
Linux 动静态库的制作,使用和加载
关于动静态库的初步理解,我们在Linux基础环境开发工具的使用(二):动静态库的理解,make,makefile
这篇博客中进行了详细介绍,大家可以去看一下
今天我们直接介绍动静态库的制作和使用,分别站在库的制作者和使用者的角度来分析
而我们要使用的文件就是我们在
Linux文件系列: 深入理解缓冲区和C标准库的简单模拟实现
这篇博客当中写的mylib.h mylib.c这几个文件
一.前置说明
1.mylib.h
#pragmaonce#include<stdio.h>#include<string.h>#include<sys/types.h>#include<sys/stat.h>#include<fcntl.h>#include<errno.h>#include<stdlib.h>#include<unistd.h>#defineSIZE4096#defineDFL_MODE0666#defineFLUSH_NONE1#defineFLUSH_LINE(1<<1)#defineFLUSH_ALL(1<<2)typedefstructmy_file{int fileno;char buffer[SIZE];int end;//缓冲区中有效数据的个数(也就是最后一个有效数据的下一个位置)int flag;//缓冲区的刷新策略}my_file;
my_file*myfopen(constchar* path,constchar* mode);intmyfwrite(constchar* s,int num,my_file* stream);intmyfflush(my_file* fp);intmyfclose(my_file* fp);
2.mylib.c
#include"mylib.h"
my_file*myfopen(constchar* path,constchar* mode){int fd=0;int flag=0;if(strcmp(mode,"r")==0){
flag |= O_RDONLY;}elseif(strcmp(mode,"w")==0){
flag |=(O_WRONLY | O_CREAT | O_TRUNC);}elseif(strcmp(mode,"a")==0){
flag |=(O_WRONLY | O_CREAT | O_APPEND);}if(flag & O_CREAT){
fd=open(path,flag,DFL_MODE);}else{
fd=open(path,flag);}//打开文件失败,设置errno错误码并返回NULLif(fd==-1){
errno=2;returnNULL;}//创建文件,设置fp的相应属性
my_file* fp=(my_file*)malloc(sizeof(my_file));if(fp==NULL){
errno=3;returnNULL;}
fp->fileno=fd;
fp->flag=FLUSH_LINE;
fp->end=0;return fp;}//把s中的数据写入stream中intmyfwrite(constchar* s,int num,my_file* stream){//保存旧的缓冲区的大小int pos=stream->end;//1.先写入用户级缓冲区memcpy(stream->buffer+pos,s,num);
stream->end += num;//更新缓冲区大小//刷新策略:按行刷新if(stream->flag & FLUSH_LINE){//2.判断是否需要刷新缓冲区(判断是否有'\n')int flushit=0;while(pos < stream->end){if((stream->buffer[pos])=='\n'){
flushit=1;break;}
pos++;}if(flushit ==1){//3.刷新缓冲区:[0,pos]数据write(stream->fileno,stream->buffer,pos+1);//4.更新缓冲区 把[pos+1,count)的数据移动到[0,count-pos-2]当中//一共移动count-pos-1个数据//先求出要移动的最后一个数据的下标int count=stream->end;memmove(stream->buffer,stream->buffer+pos+1,count-pos-1);
stream->buffer[count-pos-1]='\0';
stream->end=count-pos-1;}}return num;}intmyfflush(my_file* fp){if(fp->end >0){write(fp->fileno,fp->buffer,fp->end);
fp->end=0;}return0;}intmyfclose(my_file* fp){myfflush(fp);returnclose(fp->fileno);}
3.mymath.h mymath.c
跟下面的两个文件mymath.h mymath.c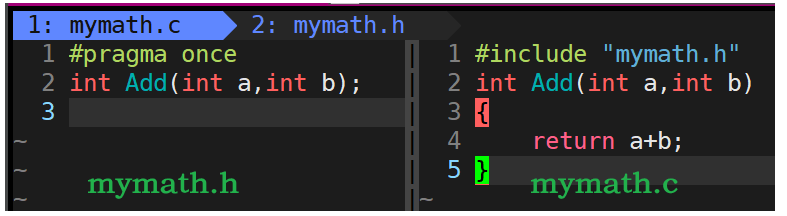
4.如何制作库
我们知道,在文件的编译链接时,只对每个.c文件进行单独编译形成.o目标文件,在链接阶段才会将所有的.o目标文件形成可执行程序
.h文件是不参与编译的,因为会在预处理阶段在包含该.h文件的文件当中展开
因此我们只需要将所有的.o目标文件用特定的方式进行打包,就能形成一个库文件
只要一个源代码需要用到某个库,只需要包含对应的头文件,并且拥有对应的库文件,就能够使用这个库文件当中的方法了
这样做的好处(也就是为什么要有库):
1.提高开发效率
2.隐藏源代码
二.动静态库的制作
1.静态库的制作
1.制作
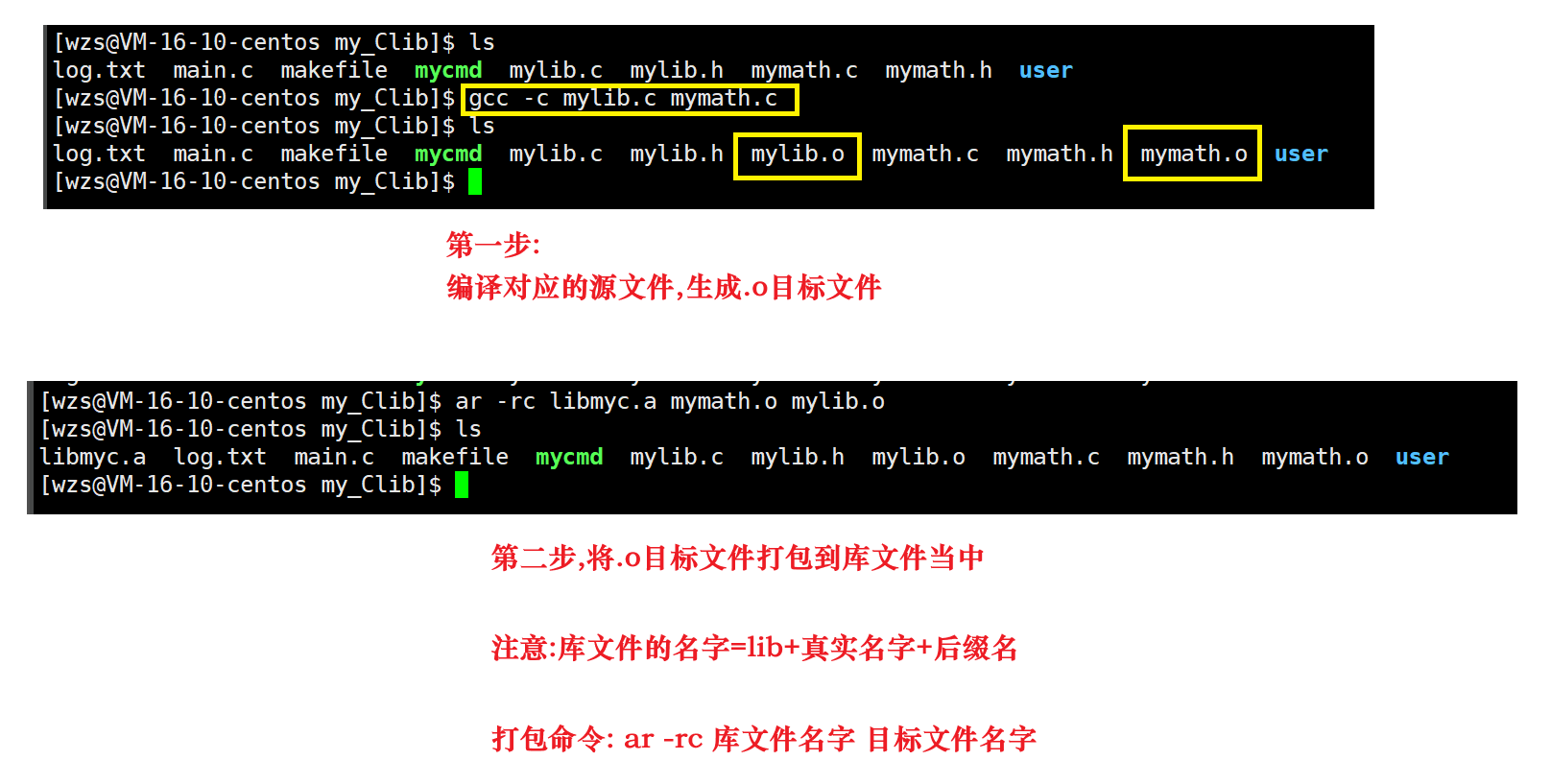
这个c是create,表示如果当前目录中不存在这个库就创建这个库
这个r是replace,表示如果当前目录中存在这个库,就替换这个库(用于库的更新)
2.使用一下静态库,验证是否成功打包
下面我们把libmyc.a和.h头文件拷贝到user目录下,
然后写一个main.c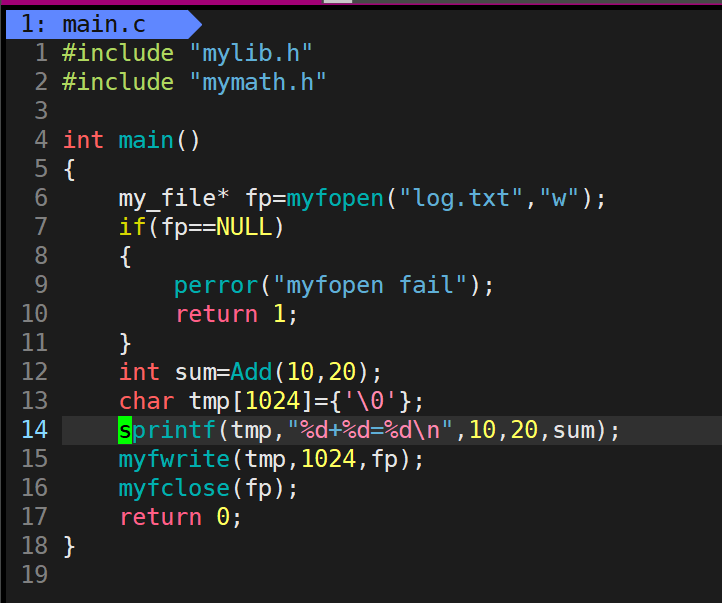
main.c里面成功使用了库当中的myfopen,myfwrite,myfclose,Add
函数
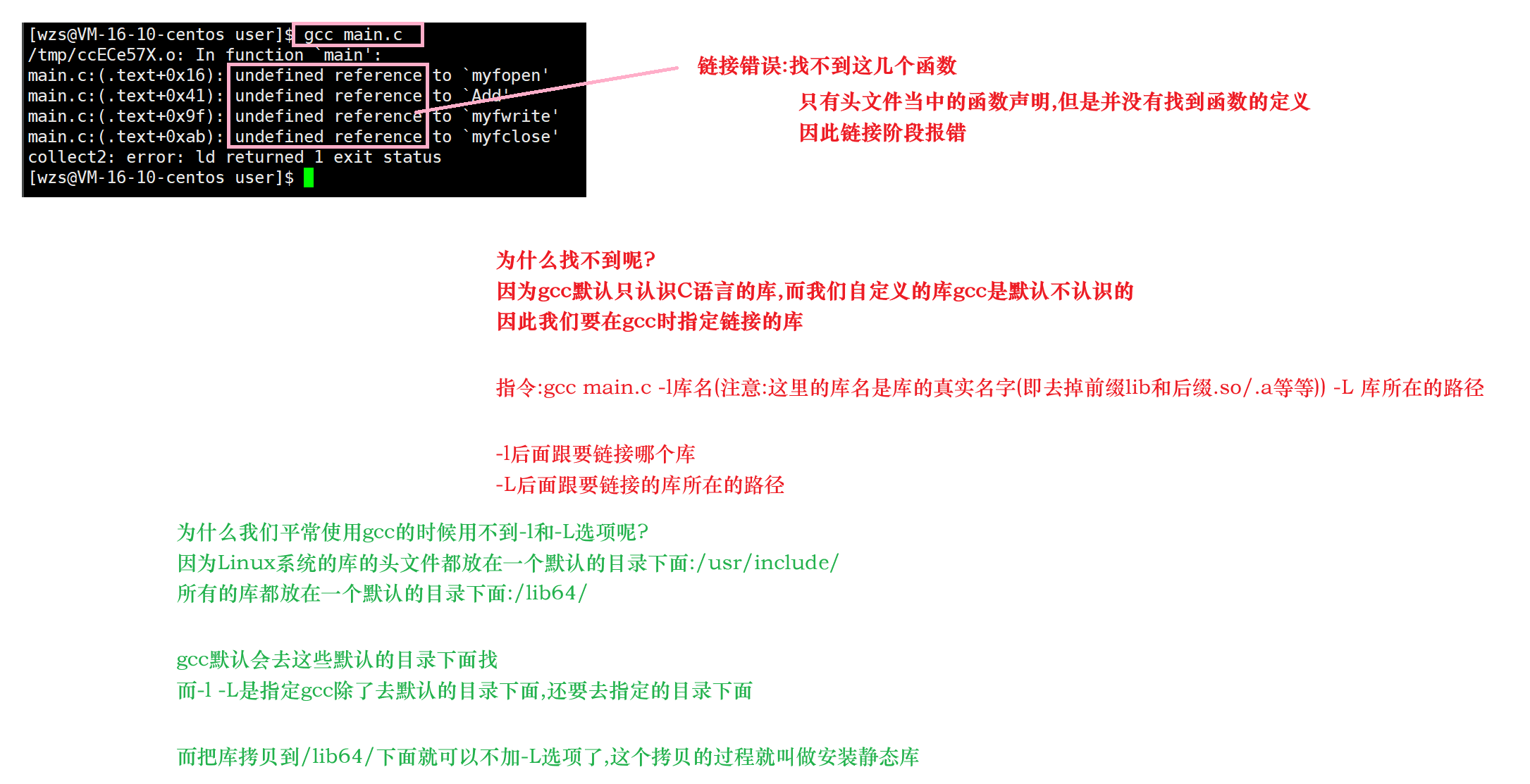
调用自定义库对文件进行编译,生成可执行程序
gcc main.c -l库名 -L 库所在的路径
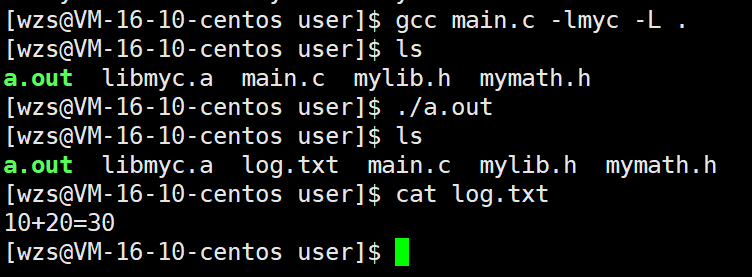
成功编译,生成的可执行程序的执行情况正确
下面我们来制作一下动态库
2.动态库的制作
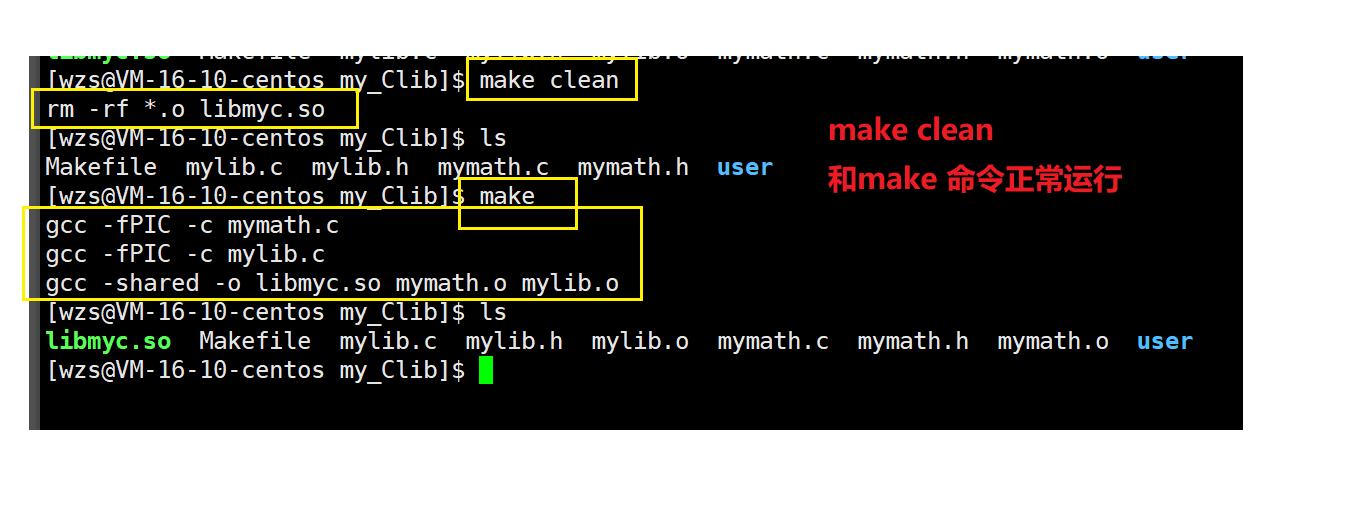
我们先删掉刚才生成的.o目标文件
1.编译.c源文件文件生成.o目标文件
我们知道gcc -c默认生成同名的.o文件
对于静态库而言,编译.c文件生成.o文件时直接使用gcc -c即可
而对于动态库来说,需要加上一个选项-fPIC(用于产生位置无关码)
gcc -fPIC-c mymath.c
gcc -fPIC-c mylib.c

