
Spark 官方文档快速入门指南
Spark架构 -Spark教程
1. 基本概念
RDD(resilient distributed dataset)弹性分布式数据集,对分布式数据和计算的基本抽象。
每个** Spark 应用 **由一个 驱动器程序(driver program)发起集群上的并行操作,驱动器程序一般要管理多个 执行器(executor)节点。
当我们在集群上执行一个操作,不同的节点会对文件不同部分展开计算。
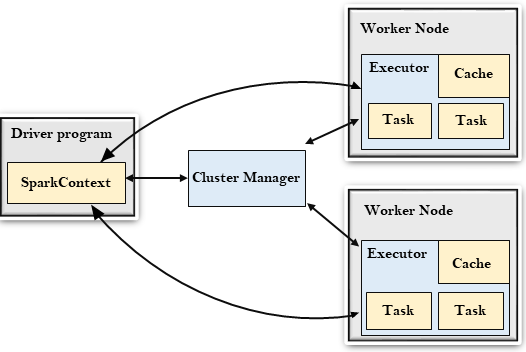
驱动器程序 发起集群上的并行操作,定义了集群上的分布式数据集,进行相关操作。包含了一个 main 函数。
驱动器程序通过一个 **SparkContext **对象访问 Spark。这个对象代表对计算集群的一个连接。
我们可以用** SparkContext **创建RDD。
Spark 会自动动将函数发送到各个执行器器节点上,我们可以在单一的驱动器程序中编辑,并让代码自动运行在多个节点上。
2. Spark 执行 Python 脚本
Spark 执行 Python 需要将应用写成 Python 脚本,使用 bin/spark-submit 脚本提交运行。
Spark 对数据的操作大致可以分为 1. 创建 RDD 2. 转化已有 RDD 3. 调用 RDD 操作
转化是由一个 RDD 生成一个新的 RDD ,转化是对 RDD 进行一个操作返回结果到驱动器程序或外部存储系统。
bin/spark-submit my_script.py
一般 Spark 程序按照如下方式工作:
(1)从外部数据创建 RDD
(2)对 RDD 进行转化,定义的新的 RDD
(3)告诉 RDD 需要被重用的中间结果执行 persist () 操作
(4)触发计算
2.1 自行初始化 **SparkContext **
** 导入 Spark 包,先创建一个 SparkConf 对象配置应用**,然后基于 SparkConf 创建一个 SparkContext 对象。
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
# setMaster 集群URL:告诉Spark如何连接到集群。local 单机单线程
# setAppName 应用名,连接到集群时候在集群管理器用户界面找应用
sc = SparkContext(conf = conf)
关闭方法: stop() / System.exit(0) / sys.exit()
2.2 创建 、转化、操作RDD
2.2.1 创建
**RDD**(resilient distributed dataset)**弹性分布式数据集,**一个不可变的分布式对象集合。
** ** 可以分为:(1)读取外部数据集。(2)在驱动器城区里分发对象合集。
将一个已有的集合传给 SparkContext。例如:
lines = sc.paralleize(["pandas", "i like pandas"])
lines = sc.textFile("/path/to/README.md")
2.2.2 创建
用户可以在任何时候定义新的 RDD 但是 **Spark** 只会**惰性计算**,当我们调用转化操作时,不会立即执行。默认情况下 Spark 的** RDD **会在**每次对他们进行行动操作时重新计算**,如果需要在多个行动中重用一个 RDD 可以用 **RDD.persist() **让 Spark 缓存 RDD 到内存,反复查询和分析。
** Spark 对 转化和操作的执行方式不同,需要明确使用的操作的类型。**
** 返回值判断:**转化操作返回 RDD ,行动操作返回其他数据类型。
转化操作不会改变已有的 RDD 数据,而是返回一个全新的 RDD。后续仍可使用原始 RDD。
另外 Spark 会用**谱系图记录 RDD 之间的依赖关系**。
2.2.3 操作
**行动操作会生成计算结果,强制执行求值必须用到的 RDD 的转化操作。**
3. 向 Spark 传递函数(Python)
(1)传递比较短的函数,**lamabda 表达式**
word = rdd.filter(lambda s: "error" in s)
def containsError(s):
return "error" in s
word = filter(containsError)
注意传递函数会把函数所在的对象也序列化传出去,把整个对象发送到工作节点。应该把需要的字段从对象中取出来作为局部变量,**传递局部变量。**
class WordFunctions(object):
...
