
- 🔗 运行环境:python3
- 🚩 作者:K同学啊
- 🥇 精选专栏:《深度学习100例》
- 🔥 推荐专栏:《零基础入门深度学习》
- 📚 选自专栏:《Matplotlib教程》
- 🧿 优秀专栏:《Python入门100题》
大家好,我是K同学啊!
今天和大家分享一篇 本科毕设 实战项目,项目中我将使用
VGG16
、
InceptionV3
、
DenseNet121
、
MobileNetV2
等四个模型进行对比分析(文中提供了每一个模型的 算法框架图),最后可以自选图片进行预测,最后的识别效果高达
99.2%
。结果如下:

文章目录
一、导入数据
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory("./1-data/",
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 1308 files belonging to 14 classes.
Using 1047 files for training.
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory("./1-data/",
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 1308 files belonging to 14 classes.
Using 261 files for validation.
class_names = train_ds.class_names
print(class_names)
['15', '16', '17', '20', '22', '23', '24', '26', '27', '28', '29', '30', '31', '32']
train_ds
<BatchDataset shapes: ((None, 224, 224, 3), (None,)), types: (tf.float32, tf.int32)>
AUTOTUNE = tf.data.AUTOTUNE
# 归一化deftrain_preprocessing(image,label):return(image/255.0,label)
train_ds =(
train_ds.cache().map(train_preprocessing)# 这里可以设置预处理函数.prefetch(buffer_size=AUTOTUNE))
val_ds =(
val_ds.cache().map(train_preprocessing)# 这里可以设置预处理函数.prefetch(buffer_size=AUTOTUNE))
plt.figure(figsize=(10,8))# 图形的宽为10高为5for images, labels in train_ds.take(1):for i inrange(15):
plt.subplot(4,5, i +1)
plt.xticks([])
plt.yticks([])
plt.grid(False)# 显示图片
plt.imshow(images[i])# 显示标签
plt.xlabel(class_names[int(labels[i])])
plt.show()

二、定义模型
1. VGG16模型
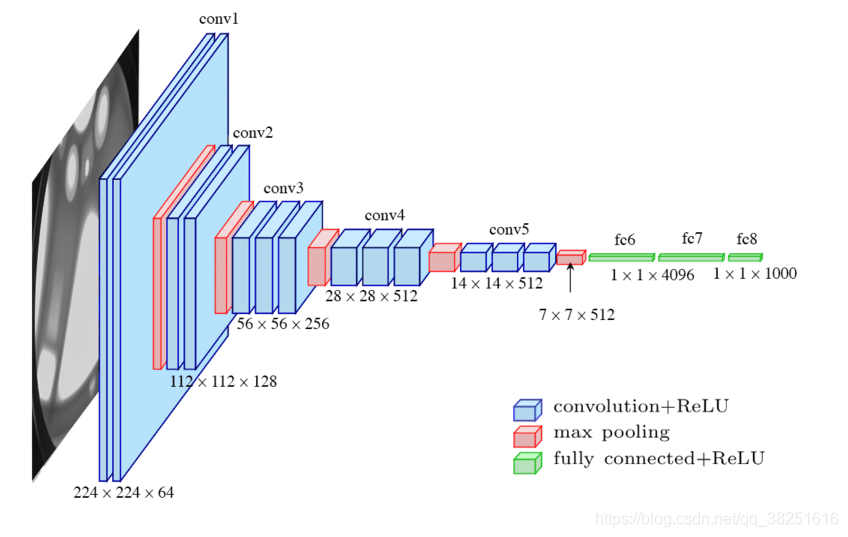
# 加载预训练模型
vgg16_base_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,# input_tensor=tf.keras.Input(shape=(img_width, img_height, 3)),
input_shape=(img_width, img_height,3),
pooling='max')for layer in vgg16_base_model.layers:
layer.trainable =False
X = vgg16_base_model.output
X = Dropout(0.4)(X)
output = Dense(len(class_names), activation='softmax')(X)
