
一、Hadoop介绍
Hadoop之父:道格 卡丁 (Doug Cutting)
吉祥物: 大象
Hadoop 解释:
狭义解释:指的是HDFS、MapReduce、Yarn等框架.
广义解释:指的是Hadoop生态圈,包括但不限于周边所有技术.
- Hadoop组成:
HDFS(Hadoop distributed file system):Hadoop分布式文件存储系统
MapReduce:分布式计算框架
Yarn:分布式 任务接收和资源调度框架
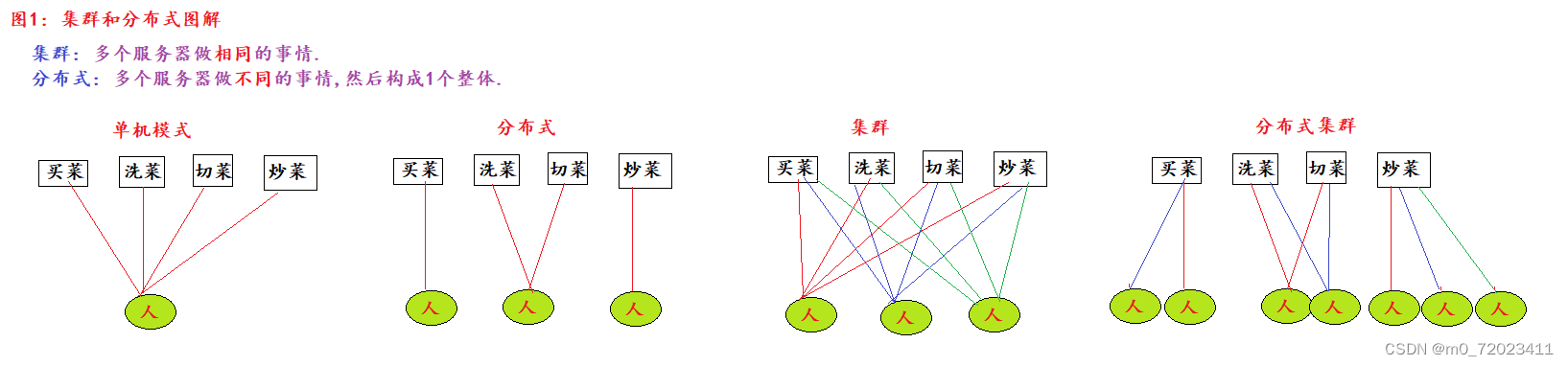
- 分布式和集群:
分布式:多台机器做不同的事,组成一个整体.
集群: 多台机器做相同的事.
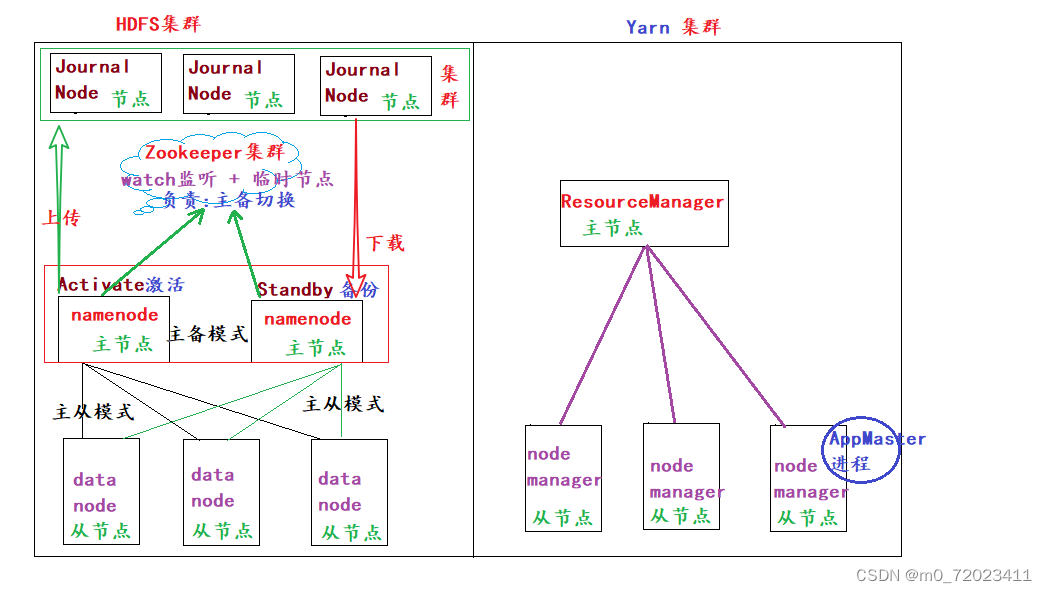
多台机器可以组成 中心化模式 (主从模式),也可以组成 去中心化模式 (主备模式).
