
前言
此实验搭建3个虚拟节点,一个mater,一个slave1,一个slave2
集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但在物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
那mapreduce是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
一、集群部署方式
Hadoop部署方式分三种:
1、Standalone mode(独立模式)
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
2、Pseudo-Distributed mode(伪分布式模式)
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
3、Cluster mode(群集模式)单节点模式-高可用HA模式
集群模式主要用于生产环境部署,会使用n台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
二、Hadoop集群规划
Hadoop是典型的主从架构。HDFS的NameNode是主,DataNode是从,YARN的ResourceManager是主,NodeManager是从。在正式集群部署之前,我们首先要做规划,规划好每个主机/节点分别运行Hadoop的哪些进程,这样做,至少有两个好处:1、指导部署,没有规划图,很可能部署过程中就容易迷失,一个小小的细节没处理好,可能导致集群启动失败;2、方便日后查询,例如查询哪些进程在哪些节点上运行等。
此次部署的规划如下:(说明:每个人的虚拟机的IP网段可能都不一样,要根据实际虚拟机修改下表的IP地址,我的是192.168.241.xxx)
Hadoop集群规划
主机IP
主机的主机名
HDFS
YARN
192.168.241.100
master
NameNode
DataNode
ResourceManager
NodeManager
192.168.241.101
slave1
SecondaryNameNode
DataNode
NodeManager
192.168.241.102
slave2
DataNode
NodeManager
2.1集群环境准备
集群模式主要用于生产环境部署,需要多台主机,并且这些主机之间可以相互访问,我们在之前搭建好基础环境的三台虚拟机上进行Hadoop的搭建。
(1)找到之前伪分布式hadoop虚拟机的路径
 (2)创建三个文件夹master、slave1、slave2,然后复制步骤1中找到的虚拟机文件,并分别粘贴一份到这三个文件夹中
(2)创建三个文件夹master、slave1、slave2,然后复制步骤1中找到的虚拟机文件,并分别粘贴一份到这三个文件夹中
(3)用VMware Workstation,打开master、slave1、slave2文件夹下的虚拟机,并重命名,以防万一与之前伪分布式的虚拟机搞混了
2.2修改master、slave1、slave2的ip
master、slave1、slave2这三台虚拟机是从原有的虚拟机拷贝过来的,所有东西都是一样的,包括环境变量、已安装的程序(jdk、redis、hadoop、hbase等)、ip、主机名。而不同的主机,ip肯定不能一样,所以要修改这三台虚拟机的ip和主机名。
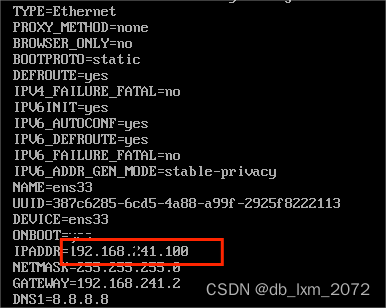
打开网卡配置文件,将IPADDR修改为部署规划的master ip,然后保存退出
代码示例如下:
vi /etc/sysconfig/network-scripts/ifcfg-ens33


ip修改后,重启网卡重启网卡,并验证是否可以访问外网:
代码示例如下:
systemctl restart network
ping www.baidu.com
执行hostnamectl set-hostname ...(master/slave1/slave2),将主机名分别改为master、slave1、slave2
退出root,再重新登录,命令行提示符看到最新的主机名
2.3修改master、slave1、slave2的主机名和IP的映射
我们知道,网络中,都是通过IP来通信的,在集群中,如果想要通过主机名通信,则还要设置IP来与之对应,类似于域名要绑定IP。编辑/etc/hosts这个文件,然后追加一条记录,master、slave1、slave2三个主机的/etc/hosts新增的映射记录一样