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer="adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])# vgg16_model.summary()
vgg16_history = vgg16_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/10
33/33 [==============================] - 8s 113ms/step - loss: 2.7396 - accuracy: 0.2531 - val_loss: 1.4678 - val_accuracy: 0.6092
Epoch 2/10
33/33 [==============================] - 2s 45ms/step - loss: 1.5873 - accuracy: 0.5091 - val_loss: 0.8500 - val_accuracy: 0.8046
Epoch 3/10
33/33 [==============================] - 2s 45ms/step - loss: 1.0996 - accuracy: 0.6495 - val_loss: 0.5299 - val_accuracy: 0.9272
Epoch 4/10
33/33 [==============================] - 2s 45ms/step - loss: 0.7349 - accuracy: 0.7947 - val_loss: 0.3765 - val_accuracy: 0.9349
Epoch 5/10
33/33 [==============================] - 2s 45ms/step - loss: 0.5373 - accuracy: 0.8481 - val_loss: 0.2888 - val_accuracy: 0.9502
Epoch 6/10
33/33 [==============================] - 2s 45ms/step - loss: 0.4326 - accuracy: 0.8892 - val_loss: 0.2422 - val_accuracy: 0.9617
Epoch 7/10
33/33 [==============================] - 2s 45ms/step - loss: 0.3350 - accuracy: 0.9198 - val_loss: 0.2068 - val_accuracy: 0.9693
Epoch 8/10
33/33 [==============================] - 2s 45ms/step - loss: 0.2821 - accuracy: 0.9398 - val_loss: 0.1713 - val_accuracy: 0.9885
Epoch 9/10
33/33 [==============================] - 2s 45ms/step - loss: 0.2489 - accuracy: 0.9456 - val_loss: 0.1589 - val_accuracy: 0.9847
Epoch 10/10
33/33 [==============================] - 2s 48ms/step - loss: 0.2146 - accuracy: 0.9608 - val_loss: 0.1511 - val_accuracy: 0.9885
2. InceptionV3模型
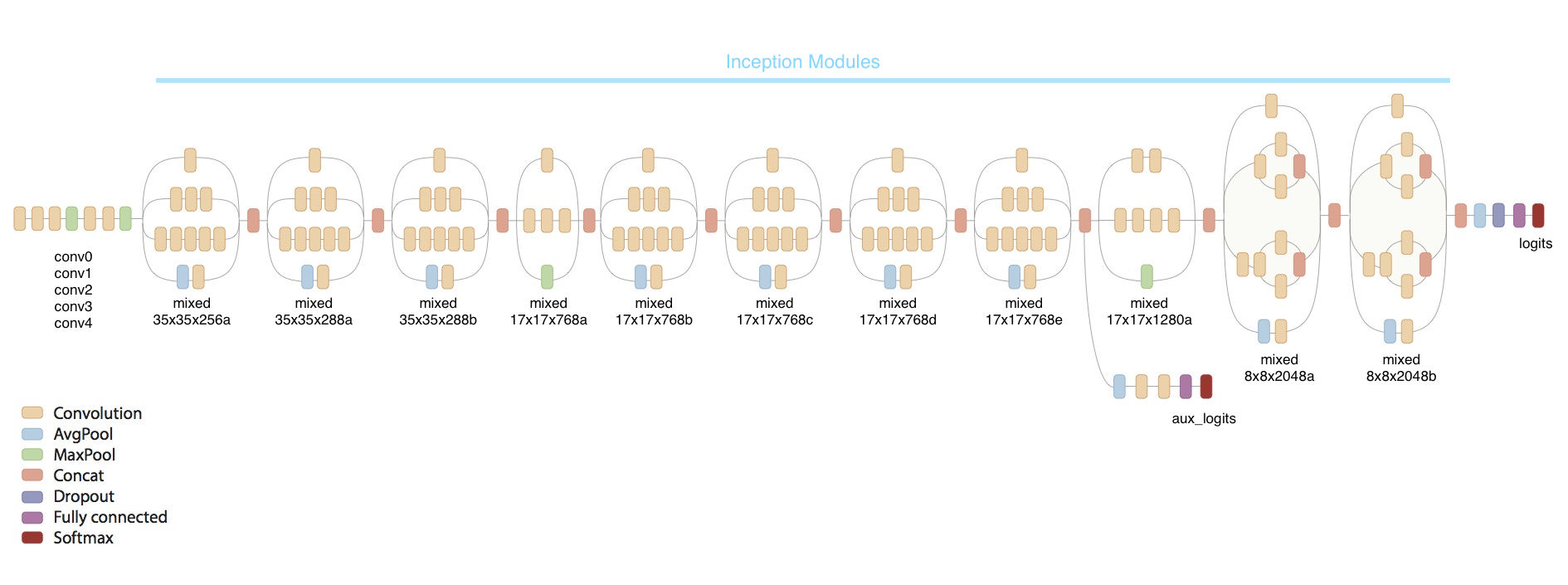
# 加载预训练模型
InceptionV3_base_model = tf.keras.applications.inception_v3.InceptionV3(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height,3),
pooling='max')for layer in InceptionV3_base_model.layers:
layer.trainable =False
X = InceptionV3_base_model.output
X = Dropout(0.4)(X)