二、Hadoop 架构
1、 Hadoop 1.x 架构
Hadoop 1.x = HDFS + MapReduce
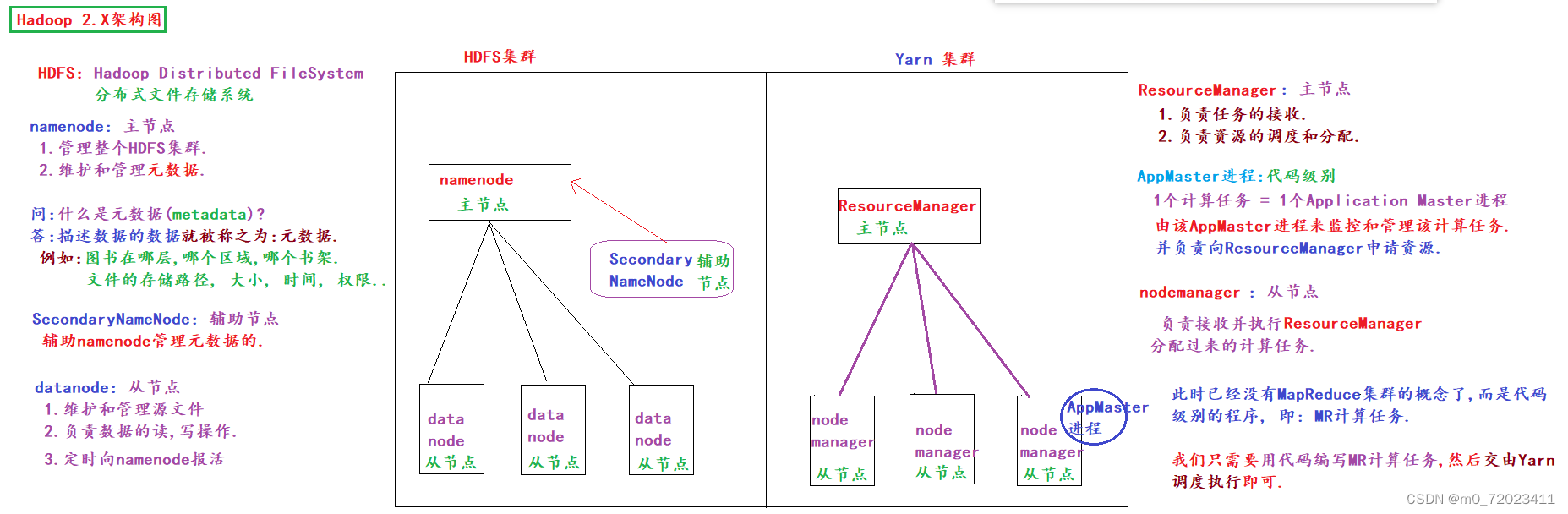
HDFS集群中:
namenode 为主节点,负责管理整个HDFS集群 以及 维护和管理元数据.
SecondaryNameNode 为辅助节点,负责辅助namenode管理元数据.
datanode 为从节点,负责维护和管理源文件 、 数据的读、写操作 以及 定时向 namenode 报活.
MapReduce集群中:
JobTracker 为主节点,负责任务的接收、调度、监控 以及 资源的调度和分配.
TaskTracker 为从节点,负责接收并执行 JobTracker 分配过来的计算任务.
元数据:描述数据的数据称之为元数据.

由于 JobTarcker 任务过于繁重,容易宕机. 所以 2.x 3.x 架构有所改变.