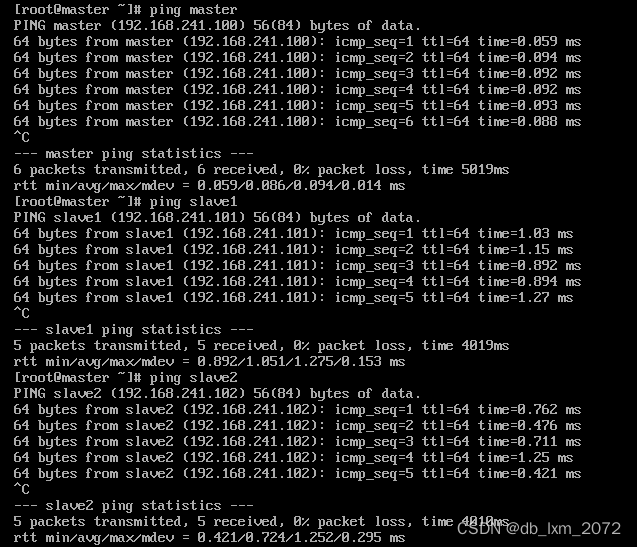
能ping成功三个主机名,说明映射配置成功
提示:为了避免手写错误,master的hosts映射配置好后,可以通过scp命令,将master修改好的/etc/hosts文件,同步到slave1、slave2主机上。

