
简介
此程序是本人大三时期的Python大作业,初学Python后所编写的一个程序,是一个网络爬虫程序,可爬取指定网站的信息。
本程序爬取的网站是Bangumi-我看过的动画,Bangumi是一个专注于二次元的收视进度管理网站,在这里可以记录自己看过的动画和书籍、玩过的游戏、听过的音乐等等,本程序爬取的正是作者本人看过的所有动画,读者若想爬取自己看过的动画,可下载程序后,自行修改源代码中的相应网址。
本程序使用Python编写,使用PyCharm进行开发,数据库使用MySQL数据库,程序可将“Bangumi-我看过的动画”中的所有动画信息爬取下来,并保存至数据库和Excel表格中,亦可将爬取的网站html源码保存至本地,作者还编写了一个JavaWeb程序,用网页的形式展示爬取到的所有动画信息。
程序源代码及程序设计说明书可在下方GitHub链接处进行下载,供各位需要的人学习参考。
GitHub链接:Python爬虫-Bangumi
目录
程序代码
在此展示Python爬虫的完整代码,代码不多做介绍,详细请看代码注释或程序设计说明书,若读者对JavaWeb展示爬取数据感兴趣,可至文章开头处GitHub链接下载程序,进行了解。
import re
import ssl
import xlwt
import pymysql
import urllib.request
import urllib.error
from bs4 import BeautifulSoup
# 主函数defmain():print("开始爬取网站")
ssl._create_default_https_context = ssl._create_unverified_context #全局取消证书验证
baseurl ="https://bangumi.tv/anime/list/430090/collect"#要爬取的网站-Bangumi我看过的动画
pagecount = getPageCount(baseurl)#获取要爬取的页面总数
datalist = getData(baseurl, pagecount)#爬取网页,获取网页数据,并解析数据
saveDataToDatabase(datalist)#将数据保存至数据库
saveDataToExcel(datalist)#将数据保存至excel表格print("网站爬取成功,完毕!!!")# 获取HTML页面内容defgetHTML(url):print("正在获取页面 "+url+" ......")
headers ={#反反爬虫,模拟浏览器头部信息"User-Agent":"Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")print("页面获取成功")return html
# 保存HTML页面defsaveHTML(html, page):print("正在保存页面"+str(page)+"......")
fileobj =open("lib/html/page"+str(page)+".html","w", encoding="utf-8")
fileobj.write(html)
fileobj.close()print("页面"+str(page)+"保存成功")# 获取要爬取的页面总数defgetPageCount(baseurl):
pagecount =0#页面总数
html = getHTML(baseurl)print("正在获取页面总页数......")
soup = BeautifulSoup(html,"html.parser")
ul = soup.find("ul",id="browserItemList")
li = ul.find("li")if li isNone:#若ul标签里无li标签,则表示页面总数为0,即我看过的动画为0
pagecount =0else:
div = soup.find("div",id="multipage")
span = div.find("span", class_="p_edge")#页面过多的话,div标签里会有一个span标签,网站会将“当前页数/总页数”放在此span标签中if span isnotNone:#若有span标签,则可以直接获取页面总数
result = re.findall(r'[0-9]+', span.string)
