
写于2022.09.17,2022.10.12增加性能测试对比,2022.11.6增加单例模式方法
机器学习或深度学习算法模型在进行服务端部署时,通常通过flask包装为服务接口,对外进行调用,但存在一定一个问题是:每次调用模型进行预测时,都会加载一次模型,这个过程是比较占资源的,换言之,很耗时。
如何在flask刚启动时就加载一次模型,后续在调用接口时就不再调用模型了,直接进行预测。
方法一:模型加载为全局变量
from flask import Flask, request
import pickle
app = Flask(__name__)# 在这里进行模型的加载,如导入pkl
model = pickle.load(open('model.pkl','rb'))@app.route('/predict', methods=['GET'])defpredict():'''这里获取接口的请求参数,下面是举例'''
features = request.args.get("feature")# 调用模型进行预测
result = model.predict(features)return result
if __name__ =="__main__":
app.run(port=80,debug =True)
以一个实际的中文分词接口部署为例:
需要安装LAC,LAC是百度出品的一个中文分词工具,很好用。
pip install LAC
from flask import Flask, request
from LAC import LAC
app = Flask(__name__)# 装载LAC模型
lac = LAC(mode='lac')@app.route('/predict', methods=['GET'])defpredict():
text = request.args.get("text")# 调用模型进行预测
result = lac.run(text)returnstr(result)if __name__ =="__main__":
app.run(port=8080,debug=True)
访问接口:
http://127.0.0.1:8080/predict?text=我爱北京天安门
每次访问时,都无需再加载模型,模型相当于一个全局变量,每次接口请求时,直接调用即可。非常快!
方法二:使用单例模式
首先创建一个文件用于加载模型:
load.py
from LAC import LAC
classMODEL:def__init__(self):
self.model = LAC(mode='lac')
lac = MODEL()
在main.py中进行引用
from flask import Flask, request
from load import lac
app = Flask(__name__)@app.route('/predict', methods=['GET'])defpredict():
text = request.args.get("text")# 调用模型进行预测
result = lac.model.run(text)returnstr(result)if __name__ =="__main__":
app.run(port=8080)
其它单例模式实现,请参考:
https://blog.csdn.net/qq_41248532/article/details/123246471?spm=1001.2014.3001.5506
两种方法的区别有待研究。
附性能测试:
方式一:参照本文方法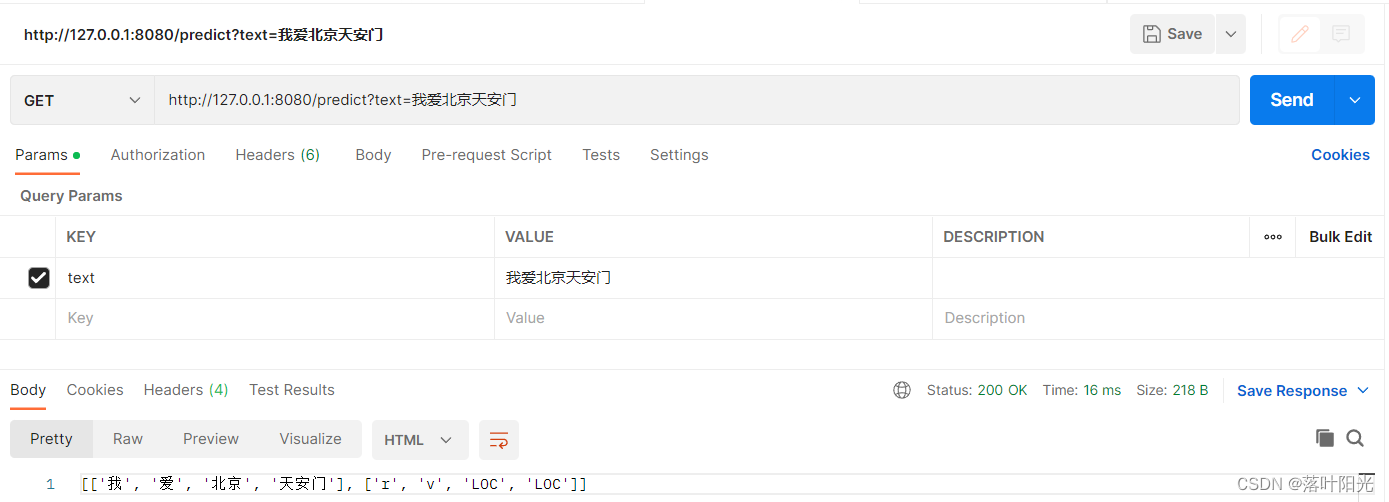
单次调用响应时间:16ms
方式二:每次调用接口时,都加载模型
from flask import Flask, request
from LAC import LAC
app = Flask(__name__)
@app.route('/predict', methods=['GET'])
def predict():
text = request.args.get("text")
# 装载LAC模型
lac = LAC(mode='lac')
# 调用模型进行预测
result = lac.run(text)
return str(result)
if __name__ == "__main__":
app.run(port=8080,debug=True)
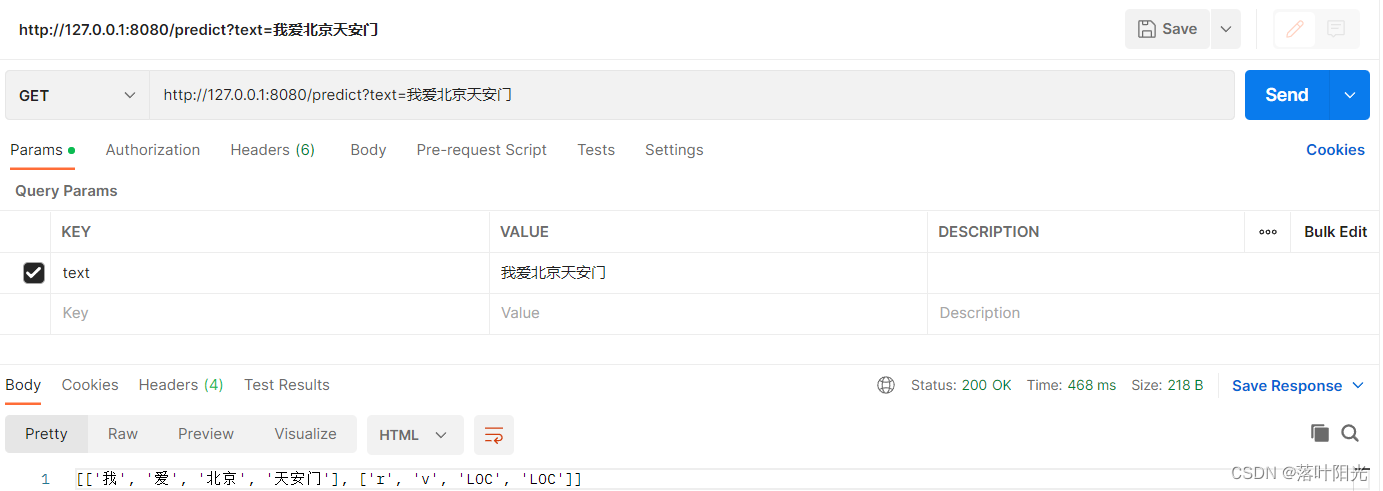
单次调用响应时间:468ms
可以发现响应时间优化非常明显!
本文转载自: https://blog.csdn.net/xiangxiang613/article/details/126910206
版权归原作者 落叶阳光 所有, 如有侵权,请联系我们删除。
版权归原作者 落叶阳光 所有, 如有侵权,请联系我们删除。