
前段时间 Flink table store 更名为 Apache Pimon ,并重新进入Apache incubator。截止目前,incubator-paimon项目已经在github上收获了600+ Star(https://github.com/apache/incubator-paimon):
之前虽然了解到Fink table store,但是没空去了解它,趁此机会,我也花了2天时间来专门对它探个究竟,看看到底值不值得研究。
Pimon目前只进行到0.4-SNAPSHOT的开发,社区提的Issue也很少,太少的Issus并不一定说明系统足够稳定,倒是可能表明当前使用的太不广泛。
任何新生事物要得到广泛认可,都要经历这一冷启动阶段,除非它是像GPT那样。Anyway,我们先秉承客观立场,来分析下这款产品。官网很简洁,文档也少得可怜,但是基本功能和Get-started 倒是介绍到了:

它定位是流数据湖平台(Streaming data lake platform),这点好像只有HUDI这么说自己是platform吧。比如:
Iceberg is a high-performance format for huge analytic tables;
Delta Lake is an open-source storage framework;
Apache Hudi is a transactional data lake platform that brings database and data warehouse capabilities to the data lake.
看来Paimon野心不小啊。不过,对我们使用方倒是好事,但是要做好数据湖平台,基本的能力具备吗?至少拿HUDI的能力先来过一遍:
- Transaction事务;
- row-level update/delete行级更新;
- change stream 变更流
然后,在此基础上实现以下能力:
- 数据摄取,支持批和流;
- 支持Schema evolution;
- 支持snapshot,time travel
- 统一并支持不同的存储引擎,像HDFS,S3、OSS都不用说了;
- 对接不同的计算引擎,Hive、Spark、Flink、Trino,毕竟这些是数据湖产品的标配;
- 支持批查询、OLAP查询;
- 支持增量查询;
如果能力足够,再支持一些能力,比如完善的sql能力、changlog流读流写能力、lookup点查询能力就更好了。如果说上述能力都具备,那就要拿出来练一练,看看是不是吹的?毕竟,这额外的特色功能连Iceberg都不支持,Paimon刚出茅庐,怎么敢口出狂言呢,而且我们被Iceberg坑了一次,这次得长长记性。
从Paimon的系统架构中,我们也能明白一二:
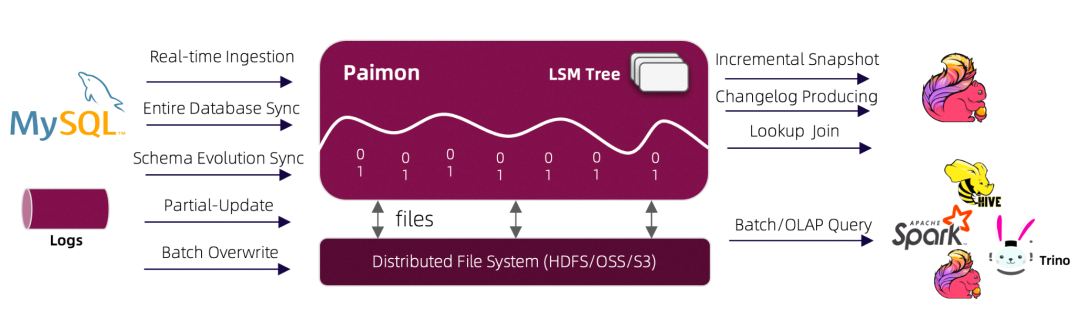
- Paimon基于HDFS、OSS、S3 ,提供了统一存储,提供统一存储的表格式也是情理之中,也是预料之中。
- Paimon内部使用了LSM。好家伙,看来LSM是Paimon的能力核心了,毕竟想提供DB级的体验,没有LSM怎么能行?至少极致的写入能力应该不用过于担心。LSM无论是理论还是工程实现在业界都比较成熟,可供借鉴的系统不要太多。差别就是具体的实现差异,比如如何解决写放大问题?何时以及如何compact?