output = Dense(len(class_names), activation='softmax')(X)
InceptionV3_model = Model(inputs=InceptionV3_base_model.input, outputs=output)
InceptionV3_model.compile(optimizer="adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])# InceptionV3_model.summary()
InceptionV3_history = InceptionV3_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/10
33/33 [==============================] - 5s 82ms/step - loss: 3.1642 - accuracy: 0.4040 - val_loss: 0.6005 - val_accuracy: 0.8352
Epoch 2/10
33/33 [==============================] - 1s 34ms/step - loss: 0.7241 - accuracy: 0.8042 - val_loss: 0.2476 - val_accuracy: 0.9234
Epoch 3/10
33/33 [==============================] - 1s 34ms/step - loss: 0.3558 - accuracy: 0.8949 - val_loss: 0.2323 - val_accuracy: 0.9425
Epoch 4/10
33/33 [==============================] - 1s 35ms/step - loss: 0.2435 - accuracy: 0.9226 - val_loss: 0.1599 - val_accuracy: 0.9617
Epoch 5/10
33/33 [==============================] - 1s 34ms/step - loss: 0.1444 - accuracy: 0.9551 - val_loss: 0.1246 - val_accuracy: 0.9617
Epoch 6/10
33/33 [==============================] - 1s 34ms/step - loss: 0.1508 - accuracy: 0.9522 - val_loss: 0.1231 - val_accuracy: 0.9732
Epoch 7/10
33/33 [==============================] - 1s 35ms/step - loss: 0.0793 - accuracy: 0.9761 - val_loss: 0.0853 - val_accuracy: 0.9885
Epoch 8/10
33/33 [==============================] - 1s 35ms/step - loss: 0.0636 - accuracy: 0.9809 - val_loss: 0.1223 - val_accuracy: 0.9732
Epoch 9/10
33/33 [==============================] - 1s 35ms/step - loss: 0.0503 - accuracy: 0.9857 - val_loss: 0.0769 - val_accuracy: 0.9923
Epoch 10/10
33/33 [==============================] - 1s 34ms/step - loss: 0.0346 - accuracy: 0.9904 - val_loss: 0.1066 - val_accuracy: 0.9923
3. DenseNet121算法模型
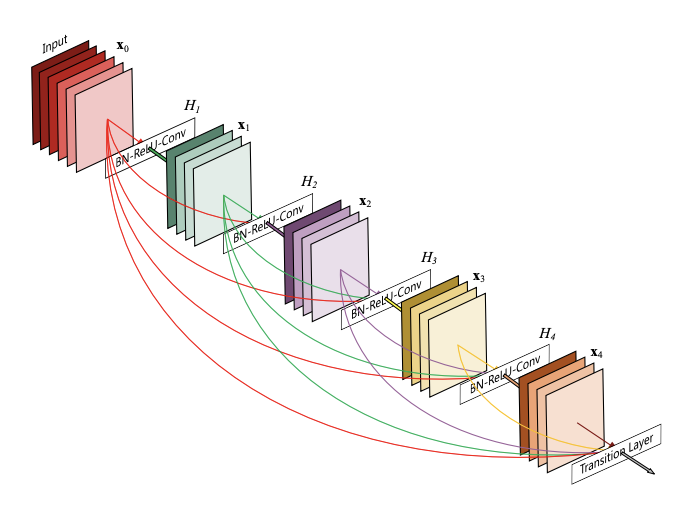
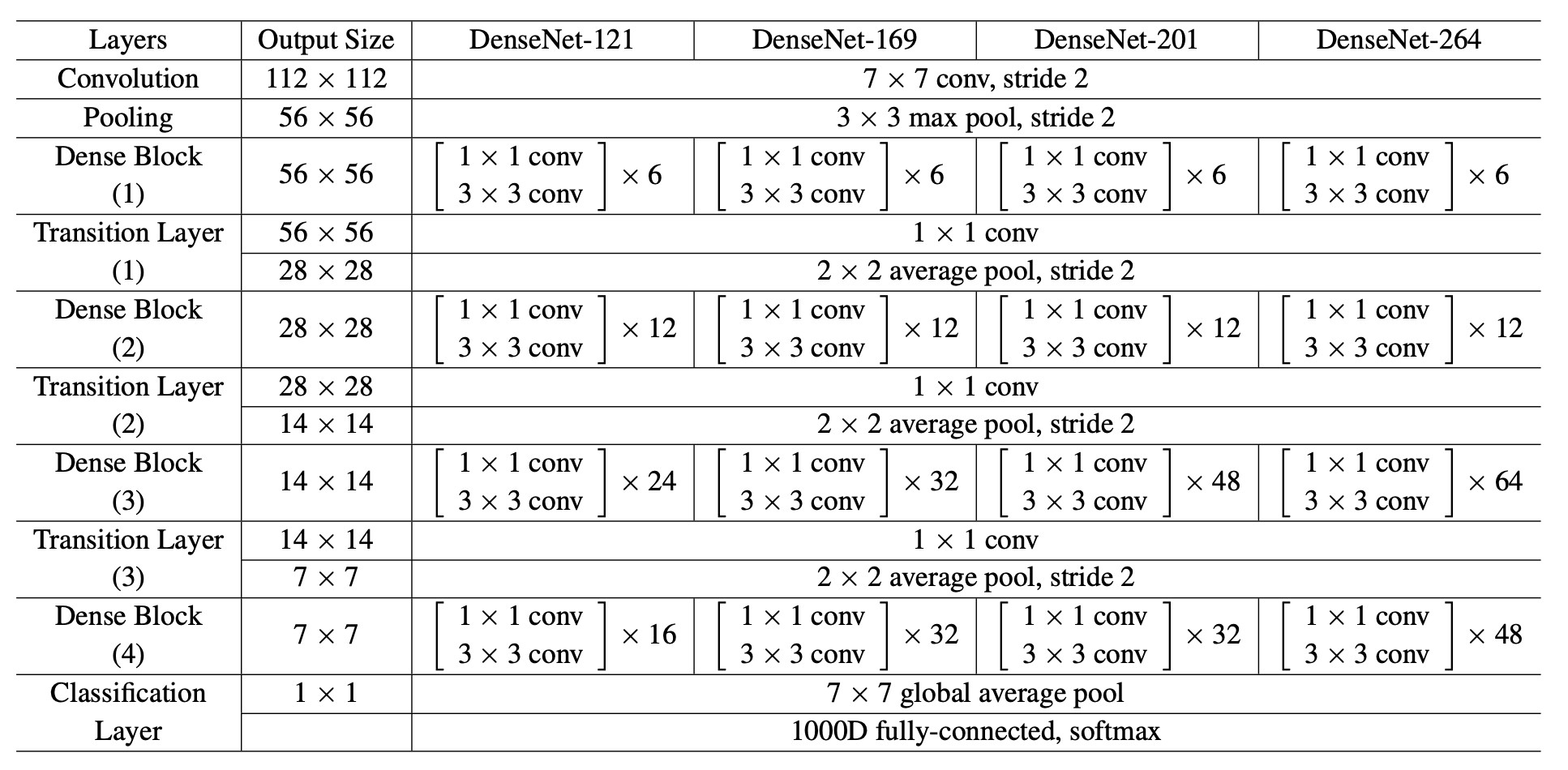