2.4设置免密登录
想要在机器1上,远程控制机器2,常用的方案就是在机器1安装ssh客户端,机器2安装ssh服务端,ssh客户端和ssh服务端之间的通信协议是ssh协议。在linux系统中ssh命令,就是一个ssh客户端程序,sshd服务,就是一个ssh服务端程序。在windows中,给大家提供的mobaxterm是一个图形化界面的ssh客户端。因为master、slave1、slave2三个节点都是从之前的已经安装好Hadoop伪分布式的虚拟机复制而来,而当时已经设置了免密登录,故不需再设置了,也就是master可以免密登录到master、slave1、slave2。
2.5关闭防火墙
防火墙实质是一个程序,它可以控制系统进来或者出去的流量,Centos7默认情况下,防火墙是开机自起的,在集群部署模式下,各个节点之间的进程要通信,为了方便,一般都要关闭防火墙。同理,之前已经设置不允许防火墙开机自启,默认开机是关闭的,故也不需要操作。
2.6删除Hadoop伪分布式数据
因为master、slave1、slave2三个节点都是从之前的已经安装好Hadoop伪分布式的虚拟机复制而来,为了保证整个进程环境干净,我们需要删除这三个节点/usr/local/hadoop-2.7.1/data路径。
2.7修改hadoop配置文件
vi core-site.xml,该配置文件内容如下:
<configuration>
<!-- hdfs分布式文件系统名字/地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--存放namenode、datanode数据的根路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.1/data</value>
</property>
</configuration>
vi hdfs-site.xml,该配置文件内容如下:
<configuration>
<!-- 数据块副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondary namenode 按照规划部署到slave1上 -->
<property>
<name>dfs.secondary.http.address</name>
<value>slave1:50090</value>
</property>
</configuration>
vi yarn-site.xml,该配置文件内容如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
vi mapred-site.xml,该配置文件内容如下:
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
slaves文件里面记录的是集群主机名。一般有以下两种作用:
一是:配合一键启动脚本,如start-dfs.sh、stop-yarn.sh用来进行集群启动,这时候slaves文件里面的主机标记的就是从节点角色所在的机器。
二是:可以配合hdfs-site.xml里面dfs.hosts属性形成一种白名单机制。
dfs.hosts指定一个文件,其中包含允许连接到NameNode的主机列表,必须指定文件的完整路径名,那么所有在slaves中的主机才可以加入的集群中。如果值为空,则允许所有主机。
vi slaves,该配置文件内容如下:
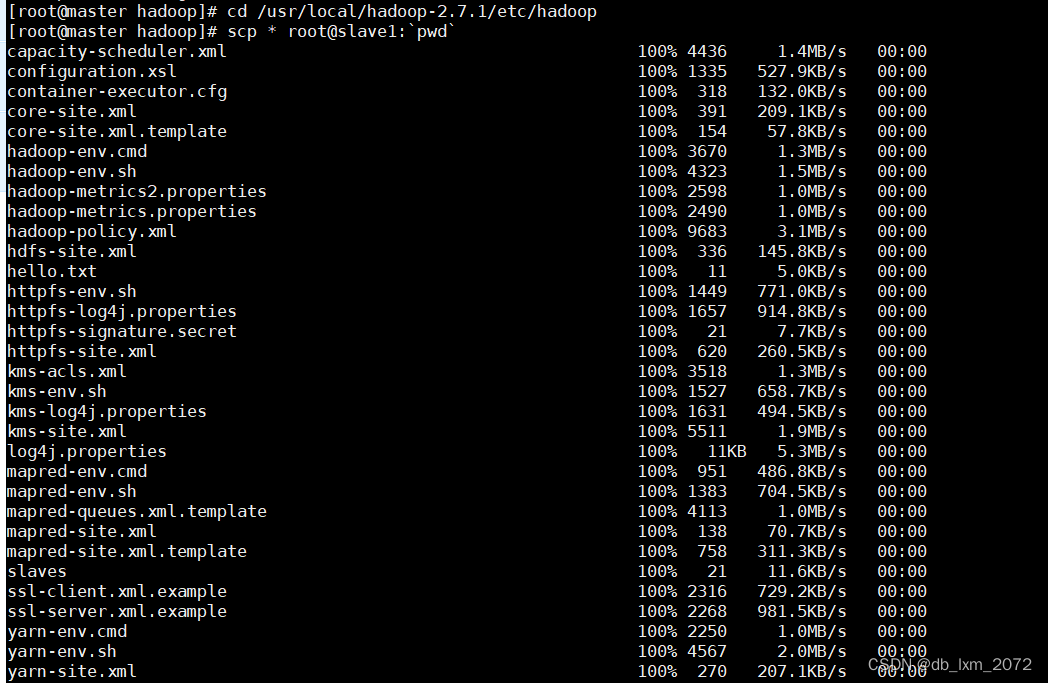
2.8将master主机上的hadoop配置文件,同步到其他两个主机上
scp第一个参数*表示当前路径下的所有文件,第二个参数冒号左边表示目标主机,冒号右边表示目标主机的路径。pwd打印出当前路径
整句命令的作用是将当前路径下的所有文件,以root身份,同步到slave1、slave2的pwd输出的路径下
2.9时间同步
hadoop集群各个节点之间的时间应该一致,也就是master当前时间如果是2023-01-01 01:01:01,那么slave1和slave2上也应该是这个时间,如果各个节点之间时间不一致/不同步,那么集群就会出现一些错误。ntp(Network Time Protocol,网络时间协议)是一种跟时间设置相关的协议。客户端-服务端架构,ntp.api.bz是一个公开的ntp服务器,执行ntpdate ntp.api.bz命令,可以从这个ntp服务器拉取时间并更新当前机器的时间。在master、slave1、slave2上分别执行该命令,即可完成时间同步,此时三个节点的时间应该是一致的。

2.10NameNode格式化
格式化只需格式化一次,以后启动Hadoop集群时,不需要再格式化。
在master上执行格式化命令:hdfs namenode -format
2.11hadoop集群的启动和停止
启动:start-all.sh
停止:stop-all.sh
master启动了四个进程,与规划表对应

