
偷个懒,用ChatGPT 帮我写段生物信息代码
如果 ChatGPT 给出的的代码不太完善,如何请他一步步改好?
网上看到一段代码,不知道是什么含义?输入 ChatGPT 帮我们解释下。
生信宝典 1: 下面是一段 Linux 代码,请帮我解读一下:
awk 'BEGIN{OFS=FS="\t"}{if(FNR==1) {for(i=3;i<=NF;i++) a[i]=$i; print "OTU","Group";} \
else {for(i=3;i<=NF;i++) if($i>0.1) print $1, a[i];}}' \
result/otutab_mean.txt > result/alpha/otu_group_exist.txt
ChatGPT 1:
这段代码是一个 awk 命令,用于处理数据文件 result/otutab_mean.txt,并将结果输出到文件 result/alpha/otu_group_exist.txt。
具体解读如下:
- awk 命令:awk 是一种处理文本文件的工具,可以按行读取文件并根据指定的规则进行处理。
'BEGIN{OFS=FS="\t"}':BEGIN 表示在 awk 处理数据之前执行的代码块,本行代码设置输出字段分隔符 OFS 和输入字段分隔符 FS 为制表符(\t)。{if(FNR==1) {for(i=3;i<=NF;i++) a[i]=$i; print "OTU","Group";}:if 语句表示如果当前处理的行号为 1,即处理的是表头,则执行花括号内的代码块。该代码块使用 for 循环将第 3 列到最后一列的值存储到数组 a 中,然后输出 “OTU” 和 “Group” 两个字符串作为表头。else {for(i=3;i<=NF;i++) if($i>0.1) print $1, a[i];}}':else 语句表示如果当前处理的行号不是 1,即处理的是数据行,则执行花括号内的代码块。该代码块使用 for 循环遍历第 3 列到最后一列的值,如果该列的值大于 0.1,则输出该行第 1 列和对应的数组 a 中的值。result/otutab_mean.txt:要处理的输入文件路径。> result/alpha/otu_group_exist.txt:输出结果到文件 result/alpha/otu_group_exist.txt。该符号 “>” 表示覆盖已有文件内容,如果文件不存在则创建该文件。
综上所述,该命令的作用是从输入文件 result/otutab_mean.txt 中提取第 3 列到最后一列中值大于 0.1 的数据,并将结果输出到文件 result/alpha/otu_group_exist.txt,同时添加表头 “OTU” 和 “Group”。
点评
这个解释是很惊艳的,很详细的。
生信宝典 2: 请帮我优化一下这段 Python 代码
aDict = {}
for line in open("GRCh38.fa"):
if line[0] == '>':
key = line[1:-1]
aDict[key] = ''
else:
aDict[key]+=line.strip()
ChatGPT 2:
可以通过使用 with 语句来打开文件,同时使用 rstrip() 方法代替 strip() 方法来剔除行末可能存在的空格、制表符等空白符号。另外,对于字符串拼接,可以使用 join() 方法提高效率。优化后的代码如下:
aDict = {}
with open("GRCh38.fa") as f:
key = ""
for line in f:
if line.startswith(">"):
key = line[1:-1]
aDict[key] = []
else:
aDict[key].append(line.rstrip())
for key, value in aDict.items():
aDict[key] = ''.join(value)
优化后的代码将打开文件的操作与程序逻辑相分离,使得代码更加易读易维护,同时使用 append() 方法将每行字符串添加到列表中,最后使用 join() 方法将列表中的字符串合并为一个字符串,可以避免使用字符串拼接操作导致的性能问题。
点评
- 这个优化很赞。我没有提到读取大文件,依然考虑了python 里面用
```
- ```
每次重新初始化存储空间带来的性能消耗问题。具体看之前的推文 为啥我的Python这么慢 - 字符串连接 (一)
- 一个小问题是,多走了一遍循环。
我还是抛出了我关于大文件的问题:
生信宝典 3: 请帮我优化一下这段 Python 代码 ,尤其是读取很大的文件时