def getMatchesNoReference(self, rdd):
query = delf.query
return rdd.filter(lambda x:query in x)
4. 常见的转化和行动操作
4.1 转化操作
map(func) 接受一个函数,用于处理RDD中的每个元素,将返回结果作为结果RDD中对应元素的值。
map() 解析字符串,返回 Double 值。
filter(func) 接收一个函数,将RDD中满足该函数的元素放入新的RDD返回。
flatMap(func) 每个输入项可以映射到零个或多个输出项, 因此函数返回序列而不是单个项。
类似 map() 对每个元素应用,但返回是 一个返回值序列的迭代器。输出的 RDD 不是由迭代器组成,而是一个包含各个迭代器可访问的所有元素的 RDD。常用于将一个输入字符串切分为单词。返回的是一个由各列表中的元素组成的 RDD, 而不是一个由列表组成的RDD。
lines = sc.parallelize(["hello world", "hi"])
words = lines.flatMap(lambda line: line.split(" "))
words.first() // 返回"hello"
(返回:{"hello", "word", "hi"},而不是 { ["hello", "world"], ["hi"] } 。)
mapPartitions(func) 类似于map,但是在RDD的每个分区(块)上单独运行, 因此当在类型T的RDD上运行时,
函数必须是Iterator <T> => Iterator <U>类型。mapPartitionsWithIndex(func) 类似于
mapPartitions,为函数提供了一个表示分区索引的整数值,因此当在类型T的RDD上运行时,func必须是类型(Int,Iterator <T>)=> Iterator <U>。sample(withReplacement, fraction, seed) 使用给定的随机数生成器种子对数据进行采样,并且有或没有替换。
union(otherDataset) 返回一个包含源数据集和参数中元素的并集的新数据集。(不去重)
intersection(otherDataset) 返回一个包含源数据集和参数中的元素的交集的新的RDD。(去重,对单个RDD也去重,需要混洗数据)
subtract(otherDataset) 返回一个只存在于第一个RDD而不存在第二个RDD中元素组成的RDD。(需要数据混洗)
distinct([numPartitions]) 返回一个新数据集,其中只包含源数据集的不同元素的新RDD。
注意,开销很大,需要将所有数据通过网络进行数据混洗。
groupByKey([numPartitions]) 当在
(K,V)对的数据集上调用时,它返回(K,Iterable)对的数据集。reduceByKey(func, [numPartitions]) 当调用
(K,V)对的数据集时,返回(K,V)对的数据集,其中使用给定的reduce函数func聚合每个键的值,该函数必须是类型(V,V)=>V。aggregateByKey(xeroValue)(seqOp, combOp, [numPartitions]) 当调用
(K,V)对的数据集时,返回(K,U)对的数据集,其中使用给定的组合函数和中性“零”值聚合每个键的值。sortByKey([ascending], [numPartitions]) 返回按键按升序或降序排序的键值对的数据集,如在布尔
ascending参数中所指定。join(otherDataset, [numPartitions]) -当调用类型
(K,V)和(K,W)的数据集时,返回(K,(V,W))对的数据集以及每个键的所有元素对。通过leftOuterJoin,rightOuterJoin和fullOuterJoin支持外连接。cogroup(otherDataset, [numPartitions]) 调用类型
(K,V)和(K,W)的数据集时,返回(K,(Iterable,Iterable))元组的数据集。此操作也称为groupWith。cartesian(otherDataset) 计算笛卡尔积,返回所有可能的(a,b)对,a是源RDD元素,b来自另一个RDD。在我们希望考虑所有可能的组合的相似度时有用。(大规模数据开销大)