# 加载预训练模型
DenseNet121_base_model = tf.keras.applications.densenet.DenseNet121(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height,3),
pooling='max')for layer in DenseNet121_base_model.layers:
layer.trainable =False
X = DenseNet121_base_model.output
X = Dropout(0.4)(X)
output = Dense(len(class_names), activation='softmax')(X)
DenseNet121_model = Model(inputs=DenseNet121_base_model.input, outputs=output)
DenseNet121_model.compile(optimizer="adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])# model.summary()
DenseNet121_history = DenseNet121_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/10
33/33 [==============================] - 7s 109ms/step - loss: 4.5573 - accuracy: 0.2932 - val_loss: 1.2358 - val_accuracy: 0.6322
Epoch 2/10
33/33 [==============================] - 1s 43ms/step - loss: 2.0711 - accuracy: 0.5482 - val_loss: 0.4970 - val_accuracy: 0.8391
Epoch 3/10
33/33 [==============================] - 1s 41ms/step - loss: 1.2808 - accuracy: 0.6953 - val_loss: 0.2534 - val_accuracy: 0.9042
Epoch 4/10
33/33 [==============================] - 1s 41ms/step - loss: 0.8280 - accuracy: 0.7736 - val_loss: 0.1845 - val_accuracy: 0.9502
Epoch 5/10
33/33 [==============================] - 1s 41ms/step - loss: 0.5928 - accuracy: 0.8300 - val_loss: 0.1211 - val_accuracy: 0.9770
Epoch 6/10
33/33 [==============================] - 1s 41ms/step - loss: 0.4390 - accuracy: 0.8749 - val_loss: 0.1046 - val_accuracy: 0.9808
Epoch 7/10
33/33 [==============================] - 1s 41ms/step - loss: 0.4108 - accuracy: 0.8797 - val_loss: 0.0950 - val_accuracy: 0.9885
Epoch 8/10
33/33 [==============================] - 1s 41ms/step - loss: 0.3137 - accuracy: 0.9102 - val_loss: 0.0662 - val_accuracy: 0.9808
Epoch 9/10
33/33 [==============================] - 1s 41ms/step - loss: 0.2416 - accuracy: 0.9284 - val_loss: 0.0698 - val_accuracy: 0.9885
Epoch 10/10
33/33 [==============================] - 1s 41ms/step - loss: 0.2524 - accuracy: 0.9217 - val_loss: 0.0597 - val_accuracy: 0.9923