2、Hadoop 2.x 3.x 架构
Hadoop 2.x 3.x = HDFS + MapReduce + Yarn
此时 MapReduce 已经没有集群概念了,而是代码级别的程序 . 即:MR计算任务
Yarn 集群中:
ResourceManager 为主节点,负责任务的接收 以及 资源的调度和分配.
nademanager 为从节点,负责接收并执行 ResourceManager 分配过来的计算任务.
Hadoop 集群高可用模式图解
三、HDFS介绍
1、HDFS架构
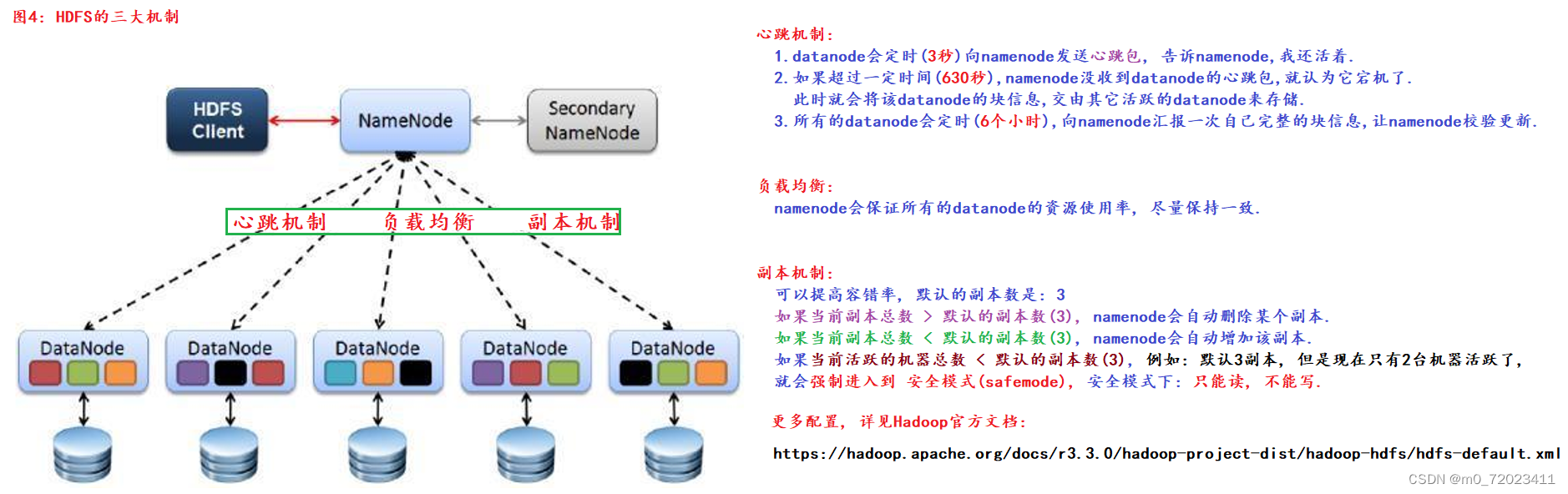
HDFS 的三大机制:
心跳机制(3秒,630秒,6小时):
(1) datanode 会定时 3 秒向 namenode 发送心跳包.
(2) 如果超过一定时间 630 秒,namenode 没有收到 datanode 的心跳包,就认为它宕机了,此时就会将该 datanode 的块信息交由其它活跃的 datanode 来储存.
(3) 所有的 datanode 会定时 6 小时向 namenode 汇报一次自己完整的块信息,让 namenode 校验更新.
负载均衡:
namenode 会保证所有的 datanode 的资源使用率尽量保持一致.
副本机制:
可以提高容错率,默认的副本数是:3
如果 当前副本总数 > 默认的副本数 ,namenode 会自动删除某个副本.
如果 当前副本总数 < 默认的副本数, namenode 会自动增加该副本.
如果 当前活跃的机器总数 < 默认的副本数,就会强制进入安全模式(safemode),安全模式下:只能读不能写.
2、HDFS 特点
(1) HDFS 文件系统可存储超大文件,时效性稍差.