pagecount =int(result[1])else:#若无span标签,则需通过a标签获取页面总数
alist = div.find_all("a")iflen(alist)!=0:#若有a标签,则倒数第二个a标签的内容即为总页数
pagecount =int(alist[len(alist)-2].string)else:#若无a标签,则表示页面总数为1
pagecount =1print("页面总数获取成功,页面总数为{}页".format(pagecount))return pagecount
# 将网页中的链接由相对路径改为绝对路径,或修改不符合要求的链接defchangeLink(html):print("正在修改相关链接......")
soup = BeautifulSoup(html,"html.parser")# 获取所有a标签,对不符合要求的进行修改
a_list = soup.find_all("a")for i in a_list:#对链接为相对路径的a标签进行修改if'href'in i.attrs and re.match(r'/[^\s]*', i['href'])isnotNone:
i['href']="https://bangumi.tv"+ i['href']# 获取所有link标签,对不符合要求的进行修改
link_list = soup.find_all("link")for i in link_list:#对链接为相对路径的link标签进行修改if'href'in i.attrs and re.match(r'/[^\s]*', i['href'])isnotNone:
i['href']="https://bangumi.tv"+ i['href']# 获取所有script标签,对不符合要求的进行修改
script_list = soup.find_all("script")for i in script_list:#对链接为相对路径的script标签进行修改if'src'in i.attrs and re.match(r'/[^\s]*', i['src'])isnotNone:
i['src']="https://bangumi.tv"+ i['src']# 获取所有form标签,对不符合要求的进行修改
form_list = soup.find_all("form")for i in form_list:#对链接为相对路径的form标签进行修改if'action'in i.attrs and re.match(r'/[^\s]*', i['action'])isnotNone:
i['action']="https://bangumi.tv"+ i['action']# 获取所有img标签,对不符合要求的进行修改
img_list = soup.find_all("img")for i in img_list:#为img标签的图片链接加上https:前缀if'src'in i.attrs and re.match(r'//[^\s]*', i['src'])isnotNone:
i['src']="https:"+ i['src']# 发生未知错误,无法正确爬取获取该动画的img标签的src属性,实属无奈,故手动显式修改if soup.find("li",id="item_7157")isnotNone:
img = soup.find("li",id="item_7157").find("img")
img['src']="https://lain.bgm.tv/pic/cover/s/6e/01/7157_QV8Rz.jpg"# 特殊情况,为我的头像的图片链接加上https:前缀
span = soup.find("span", class_="avatarNeue avatarSize75")
span['style']= re.sub(r'//[^\s]*',"https:"+ re.search(r'//[^\s]*', span['style']).group(), span['style'])# 特殊情况,修改特定a标签链接
div = soup.find("div",id="robot_speech")
a = div.find("a", class_="nav")
a['href']="https://bangumi.tv/"+ a['href']print("相关链接修改成功")return soup.prettify()# 将网页改为本地,相关依赖使用本地资源,无需联网即可访问............ 暂不考虑实现deftoLocal():pass# 爬取网页,获取网页数据,并解析数据defgetData(baseurl, pagecount):
datalist =[]#二维列表,用于存放所有我看过的动画for i inrange(1, pagecount+1):#遍历所有页面,一个一个爬取
