
相关概念介绍
数据相关概念
什么是数据?
对人的行为及习惯做的一种记录
数据有什么?
可以帮助我们更好的了解事与物之间的规律, 更好的提高人们的生活体验和生活环境.
数据能做什么?
我们能够对数据进行数据分析, 从海量的数据中提取出有效的价值信息, 实现数据的商业化, 价值化,能够给企业决策者或者运营人员提供分析型报告和数据支持
大数据相关概念
什么是大数据?
从狭义上理解就是分析海量的数据, 提取出有价值的信息, 而从广义上理解就是用数据为生活赋能, 改善人类的生活体验和生活质量.
大数据的特点?
大数据的特点主要就五个字: 大多值快信.
数据体量大, 种类繁多, 价值密度低, 速度快, 数据的可信赖度高.
大数据解决了什么问题?
存储, 计算, 传输
大数据的体系介绍
存储: HDFS, HBase
计算: MapReduce, Hive, Spark, Flink
传输: Sqoop, Flume, Kafka...
下面是关于大数据体系的详细概念图

Apache Hadoop介绍
Hadoop之父: 道格 卡丁(Doug Cutting)
吉祥物: 大象
Hadoop的介绍:
在狭义上指的是HDFS, MapReduce, Yarn等框架, 而在广义上指的是Hadoop生态圈, 包括但不限于周边所有技术, 例如: Spark, Flink, Sqoop...
Hadoop是由HDFS, MapRedure, Yarn三部分组成:
HDFS: hadoop distributed file system, Hadoop的分布式文件系统.
MapReduce: 分布式计算框架
Yarn: 分布式任务接收和资源调度框架
分布式和集群介绍
分布式: 多台机器做不同的事情, 然后组成一个整体.
集群: 多台机器做相同的事情.
扩展: 多台机器既可以组成中心化模式(主从模式), 也可以组成去中心化模式(主备模式)
Hadoop的架构图
Hadoop1.X = HDFS + MapReduce
Hadoop2.X, 3.X = HDFS + MapReduce + Yarn
Hadoop集群高可用模式图解

相关概念介绍
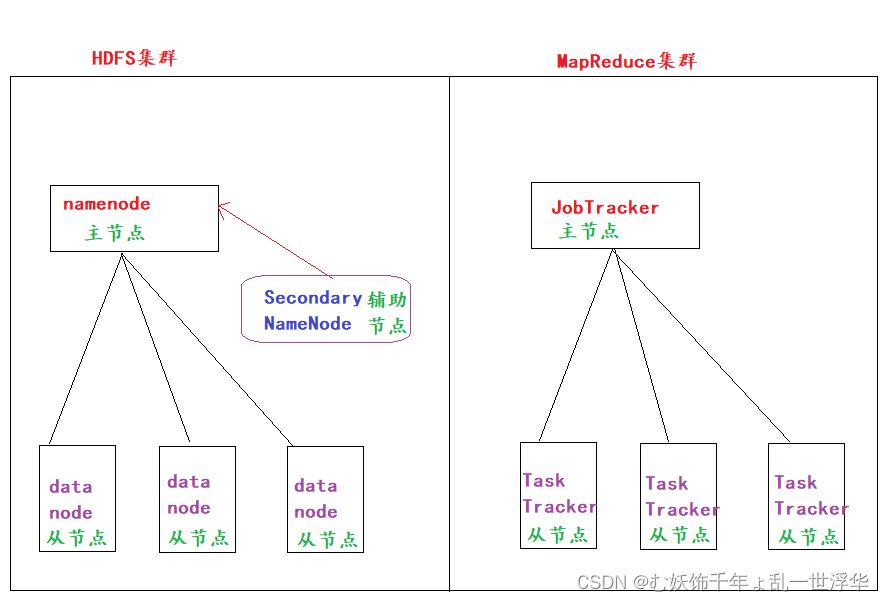
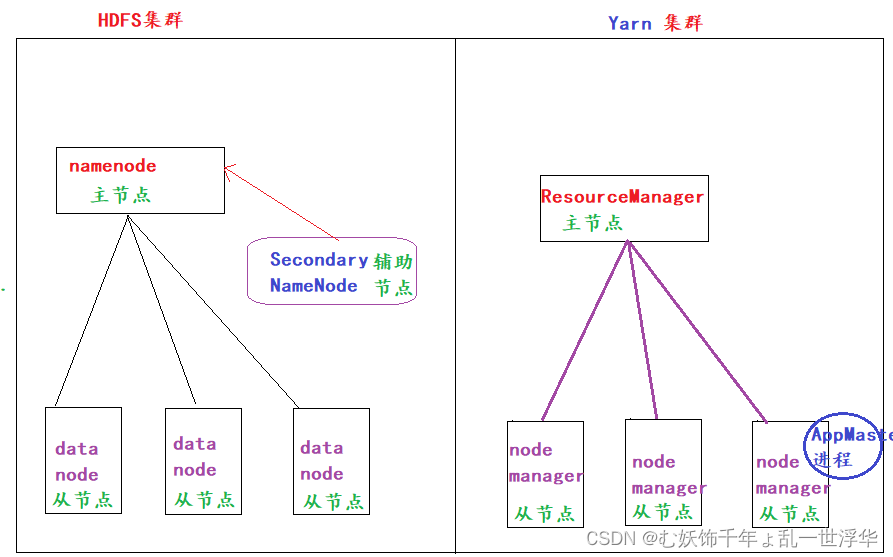
HDFS: 分布式文件存储系统
namenode: 主节点
管理整个HDFS集群,维护和管理元数据
元数据: 描述数据的数据被称为元数据
SecondaryNameNode: 辅助节点
辅助namenode管理元数据的
datenode: 从节点
维护和管理源文件, 负责数据的读写操作, 定时向namenode报活