2.打包生成动态库
对于静态库的打包,需要使用ar命令
但是对于动态库的打包,直接使用gcc即可
不过要加上-shared(表示生成共享库格式)选项
gcc -shared-o -libmyc.so(动态库名称lib前缀+库名称+.so后缀) mymath.o mylib.o

此时我们的动态库就制作完成了
3.编写makefile文件,自动化制作动态库
下面我们写一个makefile文件,来自动化制作动态库
4.使用一下动态库,验证是否成功打包
跟静态库的验证一样,我们依旧是把.h头文件和动态库拷贝到user目录下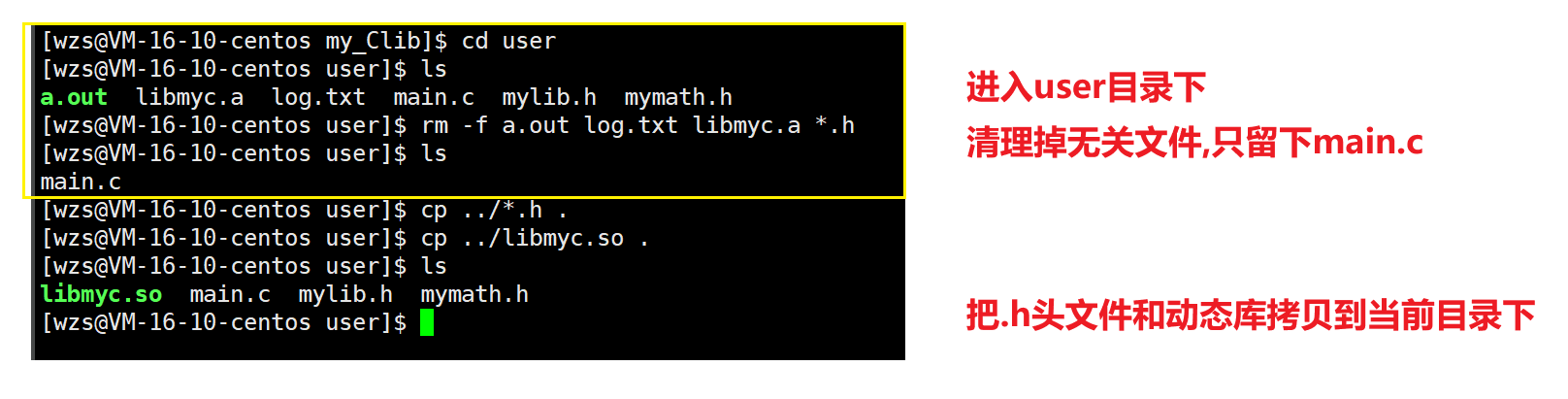
然后
gcc main.c -lmyc-L.
gcc main.c -l(要链接的库的名称) -L(要链接的库的路径)
因为我们制作的库属于第三方库,而gcc只认识c/c++的库和路径
因此必须要加上-l指定我们要额外链接的库名称
又因为gcc只会到系统默认的库搜索路径下进行搜索
并不会在当前路径下搜索库,因此我们需要加上-L指定要额外链接的库路径
指定完之后就等于告诉gcc,链接的时候不要忘了到xx路径下帮我链接一下xxx文件哦