- LSM支持范围查询和点查询能力,所以它提到Lookup join也是没有大问题的,问题是它如何进一步提升其性能了。比如可以引入二级索引bloomfilter等。
- changelog在官网中有提到,它支持将changlog写入本地文件或者发送到kafka供下游消费。
- 内核能力具备之后,外围的多模式数据导入与查询只是上层应用的事情,这块儿借助Spark、Hive、Trino、Flink就可以实现。最后就是Schema Evolution与文件组织方式了,这个在官网中也有介绍:
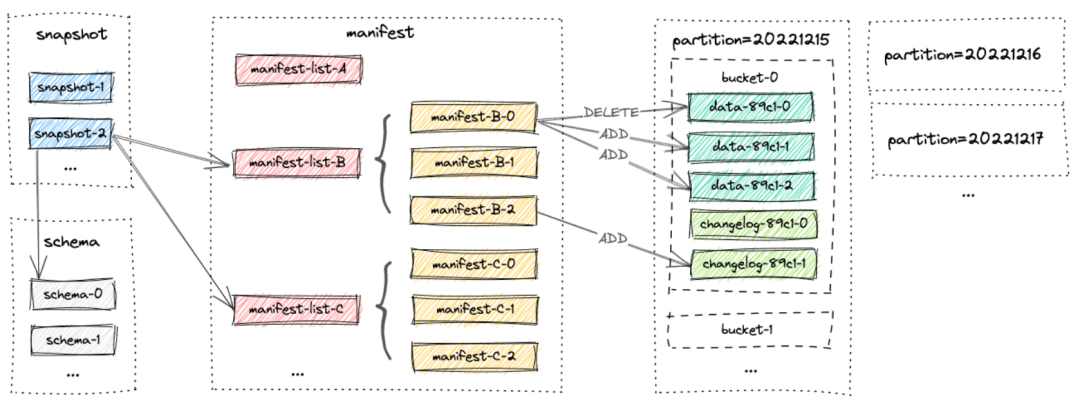
文件组织并没有亮点,直接借鉴(抄袭)Iceberg前辈的思路就好了。Schema保存在snapshot,snapshot由manifest-list组成,而manifest-list又由manifest组成,manifest由datafile组成。最底层的datafile由partition和bucket决定(定位)。在bucket中维护了LSM结构。
最后就是多模读的能力了。具备snapshot能力,自然就具备了增量(流)读的能力。LSM的支持,使得增量读和批量读的高效读取能力成为可能,因为LSM在写入后的合并阶段能够保证顺序。
关于Paimon的一些更多能力介绍,我从Paimon PMC 22年9月份的演讲中寻得蛛丝马迹,他们对Flink Table Store 设计提出了一些基本要求:
① 是一个流批统一的存储,提供一定的 OLAP 查询能力(基于列式存储),做到毫秒级别的实时流式读取,能够支持 Insert Overwrite。
这是早期设计跟Flink绑定时候的要求,从中,我们姑且相信借助Flink,基于列式存储的OLAP 查询能力是不难做到的,但是要做到极致的交互查询能力估计够呛,这是题外话,不能期待过高,暂时不表。但不意味着无法实现,要知道Clickhouse基于LSM能够提供极致的单机单表查询能力,在这方面,Paimon要达到这种能力理论上也是可能的。
