
启动集群:
注:第一次启动集群需要对整个集群进行格式化:
[root@node01 ~]# cd /opt/software/
[root@node01 software]# hdfs namenode -format
格式化后正式启动集群:在node01中输入start-dfs.sh脚本启动集群,在启动过程中出现are you sure you want to continue connecting (yes/no)?则输入yes回车后继续启动。
[root@node01 ~]# cd /opt/software/
[root@node01 software]# start-dfs.sh
Starting namenodes on [node01]
node01: namenode running as process 1517. Stop it first.
node03: datanode running as process 2445. Stop it first.
node02: datanode running as process 2435. Stop it first.
node01: datanode running as process 1624. Stop it first.
Starting secondary namenodes [0.0.0.0]
0.0.0.0: secondarynamenode running as process 1819. Stop it first.
在node01中启动了namenode节点,node01、node02、node03中启动datanode节点,并在node01中启动secondary namenode
启动后使用jps命令查看每个节点中的进程,在node01中有DataNode、NameNode、SecondaryNameNode三个与HDFS相关的进程;node02中有DataNode一个与HDFS相关的进程;node03中有DataNode一个与HDFS相关的进程;
[root@node01 software]# jps
2434 Jps
1624 DataNode
1819 SecondaryNameNode
1517 NameNode
[root@node02 ~]# jps
2435 DataNode
2614 Jps
[root@node03 ~]# jps
2626 Jps
2445 DataNode
只有当三个节点中的这些进程同时存在,则说明HDFS完全分布式搭建完成。
接下来去网页端验证,HDFS的默认web界面的端口号为50070,浏览器访问node01:50070查看集群运行情况可看到如下页面:
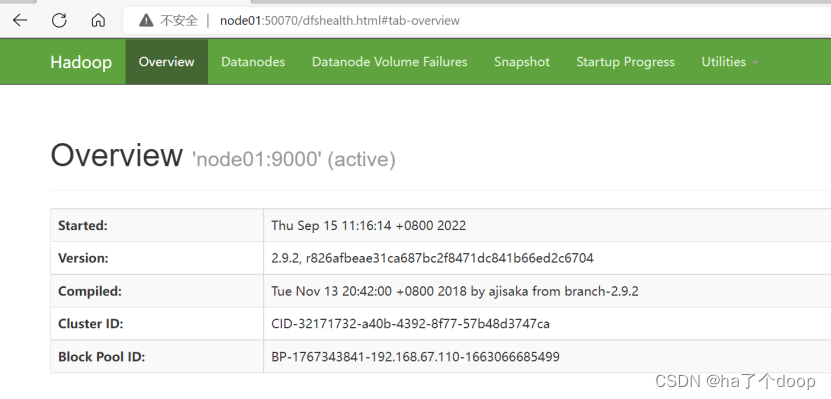
其中,’node01:9000’为HDFS的地址;
node01为主机名称;
9000为运行的端口号;
(active)为namenode节点运行的状态;
到此集群搭建完毕
测试文件上传到web端:
新建testData文件夹,在testData中再新建hdfs文件夹,使用rz命令选择要上传的文件开始上传
[root@node01 software]# mkdir testData
[root@node01 software]# cd testData/
[root@node01 testData]# mkdir hdfs
[root@node01 testData]# cd hdfs/
[root@node01 hdfs]# rz
使用ll命令查看上传结果
[root@node01 hdfs]# ll
总用量 357860
-rw-r--r-- 1 root root 366447449 9月 13 15:19 hadoop-2.9.2.tar.gz
在hdfs中创建一个测试的路径:
[root@node01 hdfs]# hdfs dfs -mkdir /test
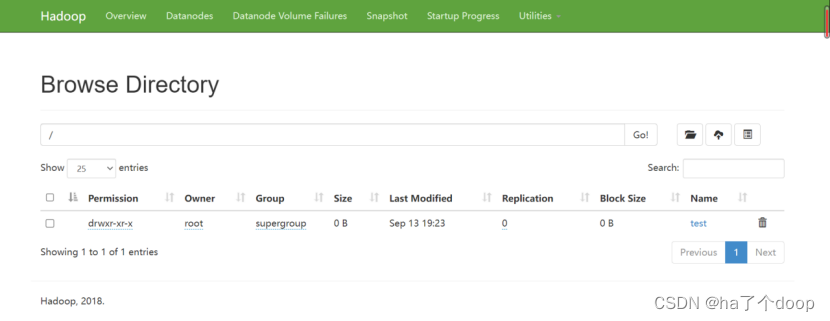
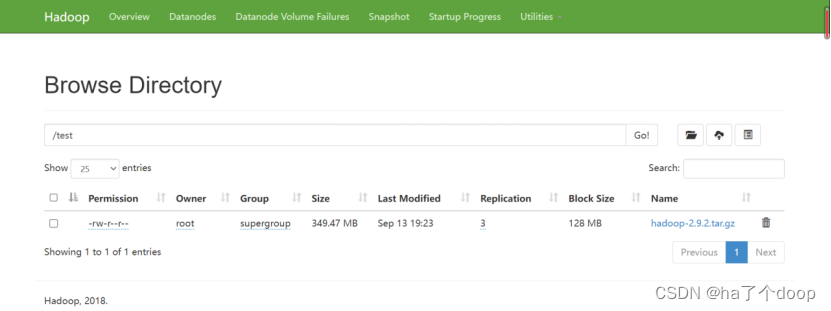
将上面上传的压缩包上传到此路径中:
[root@node01 hdfs]# hdfs dfs -put hadoop-2.9.2.tar.gz /test