3.动态库的打包与发布
刚才我们演示完了动态库的制作和使用的过程
我们也知道了对于编写库的人而言
我们要给用库的人提供的是头文件+库文件
刚才我们把头文件和动态库拷贝到当前路径下
可是如果我们今天要用的头文件和动态库有成百上千个怎么办呢?
全拷贝到当前路径下?
那未免也太挫了吧
因此下面我们来学习一下动态库的打包与发布
我们将其写入makefile当中,自动化完成其过程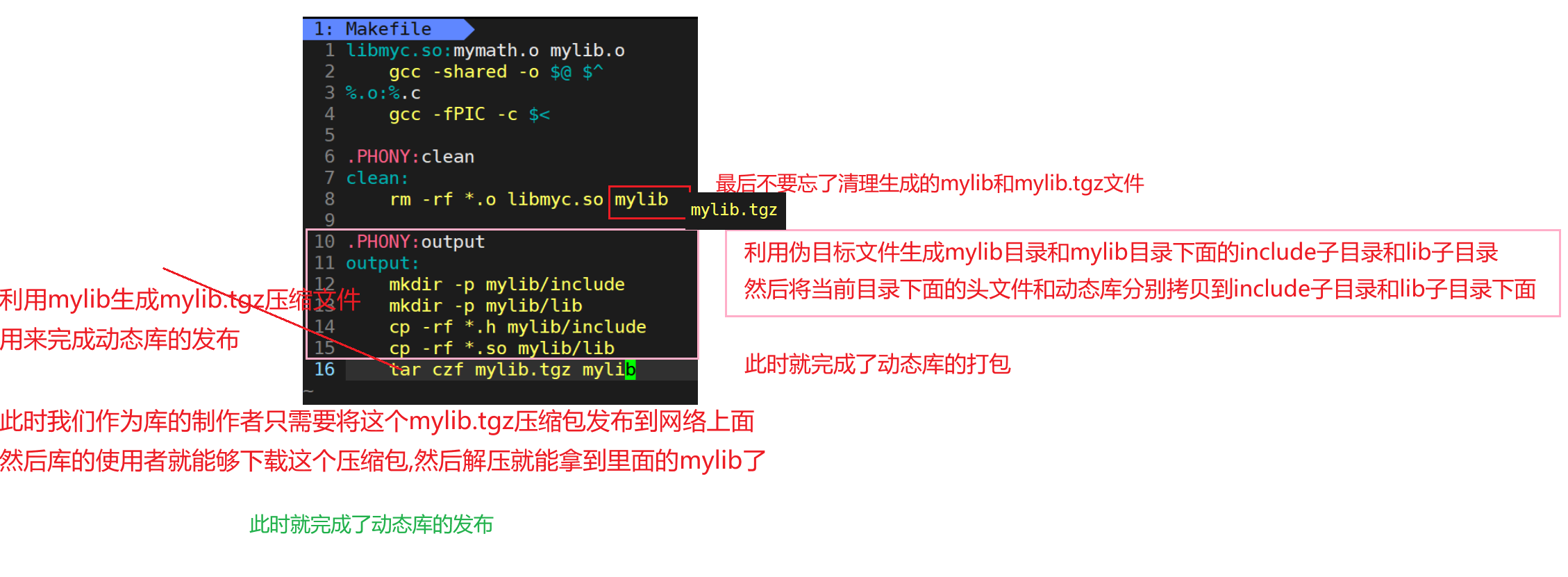
生成伪目标文件:
make 伪目标文件名
因此只需要make output就能够完成动态库的打包与发布
下面我们测试一下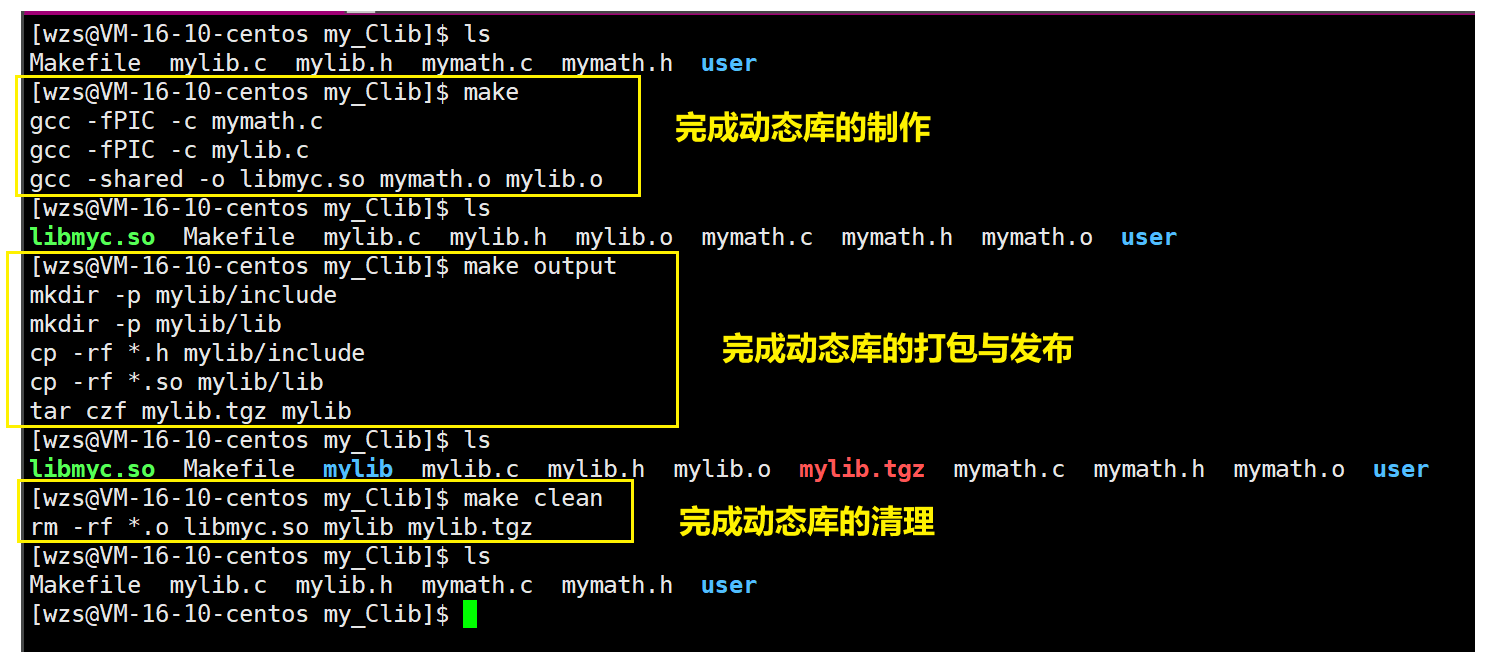
测试成功,下面我们重新make 和 make output
然后切换为库的使用者来用一下这个库
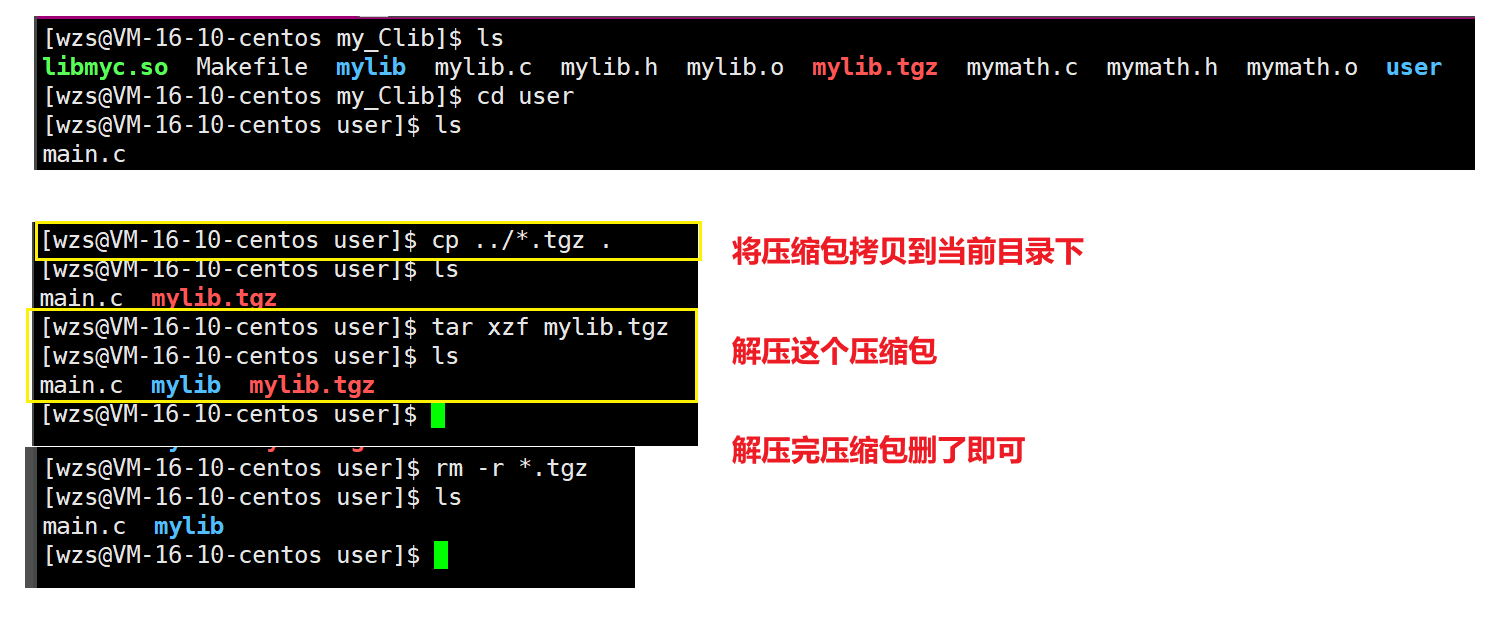
三.动态库的使用
1.下载压缩包并解压
czf:形成压缩包
xzf:解压
tar -czf/cvzf dst.tgz src
tar -xzf/xvzf dst.tgz
dst:要形成的压缩文件的名称
src:要打包的文件名/目录名
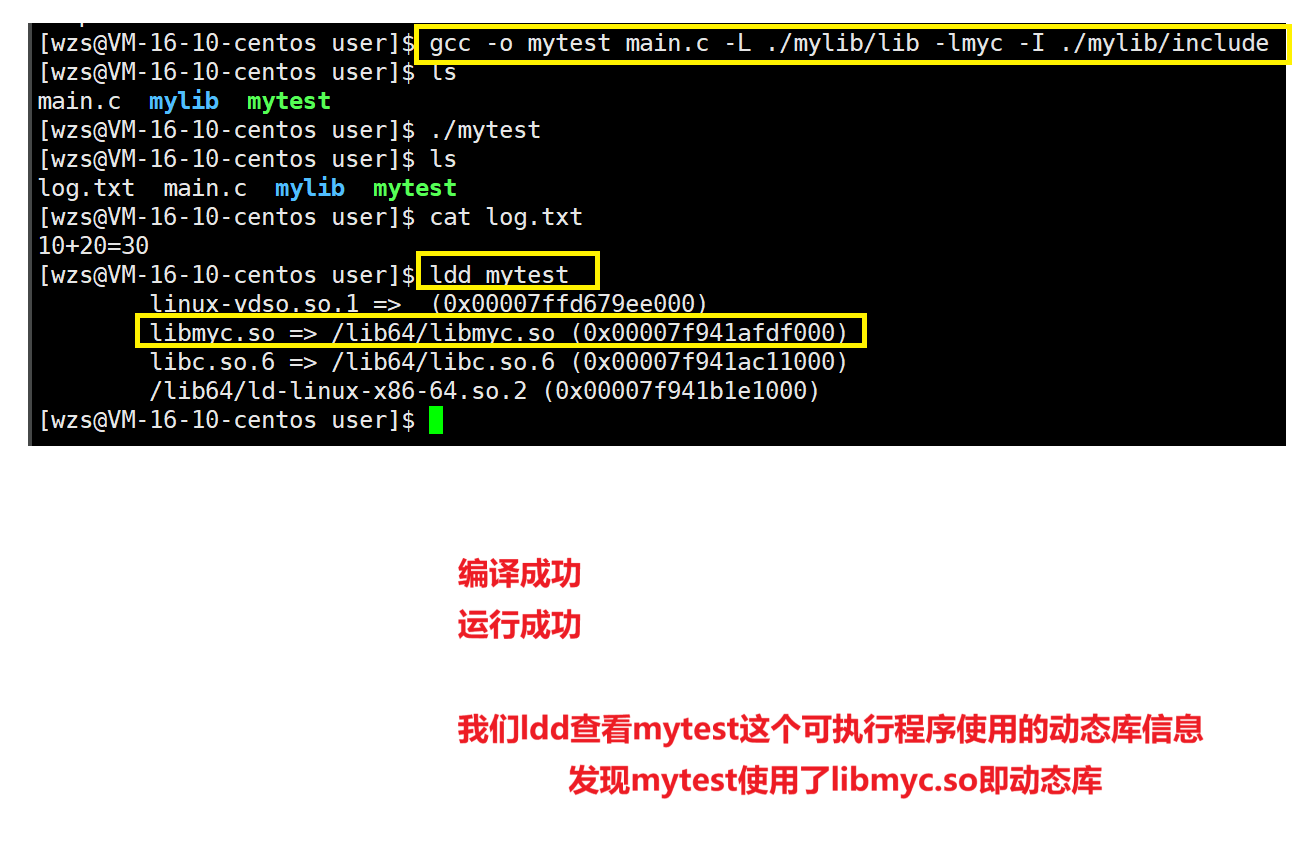
2.使用动态库对main.c进行编译
此时头文件不在当前目录下,因此我们一定要加上某个选项来告诉gcc我们的头文件在哪里
这个选项就是-I选项(大写的i,不是小写的L)
gcc -o mytest main.c -L ./mylib/lib -lmyc-I ./mylib/include
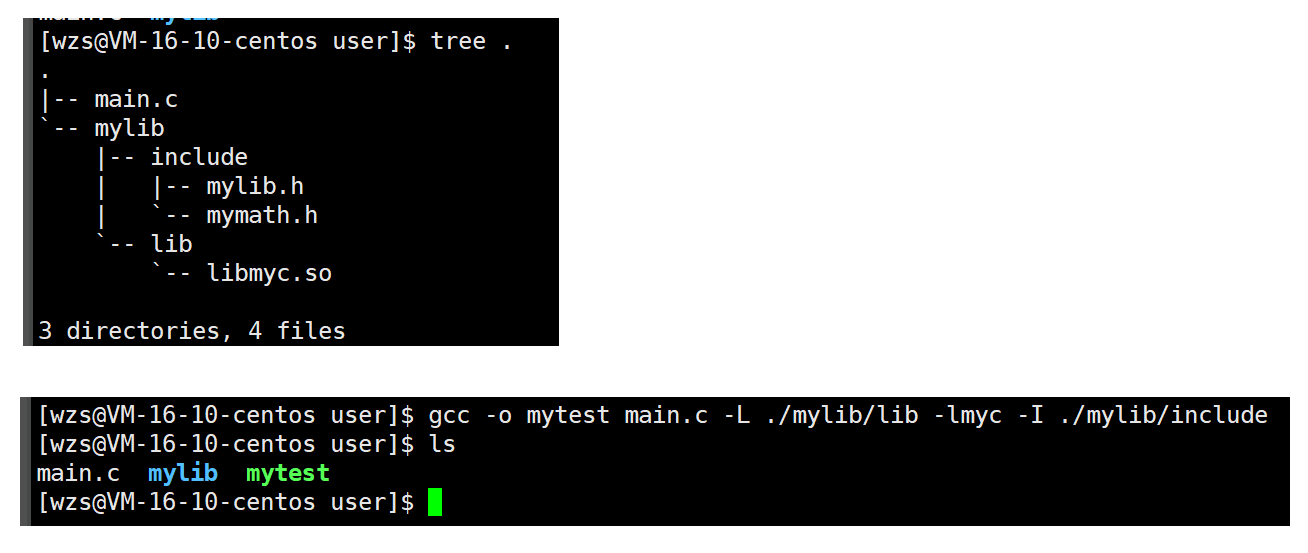
成功生成mytest这个可执行程序
下面我们运行这个可执行程序
报错了,找不到这个库,为什么呢?
我刚才不是在gcc的时候用-L选项告诉你这个动态库在哪里了吗?
为什么你还跟我说你找不到呢?
我们要理清一个思路
1.我们刚才是告诉gcc这个路径的
2.gcc只负责编译链接生成可执行程序,不负责执行可执行程序
3.可执行程序的执行是由OS负责的,跟gcc无关
4.我们并没有告诉OS我们的动态库在哪里
此时我们就能理解为什么这里会报错了
那么我们应该怎么解决这个问题呢
有4种解决方法,下面我们一一介绍,大家可以随意挑选使用
1.安装动态库到系统当中
想一下,我们平常执行可执行程序的时候可是从来都没有出现过这种问题的哦
为什么呢?
因为我们平常用的库都是c/c++的官方库,OS默认就回到对应的路径当中去查找这个库,因此不存在找不到的问题
而且gcc,g++也是默认到这个路径当中去查找的
因此我们只需要将libmyc.so这个动态库安装(拷贝)到系统的那个路径当中,OS不就能找到了吗,而且gcc/g++也能顺带找到哦
因此:
所谓的把库(或者其他软件)安装到系统当中,本质上就是把对应的文件拷贝到系统指定的路径当中!
注意:这个路径是机器指定好的,一般都是root的目录
因此拷贝的时候需要使用sudo命令或者切换成root身份来操作
演示
因为要用sudo修改/lib64目录下的内容,因此这个过程的操作一定要小心
千万不能误操作…后果你懂的…
这个路径就是根目录当中的lib64这个目录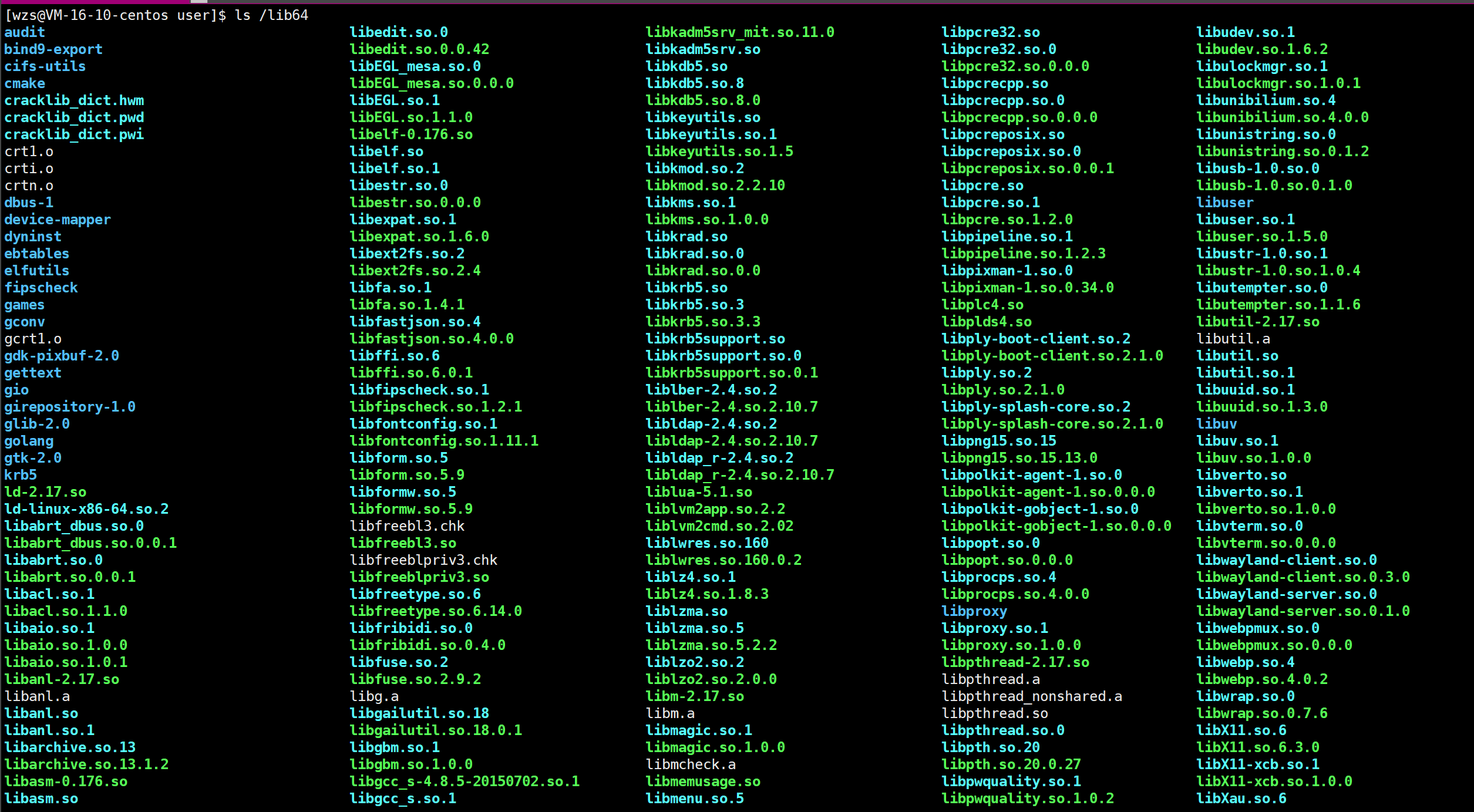
后面还有一堆,就不放进来了,大家知道这里有一大堆动静态库就行了
验证
此时我们不仅能够执行这个可执行程序了
而且gcc的时候我们也不用指明库的路径了
但是库的名称依然要指定(因为我们用的是第三方库,gcc/g++不认识)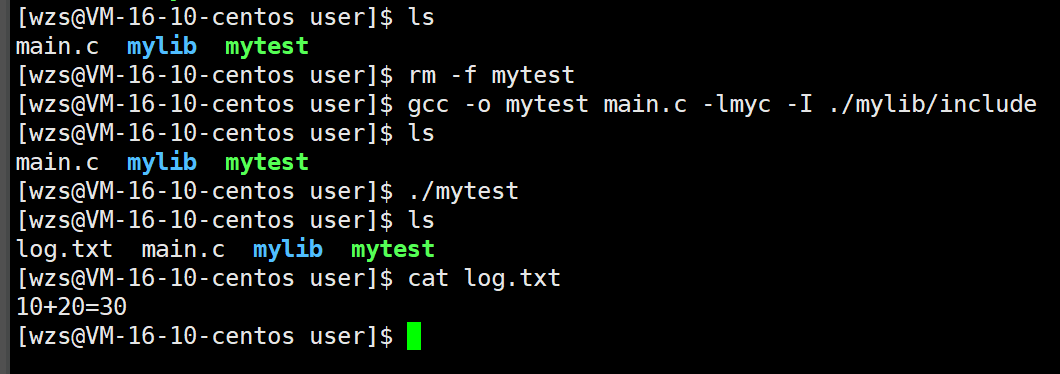
运行成功
下面为了演示后面的操作,我们先把libmyc.so从/lib64/目录下移除
移除成功
2.修改环境变量LD_LIBRARY_PATH
1.演示+验证
环境变量LD_LIBRARY_PATH是OS运行程序时,动态库查找的辅助路径
也就是说OS在运行程序时不仅仅会到系统默认搜索路径当中进行查找,也会到环境变量LD_LIBRARY_PATH当中包含的路径当中进行查找