4. MobileNetV2算法模型

# 加载预训练模型
MobileNetV2_base_model = tf.keras.applications.mobilenet_v2.MobileNetV2(weights='imagenet',
include_top=False,
input_shape=(img_width, img_height,3),
pooling='max')for layer in MobileNetV2_base_model.layers:
layer.trainable =False
X = MobileNetV2_base_model.output
X = Dropout(0.4)(X)
output = Dense(len(class_names), activation='softmax')(X)
MobileNetV2_model = Model(inputs=MobileNetV2_base_model.input, outputs=output)
MobileNetV2_model.compile(optimizer="adam",
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])#MobileNetV2_model.summary()
MobileNetV2_history = MobileNetV2_model.fit(train_ds, epochs=epochs, verbose=1, validation_data=val_ds)
Epoch 1/10
33/33 [==============================] - 3s 47ms/step - loss: 4.0865 - accuracy: 0.4403 - val_loss: 0.5897 - val_accuracy: 0.8812
Epoch 2/10
33/33 [==============================] - 1s 22ms/step - loss: 1.1042 - accuracy: 0.7536 - val_loss: 0.1841 - val_accuracy: 0.9540
Epoch 3/10
33/33 [==============================] - 1s 22ms/step - loss: 0.6147 - accuracy: 0.8596 - val_loss: 0.1722 - val_accuracy: 0.9770
Epoch 4/10
33/33 [==============================] - 1s 22ms/step - loss: 0.3826 - accuracy: 0.9007 - val_loss: 0.1505 - val_accuracy: 0.9770
Epoch 5/10
33/33 [==============================] - 1s 22ms/step - loss: 0.2290 - accuracy: 0.9370 - val_loss: 0.1408 - val_accuracy: 0.9885
Epoch 6/10
33/33 [==============================] - 1s 22ms/step - loss: 0.1976 - accuracy: 0.9484 - val_loss: 0.1294 - val_accuracy: 0.9923
Epoch 7/10
33/33 [==============================] - 1s 22ms/step - loss: 0.1193 - accuracy: 0.9608 - val_loss: 0.1038 - val_accuracy: 0.9923
Epoch 8/10
33/33 [==============================] - 1s 22ms/step - loss: 0.0859 - accuracy: 0.9675 - val_loss: 0.1140 - val_accuracy: 0.9923
Epoch 9/10
