
python爬虫selenium和ddddocr使用
selenium使用
selenium实际上是web自动化测试工具,能够通过代码完全模拟人使用浏览器自动访问目标站点并操作来进行web测试。
通过python+selenium结合来实现爬虫十分巧妙。
由于是模拟人的点击来操作,所以实际上被反爬的概率将大大降低。
selenium能够执行页面上的js,对于js渲染的数据和模拟登陆处理起来非常容易。
1.安装
pip install selenium
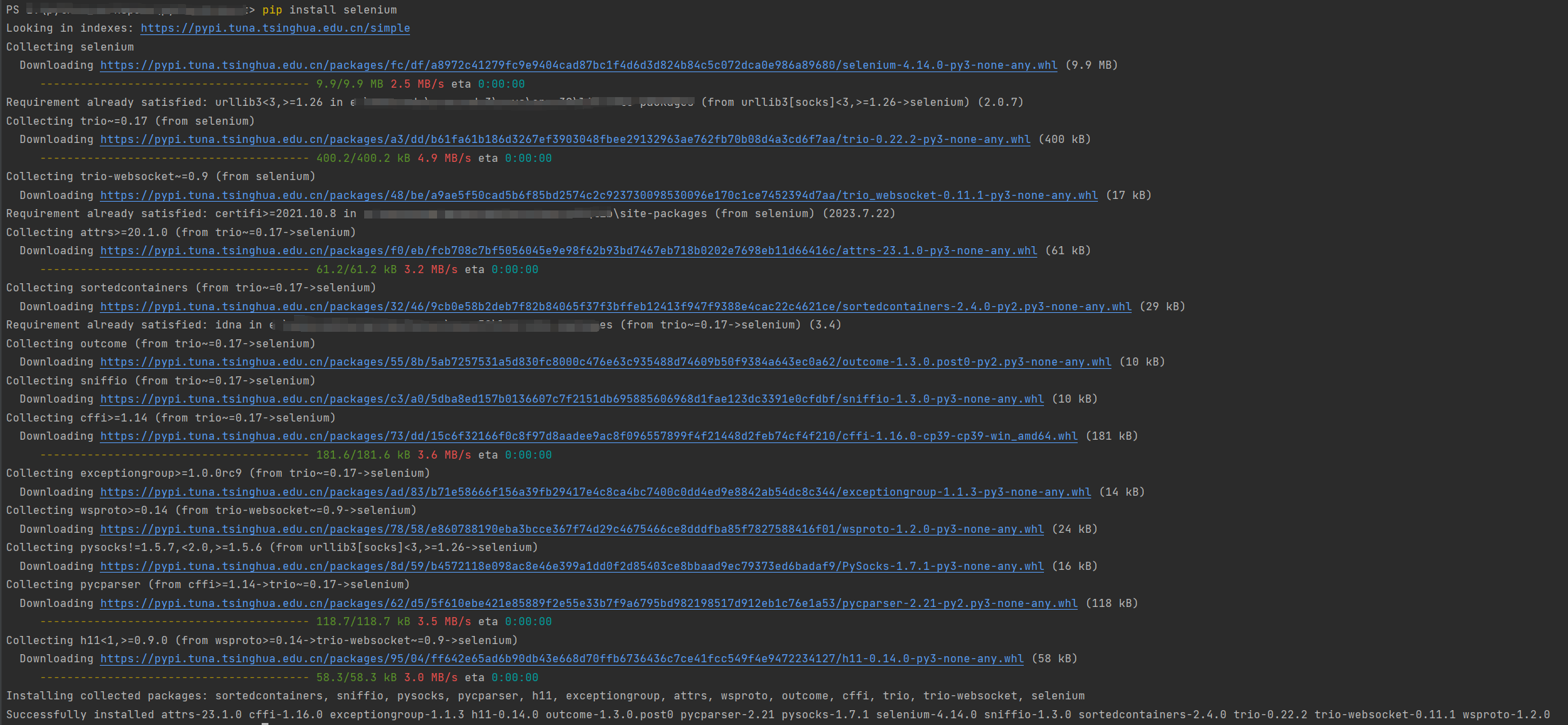
2.安装模拟驱动webdriver
以谷歌浏览器为例,首先查看浏览器的版本号
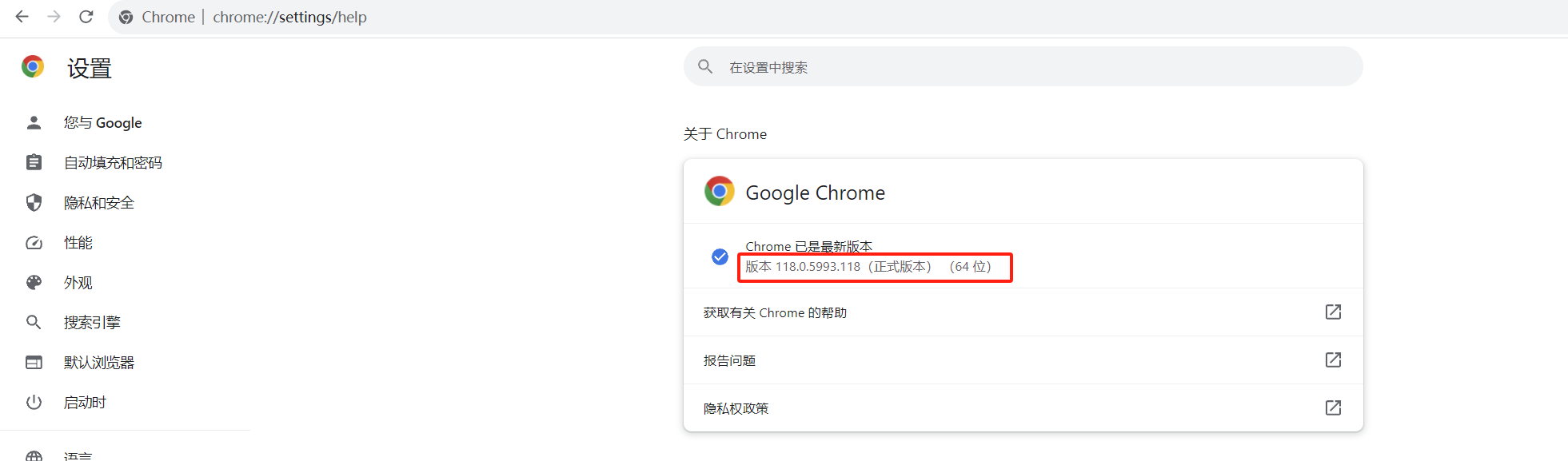
下载对应版本号的安装包,下好后解压
版本号70-114:http://chromedriver.storage.googleapis.com/index.html
版本号118-120:https://googlechromelabs.github.io/chrome-for-testing/#stable

3.代码编写
首先引入包
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
配置浏览器启动地址和webservice地址
options = webdriver.ChromeOptions()
options.binary_location = 'chrome.exe的地址
driver_location = "chromedriver.exe的地址
打开浏览器,并访问网站
browser = webdriver.Chrome(service=Service(driver_location), options=options)
browser.get('https://www.jd.com/')
完整代码