2.修改配置文件+验证
关于环境变量的知识,大家可以看我的这篇博客:
Linux环境变量与命令行参数
我们之前学习过环境变量,知道我们对环境变量的修改只会修改环境变量在内存当中的值
而并不会修改它在磁盘当中的值
每次登陆时环境变量都会重新从磁盘当中进行初始化的
因此如果我们退出Xshell,再重新登录的话,这个环境变量又变成我们修改之前的值了
那么怎么才能彻底修改这个环境变量呢?
只需要修改我们家目录下面的
.bashrc
.bash_profile
即可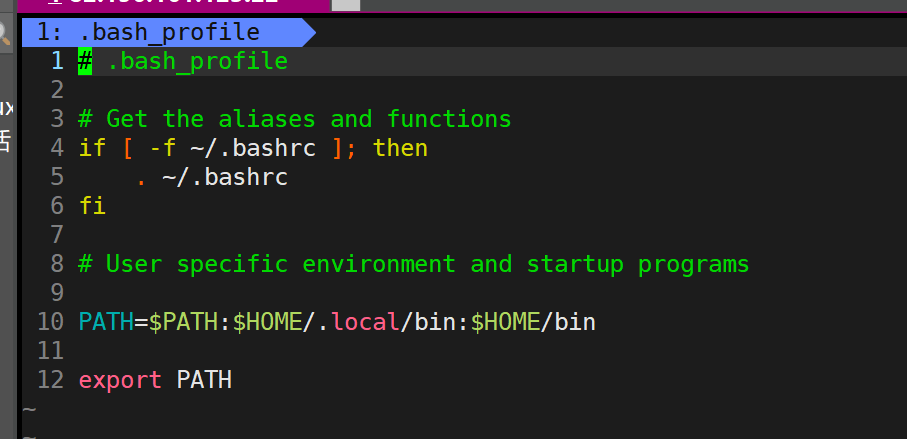
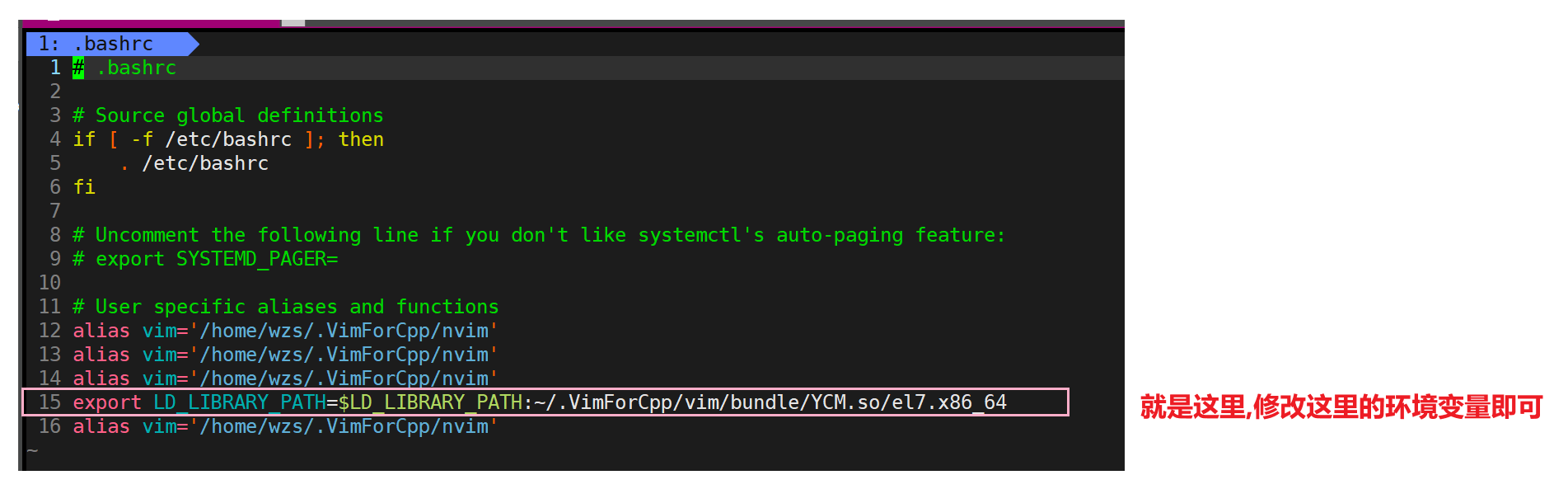
一般我们不建议修改这些配置文件,因为如果误操作的话会出现很严重的问题
这里我们演示一下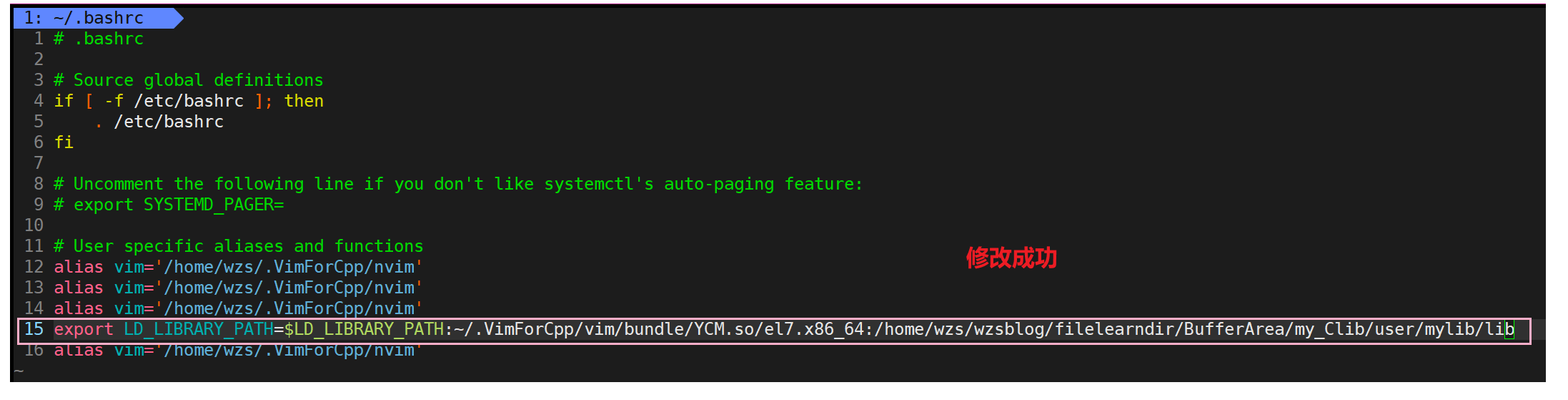
然后我们退出Xshell,重新登录
然后cd到当前的user目录下,使用这个动态库编译main.c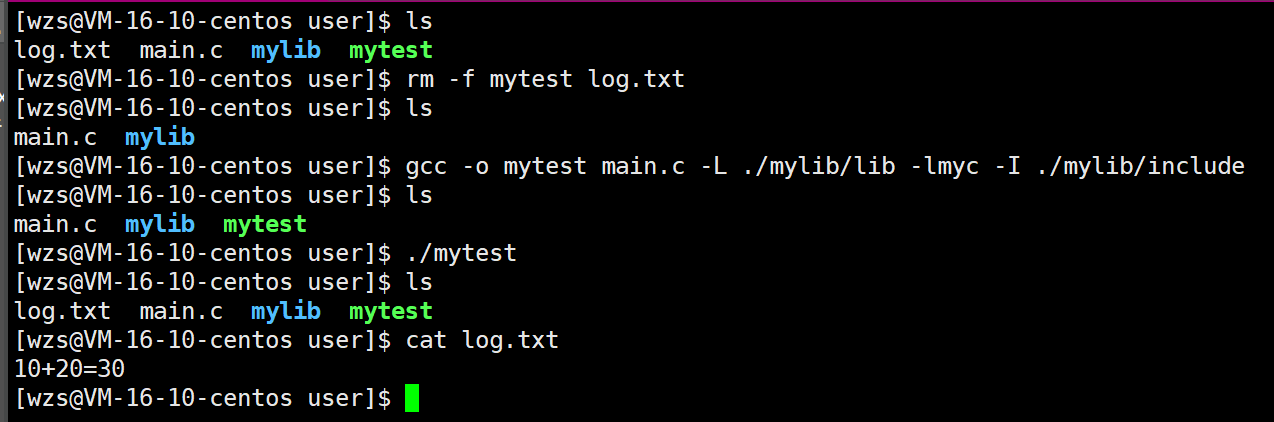
成功运行
我们不建议使用第二种方法,因为会修改配置文件
而且我们后面介绍其他知识点,演示的时候会删掉这个动态库的
别出现什么意想不到的问题就得不偿失了
因此我们下面把配置文件修改回之前的样子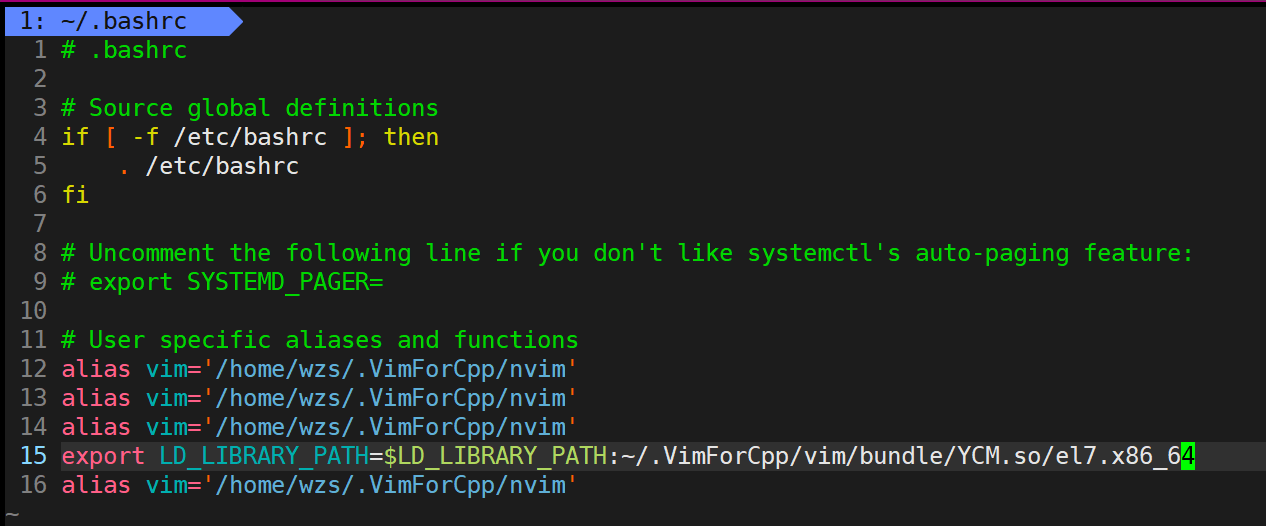
恢复完毕
请问此时为什么我删掉mytest,重新编译之后
这个mytest还能正常运行呢?
因为我们登上Xshell之后我们的环境变量就已经从磁盘当中读取到内存了,刚才我们修改的是磁盘当中的配置文件,并没有修改内存当中的环境变量
因此我们退出Xshell并重新登录
然后下面我们介绍第三种方法
3.在/lib64/目录下面建立动态库的软链接文件
因为我们要sudo修改/lib64目录,所以小心为上
1.演示
只要我们在/lib64/目录下面建立libmyc.so这个动态库的软连接文件
这样OS和gcc/g++在搜索库的时候不就能够搜索到我这个库了吗
这点很好理解,下面我们来搞一下
ln-s 目标文件名 链接文件名
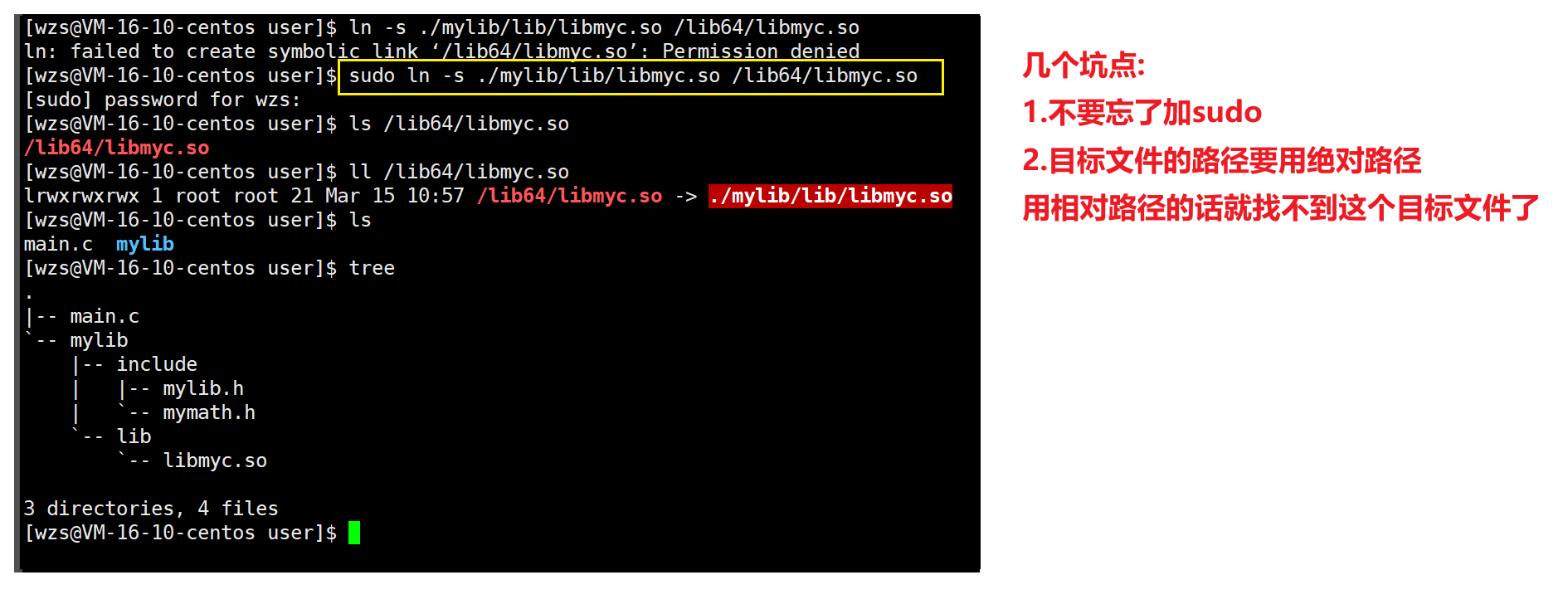