slave1启动了三个进程,与规划表对应
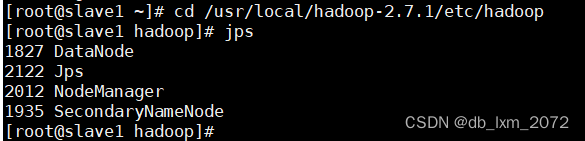
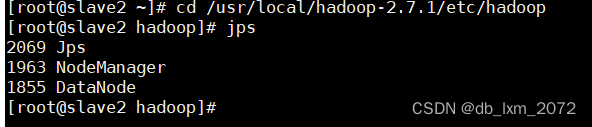
slave2启动了三个进程,与规划表对应
2.12查看hdfs的web管理页面
浏览器访问master的50070端口:http://192.168.1241.100:50070
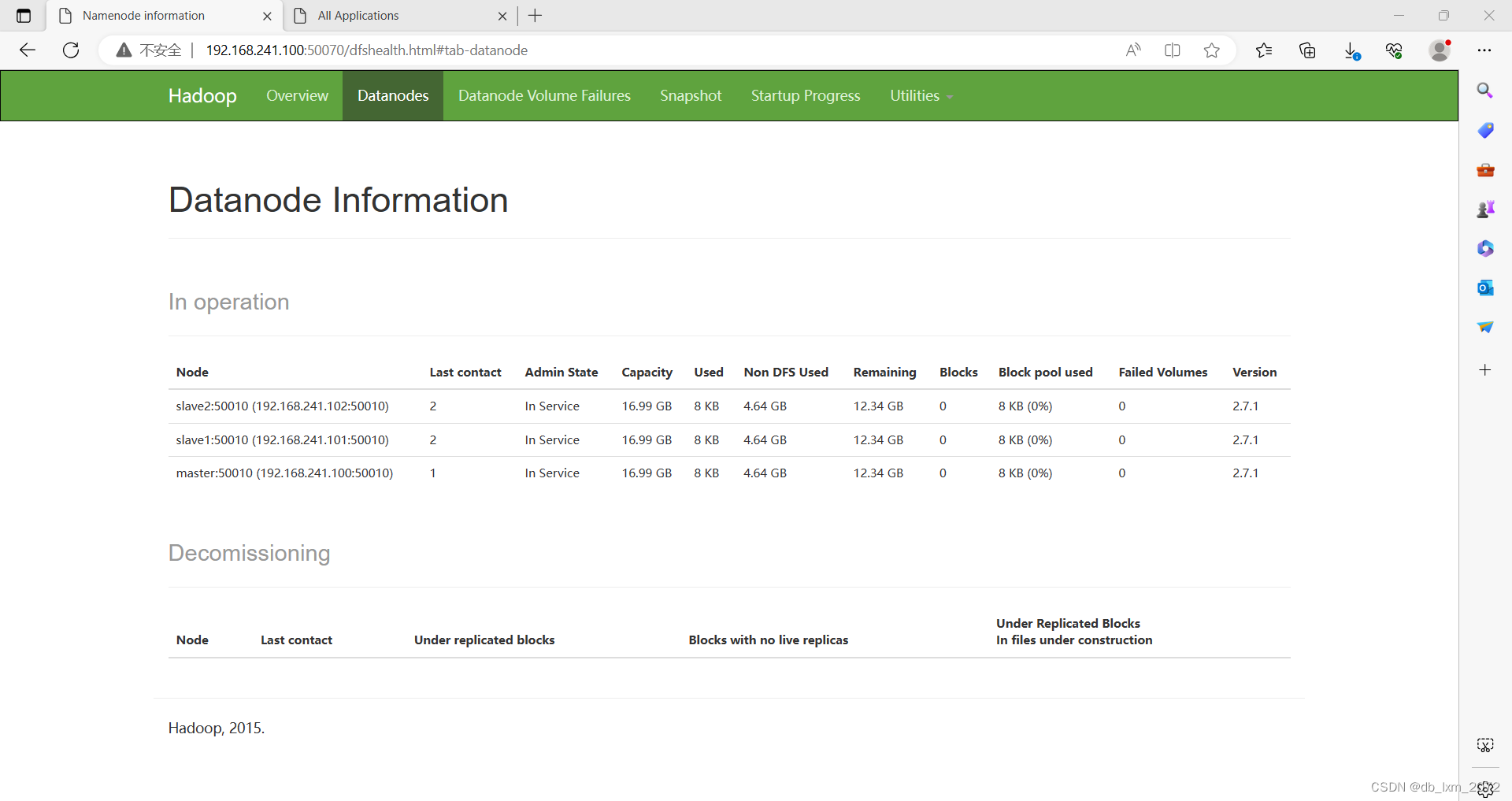
可以看到hdfs有三个datanode节点,没有节点可用的磁盘空间是 16.99GB
2.13查看yarn的web管理页面
验证是否部署成功
192.168.241.100:8088/cluster/nodes
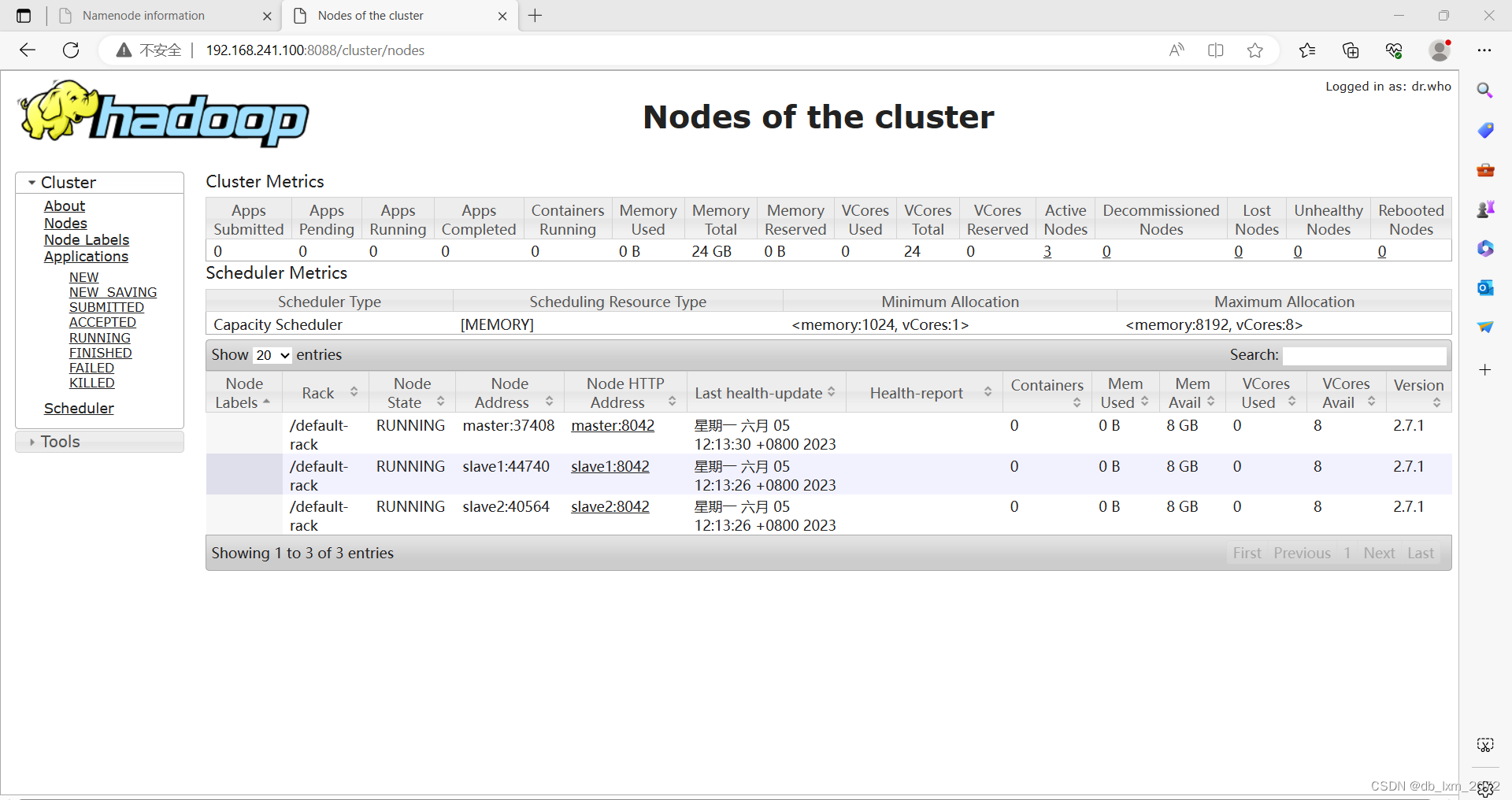
IP改为本人真实IP,访问该地址,看到该页面,YARN组件部署成功
hadoop部署总结:
互联网的快速发展带来了数据快速增加,海量数据的存储已经不是一台机器所能处理的问题了。Hadoop的技术应运而生,对于伪分布式存储,Hadoop有自己的一套系统Hadoop distribution file system来处理,为什么分布式存储需要一个额外的系统来处理,而不是就把1TB以上的文件分开存放就好了呢,如果不采用新的系统,我们存放的东西没办法进行一个统一的管理。存放在A电脑的东西只能在连接到A去找,存在B的又得单独去B找,繁琐目不便干管理,而这个分布式存储文件系统能把这些文件分开存储的过程透明化,用户看不到文件是怎么存储在不同电脑上,看到的只是一个统一的管理界面。现在的云盘就是很好的给用户这种体验。对于分布式计算,在对海量数据进行处理的时候,一台机器肯定也是不够用的,所以也需要考虑将将数据分在不同的机器上并行的进行计算,这样不仅可以节省大量的硬件的1/0开销,也能够将加快计算的速度。
三、HBase部署
3.1配置文件
打开hbase根目录的cof目录下的hbase-site.xml文件,并添加两个配置项,将hbase数据存放在hdfs
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://20210322072-master:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hbase-1.4.8/zk_data</value>
</property>
</configuration>
启动hadoop和hbase
hbase 启动命令: start-hbase.sh