(2) HDFS 具有硬件故障检测和自动快速恢复功能.
(3) HDFS 为数据存储提供很强的扩展能力.
(4) HDFS 存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改.
(5) HDFS 可在廉价的机器上运行.
四、 Hadoop 之 MapReduce 初体验
Hadoop框架提供了MapReduce的测试包, 具体如下
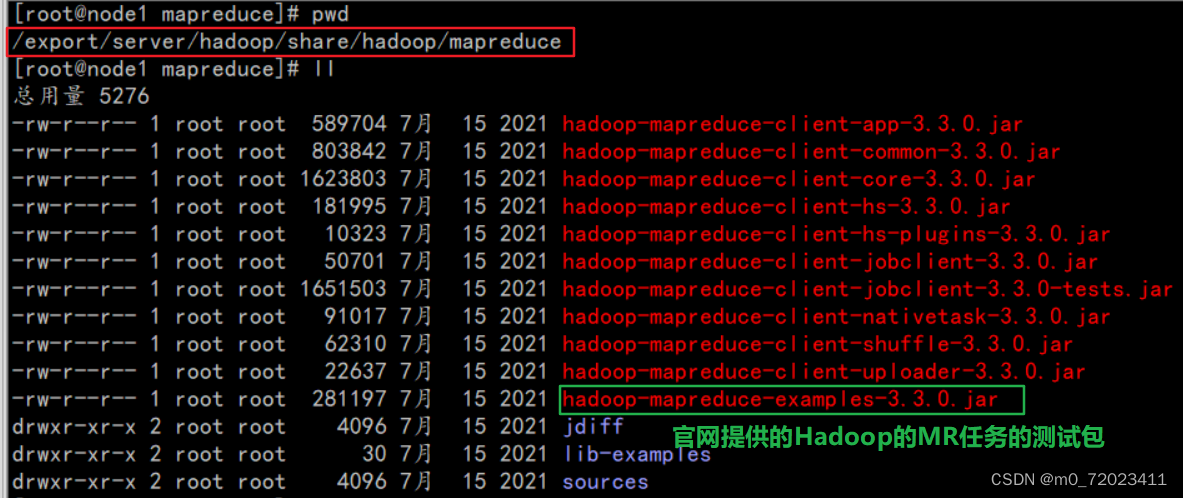
1、使用上述的测试包, 计算圆周率
建议cd先进入到Hadoop提供的MR的测试包所在的路径下
#进入到 Hadoop 提供的 MR 测试包所在路径
cd /export/server/hadoop/share/hadoop/mapreduce
#执行 MR 包计算任务
yarn jar hadoop-mapreduce-examples-3.3.0.jar pi 2 50
格式解释:
yarn jar 固定格式, 说明要把某个jar包交给yarn调度执行.
hadoop-mapreduce-examples-3.3.0.jar Hadoop 提供的MR任务的测试包
pi 要执行的任务名
2 表示MapTask的任务数, 即: 几个线程来做这个事儿.
50 投点数, 越大, 计算结果越精准.