改成绝对路径之后就成功了
2.验证
下面我们验证一下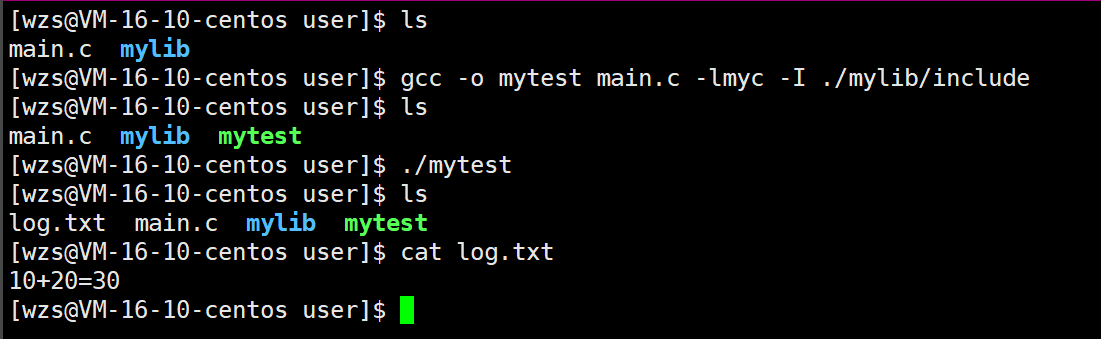
gcc无需-L指明库的路径
OS运行可执行程序成功
因为软链接文件也是一个磁盘级文件,因此退出重登Xshell之后依然存在,依然可以直接编译main.c,运行可执行程序
为了不影响下面的操作,我们删除这个软链接文件
4.在/etc/ld.so.conf.d目录下添加.conf配置文件
1.演示
在我们系统当中存在一个存放各种配置文件的目录/etc
在这个目录下面有一个配置文件叫做
ld.so.conf.d
(ld:链接 so:动态库 conf:配置文件 d:表示这个文件是一个目录文件)
这里面允许我们建立各种各样的用户级别配置文件
这里面的配置文件的名字随便起,只要后缀是.conf即可
下面我们在/etc/ld.so.conf.d目录下创建一个my_dynamic_lib.conf配置文件
依旧要sudo创建
然后我们只需要将libmyc.so的绝对路径sudo写入到这个配置文件当中即可
因为使用sudo写入,而root的vim是没有配置过的,因此是这么个样子
注意:这里的路径跟我们刚才修改环境变量的时候加的路径一样
都是只到lib,不包含libmyc.so
然后我们还需要使用
sudo ldconfig
这个命令让刚才的配置文件生效
2.验证
注意:gcc依旧是要加上-L选项指明库路径的
验证成功
小小建议
我们建议:
如果我们想要拷贝的库很官方,那么建议使用第一种方法,直接安装到系统当中
如果不是很官方,那么建议使用第三种方法,建议软链接文件
因为我们目前的这个库并不是很官方,因此我们采用第三种方法
下面我们删掉这个配置文件,然后建立软链接文件
注意:删除那个配置文件之后,还是要使用sudo ldconfig让删除操作生效