执行jps,确认hbase是否部署成功

执行hbase shell命令,连接到hbase

3.2创建表
第一个参数是表名,要用单引号括起来;第二个参数及之后的参数,指定列族,并修改版本数的数量为2,即只保留两个版本的数据

查看表
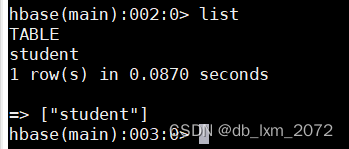
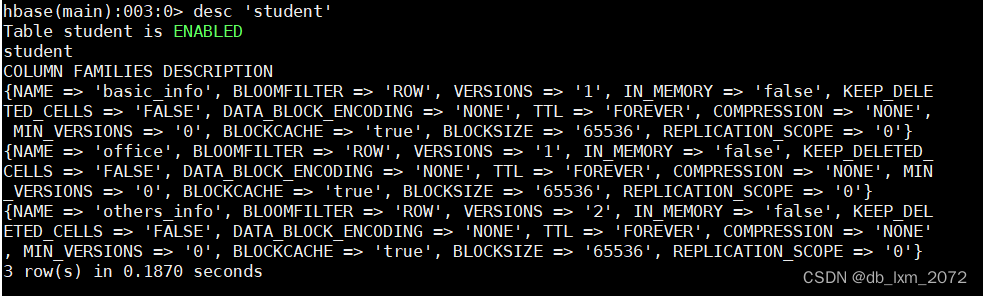
3.3表信息查询
用desc命令查看表结构,desc的输出中,一个大括号对应一个列族,每个字段对应列族的一个属性
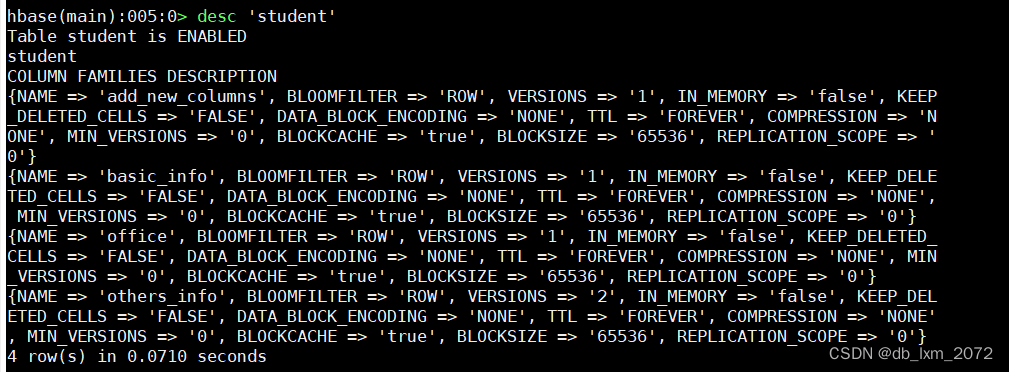
3.4表结构修改
用alter命令添加新的列族