毫秒级别的实时流式读取能力针对append Stream scan应该是问题不大,但是读取需要合并的更新数据流就不一定了。
② 是最为完善的 Flink Connector,支持 Flink SQL 的全部概念,支持任意 Flink Job 的输出,支持所有数据类型。
Flink table store 全面支持 Flink SQL语法,这个从字节火山引擎的使用反馈可以印证这一点,比如它在建表ddl的确支持分区、分桶、主键等能力。借助Flink实现批写入、流式写入也是没问题的。
③ 是最好用的 Flink Connector,能够结合 Flink SQL 提供 DB 级别的体验,并且支持大规模更新。
重点来了,DB级别的体验需要支持上述事务、行级更新、批更新、lookup、change stream等等,OLTP的能力大家都懂的,再加上OLAP的能力,这会是个什么系统,一般人不敢说。
在演讲后面同时也提到了 Flink Table Store后续规划的三个目标:
第一,好用的流存储。比如多作业写同时写入、Compaction 分离,比如完整的 Streaming Data Warehouse API 设计,包括完整的 DDL、Update、Delete 语法、Time Travel API 支持。以上能力将与 Flink 社区一起在 1.17 版本中重点攻克。
第二,准确的流存储。存储本身能够产生完整的 Changelog ,下游的流计算易用性才能真正得到提高。
第三,可连接的流存储。继续增强 Lookup Join ,实现二级索引以更好地 Join,实现维表对齐能力,解决维表不确定性。