建立成功
四.动静态库与动静态链接
1.先上结论
1.动态库只能进行动态链接
2.静态库只能进行静态链接
3.gcc默认使用动态链接,如果我们想要进行动态链接gcc需要加-static选项
4.如果我们同时提供动态库和静态库,gcc默认使用的是动态库
5.如果我们只提供静态库,不提供动态库
那么gcc只能对该库进行静态链接,对能够进行动态链接的库依旧进行动态链接
6.如果我们只提供动态库还非要进行静态链接,那么就会发生链接报错
7.我们的云服务器默认是没有安装c/c++的静态库的,默认只安装了动态库
centos 7中使用yum安装
安装c/c++的静态库的命令是:
C语言静态库:glibc-static
C++静态库:libstdc++-static
执行
sudo yum install-y glibc-static libstdc++-static
2.验证
其中,第1,2,7条我们无需验证
我们只验证3,4,5,6这4条
1.修改makefile
我们修改一下makefile
让它也能够编译生成静态库
并且也把静态库放到mylib/lib目录当中
因为makefile的扫描特性
此时我们需要:
1.make生成静态库
2.make libmyc.so生成动态库
3.make output打包发布动静态库
4.make clean清理动静态库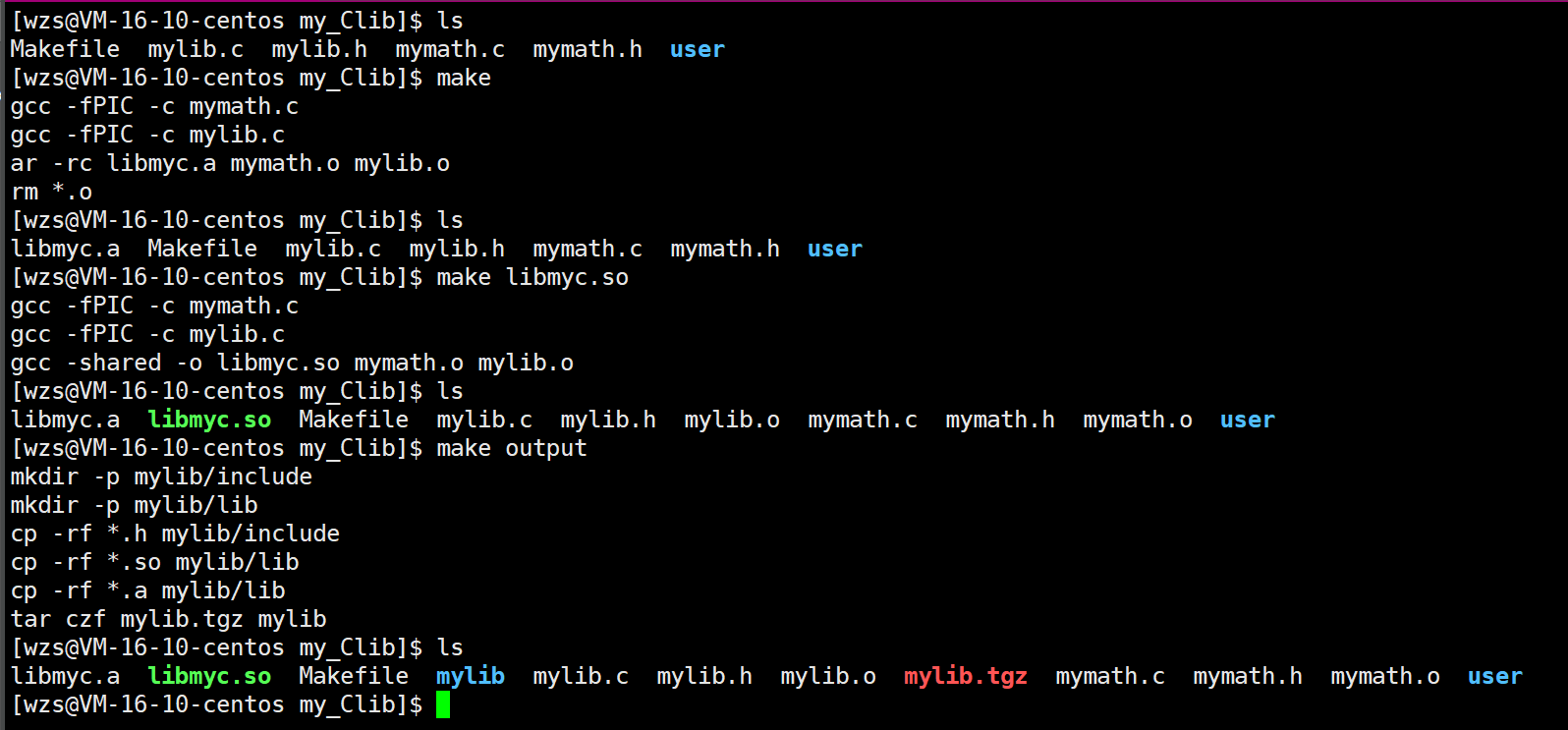
成功运行
2.同时提供动态库和静态库,gcc默认使用的是动态库
先拷贝压缩包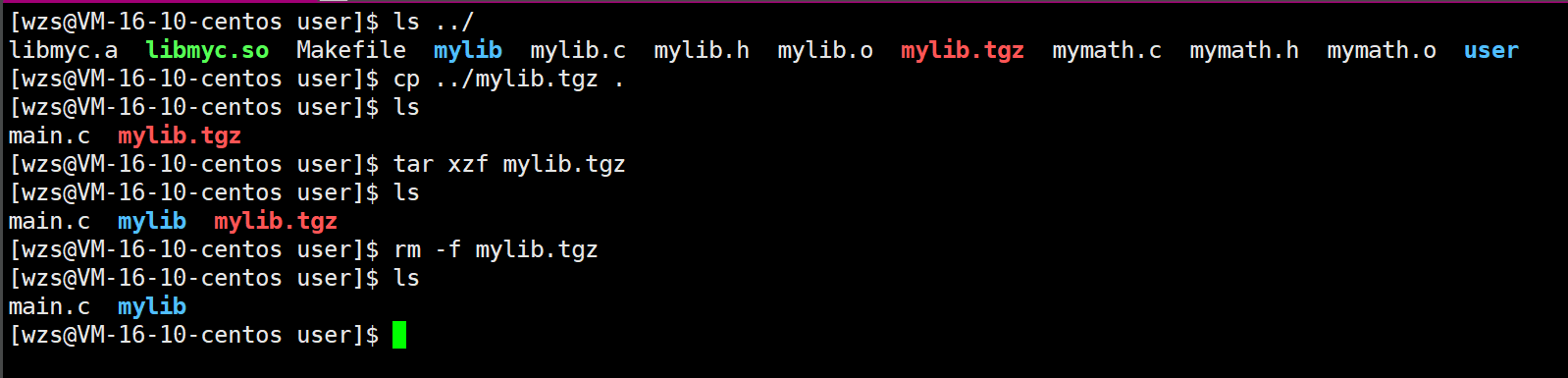
第一条验证完毕
至于为什么呢?
我们之前提到过动静态库的优缺点,这些就是原因
3.只提供静态库,不提供动态库
那么gcc只能对该库进行静态链接,对能够进行动态链接的库依旧进行动态链接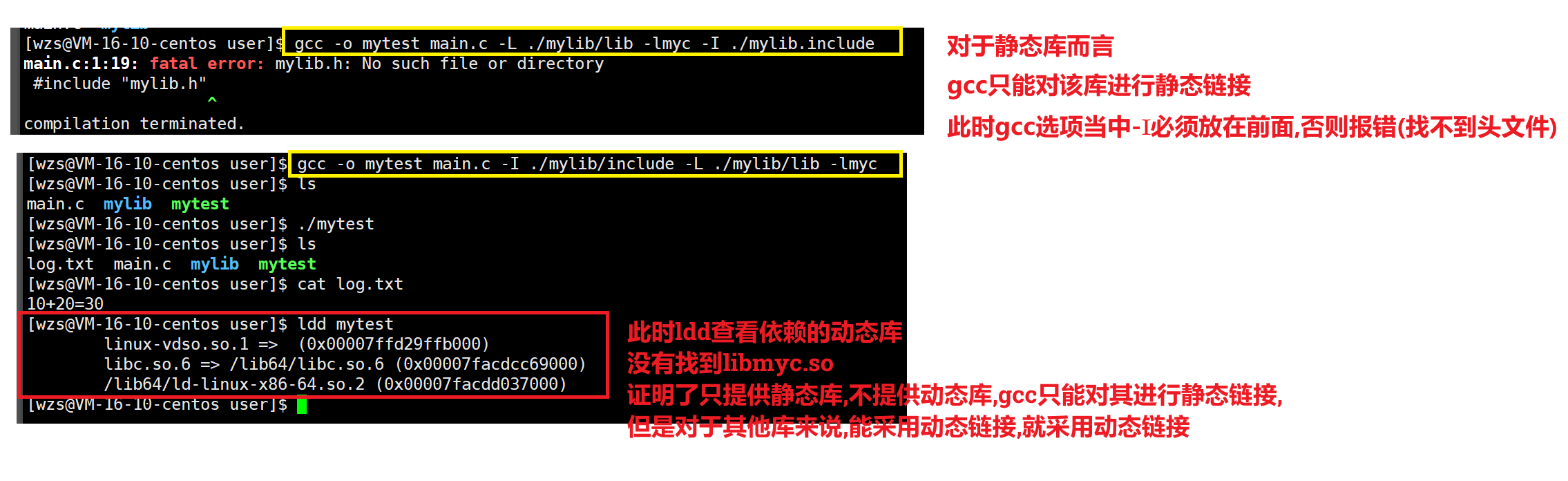
一个小问题
此时我们发现了一个问题:
利用动态库进行动态链接的时候,OS运行该可执行程序时必须要能够找到该动态库,否则就会报错
而我们刚才利用静态库进行静态链接,OS运行该可执行程序时不应该也是找不到该静态库吗?为什么不报错呢?
OS的确找不到该静态库,但是OS不需要找静态库,你给我我也不要
为什么呢?
因为使用对该库使用静态链接编译时,会将对应库函数的具体实现拷贝到可执行程序当中,因此可执行程序当中就有了你这些方法的拷贝
那么我就不需要你这个静态库了,因此我不需要去找你
4.同时提供动态库和静态库,采用静态链接进行编译