上传后刷新web页面,可以看到文件已经成功上传到test文件中
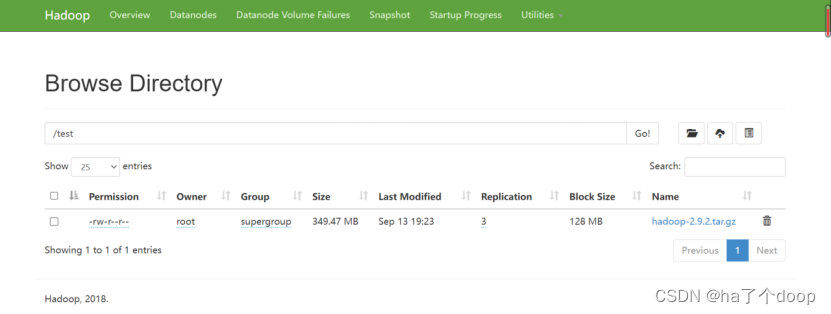
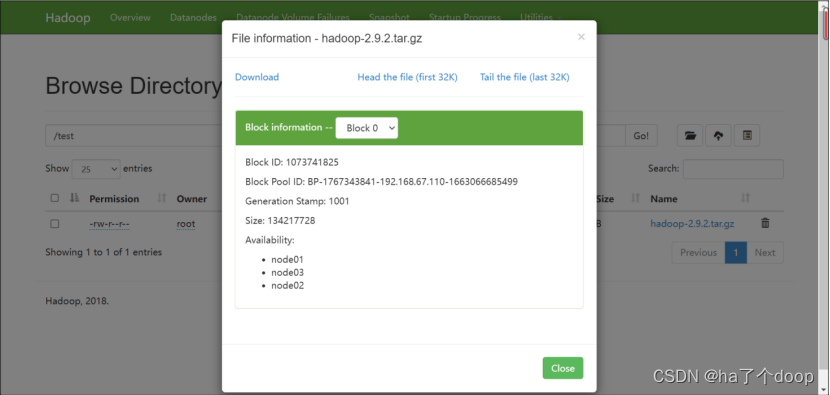
点击文件名,可看到其具体信息:
在我们进行HDFS完全分布式集群搭建与配置的过程中,会遇到很多问题,以下便是相关常见问题解决的总结。
一、防火墙问题
在集群搭建之前,一定要关闭防火墙。
关于关闭防火墙以及防止火墙开机自启动的代码:
关闭防火墙代码:
systemctl stop firewalld
防止火墙开机自启动代码:
systemctl disable firewalld.service
二、有的时候我们HDFS出了问题,无法解决,可以通过重新格式化NameNode来解决。
首先要停止集群的HDFS和Yarn进程,然后删除hadoop目录下的logs以及data文件。

代码为:
rm -rf data
rm -rf logs
不仅要在bigdata102上删除,同时在bigdata103和bigdata104上也要删除。
然后我们再进行namenode的格式化,要在bigdata102上面进行。
代码为:
hdfs namenode -format
再进行HDFS和Yarn的启动。就可以解决这个问题了。
三、Namenode无法与DataNode通信
在这个问题上,我们首先要注意的是在格式化namenode的过程中遇到的小细节。
首先一定要先关闭集群再进行操作,然后我们要删除缓存路经下的缓存文件,最后重新格式化。
四、在虚拟机内linux系统中的浏览器不能访问
首先要检查自己的防火墙有没有关闭。
代码为:
service iptables status
如果没有关闭防火墙,那么我们就要去关闭防火墙。
代码为:
systemctl stop firewalld
我们再重新启动linux系统后检查防火墙状态,之后查看 vim /etc/hosts文件,是否修改成功或相对应,最后验证浏览器的访问。
五、在启动集群的时侯报错找不到 JAVA_HOME
首先呢我们去查看jdk是否配置成功。
