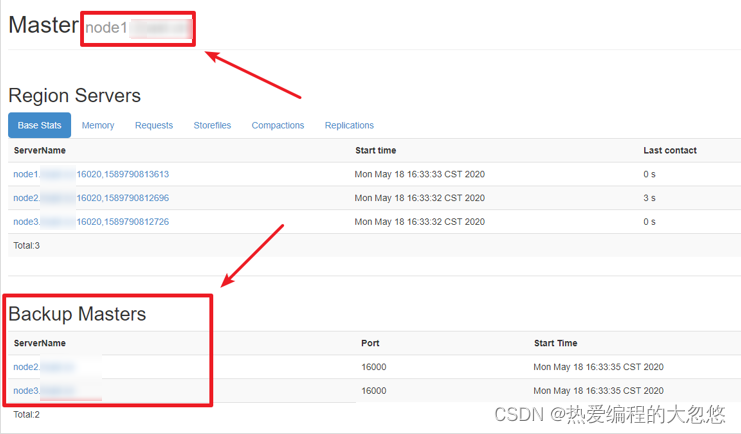
- 尝试杀掉node1节点上的master
kill -9 HMaster进程id
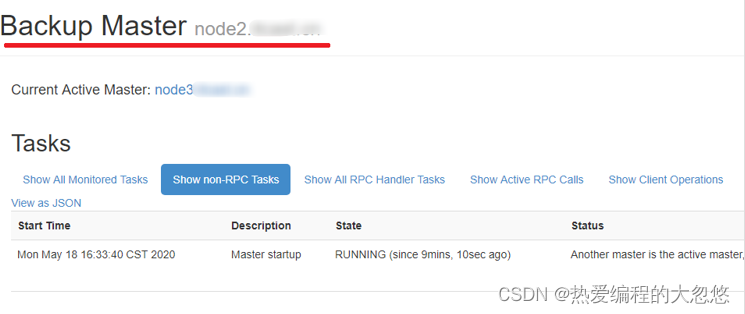
注意:
- HBase的HA也是通过ZK来实现的(临时节点、watch机制)
- 只需要添加一个backup-masters文件,往里面添加要称为Backup master的节点,HBase启动的时候,会自动启动多个HMaster
- HBase配置了HA后,对Java代码没有影响。因为Java代码是通过从ZK中来获取Master的地址的
HBase架构
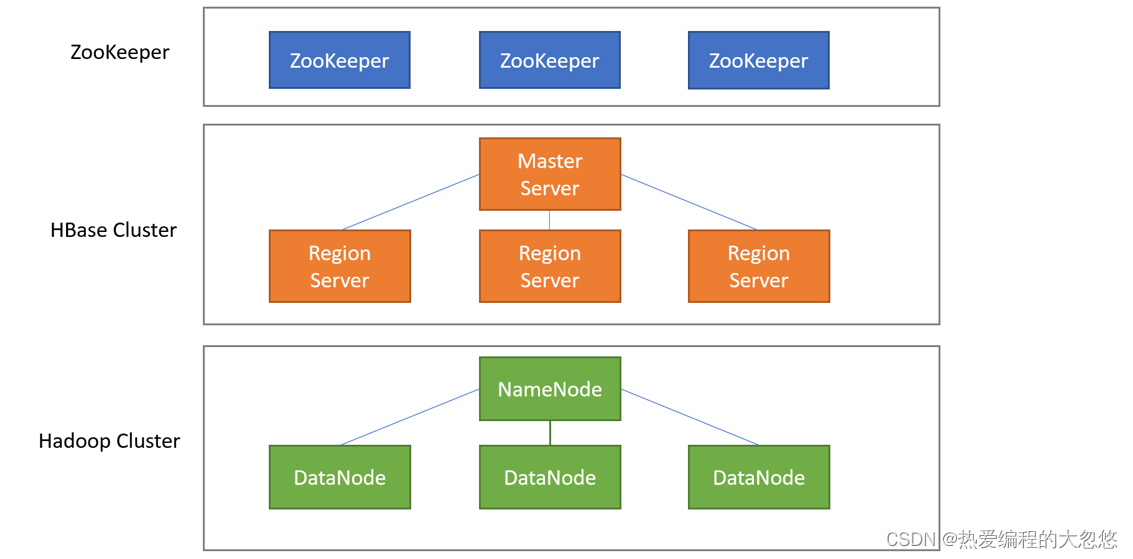
- client:客户端,写的Java程序、hbase shell都是客户端(Flink、MapReduce、Spark)
- Master Server - 监控RegionServer- 处理RegionServer故障转移- 处理元数据的变更- 处理region的分配或移除- 在空闲时间进行数据的负载均衡- 通过Zookeeper发布自己的位置给客户端
HMaster:主要是负责表的管理操作(创建表、删除表、Region分配),不负责具体的数据操作
- Region Server - 处理分配给它的Region- 负责存储HBase的实际数据- 刷新缓存到HDFS- 维护HLog- 执行压缩- 负责处理Region分片
- RegionServer中包含了大量丰富的组件,如下: - Write-Ahead logs- HFile(StoreFile)- Store- MemStore- Region
HRegionServer:负责数据的管理、数据的操作(增删改查)、负责接收客户端的请求来操作数据
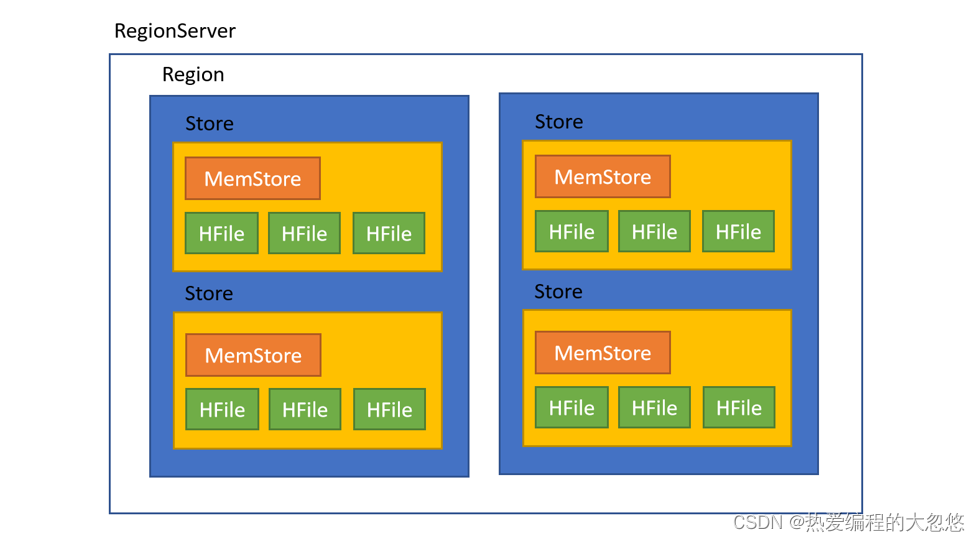
- Region - 在HBASE中,表被划分为很多「Region」,并由Region Server提供服务

一个表由多个Region组成,每个Region保存一定的rowkey范围的数据,Region中的数据一定是有序的,是按照rowkey的字典序来排列的
- Store - 存储的是表中每一个列蔟的数据- Region按列族垂直划分为「Store」,存储在HDFS在文件中
- MemStore - MemStore与缓存内存类似- 当往HBase中写入数据时,首先是写入到MemStore- 每个列族将有一个MemStore- 当MemStore存储快满的时候,整个数据将写入到HDFS中的HFile中
所有的数据都是先写入到MemStore中,可以让读写操作更快,当MemStore快满的时候,需要有一个线程定期的将数据Flush到磁盘中
- StoreFile - 每当任何数据被写入HBASE时,首先要写入MemStore- 当MemStore快满时,整个排序的key-value数据将被写入HDFS中的一个新的HFile中- 写入HFile的操作是连续的,速度非常快- 物理上存储的是HFile
HFile是在HDFS上保存的数据,是HBase独有的一种数据格式(丰富的结构、索引、DataBlock、BloomFilter布隆过滤器…)