# @Author : 陈天在睡觉# @Time : 2023/10/28 23:19from selenium import webdriver
from selenium.webdriver.chrome.service import Service
options = webdriver.ChromeOptions()
options.binary_location ='C:\\chrome.exe'# 谷歌浏览器地址
driver_location ="E:\\chromedriver.exe"# 谷歌浏览器driver地址
browser = webdriver.Chrome(service=Service(driver_location), options=options)
browser.get('https://www.jd.com/')# 访问网站

这个时候我们发现浏览器打开页面后就会关闭,我们只需要加上一行代码即可
options.add_experimental_option("detach",True)
完整代码
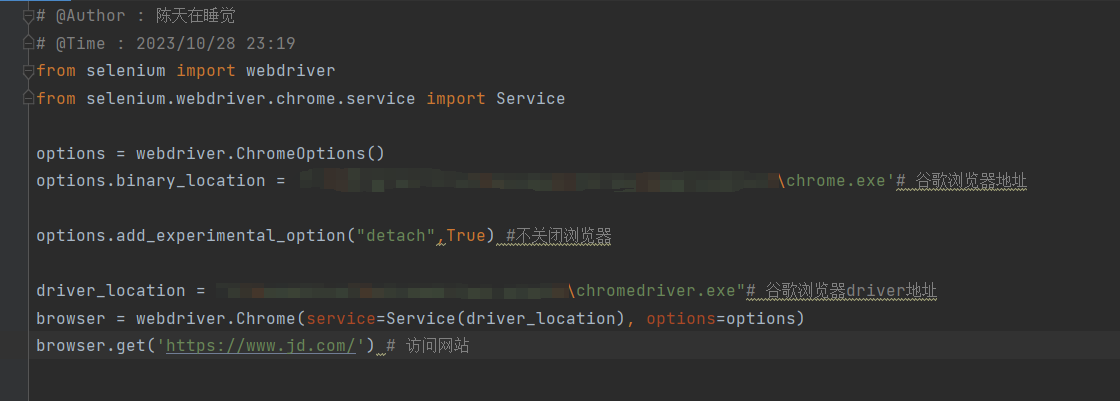
4.获取元素
我们可以通过drowser的find_element找到对象
from selenium.webdriver.common.by import By
browser.find_element(By.ID,"title")#通过id来查找id为title的元素
老版本的selenium查找方法为
from selenium.webdriver.common.by import By
browser.find_element_by_id("title")
找到元素可以使用click()模拟点击,send_keys()模拟输入
from selenium.webdriver.common.by import By
username = browser.find_element(By.ID,"username")
