
《Kafka权威指南》序列化章节中有对AVRO序列化的代码实现,刚好工作中遇到相关知识,运行下书中的代码,了解下 模式注册表(Schema Registry)
Confluent Schema Registry的使用
在工作中使用传统的 avro API 自定义序列化类和反序列化类 结果就是在每条Kafka记录里都嵌入了schema,这会让记录的大小成倍地增加。不管怎样,在读取记录时仍然需要用到整个 schema,所以要先找到 schema。有没有什么方法可以让数据共用一个schema?
遵循通用的结构模式并使用"schema注册表"来达到目的。"schema注册表"的原理如下:
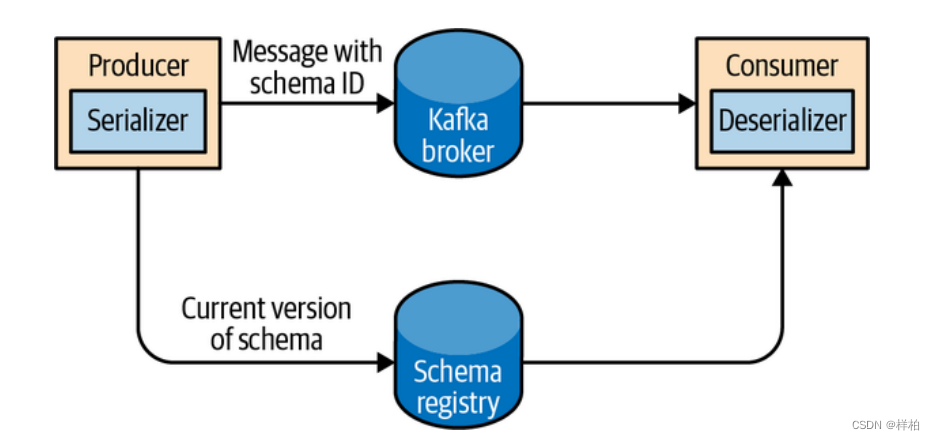
把所有写入数据需要用到的 schema 保存在注册表里,然后在记录里引用 schema 的 ID。负责读取数据的应用程序使用 ID 从注册表里拉取 schema 来反序列化记录。序列化器和反序列化器分别负责处理 schema 的注册和拉取。
schema注册表并不属于Kafka,现在已经有一些开源的schema 注册表实现。比如本文要讨论的Confluent Schema Registry。
安装和使用参考: 这里
步骤:用curl 把 schema 中的内容注册到 Confluent Schema Registry 中,Kafka Producer 和 Kafka Consumer 通过识别 Confluent Schema Registry 中的 schema 内容来序列化和反序列化。
schema
{"type":"record","name":"User","fields":[{"name":"id","type":"int"},{"name":"name","type":"string"},{"name":"age","type":"int"}]}
部分需要转义
{"schema": "{
\"type\": \"record\",
\"name\": \"User\",
\"fields\":[{\"name\": \"id\", \"type\": \"int\"},{\"name\": \"name\", \"type\": \"string\"},{\"name\": \"age\", \"type\": \"int\"}]}"
}
放入 - -data中
curl -X POST -H"Content-Type: application/vnd.schemaregistry.v1+json" \
--data '{"schema":"{\"type\": \"record\", \"name\": \"User\", \"fields\": [{\"name\": \"id\", \"type\": \"int\"}, {\"name\": \"name\", \"type\": \"string\"}, {\"name\": \"age\", \"type\": \"int\"}]}"}' \
http://192.168.42.89:8081/subjects/dev3-yangyunhe-topic001-value/versions
地址栏:http://nn1.hadoop:8081/subjects/ ${topicName} /versions
Producer代码:
packagecom.registry.producerimportcom.registry.utils.SchemaUtilsimportorg.apache.avro.generic.{GenericData,GenericRecord}importorg.apache.kafka.clients.producer.{KafkaProducer,Producer,ProducerRecord}importjava.util.{Properties,Random}/**
* @describe: -
* @author: Wang Yang
* @createDate: 2022/6/11 19:12
*/
object ConfluentProducer{
def main(args:Array[String]):Unit={
val props =newProperties
props.put("bootstrap.servers","nn1.hadoop:9092")
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer")// 使用Confluent实现的KafkaAvroSerializer
props.put("value.serializer","io.confluent.kafka.serializers.KafkaAvroSerializer")// 添加schema服务的地址,用于获取schema
props.put("schema.registry.url","http://nn1.hadoop:8081")
val topic ="test01"
val producer =newKafkaProducer[String,GenericRecord](props)
val rand =newRandomfor(i <-0 until 100){
val name ="name"+ i
val age = rand.nextInt(40)+1
val user =newGenericData.Record(SchemaUtils.getSchema(topic))
user.put("id", i)
user.put("name", name)
user.put("age", age)
val record=newProducerRecord[String,GenericRecord](topic, user)
producer.send(record)System.out.println("send:"+"id:"+ i +",name"+ name +",age"+ age)Thread.sleep(1000)}}}
Schema工具类代码:
packagecom.registry.utilsimportio.confluent.kafka.schemaregistry.client.{CachedSchemaRegistryClient,SchemaMetadata}importorg.apache.avro.Schema/**
* @describe: SchemaUtils
* @author: Wang Yang
* @createDate: 2022/6/11 20:10
*/
object SchemaUtils{var topicSchema:Map[String,Schema]=Map[String,Schema]()//topic1,topic2 ...var topicList ="test01"//调用Registry服务接口 获取schema
val Client=newCachedSchemaRegistryClient("http://nn1.hadoop:8081",100)private val topics = topicList.split(",")putSchema(Client, topics)//通过topic名字获取topic名的 schema
def getSchema(topic:String):Schema=topicSchema(topic)//放入topic
def putSchema(client:CachedSchemaRegistryClient, topics:Array[String]):Unit={for(topic <- topics){
val metadata = client.getLatestSchemaMetadata(topic)