查看是否添加成功
将add_new_columns列族的版本数改为3

删除add_new_columns列族

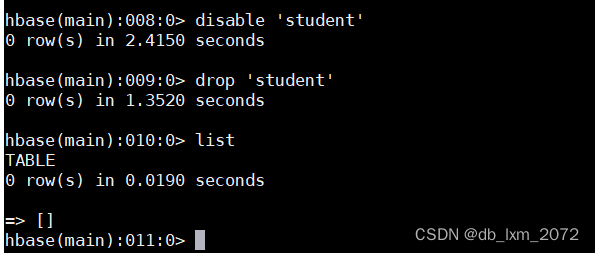
3.5 删除表
先disable,再使用drop命令删除表并查看
3.6 数据插入
用put插入一条记录,get命令可以查看指定表的某个row key的所有列的单元格最新版本的值

3.7数据更新

3.8数据删除
删除某个cell最新的数据,用delete删除指定表的指定cell的最新的值,但版本1的数据还在
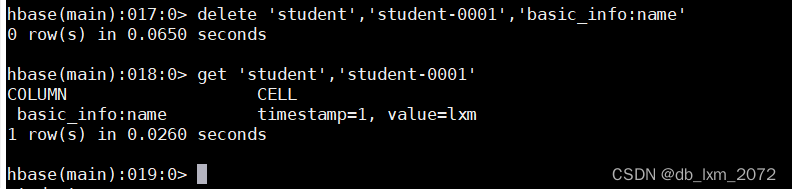
再delete一次,版本1的数据也没了
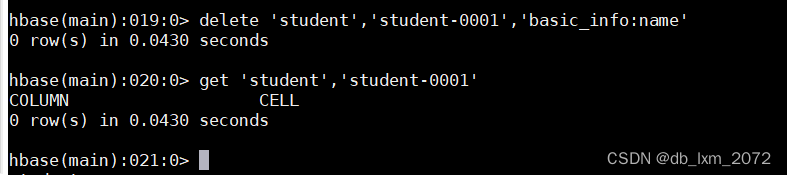
删除指定row key的某个列族的数据

删除指定row key的所有数据

3.9数据查询
根据row key获取一行数据
清空表数据

插入几条记录,用get命令查看指定表的指定row key的数据

查看表的所有数据
用scan命令可以扫描出指定表的所有数据

指定条件来查询数据

查询出在[STARTROW,ENDROW]范围内的row key,且显示一行

查看表的行数

3.10使用过滤器查询
Hbase利用过滤器查询时会进行全表扫描(例如表里有1亿行,如果直接用过滤器查询,那么就会遍历这1亿行,一条一条来匹配满足条件的数据),查询效率低下,所以所用过滤器查询时,查询的数据量要小,也就是先用STARTROW、ENDROW来缩小范围(范围查不用全表扫描,相对快很多),然后再用过滤器过滤满足条件的数据。即scan+filter。
过滤器一般需配合比较运算符或比较器共同使用。

hbase部署总结:
部署比较简单的,唯一注意的就是hbase-site.xml中的hadoop节点配置,一定要是当前的active节点。
版权归原作者 db_lxm_2072 所有, 如有侵权,请联系我们删除。