如果把基本要求看做理想的话,那后续规划的目标就是现实跟理想的差距。不管理想能否实现,从理想的动员能力来看,的确起到了效果:DB级的体验多么令人向往,连我都有一种想去贡献代码的冲动了。以上就是外界获取的关于Paimon 的设计与能力,截止目前,它又有了什么样的能力以及这些能力落地的程度还需要亲自去代码里检查了,下面我就从最重要的读写模块来从代码中梳理下:
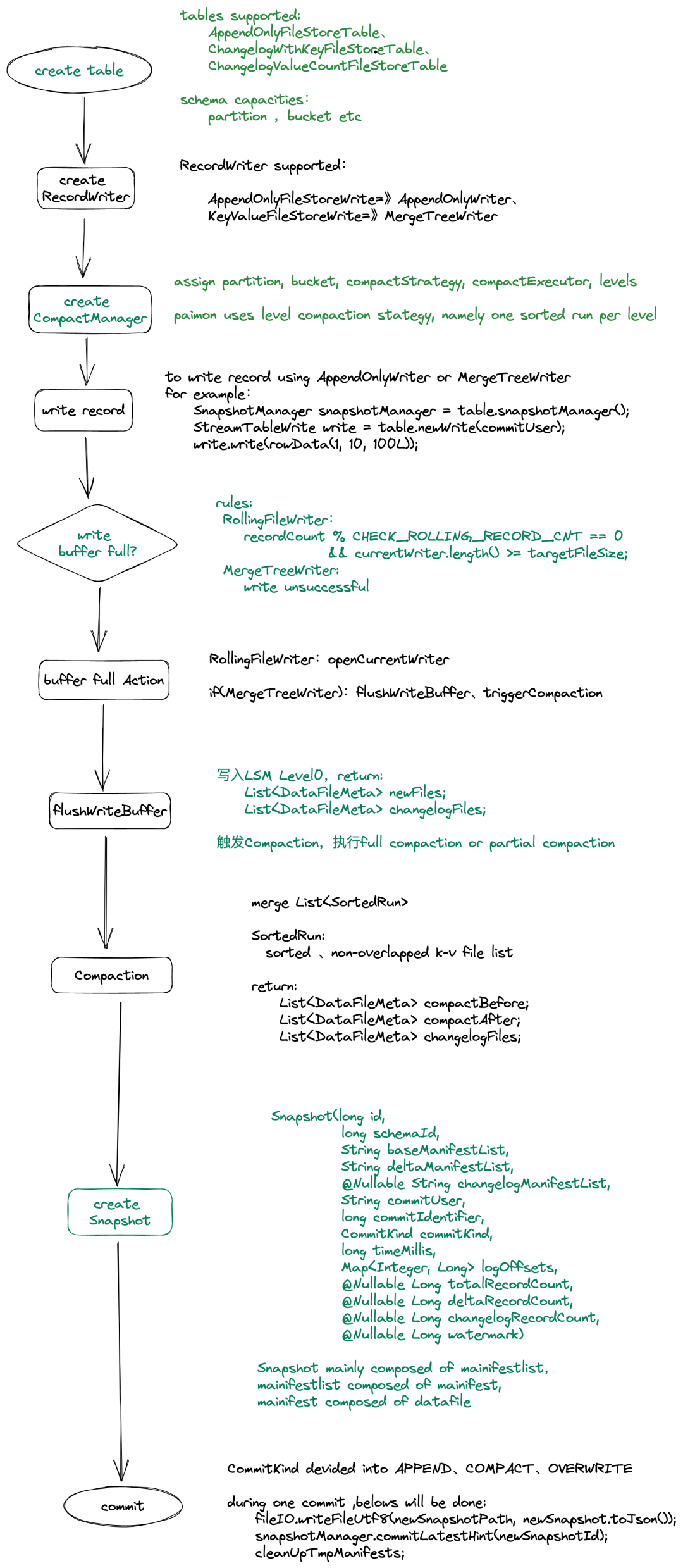
这是实现的写入的基本流程,数据是先写内存缓存表,当缓存满的时候,再flush到磁盘Level0级,同时触发LSM合并。合并完成之后,再commit生成snapshot。
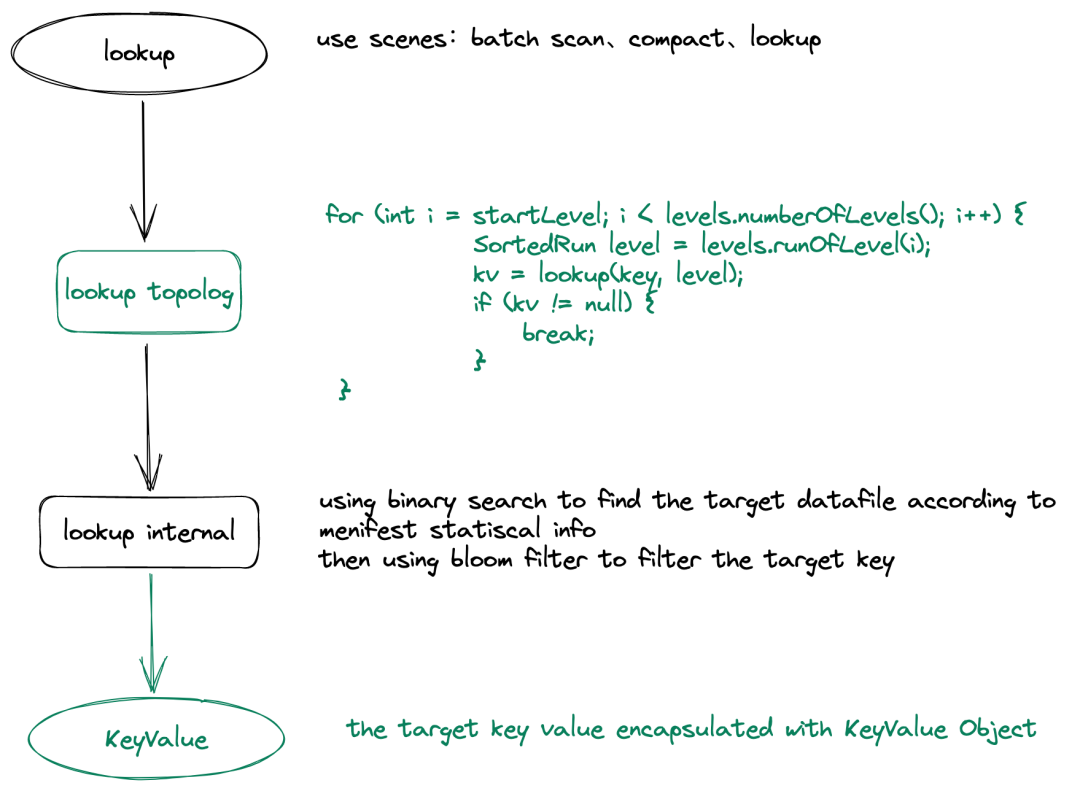
Paimon有多处涉及到读取过程,比如lookup、scan以及在compact的过程中也会涉及到读取。这里以lookup过程为例,它依次按照Level从高到低的顺序查询每个level是否命中记录。在查询每个level过程中,采用二分法定位目标记录所在的datafile元数据文件,然后通过datafile元数据文件找到物理存储文件,最后在物理文件中通过r二级索引bloomfilte定位目标记录。
总结
从上述调研情况来看,Paimon具备了Iceberg的几乎所有能力,同时引入LSM提升了使用Iceberg合并删除文件的检索能力。Paimon通过partition和bucket中引入细粒度的LSM和二级索引,提供了分布式查询能力,提供了不依赖Hbase实现lookup的可能性。Paimon支持主键、分区、分桶等的能力,以及底层存储引擎上面的列存、预排序,以及向量化查询能力,提供了不依赖Clickhouse实现极致简单查询能力的可能。Paimon目前从跟Flink的深度绑定中解脱出来,支持了多引擎,同时Paimon支持的多流join能力,有助于将状态存储在存储层中实现,从而降低Flink本身的State压力,所以Paimon 值得期待。
版权归原作者 咬定青松 所有, 如有侵权,请联系我们删除。