
目录
4.1使用下面的命令,解压Spark安装包到用户根目录:
[zkpk@master ~]$ cd /home/zkpk/tgz/spark/
[zkpk@master spark]$ tar -xzvf spark-2.1.1-bin-hadoop2.7.tgz -C /home/zkpk/
[zkpk@master spark]$ cd
[zkpk@master ~]$ cd spark-2.1.1-bin-hadoop2.7/
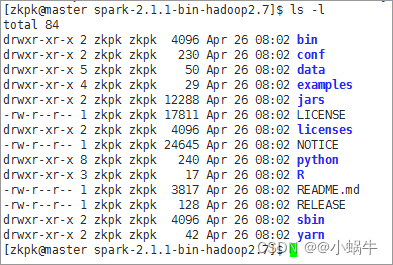
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ ls-l
执行ls -l命令会看到下面的图片所示内容,这些内容是Spark包含的文件:
4.2配置Hadoop环境变量
4.2.1在Yarn上运行Spark需要配置HADOOP_CONF_DIR、YARN_CONF_DIR和HDFS_CONF_DIR环境变量
4.2.1.1命令:
[zkpk@master ~]$ cd
[zkpk@master ~]$ gedit ~/.bash_profile
4.2.1.2在文件末尾添加如下内容;保存、退出
#SPARK ON YARN
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
4.2.1.3重新编译文件,使环境变量生效
[zkpk@master ~]$ source ~/.bash_profile
4.3验证Spark安装
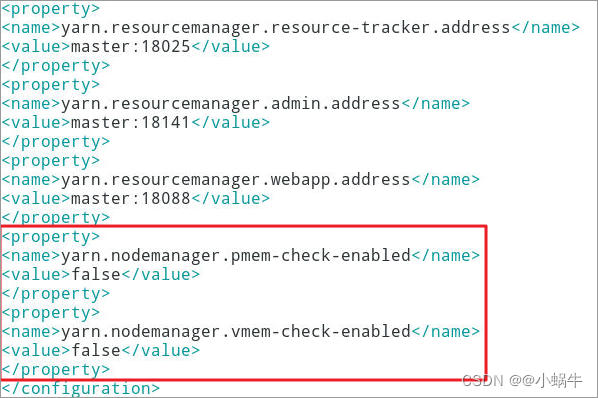
4.3.1修改${HADOOP_HOME}/etc/Hadoop/yarn-site.xml;
说明:在master和slave01、slave02节点都要如此修改此文件
4.3.2添加两个property
[zkpk@master ~]$ vim ~/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4.4重启hadoop集群(使配置生效)
[zkpk@master ~]$ stop-all.sh
[zkpk@master ~]$ start-all.sh
4.5进入Spark安装主目录
[zkpk@master ~]$ cd ~/spark-2.1.1-bin-hadoop2.7
4.5.1执行下面的命令(注意这是1行代码):
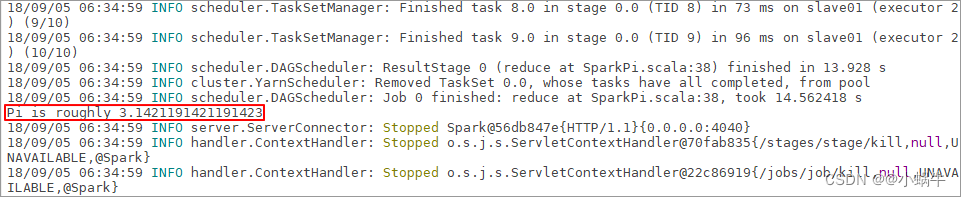
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --num-executors 3 --driver-memory 1g --executor-memory 1g --executor-cores 1 examples/jars/spark-examples*.jar 10
4.5.2执行命令后会出现如下界面:
4.5.3Web UI验证
4.5.3.1进入spark-shell交互终端,命令如下:
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ ./bin/spark-shell
4.5.3.2打开浏览器,输入下面地址,查看运行界面(地址:http://master:4040/)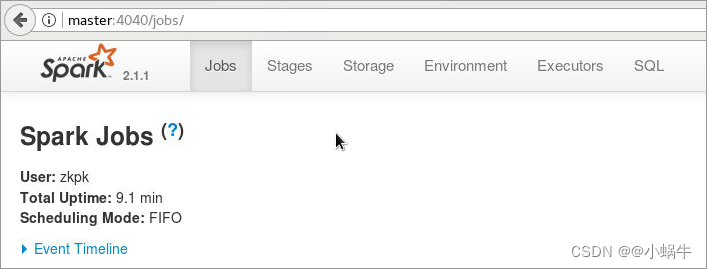
4.5.3.3退出交互终端,按ctrl+d组合键
scala> :quit
4.6安装部署Spark-SQL
4.6.1将hadoop安装目录下的hdfs-site.xml文件复制到spark安装目录下的conf目录下
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ cd
[zkpk@master ~]$ cd hadoop-2.7.3/etc/hadoop/
[zkpk@master hadoop]$ cp hdfs-site.xml /home/zkpk/spark-2.1.1-bin-hadoop2.7/conf
4.6.2将Hive安装目录conf子目录下的hive-site.xml文件,拷贝到spark的配置子目录
[zkpk@master hadoop]$ cd
[zkpk@master ~]$ cd apache-hive-2.1.1-bin/conf/
[zkpk@master conf]$ cp hive-site.xml /home/zkpk/spark-2.1.1-bin-hadoop2.7/conf/
4.6.3修改spark配置目录中的hive-site.xml文件
[zkpk@master conf]$ cd
[zkpk@master ~]$ cd spark-2.1.1-bin-hadoop2.7/conf/
[zkpk@master conf]$ vim hive-site.xml
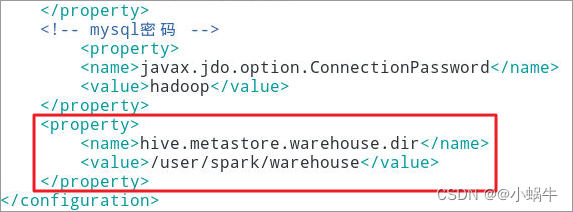
4.6.3.1添加如下属性
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/spark/warehouse</value>
</property>
4.6.4将mysql连接的驱动包拷贝到spark目录的jars子目录
[zkpk@master conf]$ cd
[zkpk@master ~]$ cd apache-hive-2.1.1-bin/lib/
[zkpk@master lib]$ cp mysql-connector-java-5.1.28.jar /home/zkpk/spark-2.1.1-bin-hadoop2.7/jars/
4.6.5重启Hadoop集群并验证spark-sql;下图,进入spark shell客户端,说明spark sql配置成功
[zkpk@master lib]$ cd
[zkpk@master ~]$ stop-all.sh
[zkpk@master ~]$ start-all.sh
[zkpk@master ~]$ cd ~/spark-2.1.1-bin-hadoop2.7
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ ./bin/spark-sql --master yarn

4.6.6按ctrl+d组合键,退出spark shell
4.6.7若hadoop集群不再使用,请关闭集群
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ cd
[zkpk@master ~]$ stop-all.sh
本文转载自: https://blog.csdn.net/Manonll/article/details/125299700
版权归原作者 @小蜗牛 所有, 如有侵权,请联系我们删除。
版权归原作者 @小蜗牛 所有, 如有侵权,请联系我们删除。