
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:zhuyc@vip.163.com。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
Flume实现Kafka数据持久化存储到HDFS
本文关键字:Flume、Kafka、HDFS、实时数据、存储
文章目录
一、场景描述
对于一些实时产生的数据,除了做实时计算以外,一般还需要归档保存,用于离线数据分析。使用Flume的配置可以实现对数据的处理,并按一定的时间频率存储,本例中将从Kafka中按天存储数据到HDFS的不同文件夹。
1. 数据输入
本场景中数据来自Kafka中某个Topic订阅,数据格式为json。
2. 数据管道
使用Flume作为数据处理管道,通过配置实现自定义存储规则。
3. 数据输出
最终数据将存储在HDFS中,每一天的数据将对应一个单独的文件夹。
二、组件介绍
1. Kafka
来自维基百科:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。
如果需要参考安装步骤可以点击:Kafka 3.x的解压安装 - Linux
2. Hadoop
来自维基百科:Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架,有助于使用许多计算机组成的网络来解决数据、计算密集型的问题。基于MapReduce计算模型,它为大数据的分布式存储与处理提供了一个软件框架。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。
如果需要参考安装步骤可以点击:Hadoop 3.x各模式部署 - Ubuntu
3. Flume
来自维基百科:Apache Flume是一款分布式、可靠且可用的软件,用于高效地收集、聚合和移动大量日志数据。它有一个基于流数据流的简单而灵活的体系结构。它具有健壮性和容错性,具有可调的可靠性机制以及许多故障切换和恢复机制。它使用了一个简单的可扩展数据模型,允许在线分析应用程序。
Flume的运行只需要预先配置好JDK即可,安装过程只需要解压以及环境变量的配置。
三、前置准备
1. Flume下载
- 点击Download -> 选择binary中的tar.gz

- 进入镜像地址列表,右键复制下载链接

- 使用wget下载到Linux系统
wget https://dlcdn.apache.org/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz

2. Flume安装
关于前置环境JDK的安装可以参考:Hadoop 3.x各模式部署 - Ubuntu中前置环境的部分【点击可直接跳转到指定位置】。
- Flume解压缩
tar -zvxf apache-flume-1.11.0-bin.tar.gz
- 环境变量配置
vi ~/.bashrc
exportFLUME_HOME=/path/to/apache-flume-1.11.0-bin
exportPATH=$PATH:$FLUME_HOME/bin
3. 数据源准备
可以在Kafka中创建一个新的Topic用于测试,具体步骤可以参考:Kafka 3.x的解压安装 - Linux中Console测试的部分【点击可直接跳转到指定位置】。
四、配置文件
在Flume中主要需要配置3个部分,source、channel、sink。本例中source为kafka,sink为HDFS,channel同样有多种选择。
1. 以内存为channel
- 优缺点 - 优点:速度较快,不会占用额外硬盘空间- 缺点:只依赖Kafka的偏移量记录,Flume自身不会存储偏移量信息
- 核心配置项 - agent.sources.kafka-source.batchSize:每一批次处理的数据量,可以根据需要修改- agent.sources.kafka-source.kafka.bootstrap.servers:Kafka的订阅地址,包含主机及端口号- agent.sources.kafka-source.kafka.topics:Kafka的Topic名称- agent.sinks.hdfs-sink.hdfs.path:最终数据在HDFS的保存路径,父级目录需要手动创建
- 在Flume的conf文件夹中新建配置文件kafka-memory-hdfs.conf:
# Name the components on this agent
agent.sources = kafka-source
agent.channels = memory-channel
agent.sinks = hdfs-sink
# Describe/configure the source
agent.sources.kafka-source.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafka-source.batchSize = 1000
agent.sources.kafka-source.kafka.bootstrap.servers = localhost:9092
