
使用java远程提交flink任务到yarn集群
背景
由于业务需要,使用命令行的方式提交flink任务比较麻烦,要么将后端任务部署到大数据集群,要么弄一个提交机,感觉都不是很离线。经过一些调研,发现可以实现远程的任务发布。接下来就记录一下实现过程。这里用flink on yarn 的Application模式实现
环境准备
- 大数据集群,只要有hadoop就行
- 后端服务器,linux mac都行,windows不行
正式开始
1. 上传flink jar包到hdfs
去flink官网下载你需要的版本,我这里用的是flink-1.18.1,把flink lib目录下的jar包传到hdfs中。
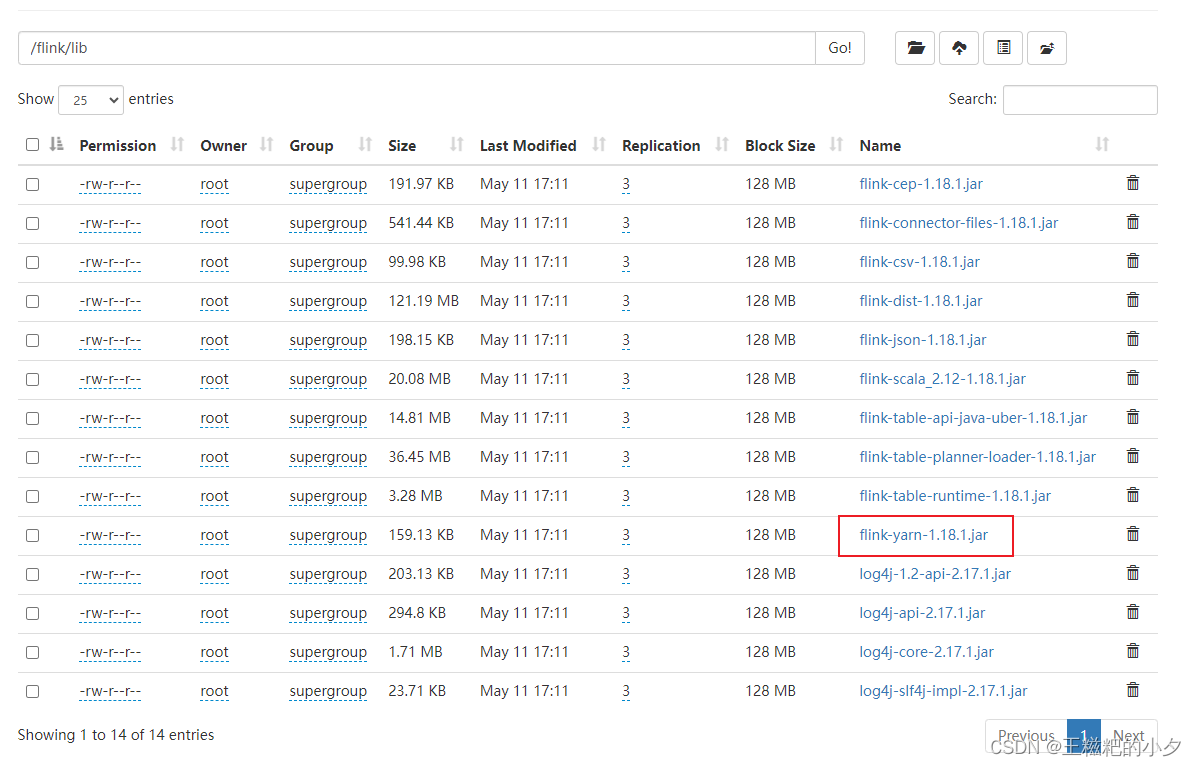
其中flink-yarn-1.18.1.jar需要大家自己去maven仓库下载。
2. 编写一段flink代码
随便写一段flink代码就行,我们目的是测试
packagecom.azt;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.source.SourceFunction;importjava.util.Random;importjava.util.concurrent.TimeUnit;publicclassWordCount{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> source = env.addSource(newSourceFunction<String>(){@Overridepublicvoidrun(SourceContext<String> ctx)throwsException{String[] words ={"spark","flink","hadoop","hdfs","yarn"};Random random =newRandom();while(true){
ctx.collect(words[random.nextInt(words.length)]);TimeUnit.SECONDS.sleep(1);}}@Overridepublicvoidcancel(){}});
source.print();
env.execute();}}
3. 打包第二步的代码,上传到hdfs
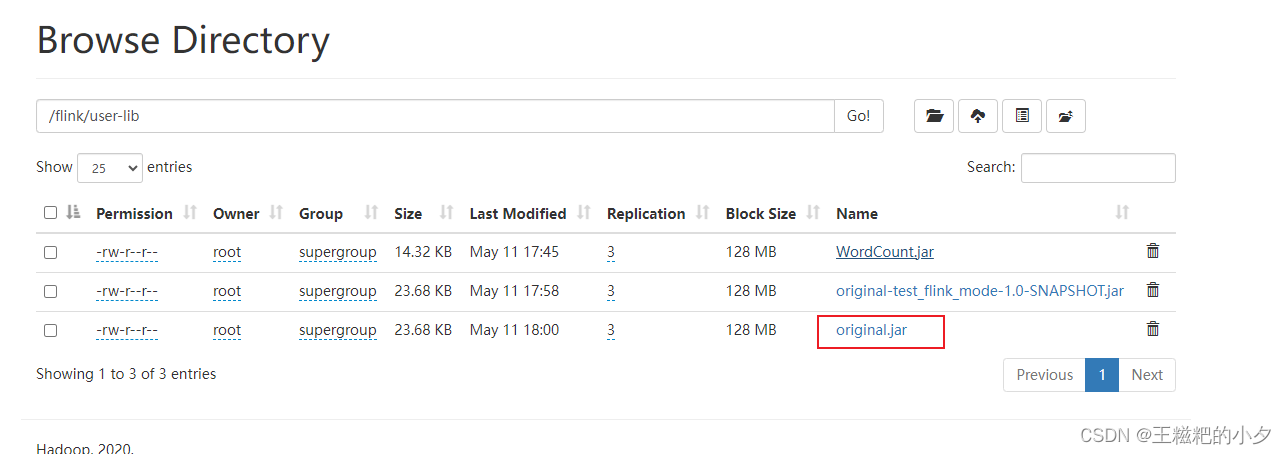
4. 拷贝配置文件
- 拷贝flink conf下的所有文件到java项目的resource中
- 拷贝hadoop配置文件到到java项目的resource中
具体看截图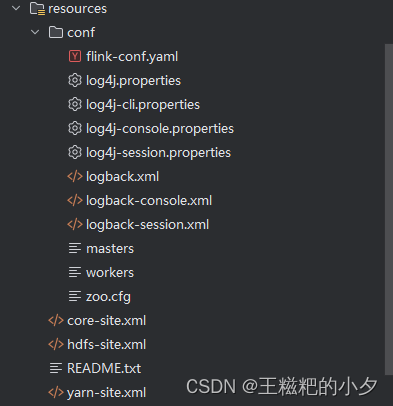
5. 编写java远程提交任务的程序
这一步有个注意的地方就是,如果你跟我一样是windows电脑,那么本地用idea提交会报错;如果你是mac或者linux,那么可以直接在idea中提交任务。