submit = browser.find_element(By.ID,"submit")
username.send_keys("admin")
submit.click()
ddddocr使用
ddddocr(Deep Double-Digital Digits OCR)是一个基于深度学习的数字识别库,专门用于识别双重数字(双位数字)的任务。它是一个开源项目,提供了训练和预测的功能,可用于识别图片中的双位数字并输出其具体的数值。
- 深度学习:ddddocr利用深度学习技术,特别是卷积神经网络和循环神经网络,对双重数字进行准确的识别。
- 开源项目:ddddocr是一个开源项目,允许用户免费使用、修改和分发代码。这使得更多的开发者可以参与其中,贡献自己的想法和改进。
- 高准确率:通过深度学习的方法,ddddocr在双重数字识别任务上能够取得较高的准确率,有效克服了传统方法在此任务上的困难。
- 灵活性:ddddocr提供了训练和预测的功能,用户可以根据自己的需求自定义模型并进行训练,以适应不同的双重数字识别任务。
ddddocr的目标是提供一个简单而有效的工具,帮助开发者和研究者在双重数字识别任务上取得更好的结果。通过使用该库,用户可以轻松地集成双重数字识别功能到自己的应用程序或项目中,实现更准确和可靠的数字识别功能。
1.安装
需要注意的是python版本过高是安装不了的,我使用的是python3.9
pip install ddddocr
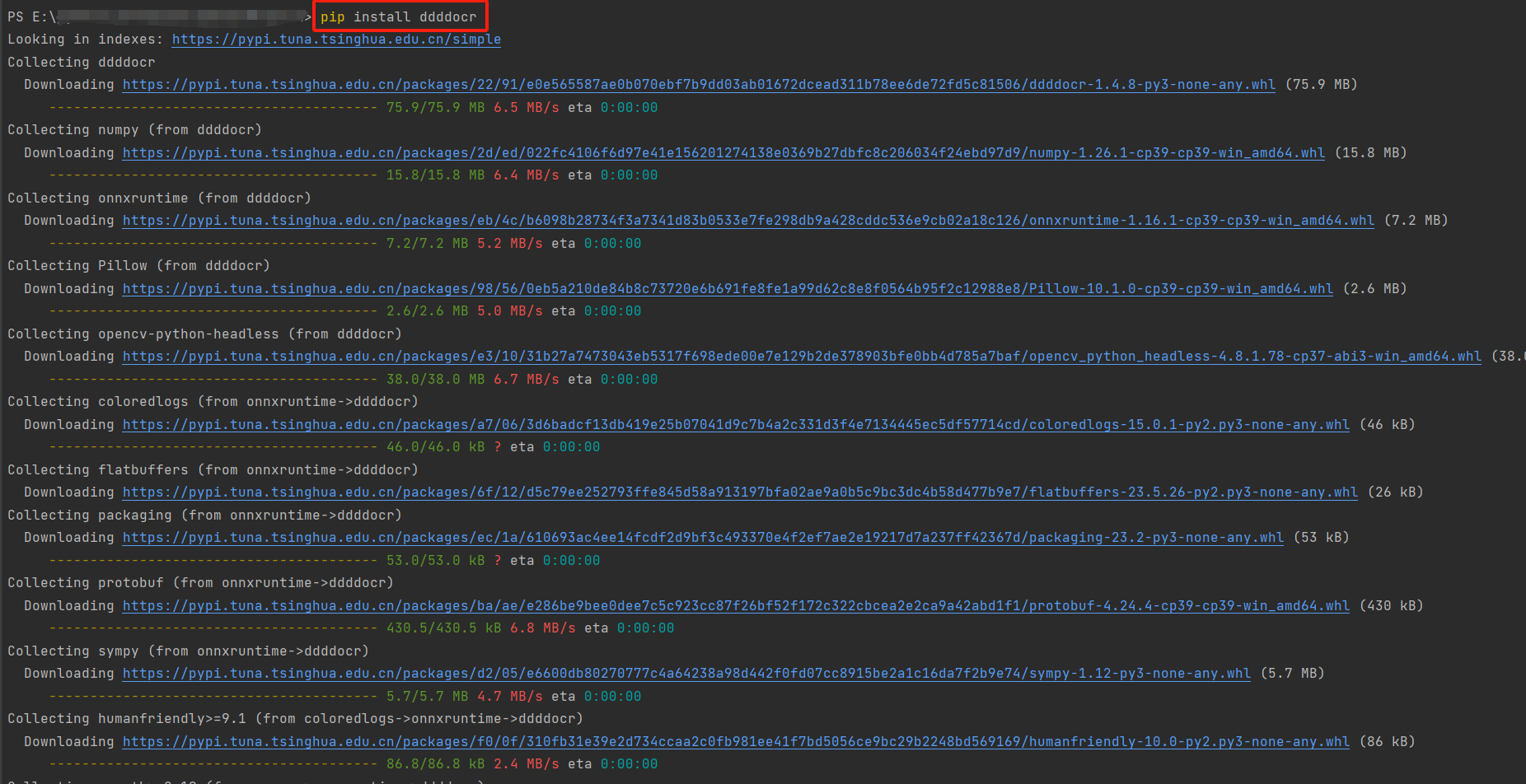
2.修改配置
我们直接使用ddddocr会出现以下错误

原因是在pillow的10.0.0版本中,ANTIALIAS方法被删除了,使用新的方法即可:
旧方法:Image.ANTIALIAS
新方法:Image.LANCZOS
解决办法:
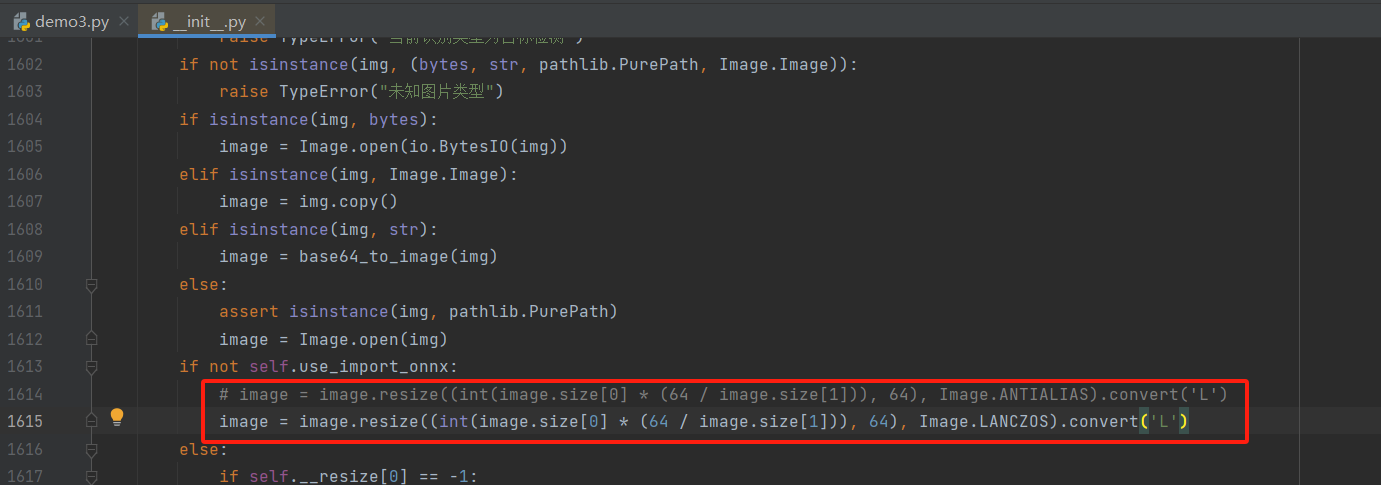