agent.sources.kafka-source.kafka.topics = my-topic
agent.sources.kafka-source.kafka.consumer.group.id = flume-memory-hdfs
agent.sources.kafka-source.kafka.consumer.auto.offset.reset = earliest
# Describe/configure the channel
agent.channels.memory-channel.type = memory
agent.channels.memory-channel.capacity = 10000
agent.channels.memory-channel.transactionCapacity = 1000
# Describe the sink
agent.sinks.hdfs-sink.type = hdfs
agent.sinks.hdfs-sink.hdfs.path = /flume_data/%Y-%m-%d
agent.sinks.hdfs-sink.hdfs.fileSuffix = .jsonl
agent.sinks.hdfs-sink.hdfs.rollInterval = 3600
agent.sinks.hdfs-sink.hdfs.rollSize = 0
agent.sinks.hdfs-sink.hdfs.rollCount = 1000
agent.sinks.hdfs-sink.transactionCapacity = 1000
agent.sinks.hdfs-sink.hdfs.fileType = DataStream
agent.sinks.hdfs-sink.hdfs.writeFormat = Text
# Bind the source and sink to the channel
agent.sources.kafka-source.channels = memory-channel
agent.sinks.hdfs-sink.channel = memory-channel
2. 以文件为channel
- 优缺点 - 优点:可以保证数据不丢失,将数据状态保存在本地磁盘上- 缺点:会额外占用硬盘存储空间,读写速度相对较慢,需要合理移除历史文件
- 核心配置项 - agent.sources.kafka-source.batchSize:每一批次处理的数据量,可以根据需要修改- agent.sources.kafka-source.kafka.bootstrap.servers:Kafka的订阅地址,包含主机及端口号- agent.sources.kafka-source.kafka.topics:Kafka的Topic名称- agent.channels.file-channel.checkpointDir:本地磁盘路径,需要预先创建父级目录- agent.channels.file-channel.useDualCheckpoints:设置为true则开启双重机制,可额外设置一个备份路径- agent.channels.file-channel.maxFileSize:单位为字节,当达到文件大小时会自动滚动新建- agent.sinks.hdfs-sink.hdfs.path:最终数据在HDFS的保存路径,父级目录需要手动创建
- 在Flume的conf文件夹中新建配置文件kafka-file-hdfs.conf:
# Name the components on this agent
agent.sources = kafka-source
agent.channels = file-channel
agent.sinks = hdfs-sink
# Describe/configure the source
agent.sources.kafka-source.type = org.apache.flume.source.kafka.KafkaSource
agent.sources.kafka-source.batchSize = 1000
agent.sources.kafka-source.kafka.bootstrap.servers = localhost:9092
agent.sources.kafka-source.kafka.topics = my-topic
agent.sources.kafka-source.kafka.consumer.group.id = flume-file-hdfs
agent.sources.kafka-source.kafka.consumer.auto.offset.reset = earliest
# Describe/configure the channel
agent.channels.file-channel.type = file
agent.channels.file-channel.capacity = 10000
agent.channels.file-channel.transactionCapacity = 1000
agent.channels.file-channel.checkpointDir = /tmp/flume/checkpoint/