(圆周率计算底层用的是:蒙特卡洛算法)
运行结果:
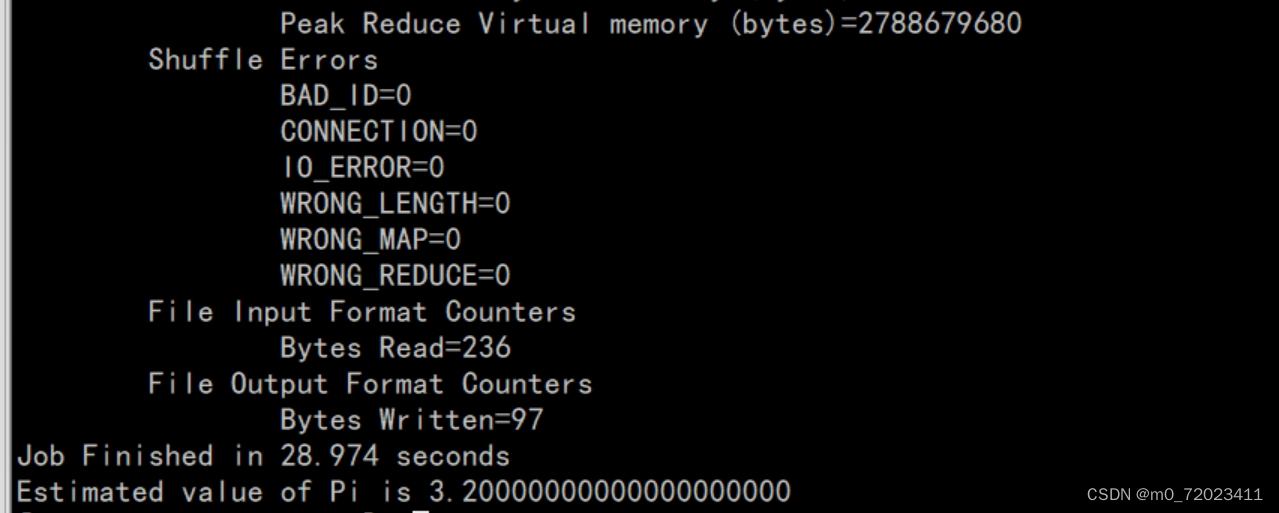
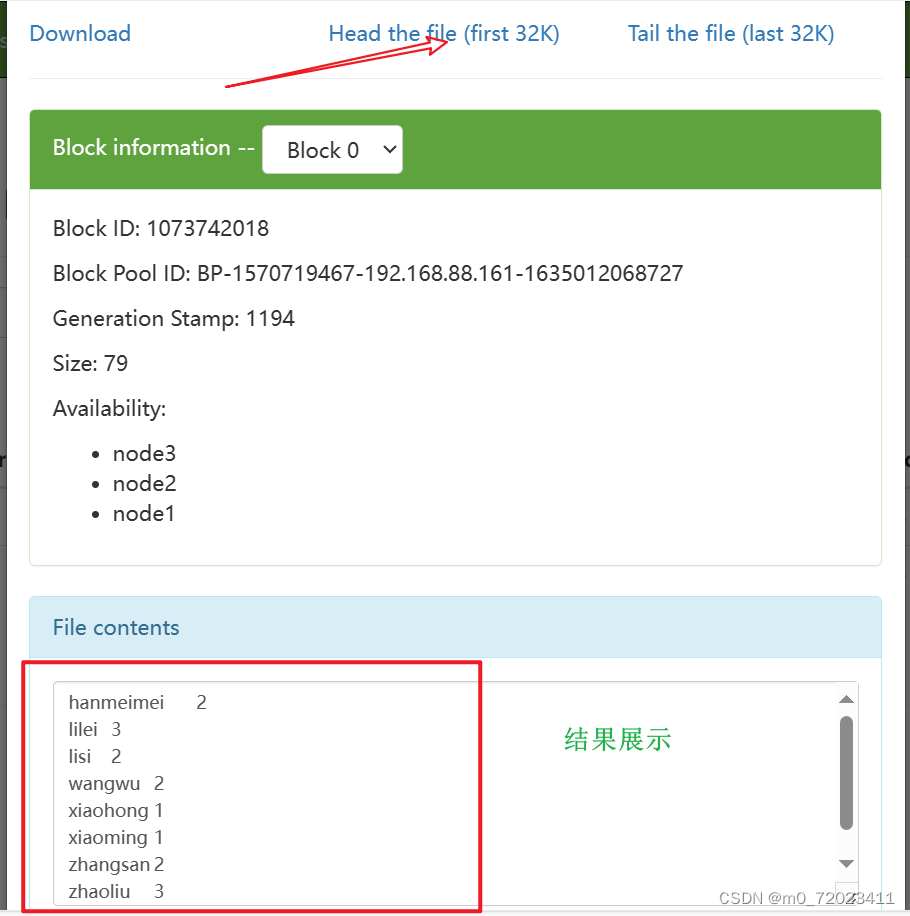
2、使用上述的测试包, 进行词频统计
# 使用 MR 包进行词频统计
yarn jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input/word.txt
/output
结果展示:


版权归原作者 m0_72023411 所有, 如有侵权,请联系我们删除。