方案一,修改ddddocr的_init_.py文件,将其中的ANTIALIAS替换为新方法:
image = image.resize((int(image.size[0]*(64/ image.size[1])),64), Image.ANTIALIAS).convert('L')
image = image.resize((int(image.size[0]*(64/ image.size[1])),64), Image.LANCZOS).convert('L')
方案二,降级Pillow的版本,比如使用9.5.0版本
先卸载,再重新安装
pip uninstall -y Pillow
pip install Pillow==9.5.0
这里我采用的是方法一,直接点击红框框里的文件

3.编写代码
直接上代码
# @Author : 陈天在睡觉# @Time : 2023/10/29 21:50import ddddocr
ocr = ddddocr.DdddOcr()withopen('img.png','rb')as f:
image = f.read()
res = ocr.classification(image)print('识别出的验证码为:'+ res)
测试的图片
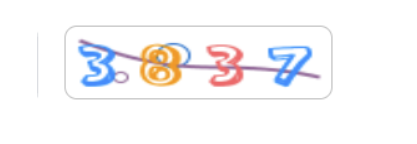
测试结果

如果不想看到广告可以添加show_ad = False
# @Author : 陈天在睡觉# @Time : 2023/10/29 21:50import ddddocr
ocr = ddddocr.DdddOcr(show_ad =False)withopen('img.png','rb')as f:
image = f.read()
res = ocr.classification(image)print('识别出的验证码为:'+ res)

版权归原作者 陈天在睡觉 所有, 如有侵权,请联系我们删除。