val schema =newSchema.Parser().parse(metadata.getSchema)
topicSchema +=(topic -> schema)}}}
Consumer代码:这个例子由 sparkStreaming 改写
packagecom.registry.consumerimportorg.apache.avro.generic.GenericRecordimportorg.apache.kafka.clients.consumer.{ConsumerConfig,ConsumerRecord}importorg.apache.spark.SparkConfimportorg.apache.spark.streaming.dstream.InputDStreamimportorg.apache.spark.streaming.kafka010.{ConsumerStrategies,ConsumerStrategy,KafkaUtils,LocationStrategies,LocationStrategy}importorg.apache.spark.streaming.{Durations,StreamingContext}importscala.collection.mutable/**
* @describe: ConfluentConsumer
* @author: Wang Yang
* @createDate: 2022/6/11 20:36
*
* 这里使用的是kafka2.11版本
*/
object ConfluentConsumer{
def main(args:Array[String]):Unit={
val conf:SparkConf=newSparkConf().setMaster("local[10]").set("spark.ui.port","8086").setAppName("TestConfluentConsumer")
val ssc:StreamingContext=newStreamingContext(conf,Durations.seconds(2))
ssc.sparkContext.setLogLevel("WARN")// 读取kafka的配置
val kafkaParams =newmutable.HashMap[String,Object]()
kafkaParams +="bootstrap.servers"->"nn1.hadoop:9092"
kafkaParams +="group.id"->"default"
kafkaParams +="enable.auto.commit"->"true"
kafkaParams +="auto.offset.reset"->"earliest"
kafkaParams +="schema.registry.url"->"nn1.hadoop:8081"
kafkaParams +=ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG ->"org.apache.kafka.common.serialization.StringDeserializer"//这里使用的包是 kafka-avro-serializer-4.1.1.jar
kafkaParams +=ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG ->"io.confluent.kafka.serializers.KafkaAvroDeserializer"
val topic ="test01"
val locationStrategy:LocationStrategy=LocationStrategies.PreferConsistent
val consumerStategy:ConsumerStrategy[String,GenericRecord]=ConsumerStrategies.Subscribe[String,GenericRecord](topic.split(",").toSet, kafkaParams)
val kafkaDS:InputDStream[ConsumerRecord[String,GenericRecord]]=KafkaUtils.createDirectStream(ssc, locationStrategy, consumerStategy)
kafkaDS.foreachRDD((records, t)=>{//records里包含了一批数据
records.foreach(record=>{
val user =record.value()println(s"time:${t} ---- value = [user.id = "+ user.get("id")+", "+"user.name = "+ user.get("name")+", "+"user.age = "+ user.get("age")+"], "+"partition = "+record.partition +", "+"offset = "+record.offset)})println(s"time:${t}")})
ssc.start()
ssc.awaitTermination()}}
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.wy.cn</groupId><artifactId>avrodemo</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.1.1</version><scope>compile</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.11</artifactId><version>2.1.1</version><scope>compile</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>2.1.1</version><scope>compile</scope></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.6.5</version></dependency><dependency><groupId>org.apache.avro</groupId><artifactId>avro</artifactId><version>1.8.1</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.3.0</version></dependency><!-- 版本过低 --><!--<!– 此依赖下面指定了仓库来源 –>--><!-- <dependency>--><!-- <groupId>io.confluent</groupId>--><!-- <artifactId>kafka-avro-serializer</artifactId>--><!-- <version>1.0</version> <!– Also tried 2.0-SNAPSHOT –>--><!-- </dependency>--></dependencies><repositories><repository><id>confluent</id><url>http://packages.confluent.io/maven/</url></repository></repositories></project>
本文转载自: https://blog.csdn.net/weixin_45101742/article/details/125238419
版权归原作者 样柏 所有, 如有侵权,请联系我们删除。
版权归原作者 样柏 所有, 如有侵权,请联系我们删除。