agent.channels.file-channel.backupCheckpointDir = /tmp/flume/backup/
agent.channels.file-channel.checkpointInterval = 300
agent.channels.file-channel.maxFileSize = 104857600
agent.channels.file-channel.useDualCheckpoints = true
# Describe the sink
agent.sinks.hdfs-sink.type = hdfs
agent.sinks.hdfs-sink.hdfs.path = /flume_data/%Y-%m-%d
agent.sinks.hdfs-sink.hdfs.fileSuffix = .jsonl
agent.sinks.hdfs-sink.hdfs.rollInterval = 3600
agent.sinks.hdfs-sink.hdfs.rollSize = 0
agent.sinks.hdfs-sink.hdfs.rollCount = 1000
agent.sinks.hdfs-sink.transactionCapacity = 1000
agent.sinks.hdfs-sink.hdfs.fileType = DataStream
agent.sinks.hdfs-sink.hdfs.writeFormat = Text
# Bind the source and sink to the channel
agent.sources.kafka-source.channels = file-channel
agent.sinks.hdfs-sink.channel = file-channel
五、运行测试
开始执行后,会按照预先配置的存储规则**%Y-%m-%d**,将每一天产生的数据存放在不同的文件夹,但是由于数据是分批到达的,所以每个文件夹中会有多个文件,但是这不影响数据的计算,如果需要可以合并整理。
1. 直接运行
Flume启动时可以通过conf -f参数指定配置文件,建议分配较多的内存,防止溢出:
nohup flume-ng agent -c conf -f ptah/to/kafka-memory-hdfs.conf -n agent -Dflume.root.logger=INFO,console -Xmx2g &
运行日志可以在FLUME_HOME/flume.log中找到,测试稳定后可以将进程挂在后台执行。
2. 监控运行
如果需要方便的进行指标监控,可以在启动时加入Prometheus,具体安装步骤可以查看可以自定义指标的监控工具 - Prometheus的安装部署。
- jmx环境准备
下载jar包存储在合适位置:jmx_prometheus_javaagent-0.18.0.jar
- 配置文件修改
在flume的conf配置文件中【kafka-memory-hdfs.conf/kafka-file-hdfs.conf】添加如下内容:
flume.monitoring.type = jmx
- 添加监控规则:config.yaml
新建一个config.yaml文件,存放在合适位置。
startDelaySeconds:0ssl:falselowercaseOutputName:falselowercaseOutputLabelNames:falsewhitelistObjectNames:-'org.apache.flume.*:*'blacklistObjectNames:[]
- 添加监控配置:prometheus.yml
在scrape_configs配置中增加一组和flume相关的job,修改后需要重新加载配置文件或者重启Prometheus进程
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.-job_name:"prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:-targets:["localhost:9090"]-job_name:"flume"static_configs:-targets:["localhost:9998"]
- 启动命令
在启动Flume时,额外指定jar包所在路径,以及监控规则文件所在路径,设置的端口号为9998,与Prometheus中的设置保持一致。
nohup flume-ng agent -c conf -f path/to/kafka-memory-hdfs.conf -n agent -Dflume.root.logger=INFO,console -Xmx2g -javaagent:/path/to/jmx_prometheus_javaagent-0.18.0.jar=9998:/path/to/config.yaml &
- 监控效果
部署完成后可以通过jvm_threads_state指标来查看Flume的进程状态: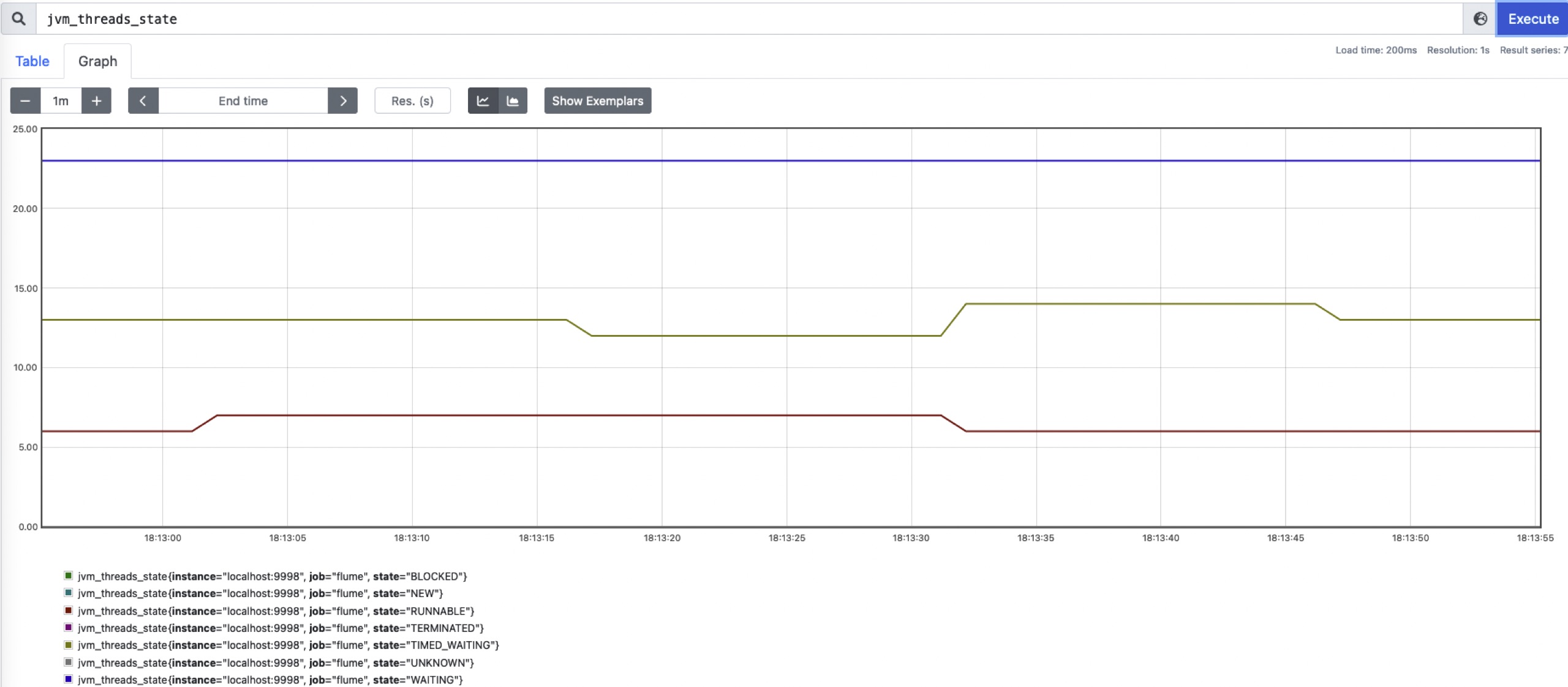
版权归原作者 一头小山猪 所有, 如有侵权,请联系我们删除。