33/33 [==============================] - 1s 22ms/step - loss: 0.0973 - accuracy: 0.9704 - val_loss: 0.1292 - val_accuracy: 0.9923
Epoch 10/10
33/33 [==============================] - 1s 22ms/step - loss: 0.0504 - accuracy: 0.9828 - val_loss: 0.1361 - val_accuracy: 0.9923
三、结果分析
1. 准确率对比分析
# 可在原码中进行阅读
plt.show()

2. 损失函数对比分析
# 可在原码中进行阅读
plt.show()

3. 混淆矩阵
# 可在原码中进行阅读
plot_cm(val_label, val_pre)

4. 评估指标生成
support:当前行的类别在测试数据中的样本总量;precision:被判定为正例(反例)的样本中,真正的正例样本(反例样本)的比例,精度=正确预测的个数(TP)/被预测正确的个数(TP+FP)。recall:被正确分类的正例(反例)样本,占所有正例(反例)样本的比例,召回率=正确预测的个数(TP)/预测个数(TP+FN)。f1-score: 精确率和召回率的调和平均值,F1 = 2精度召回率/(精度+召回率)。accuracy:表示准确率,也即正确预测样本量与总样本量的比值。macro avg:表示宏平均,表示所有类别对应指标的平均值。weighted avg:表示带权重平均,表示类别样本占总样本的比重与对应指标的乘积的累加和。
from sklearn import metrics
deftest_accuracy_report(model):print(metrics.classification_report(val_label, val_pre, target_names=class_names))
score = model.evaluate(val_ds, verbose=0)print('Loss function: %s, accuracy:'% score[0], score[1])
test_accuracy_report(InceptionV3_model)
precision recall f1-score support
15 1.00 1.00 1.00 2
16 1.00 1.00 1.00 28
17 1.00 1.00 1.00 25
20 1.00 0.33 0.50 3
22 1.00 1.00 1.00 4
23 1.00 1.00 1.00 1
24 1.00 1.00 1.00 16
26 1.00 1.00 1.00 32
27 0.71 1.00 0.83 5
28 1.00 1.00 1.00 90
29 1.00 1.00 1.00 5
30 1.00 1.00 1.00 33
31 1.00 1.00 1.00 8
32 1.00 1.00 1.00 9
accuracy 0.99 261
macro avg 0.98 0.95 0.95 261
weighted avg 0.99 0.99 0.99 261
Loss function: 0.10659126937389374, accuracy: 0.992337167263031
四、指定图片进行预测
from PIL import Image
img = Image.open("./1-data/17/017_0001.png")
image = tf.image.resize(img,[img_height, img_width])
img_array = tf.expand_dims(image,0)
predictions = InceptionV3_model.predict(img_array)print("预测结果为:",np.argmax(predictions))
预测结果为: 11
完整资源下载链接1:博主在面包多网站上的完整资源下载页
完整资源下载链接1:https://mianbaoduo.com/o/bread/YpiZmZ5v
本文转载自: https://blog.csdn.net/qq_38251616/article/details/123565790
版权归原作者 K同学啊 所有, 如有侵权,请联系我们删除。
版权归原作者 K同学啊 所有, 如有侵权,请联系我们删除。