ldd发现该可执行程序对于所有库都是采用的静态链接的方式进行链接的
5.只提供动态库还非要进行静态链接,那么就会发生链接报错

验证成功
五.理解动态库的加载
1.站在系统的角度来进行理解
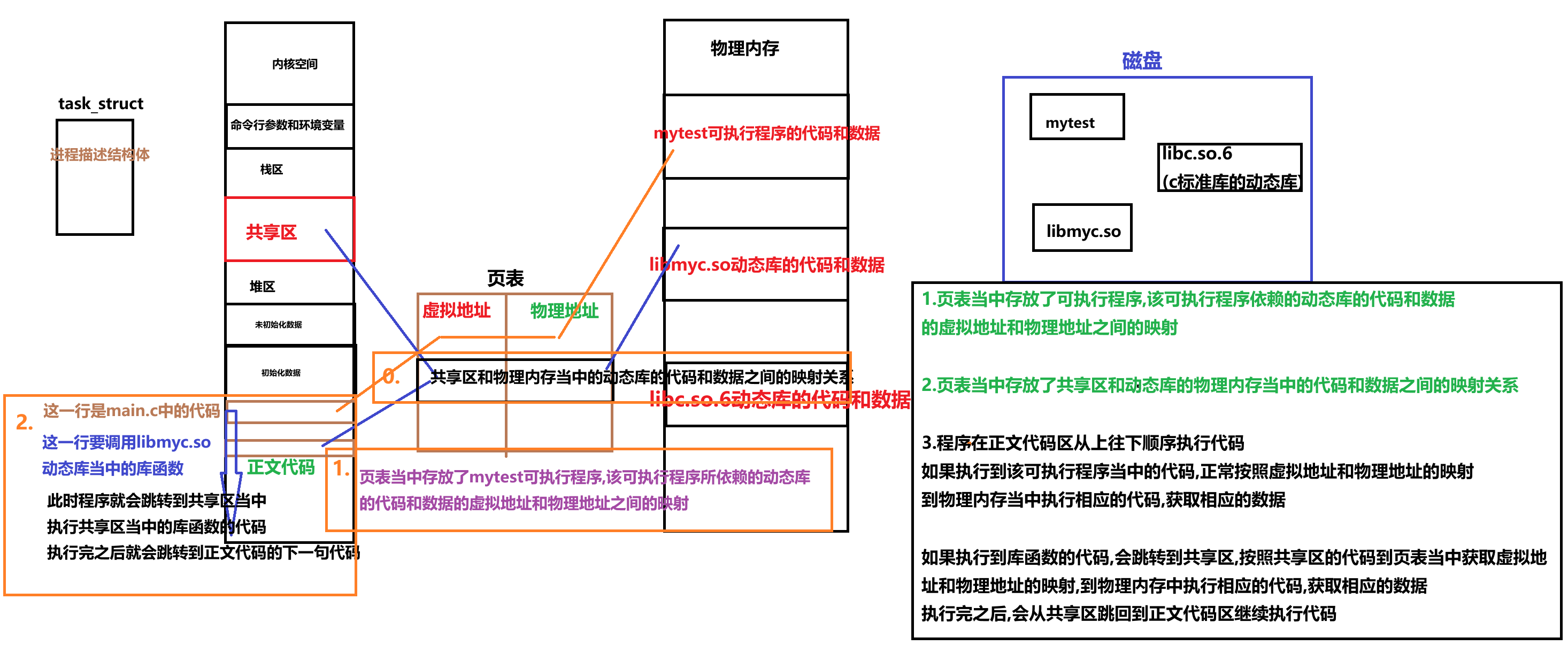
因此,我们可以得出如下结论:
1.库函数的调用依旧是在进程地址空间当中进行的
2.动态库加载之后,会被映射到进程的共享区当中
3.动态库的代码和数据是OS系统的所有进程中公共的代码和数据,在物理内存当中只需要存在一份即可!
4.如果又有一个进程需要使用已经被加载了的动态库的话,只需要在页表当中建立起共享区和物理内存之间的映射即可
5.OS知道并且决定所有库的加载与否
6.因为系统当中可能会同时存在非常多的已经加载了的库,
因此OS会对这些库进行管理
如何管理?
先描述,在组织
类似于这样的结构体
struct loadlib
{
char* libname;//库名称
void* addr;//库加载的地址
uint64_t time;//库加载的时间
结构体的管理字段:例如如果是链表的话,这里就是struct loadlib* next;};
7.动态库是如何做到共享的呢?
系统当中可能存在很多程序,这些程序可能会用到一些公共方法
我们把这些公共方法打包成库
因为动态库只需要加载一次,就能够映射到每个进程的进程地址空间当中
因此这样就能让所有的进程共享这同一份代码
因此动态库也被称为共享库
而静态库是把对应库函数直接拷贝到程序当中,因此就会造成资源的浪费
而哪些函数需要被打包成库,就看这个函数能否被很多程序所使用
2.补充一下关于可执行程序的知识点
1.先说理论
1.可执行程序本身也是有自己的格式信息的
2.可执行程序本身在加载之前,就已经被按照类别(比如权限,访问属性等)划分为各个区域了
3.可执行程序当中的代码指令本身就是有地址的,这些地址在程序被加载为进程时就会被转化为进程地址空间中的虚拟地址
也就是说进程地址空间当中的很多地址数据都是从可执行程序当中来的
1.验证可执行程序当中代码指令本身就有地址
反汇编是对可执行程序进行操作的,将可执行程序当中的二进制的01序列反汇编翻译为汇编语言
这是用的我自己用哈希桶封装的unordered_map写的测试代码
我们可以看到函数和指令都有自己的地址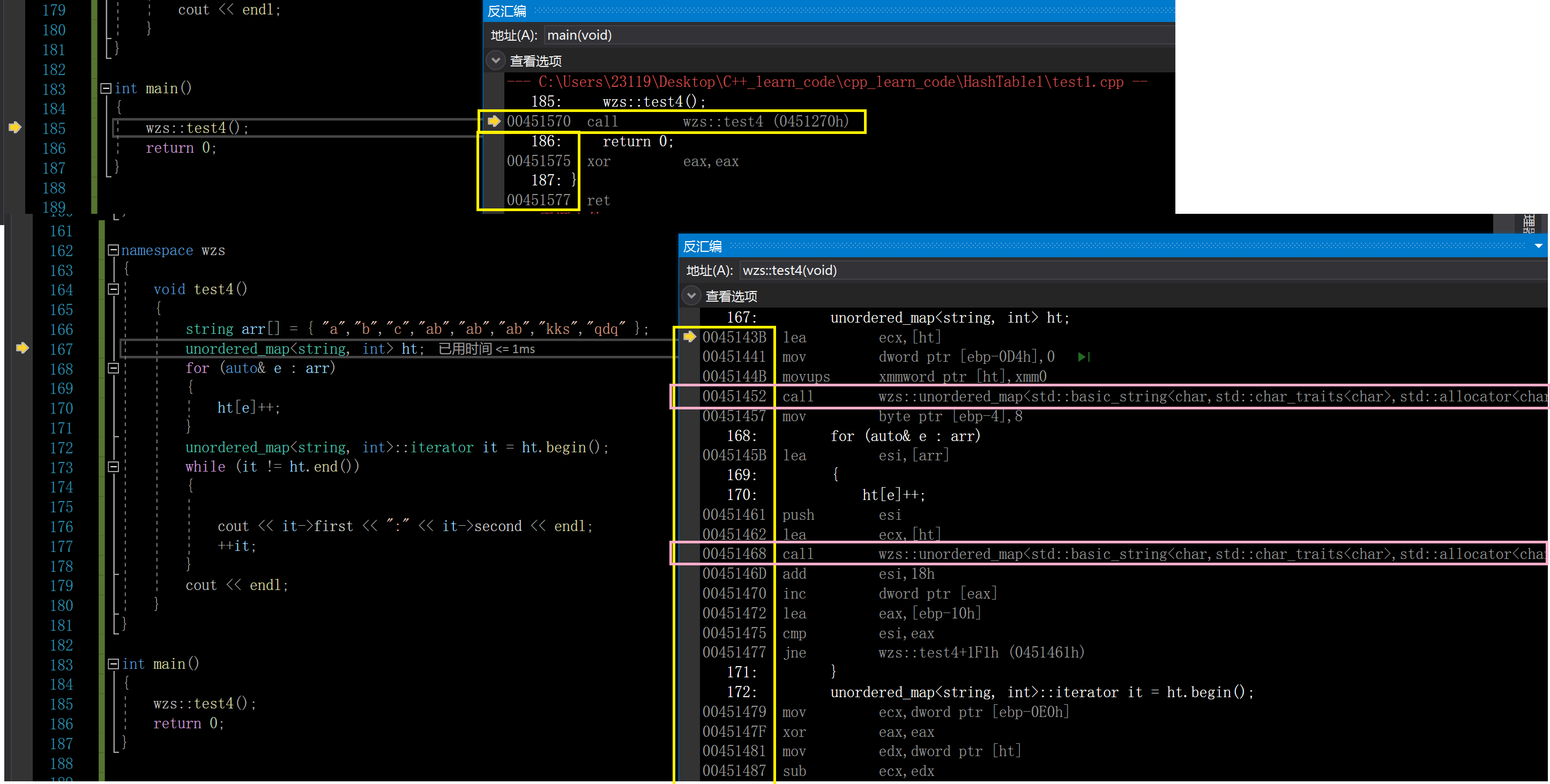

