
1.Spark编程统计各地区租房人数
实验目标:
(1) 掌握在IntelliJ IDEA 中操作spark程序开发
(2) 打包程序提交集群运行
实验说明:
现有一份某省份各地区租房信息文件 house.txt,文件中共有8个数据字段,字段说明如下表所示:
字段名称
说明
租房ID
租房编号
标题
发布的租房标题
链接
网址,可查看租房信息
地区
房子所在地区
地点
房子所在城市地点
地铁站
附近的地铁站
出租房数
可出租的房子数量
日期
发布日期
请在IntelliJ IDEA 中进行spark编程统计各地区的租房人数,完成编译后打包spark工程,通过spark-submit提交程序至集群中运行。
实现思路及步骤:
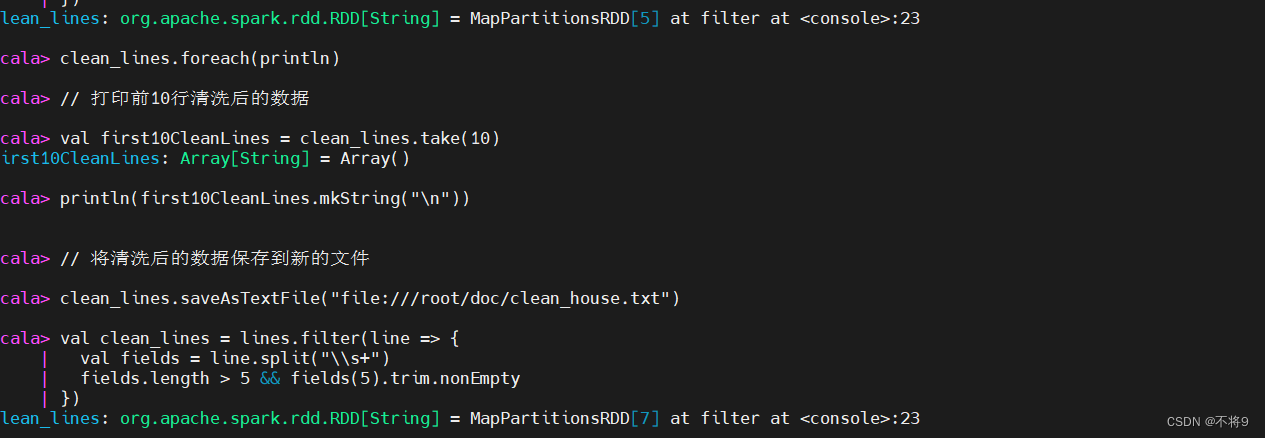
(1) 读取数据并创建RDD
val lines = sc.textFile("file:///root/doc/house.txt")
(2) 清洗数据,例如某些地铁站数据为空
val clean_lines = lines.filter(line => {
val fields = line.split("\s+") // 使用正则表达式分割字段
fields.length > 5 && fields(5).trim.nonEmpty // 确保至少有6个字段且第6个字段不为空
})
(3) 使用reduceByKey()方法统计人数
// 将清洗后的数据的第一列作为键,1作为值,转换为键值对
val categoryPairs = clean_lines.map(line => {
val fields = line.split("\s+")
(fields(0).trim, 1) // 假设第一列是分类信息
})
// 使用reduceByKey聚合相同分类的计数
val categoryCounts = categoryPairs.reduceByKey(_ + _)
categoryCounts.count()

(4) 使用saveAsTextFile()保存数据到hdfs
val hdfsOutputPath = "hdfs://master:9000/user/hadoop/clean_lines"
val lines = sc.textFile("file:///root/doc/house.txt")
lines.saveAsTextFile(hdfsOutputPath)
hdfs dfs -cat /user/hadoop/clean_lines/part-00000