aDict = {}
for line in open("GRCh38.fa"):
if line[0] == '>':
key = line[1:-1]
aDict[key] = ''
else:
aDict[key]+=line.strip()
ChatGPT 3:
这段代码的主要问题在于,它是一次性将整个文件读入内存,然后在内存中进行处理,如果处理的文件很大,会占用大量的内存,导致程序崩溃或变得非常缓慢。为了优化这段代码,可以采用流式处理的方式,逐行读取文件,避免一次性将整个文件读入内存。
以下是优化后的代码示例:
aDict = {}
with open("GRCh38.fa") as f:
key = ""
sequence_lines = []
for line in f:
if line.startswith(">"):
if key:
sequence = ''.join(sequence_lines)
aDict[key] = sequence
sequence_lines = []
key = line[1:-1]
else:
sequence_lines.append(line.strip())
if key in aDict:
sequence = ''.join(sequence_lines)
aDict[key] = sequence
else:
aDict[key] = ''.join(sequence_lines)
在优化后的代码中,使用了一个 with 语句来打开文件,以保证在处理完文件后自动关闭文件。然后使用一个循环来逐行读取文件,判断当前行是否是头部,如果是头部则将当前键值对的键设置为头部的内容,否则将当前行的内容添加到当前键值对的值中。为了避免最后一个键值对的值没有被添加到 aDict 中,还需要在循环结束后再次判断当前键值对的值是否需要添加到 aDict 中。通过这种方式,可以避免将整个文件读入内存,从而优化代码的性能和内存占用情况。
点评
- 我认为这个代码已经很赞了。
- 唯一一点:存最后一个 key 的序列时做的判断是多余的。
生信宝典 4: 请帮我写一段 R 绘制 Circos plot 的代码
ChatGPT 4:
Circos plot 是一种基于圆形坐标系的数据可视化方法,可以展示多个基因组之间的关系,以及基因组内不同区域的变化。以下是一段简单的 R 代码,用于绘制 Circos plot:
# 导入 circlize 包
library(circlize)
# 设置参数
circos.par(cell.padding = c(0, 0, 0, 0), track.height = 0.08)
chrs = c("chr1", "chr2", "chr3", "chr4", "chr5")
colors = rainbow(length(chrs))
# 创建 Circos plot
circos.initialize(factors = chrs, xlim = c(0, 1))
for(i in 1:length(chrs)) {
circos.trackPlotRegion(factors = chrs[i], ylim = c(0, 1), bg.border = NA, bg.col = colors[i])
}
circos.clear()
该代码利用 circlize 包中的函数来绘制 Circos plot。首先,通过调用 library() 函数导入 circlize 包。然后,设置绘图参数,例如设置边距、轨道高度等。接着,定义一个包含基因组名称的向量 chrs,以及一个包含颜色的向量 colors,这两个向量分别用于定义绘制 Circos plot 的基因组和颜色。在绘制 Circos plot 时,首先通过 circos.initialize() 函数来初始化绘图,其中 factors 参数指定绘制的基因组,xlim 参数指定绘图区域的宽度。然后通过一个循环,在每个轨道上绘制一个矩形区域,表示基因组的区域。最后,调用 circos.clear() 函数来清除绘图区域,以便进行下一次绘图。该代码只是一个简单的示例,实际绘制 Circos plot 需要根据数据的不同进行调整。
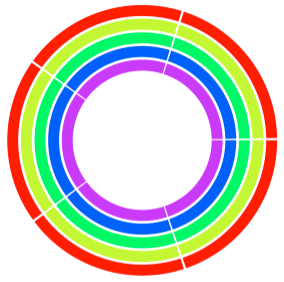
点评
运行了下,确实可以出图,如上的彩虹圈。后面应该问的再具体一些。

往期精品(点击图片直达文字对应教程)
机器学习
后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集


版权归原作者 生信宝典 所有, 如有侵权,请联系我们删除。