
一、随机现象
随机现象在某时刻t的取值是一个向量随机变量,用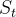,表示,所有可能的状态组成状态集合S。随机现象便是状态的变化过程。在某时刻t的状态 ,通常取决于 时刻之前的状态。我们将已知历史信息(,....,)时下一个时刻的状态为S的概率表示成P(|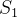,....,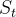)。
二、马尔可夫性质
当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质,用公式表示为。也就是说,下一刻状态只取决于当前状态,而不会受到之前状态的影响。
马尔可夫性质可以大大的简化运算,因为只要已知当前状态信息就可以求未来状态。但是,这并不意味着具有马尔可夫性质的这个随机过程与历史完全没有关系。因为虽然t+1时刻的状态只与t时刻有关,但是t时刻的状态与t-1时刻的状态有关,通过这种链式关系,历史信息就被传递到了现在。
三、马尔可夫过程
马尔可夫过程(Markov process)指具有马尔可夫性质的随机过程,也被称为马尔可夫链(Markov chain)。我们通常用有限状态集合S和状态转移矩阵P的集合来描述这一个过程。
有限状态集合
状态转移矩阵 
矩阵P中的第i行第j列的元素,表示从状态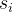到状态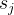的概率,我们称为状态转移概率。从某个状态出发到其他的概率和为1,这点我们也可以从马尔可夫的一个简单例子中体会到。
由下图可知up状态转移到其它状态的概率和为1,P(up|up)+P(down|up)+P(unch|up)=1
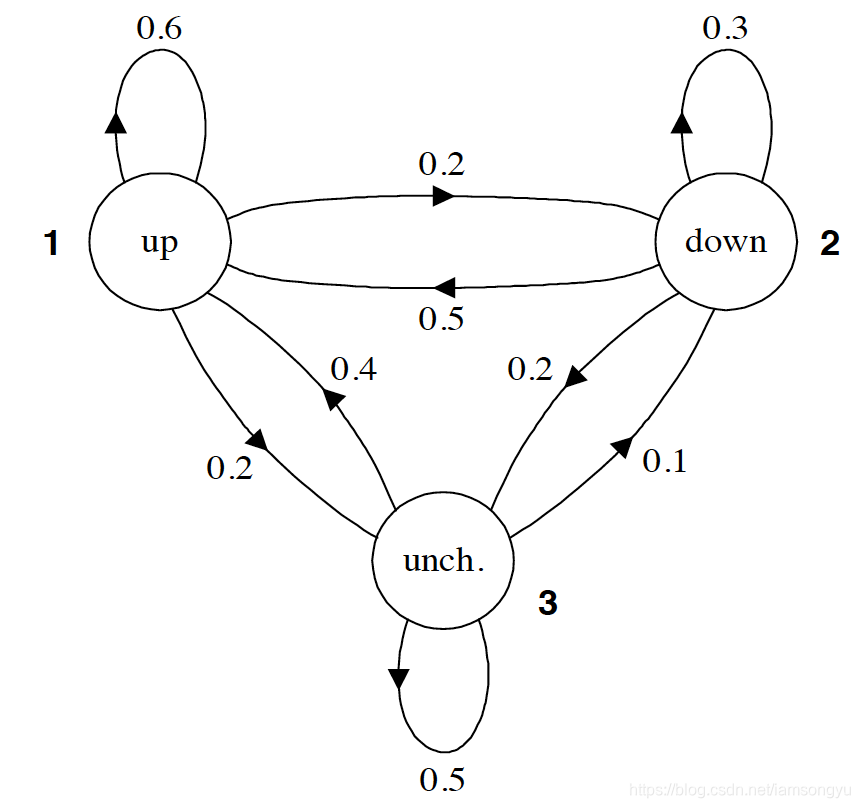
图.马尔可夫过程例子
四、马尔可夫奖励过程
在马尔可夫过程的基础上加入奖励函数r和折扣因子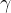构成,就可以得到马尔可夫奖励过程(Markon reward process,MRP)。一个马尔可夫奖励过程由构成,各个元素含义如下:
- S是有限状态集合
- P是状态转移矩阵
- r是奖励函数,某个状态s的奖励r(s)指转移到该状态时可以获得的奖励期望