2.自定义分区器事先按照人物标签进行数据分区
实验目标:
- 掌握使用spark自定义分区
- 掌握打包spark工程
- 掌握通过spark-submit提交应用
实验说明:
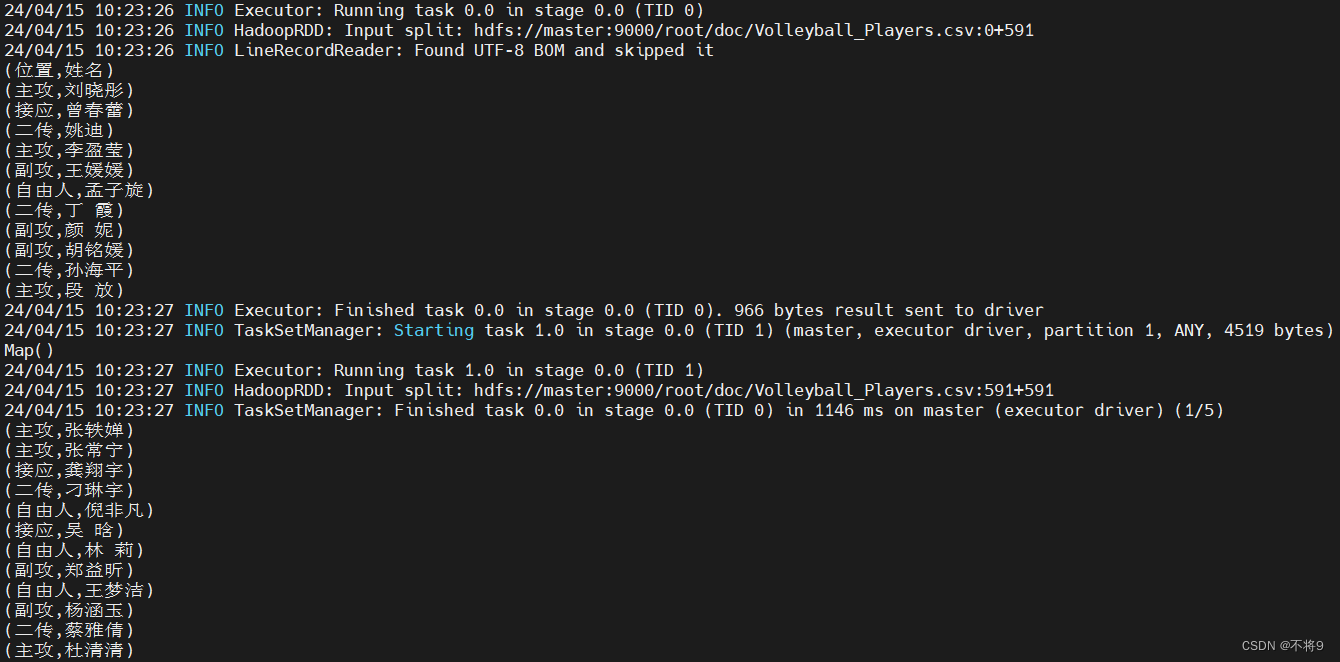
先有一份某年度中国女排集训运动员数据文件 Volleyball_Plaryer.csv ,数据字段说明如下表所示

现要求在IntelliJ IDEA 中进行spark编程,通过自定义分区实现将运动员按照所属位置进行分区,并将程序打包,通过spark-submit提交应用。按照“主攻,接应,二传,副攻,自由人”五个标签设置五个分区,将分区结果输出到hdfs上。其中一个分区的结果举例如图所示:

实现思路及步骤:
- 使用textFile()方法读取数据创建RDD,并设置分区数为5
- 使用map()方法将数据输入数据按都好进行分割,筛选出position和name字段,并转化为(Positon,Name)的形式
- 自定义MyPartioner类,继承该类,重写类里面的numPartions和getPartition 方法。
- 在主函数中调用自定义分区类MyPartioner
- 打包spark工程,将应用程序提交至集群运行
如何在idea使用scala操作可以参考
IDEA使用SCALA-CSDN博客
import org.apache.spark.api.java.JavaRDD.fromRDD
import org.apache.spark.repl.Main.conf
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object Main {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local") //本地单线程运行
sparkConf.setAppName("Main")
val sc = new SparkContext(sparkConf)
val lines = sc.textFile("/root/doc/Volleyball_Players.csv",5)
val new_lines= lines.map(line => {
val fields = line.split(",")
val position = fields(5).trim
val name = fields(0).trim
(position, name)
})
val myPartitioner: MyPartitioner = new MyPartitioner(5)
new_lines.repartition(myPartitioner.numPartitions)
new_lines.foreach(println)
}
}
class MyPartitioner(override val numPartitions: Int) extends Partitioner {
override def getPartition(key: Any): Int = key match {
case (position: String) => position.hashCode % numPartitions
}
}
打包代码

打包成功后在你本机找到该文件

传到linux下

将Volleyball_Players.csv上传到hdfs目录下
hdfs dfs -mkdir -p /root/doc
hdfs dfs -put Volleyball_Players.csv /root/doc/
此时将代码提交
spark-submit --master yarn --class Main untitled4.jar
--master yarn
指定了 Spark 应用程序应该运行在 YARN(Yet Another Resource Negotiator)集群管理器上。
--class Main
指示 Spark 应用程序的入口点是
Main
类中的
main
方法。您需要将
Main
替换为您实际的主类名。
untitled4.jar
是包含您 Spark 应用程序的 JAR 文件。
版权归原作者 浮萍哥 所有, 如有侵权,请联系我们删除。