pipe(command, [envVars]) 通过shell命令管道RDD的每个分区,例如, 一个Perl或bash脚本。
coalesce(numPartitions) 将RDD中的分区数减少到
numPartitions。repartition(numPartitions) 随机重新调整RDD中的数据,以创建更多或更少的分区,并在它们之间进行平衡。
repartitionAndSortWithPartitions(partitioner) 根据给定的分区器对RDD进行重新分区,并在每个生成的分区中键对记录进行排序。
4.2 行动操作
- reduce(func)接收一个函数func作为参数(这个函数接受两个参数并返回一个)来操作两个相同元素类型的RDD数据并返回一个同类型的新元素,常用于元素的聚合操作。
sum = rdd.reduce(lambda x, y: x + y)
fold(zero)(func)与reduce()类似,接收一个函数func作为参数(这个函数接受两个参数并返回一个),再加上一个“初始值”作为每个分区第一次调用的结果,初始值应该是提供的操作的单位元素,函数对这个初始值进行多次计算不会改变计算结果。- aggregate(zeroValue)(seqOp,combOp)需要提供一个“初始值”,返回值不必与所操作的RDD类型相同。通过一个函数将RDD中的元素合并起来放入累加器,第二个函数将累加器合并。
sumCount = nums.aggregate((0.0),
(lambda acc, value: (acc[0] + value, acc[1] + 1),
(lambda acc1, acc2: (acc1[0] + acc2[0], acc1[1] + acc2[1]))))
return sumCount[0] / float(sumCount[1])
- collect( )将数据集的所有元素作为数组返回到驱动程序中。在过滤器或其他返回足够小的数据子集的操作之后,这通常很有用。
- count( )返回数据集中的元素数。
- countByValue( )返回各元素在RDD中出现的次数。
- first( )它返回数据集的第一个元素(类似于
take(1))。 - take(n)返回RDD中的n个元素,尝试访问尽量少的区域。
- top(n)返回RDD前几个元素。
- takeSample(withReplacement, num, [seed])它返回一个数组,对数据采样有或没有替换。
- takeOrdered(n, [ordering])从RDD中按照提供的顺序返回最前面的n个元素。
- saveAsTextFile(path)用于将数据集的元素作为文本文件(或文本文件集)写入本地文件系统,HDFS或任何其他Hadoop支持的文件系统的给定目录中。
- saveAsSequenceFile(path)用于在本地文件系统,HDFS或任何其他Hadoop支持的文件系统中的给定路径中将数据集的元素编写为Hadoop SequenceFile。
- saveAsObjectFile(path)用于使用Java序列化以简单格式编写数据集的元素,然后可以使用
SparkContext.objectFile()加载。 - countByKey( )仅适用于类型(K,V)的RDD。因此,它返回(K,Int)对的散列映射与每个键的计数。
- foreach(func)它对RDD中的元素进行操作而不把结果返回到驱动器程序,用JSON格式把数据发送到网络服务器。
5. 持久化(缓存)
为了避免多次计算同一个 RDD ,可以让Spark对数据进行持久化存储一个RDD。Spark的缓存是容错的。在任何情况下,如果RDD的分区丢失,它将使用最初创建它的转换自动重新计算。
我们可以为 RDD 选择不同的持久化级别。
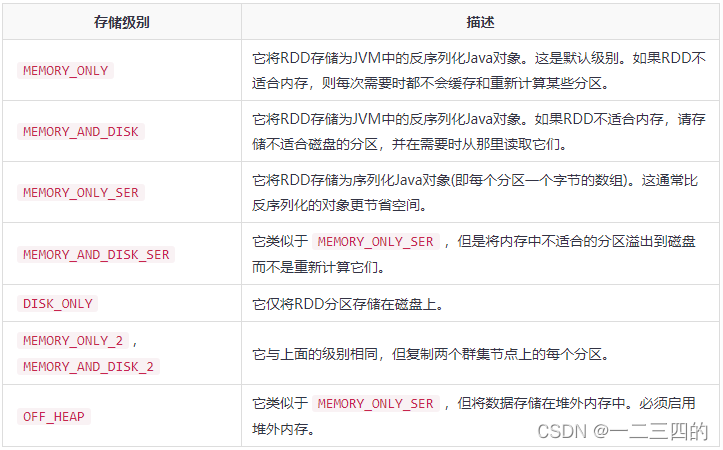
_2 把持久化的数据分成两份存储。
unpersist( ) 手动把持久化的RDD从缓存中移除。
版权归原作者 一二三四的 所有, 如有侵权,请联系我们删除。