url = baseurl +"?page="+str(i)
html = getHTML(url)#获取HTML页面内容
html = changeLink(html)#修改相关链接
saveHTML(html, i)#保存HTML页面print("开始爬取解析页面"+str(i))
soup = BeautifulSoup(html,"html.parser")
all_animation = soup.find("ul",id="browserItemList")#该ul标签中存放了目标数据,即我看过的动画# 逐一解析数据for item in all_animation.find_all("li"):#遍历一个个li标签,即遍历一部部我看过的动画,并获取数据
data =[]# 获取id
idd = re.search(r'[0-9]+', item['id']).group()
data.append(idd)print("正在解析动画(id:{})数据......".format(idd))# 获取中文名
chinese_name = item.find("a", class_="l").string.strip()
data.append(chinese_name)# 获取原名if item.find("small", class_="grey")isNone:#可能无原名
original_name =""else:
original_name = item.find("small", class_="grey").string.strip()
data.append(original_name)# 获取话数、放送开始时间、导演等人
info = item.find("p", class_="info tip").string
episodes = re.search(r'[0-9]+', info).group()if re.search(r'[\d]+年[\d]+月[\d]+日', info)isnotNone:#有两种日期格式
broadcast_time = re.search(r'[\d]+年[\d]+月[\d]+日', info).group()
broadcast_time = re.sub(r'[^\d]+',"-", broadcast_time).strip("-")#转换为xxxx-xx-xx的格式elif re.search(r'[\d]+-[\d]+-[\d]+', info)isnotNone:
broadcast_time = re.search(r'[\d]+-[\d]+-[\d]+', info).group()else:
broadcast_time =""if re.search(r'日.+', info)isNone:#可能无导演等人
people =""else:
people = re.search(r'日.+', info).group()
people = people[4:].strip()
data.append(episodes)
data.append(broadcast_time)
data.append(people)# 获取收藏时间
star_time = item.find("span", class_="tip_j").string.strip()
data.append(star_time)# 获取个人评分
score = item.find("span", class_="starlight")['class'][1]
score = re.search(r'[0-9]+', score).group()
data.append(score)# 获取个人标签if item.find("span", class_="tip")isNone:#可能无个人标签
tag =""else:
tag = item.find("span", class_="tip").string
tag = tag.strip()[4:]
data.append(tag)# 获取页面网址
page_url = item.find("a", class_="l")['href']
data.append(page_url)# 获取缩略封面图网址,并下载保存print("正在下载缩略封面图{}.jpg".format(idd))
low_image_url = item.find("img", class_="cover")['src']
data.append(low_image_url)
low_image_path ="lib/image/low/"+ idd +".jpg"
data.append(low_image_path)
low_image_url = re.sub(r'lain.bgm',"bangumi", low_image_url)#图片原链接不允许爬取下载,故需转换下链接