代码为:
cd /opt/module/hadoop-3.1.3/etc/Hadoop
然后重新配置jdk,等号后面的是修改为自己jdk安装目录。
代码为:
export JAVA_HOME=/opt/module/jdk1.8.0_151/
如果在配置所有完成后仍然启动报错,那么我们的解决方法为首先就是要停止集群。
代码为:
stop-dfs.sh
然后把core-site.xml中自己配置的文件夹删除。
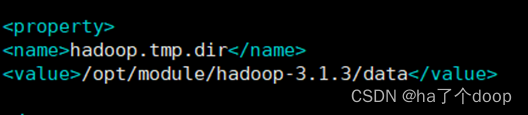
最后进行重新格式化namenode。
六、利用搭建的hadoop集群计算wordcount时出现内存问题。
运行的过程中,会出现这样的一个问题。
mapreduce.Job: Task Id : attempt_1652009045286_0001_m_000000_2,
Status : FAILED
[2022-05-08 19:32:48.836]Container
[pid=20882,containerID=container_1652009045286_0001_01_000004]
is running 375372288B beyond the 'VIRTUAL' memory limit.
Current usage: 49.8 MB of 1 GB physical memory used;
2.4 GB of 2.1 GB virtual memory used. Killing container.
这个原因就是机器上运行的container尝试用更多的内存,但是被Nodemanager给中断了,所以需要配置所需内存大小。
解决办法就是在/opt/module/hadoop-3.1.4/etc/hadoop/下的mapred-site.xml中添加如下配置:(其中的数字大小可以根据自己电脑的内存大小情况更改)
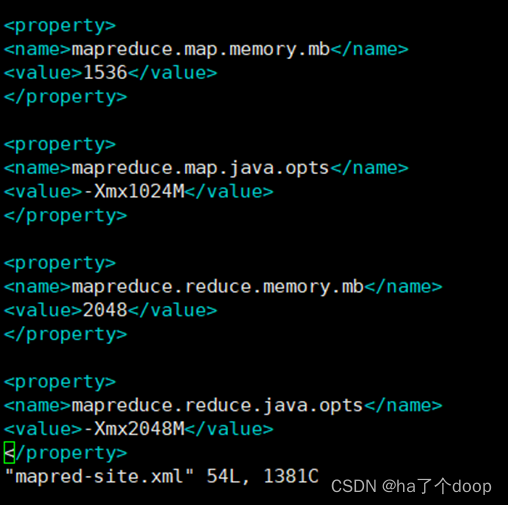
最后重启yarn进程就可以解决内存问题。
七、在执行集群wordcount程序的时候,发现报错,那么我们需要更改 yarn-site.xml 文件,增加一项配置即可。