- WAL - WAL全称为Write Ahead Log,它最大的作用就是 故障恢复- WAL是HBase中提供的一种高并发、持久化的日志保存与回放机制- 每个业务数据的写入操作(PUT/DELETE/INCR),都会保存在WAL中- 一旦服务器崩溃,通过回放WAL,就可以实现恢复崩溃之前的数据- 物理上存储是Hadoop的Sequence File
WAL预写日志,当客户端连接RegionServer写数据的时候,会先写WAL预写日志,put/delete/incr命令写入到WAL,有点类似于之前Redis中的AOF,当某一个RegionServer出现故障时,还可以通过WAL来恢复数据,恢复的就是MemStore的数据。
常见Bug记录
Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster- 找到$HADOOP_HOME/etc/mapred-site.xml,增加以下配置- 将配置文件分发到各个节点- 重新启动YARN集群
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
Caused by: java.net.ConnectException: Call to node2/192.168.88.101:16020 failed on connection exception: org.apache.hbase.thirdparty.io.netty.channel.ConnectTimeoutException: connection timed out: node2/192.168.88.101:16020- 无法连接到HBase,请检查HBase的Master是否正常启动Starting namenodes on [localhost] ERROR: Attempting to launch hdfs namenode as root ,ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch.- 解决办法: 是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh
在顶部空白处添加内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
Starting resourcemanager ERROR: Attempting to launch yarn resourcemanager as root ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch. Starting nodemanagers ERROR: Attempting to launch yarn nodemanager as root ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting launch
vim sbin/start-yarn.sh
vim sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat- 将 hadoop.dll 放到c:/windows/system32文件夹中,重启IDEA,重新运行程序
本部分思维导图
版权归原作者 Binary Oracle 所有, 如有侵权,请联系我们删除。