我们从反汇编当中看到了函数及其指令的地址
因此,我们可以得出可执行程序当中的代码指令本身就是有地址的
因为这些地址是被存放在可执行程序当中的,而可执行程序是被存放在磁盘当中的,因此这些地址被称为逻辑地址
那么这些地址是干什么用的呢?
可执行程序还有什么其他神奇之处吗?
不着急,我们一点一点分析
2.Linux下逻辑地址等于虚拟地址
在学习了进程地址空间之后,我们知道,我们平常在C/C++编程时用到的地址都是虚拟地址
并不是真正的物理地址,进程通过虚拟地址在页表上面的映射找到对应的物理地址
从而实现对数据的访问修改
通过C/C++的学习,我们也知道反汇编当中的地址跟我们代码当中函数/变量的地址是一样的
因此我们就可以得出
Linux下逻辑地址等于虚拟地址
我们又知道:
进程刚被创建时,是先创建进程描述结构体PCB,后将可执行程序的代码和数据加载到物理内存当中
此时我们就知道了,原来当我们的可执行程序将要被加载到物理内存当中之前,
OS创建进程PCB之后,在将可执行程序的代码和数据加载到物理内存当中的同时,在页表当中建立好虚拟地址和物理地址之间的映射
这里的虚拟地址就是可执行程序当中代码和数据的逻辑地址
但是我们又有一个疑问了,
页表当中的虚拟地址我知道是哪来的了,但是进程地址空间的区域是如何划分的呢?
其实也是从可执行程序当中读取的
下面我们就来说明一下
3.可执行程序的表头及其区域划分
可执行程序本身是有自己的格式信息的
它有一个ELF格式的表头
表头当中存放了
1.程序的入口地址(也就是main函数的地址)
2.整个可执行程序的区域划分,以及每个区域的起始地址
因此,可执行程序在执行时,OS先创建进程PCB,
然后根据可执行程序表头当中整个可执行程序的区域划分,以及每个区域的起始地址创建进程地址空间
然后将可执行程序的代码和数据加载到内存当中并在页表建立虚拟地址和物理地址的映射
那么程序的入口地址是干什么用的呢?
CPU是负责执行指令的,因此肯定跟CPU有关
4.CPU当中的程序计数器(pc指针/eip寄存器)

程序的入口地址是给pc指针的,CPU每次都执行pc指针指向的代码,读取pc指针指向的数据,pc指针从main函数开始一直往下移动,直到执行完整个程序,因此CPU就能跟着pc指针完整地执行完一个可执行程序了
5.理顺可执行程序的执行过程
刚才可能有些分散,现在我们把它串起来,带大家理清一下可执行程序是如何被进程PCB所描述的,如何被CPU所执行的
里面可能有些地方不是特别严谨,但是我们只要能弄清楚这个过程即可
我们简化一下程序的代码
假设我们只有2个函数:main,MyAdd
1.编译器进行编译生成可执行程序
首先,编译器对我们的代码进行编译,生成可执行程序
编译器编译时给每个指令,数据都分配一个逻辑地址,并且将程序的入口地址和整个可执行程序的区域划分存放在表头位置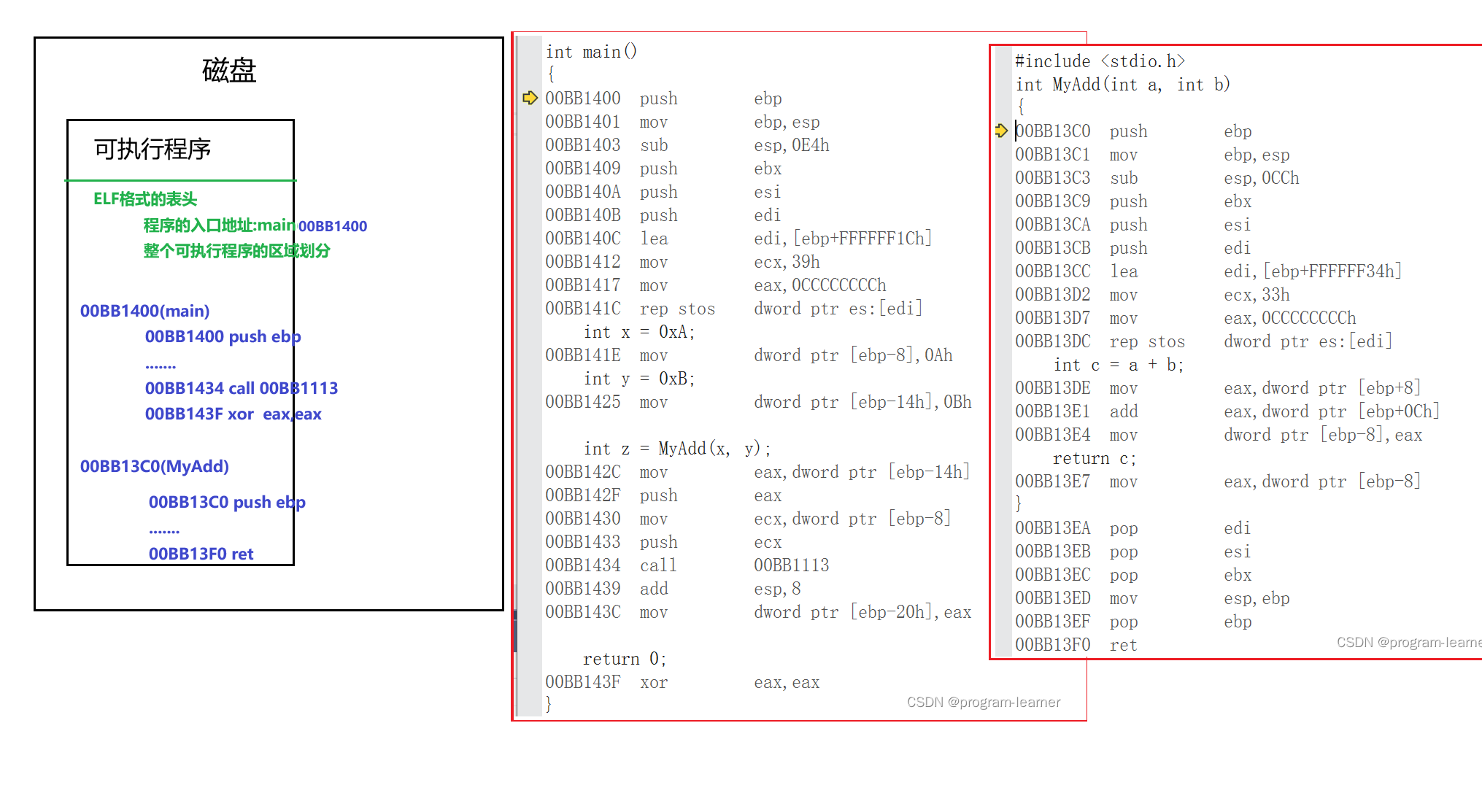
编译器生成完可执行程序之后,这个可执行程序带着表头,指令,数据,还有每个指令和数据的逻辑地址,作为一个磁盘级文件,存放在磁盘当中
当我们想要运行该可执行程序时,就要创建进程来运行该程序
进程的创建是OS的任务
2.OS根据可执行程序的信息创建进程PCB

3.CPU配合pc指针执行可执行程序的指令

6.重新理解进程地址空间
至此我们看到了,进程地址空间是由OS创建进程时进行初始化
如何初始化? 利用可执行程序当中的信息进行初始化
那些信息从哪来? 编译器编译可执行程序的时候添加上的
因此我们可以得出
进程地址空间,它不是一个单纯的内核数据结构,
它的本质是
由操作系统+编译器+计算机体系结构(CPU)三者共同配合完成的!!
7.理解静态库的静态链接和加载问题


3.理解动态库动态链接和加载问题
谈完了可执行程序有关的知识点之后,我们理解动态库的动态链接和加载的问题就能更加清晰明了了
1.理论
首先我们要先说明的是:
动态库的.o文件是采用相对编址的方式进行编址的(也就是-fPIC(产生位置无关码)这个选项的作用)
gcc -fPIC -c mymath.c

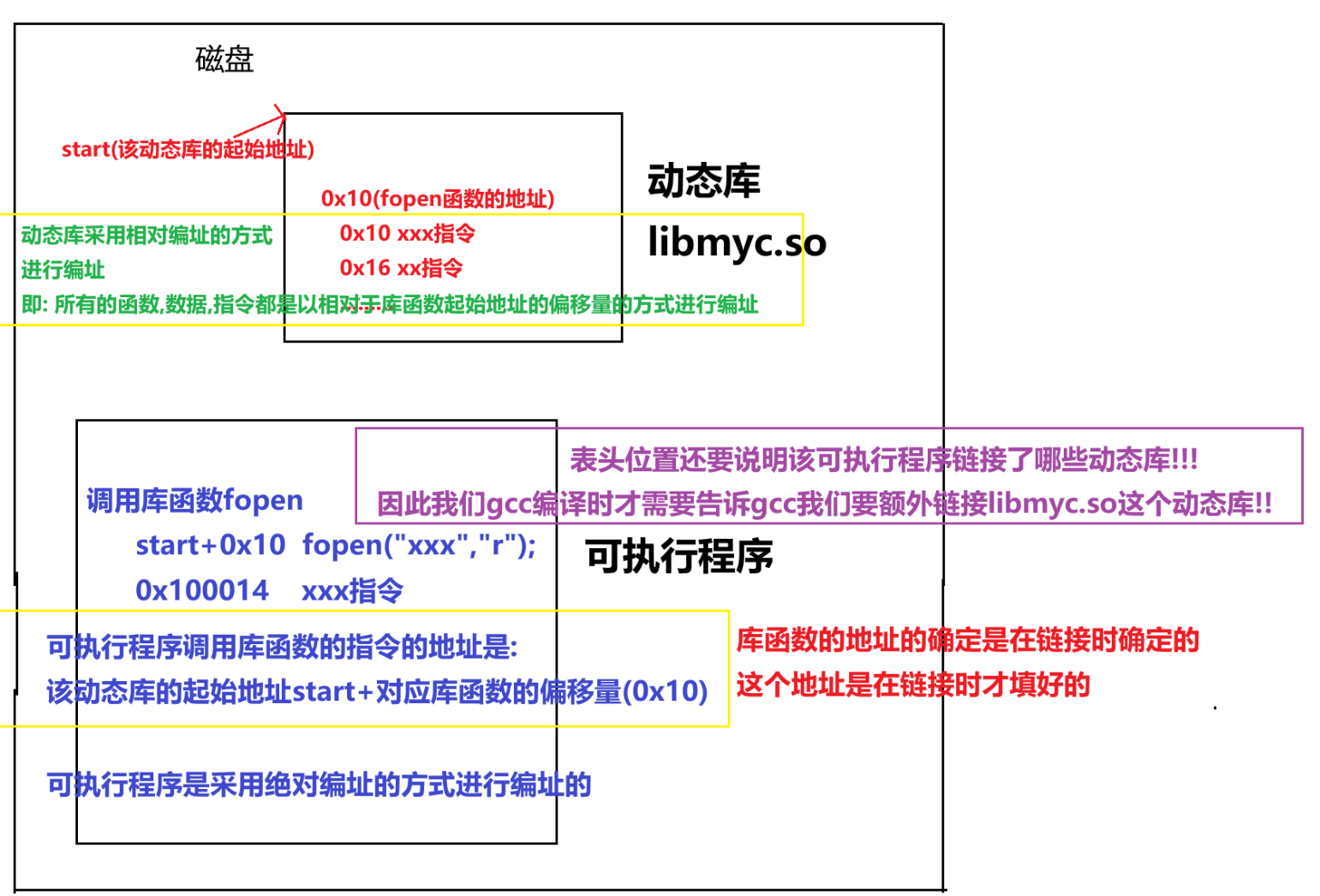

2.结论
因此我们可以得出结论:
对于动态库的数据和方法的访问,
都是可以通过该动态库在进程地址空间当中的起始地址加上偏移量的方式来进行访问
这样做有什么好处呢?
当OS创建进程地址空间,将动态库映射到共享区的时候,
无论该动态库加载到物理内存当中的什么位置,映射在共享区的什么位置,都是可以的
这样就能更充分和灵活利用虚拟地址和进程地址空间了
以上就是Linux 动静态库的制作,使用和加载的全部内容,希望能对大家有所帮助!!
版权归原作者 program-learner 所有, 如有侵权,请联系我们删除。