MapReduce集群:
JobTracker: 主节点
负责任务的接收, 调度, 监控, 负责资源的调度和分配
TaskTracker: 从节点
负责接收并执行JobTracker分配过来的计算任务
扩展: JobTracker的任务过于繁重,容易宕机,会存在单点故障的问题,一般都不再使用该集群
Yarn集群:
ResourceManager: 主节点
负责任务的接收, 负责资源的调度和分配
AppMaster进程: 代码级别
一个计算任务 = 一个Application Master进程
由该AppMaster进程来监控和管理该计算任务,并负责向ResourceManager申请资源
nodemanager: 从节点
负责接收并执行ResourceManager分配过来的计算任务
扩展: 此时已经没有MapReduce集群的概念了,而是代码级别的程序,即: MR计算任务, 我们只需要用代码编写MR计算任务,然后交由Yarn调度执行即可
HDFS的特点
HDFS文件系统可存储超大文件,时效性稍差
HDFS具有硬件故障检测和自动快速恢复功能
HDFS为数据存储提供很强的扩展能力
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改
HDFS可在普通廉价的机器上运行
HDFS的架构图
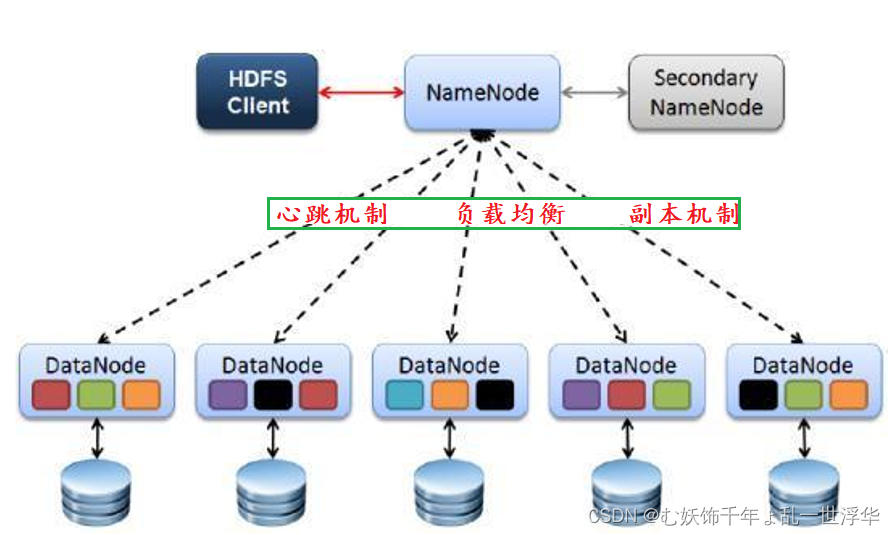
心跳机制:
1.datanode会定时3秒向namenode发送心跳包,告知namenode我还活着
2.如果超过一定时间630秒,namenode没有收到datanode的心跳包,就会认为它宕机了,此时就会将该datanode的块信息交由给其他活跃的datanode来存储
3.所有的datanode会定时6小时,向namenode汇报一次自己完整的块信息,让namenode校验更新
负载均衡:
namenode会保证所有的datanode的资源使用率尽量保持一致
副本机制:
可以提高容错率,默认的副本数是3
如果当前副本总数>默认的副本数,namenode会自动删除某个副本
如果当前副本总数<默认的副本数,namenode会自动增加该副本
如果当前活跃的机器总数<默认的副本数,就会强制进入到安全模式,在安全模式下只能读不能写
如果想要了解更多配置信息,也可以直接去Hadoop官方文档那里去查看
https://hadoop.apache.org/docs/r3.3.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
版权归原作者 む妖饰千年ょ乱一世浮华 所有, 如有侵权,请联系我们删除。