urllib.request.urlretrieve(low_image_url, low_image_path)#下载缩略封面图# 获取高清封面图网址,并下载保存print("正在下载高清封面图{}.jpg".format(idd))
high_image_url = re.sub(r'/s/',"/l/", low_image_url)#缩略图和高清图的网址仅有一字之差
data.append(high_image_url)
high_image_path ="lib/image/high/"+ idd +".jpg"
data.append(high_image_path)#urllib.request.urlretrieve(high_image_url, high_image_path) #下载高清封面图,文件较大且多,故很花时间
datalist.append(data)print("页面{}爬取解析成功".format(str(i)))return datalist
# 将数据保存至数据库defsaveDataToDatabase(datalist):print("开始将数据保存至数据库")
con = pymysql.connect(host="localhost", database="web_crawler", user="root", password="root")
cur = con.cursor()
sql ="insert into animation values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"try:for data in datalist:print("正在保存动画(id:{})数据至数据库......".format(data[0]))
cur.execute(sql,tuple(data))
con.commit()except:
con.rollback()#发生错误时回滚print("数据保存失败")else:print("数据保存成功")
cur.close()
con.close()# 将数据保存至excel表格defsaveDataToExcel(datalist):print("开始将数据保存至excel表")
book = xlwt.Workbook(encoding="utf-8")#创建一个workbook,并设置编码
sheet = book.add_sheet("我看过的动画")
colname =("ID","中文名","原名","话数","放送开始时间","导演/原作者/等制作人","收藏时间","个人评分","个人标签","页面网址","缩略封面图网址","缩略封面图本地路径","高清封面图网址","高清封面图本地路径")
style = xlwt.easyxf('font: bold on')#样式,为列名加粗for i inrange(0,14):#添加列名
sheet.write(0, i, colname[i], style)for i inrange(0,len(datalist)):#添加数据
data = datalist[i]print("正在保存动画(id:{})数据至excel表......".format(data[0]))for j inrange(0,14):
sheet.write(i +1, j, data[j])
book.save("lib/excel/Bangumi-我看过的动画.xls")#保存excel表print("数据保存成功")if __name__ =="__main__":
main()
运行结果
代码编写完成后运行程序,程序运行过程中会在控制台实时输出当前爬取进度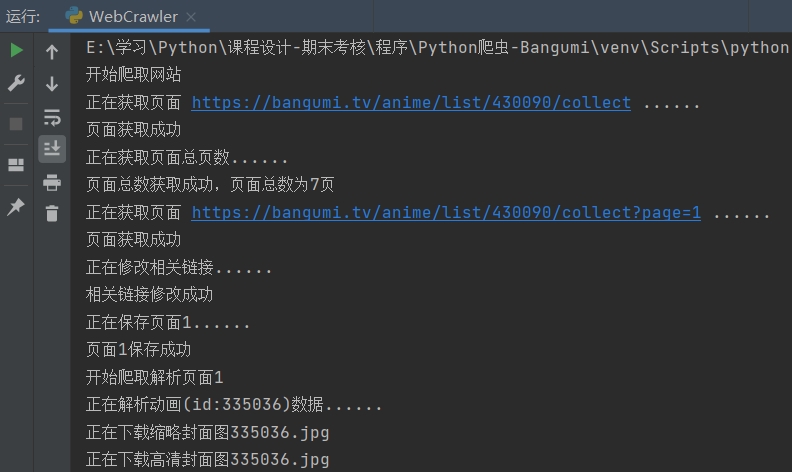
爬取完毕后,可看到成功导出html文件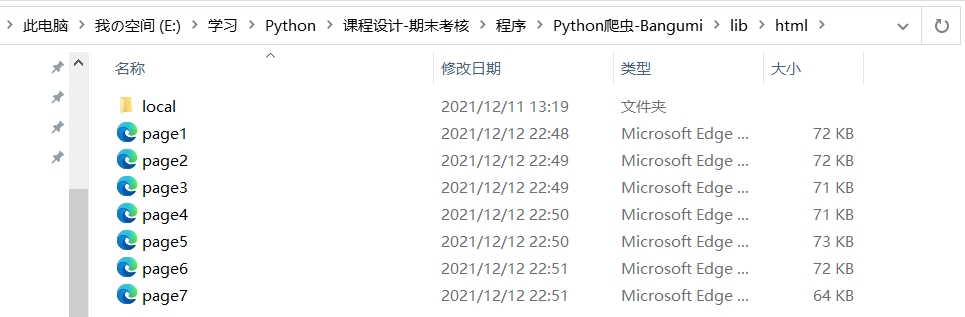
成功下载封面图片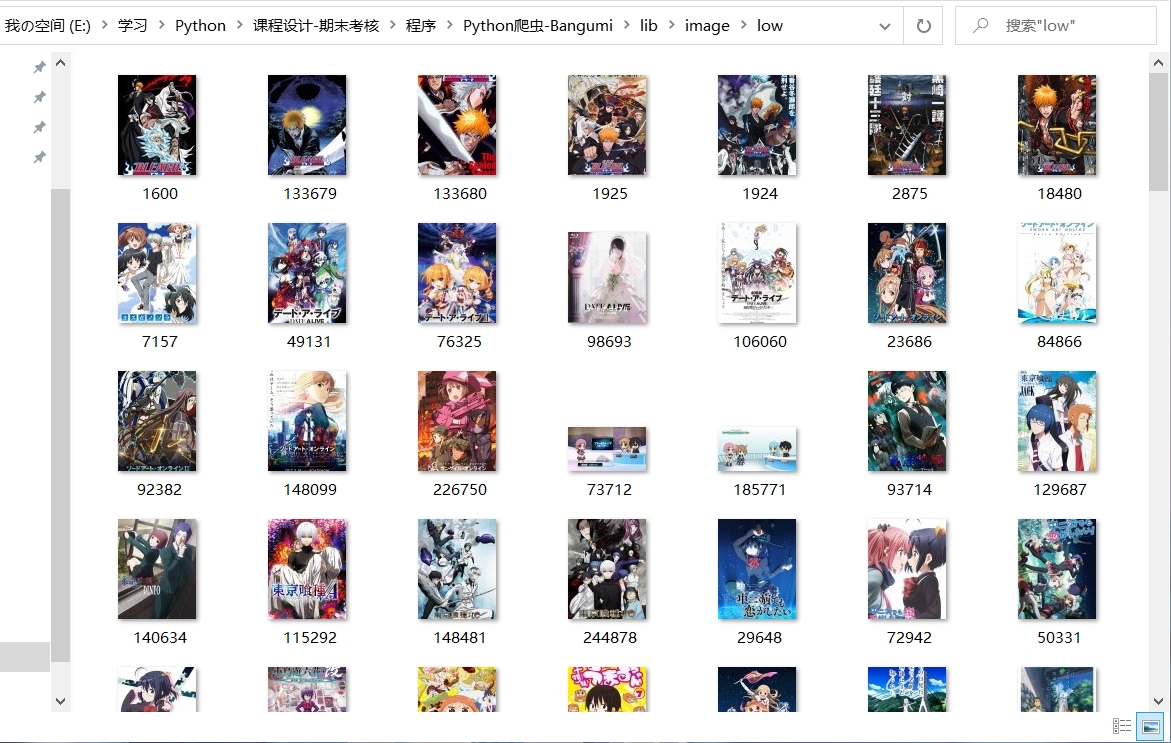
信息成功保存至数据库
成功保存至Excel表格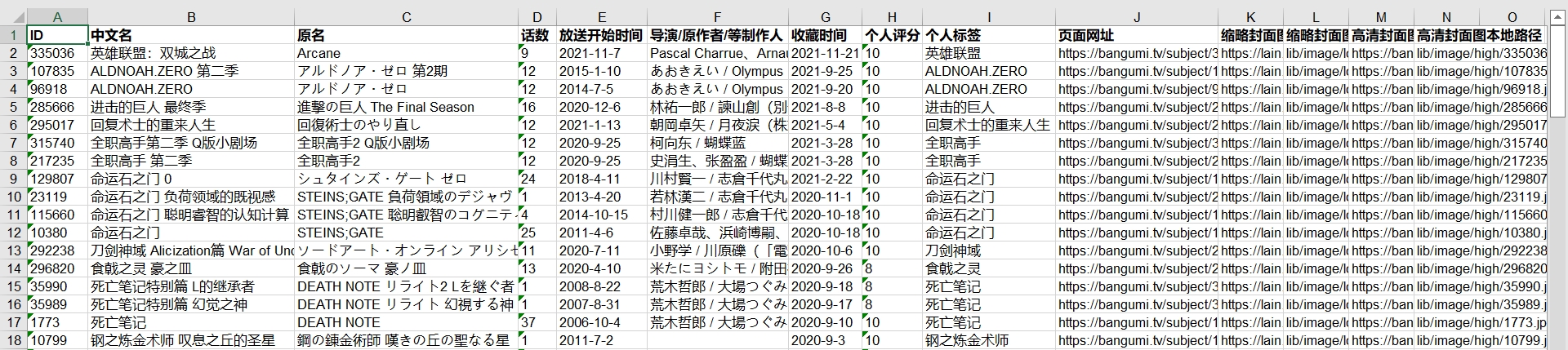
最后JavaWeb程序也成功展示爬取的数据
后记
本程序仅供学习和参考,请勿抄袭或另作他用。
感谢观看,有什么问题可在下方评论区进行评论,若觉得本文章写得不错,还请点个赞呢。
关注我,收看更多精彩!( • ̀ω•́ )✧求点赞、评论、收藏、关注
本文转载自: https://blog.csdn.net/XiuMu_0216/article/details/125935768
版权归原作者 朽木冰天 所有, 如有侵权,请联系我们删除。
版权归原作者 朽木冰天 所有, 如有侵权,请联系我们删除。