是折扣因子,取值范围为[0,1)。。引入折扣因子是因为远期利益具有一定的不确定性,有时我们更希望能够尽快获得一些奖励,所以需要对远期利益打一些折扣。接近1的Y更关注长期的累积奖励,接近0的Y更考虑短期奖励。
回报:
** **在一个马尔可夫奖励过程中,从第 t时刻状态 ,开始,直到终止状态时,所有奖励的变减之和称为回报 (Retur),公式如下:
其中,R表示在时刻t获得的奖励。

** 图.马尔可夫奖励过程例子**
如果选取 为起始状态,设置
=0.5,采样到一条状态序列为class1
class2
class3
pass
sleep,就可以计算
的回报
,得到:
价值函数:
在马尔可夫奖励过程中,一个状态的期望回报被称为这个状态的价值 (vale),的价值就组成了价值函数 (value function),价值函数的输入为某个状态,输出为这值。我们将价值函数写成![V(s)=E\left [ G_t|S_t=s \right ]](https://latex.csdn.net/eq?V%28s%29%3DE%5Cleft%20%5B%20G_t%7CS_t%3Ds%20%5Cright%20%5D),展开为:

图.价值函数展开式
在上式的最后一个等式中,一方面,即时奖励的期望正是奖励函数的输出,即![E\left [ R_t|S_t=s \right ]=r(s)](https://latex.csdn.net/eq?E%5Cleft%20%5B%20R_t%7CS_t%3Ds%20%5Cright%20%5D%3Dr%28s%29),另一方面,等式中的剩余部分![E\left [ \gamma V\left ( S_(t+1)|S_t=s \right ) \right ]](https://latex.csdn.net/eq?E%5Cleft%20%5B%20%5Cgamma%20V%5Cleft%20%28%20S_%28t+1%29%7CS_t%3Ds%20%5Cright%20%29%20%5Cright%20%5D)可以根据从状态s出发的转移概率得到,即可以得到:
上式就是马尔可夫奖励过程中非常有名的贝尔曼方程(Bellman equation),对每一个状态都成立。
** 五、马尔可夫决策过程**
** **马尔可夫过程和马尔可夫奖励过程都是自发改变的随机过程,而如果有一个外界的“刺激”来共同改变这个随机过程,就有了马尔可夫决策过程(Markov decisionprocess,MDP)。我们将这个来自外界的刺激称为智能体 (agent)的动作,在马尔可夫奖励过程(MRP)的基础上加入动作,就得到了马尔可夫决策过程(MDP)。马尔可夫决策过程由元组(S,A,P,r,)构成,其中:
- S是状态的集合:
- A是动作的集合:
- r(s,a)是奖励函数,此时奖励可以同时取决于状态s 和动作a,在奖励函数只取决于状态s时,则退化为r(s):
是状态转移函数,表示在状态s执行动作a之后到达状态
的概率
策略:
策略是指从状态和动作到动作选择概率之间的映射,常用符号元表示,它是指给定状态s时,动作集上的一个概率分布,即。简单来说就是在状态s上发生动作a的概率
。
- 策略完全地表示Agent的运动(行为方式和概率)。
- 策略决定于当前状态,与历史状态无关。
- 可能是一个查找表,也可能是一个函数。
- 确定性策略:
或
。
- 随机策略:
。
状态价值函数:
状态价值函数也简称为状态值函数或值函数,是确定Agent在策略元 下处于某一特定状态 s 的最佳程度,即在遵循策略元下从s开始获得的未来期望回报,表示为: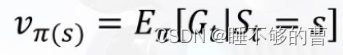
根据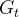的表达式,可以得到: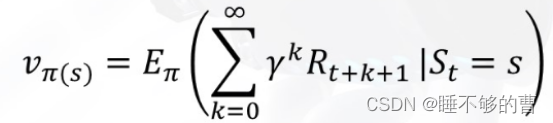
状态-动作价值函数 (动作值函数,O函数)
** **状态-动作价值函数也简称为动作值函数,也称作Q区数,用于表明遵循策略在某一状态执行特定动作的最信程度,即在遵循策略
在状态s执行动作a之后获得的未来期望回报:

根据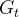,的表达式,可以得到: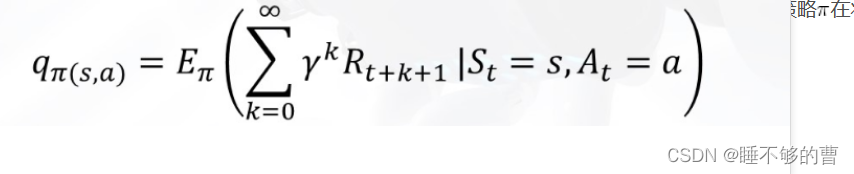
下面可以结合几张图片理解一下状态值函数和动作值函数。
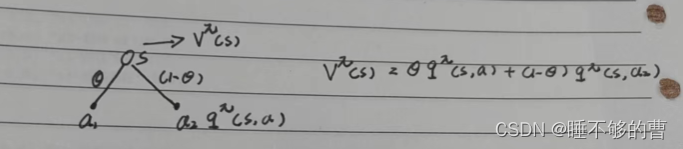
其中空心代表状态,实心代表动作,s的概率为
,s
的概率为
,那么由状态s
动作
的期望值为

其中空心代表状态,实心代表动作,那么动作状态
的期望值
,动作
的期望值
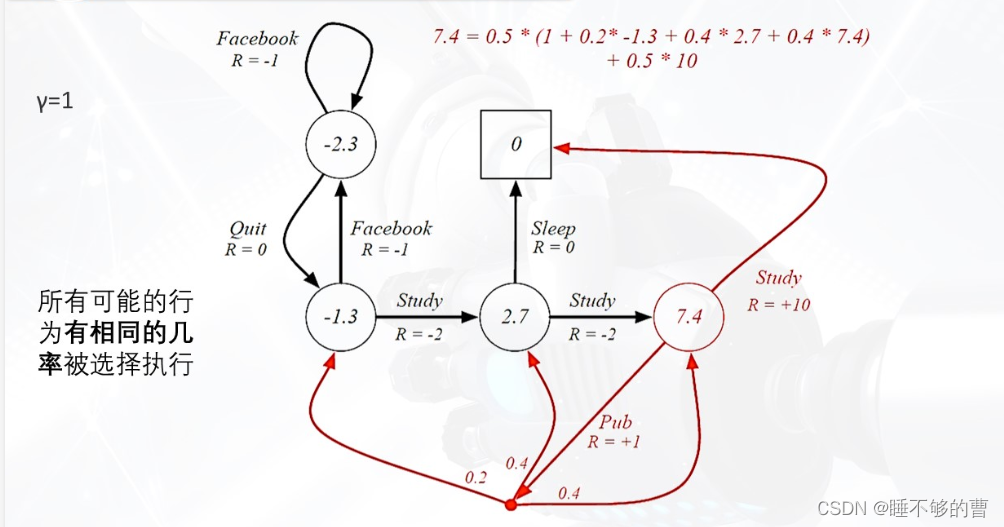
题中所示,7.4所处的状态值到动作红点和状态0的概率为0.5,那么根据其状态值函数,可以求得7.4=0.5(1+0.2(-1.3)+0.42.7+0.47.4)+0.5*10。
版权归原作者 睡不够的曹 所有, 如有侵权,请联系我们删除。