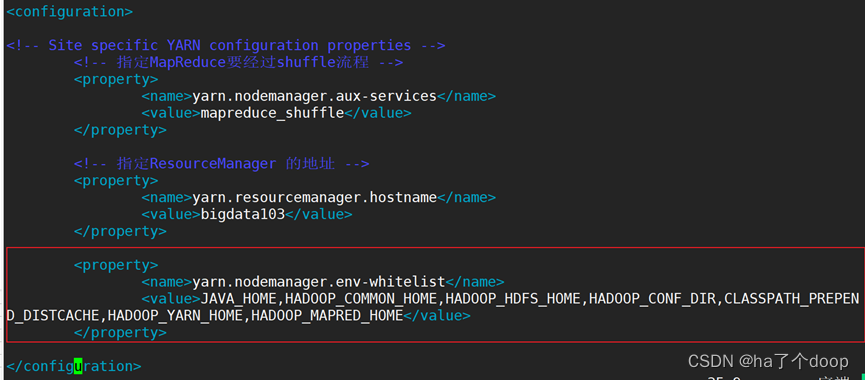
之后进行分发给bigdata103和bigdata104。
代码为:
xsync yarn-site.xml
然后在bigdata103上面停止yarn。
代码为:
stop-yarn.sh
在bigdata103上面重新启动yarn。
代码为:
start-yarn.sh
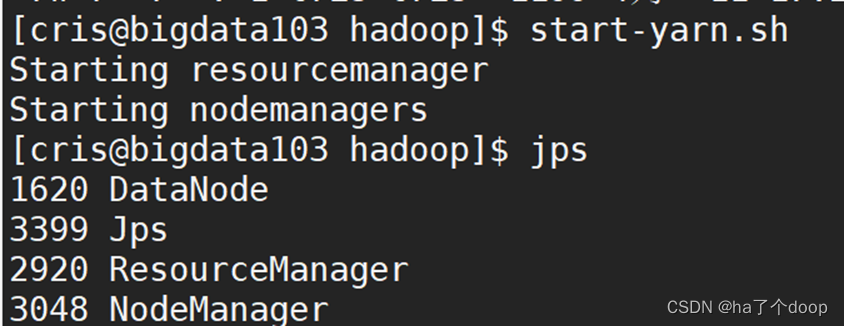
我们在bigdata102上面再去执行wordcount程序。

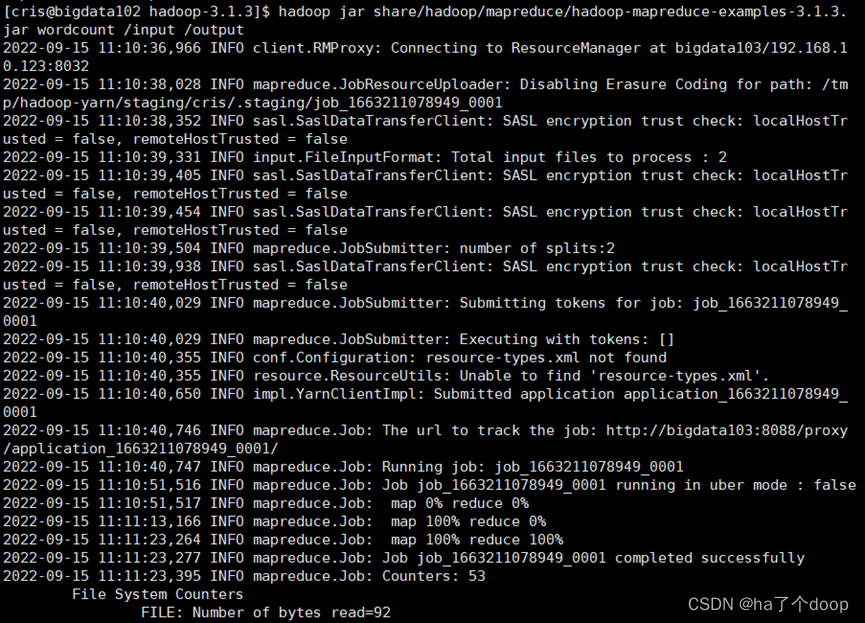
在执行完成后,我们就在浏览器可以发现新生成了文件夹。

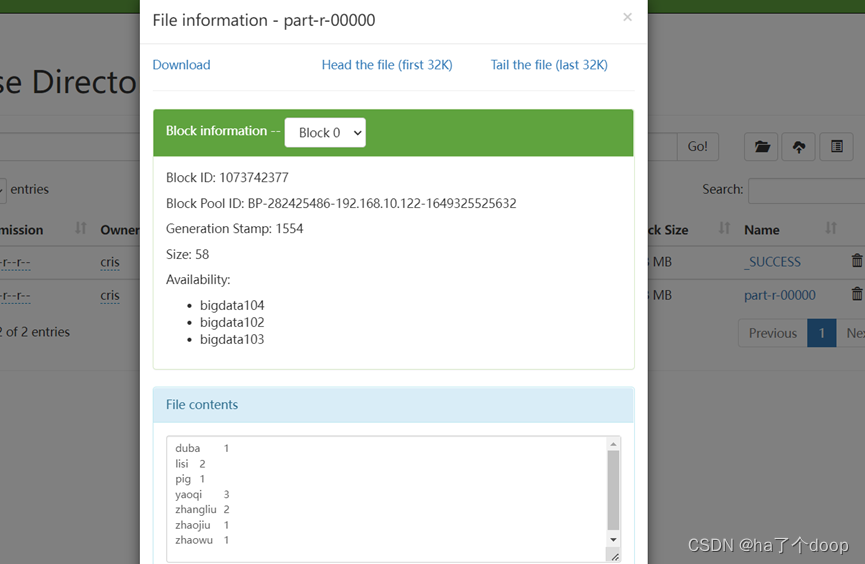
并且下面就是我们执行出来的结果。
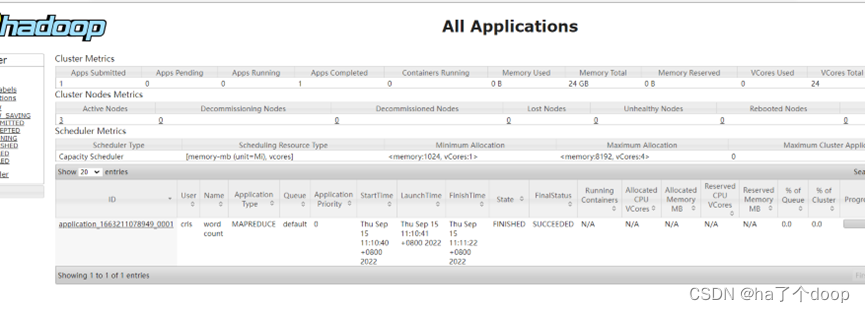
 我们还可以在yarn中看见执行的程序。
我们还可以在yarn中看见执行的程序。
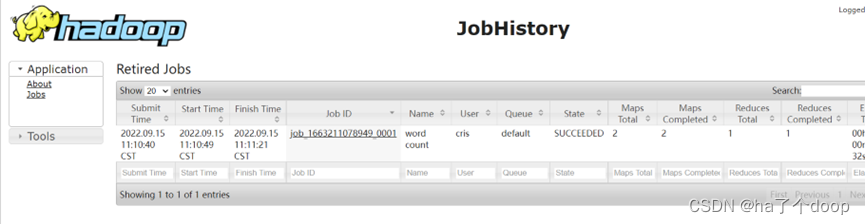
并且在历史服务器上也有执行任务的记录。
所以我们在执行wordcount就不会出现问题了!!
八、除了这些在配置上出现问题之外,还有一些我们个人遇到的问题,尤其在编写代码的时候,有时候会因为一个标点符号,大小写字母,一个空格都会让程序报错,从而无法进行下一步,所以我们在配置的过程中,一定要看好,千万不要打错,按照步骤一步一步进行,一般都不会出现错误,就像吃糖葫芦,吃完一个才能吃下一个,不能贪多,也不能缺少。
在这个过程中,我们要及时进行拍摄快照,如图所示,这样就算有一个步骤写错,也可以转回上一步。
有了拍摄快照,我们也可以更加大胆的去尝试,去运行更多的案例,从而提升专业知识。
友友们!!虽然写代码会遇到很多困难,但一定不要放弃哦!!不会的多去问问老师,我们的专业课老师就是牛!加油!让我们在更高的山峰上相见!
版权归原作者 ha了个doop 所有, 如有侵权,请联系我们删除。