packagecom.test;importorg.apache.flink.client.deployment.ClusterDeploymentException;importorg.apache.flink.client.deployment.ClusterSpecification;importorg.apache.flink.client.deployment.application.ApplicationConfiguration;importorg.apache.flink.client.program.ClusterClient;importorg.apache.flink.client.program.ClusterClientProvider;importorg.apache.flink.configuration.*;importorg.apache.flink.runtime.client.JobStatusMessage;importorg.apache.flink.yarn.YarnClientYarnClusterInformationRetriever;importorg.apache.flink.yarn.YarnClusterDescriptor;importorg.apache.flink.yarn.YarnClusterInformationRetriever;importorg.apache.flink.yarn.configuration.YarnConfigOptions;importorg.apache.flink.yarn.configuration.YarnDeploymentTarget;importorg.apache.flink.yarn.configuration.YarnLogConfigUtil;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.yarn.api.records.ApplicationId;importorg.apache.hadoop.yarn.client.api.YarnClient;importorg.apache.hadoop.yarn.conf.YarnConfiguration;importjava.util.ArrayList;importjava.util.Collection;importjava.util.Collections;importjava.util.List;importjava.util.concurrent.CompletableFuture;importstaticorg.apache.flink.configuration.MemorySize.MemoryUnit.MEGA_BYTES;/**
* @date :2021/5/12 7:16 下午
*/publicclassMain{publicstaticvoidmain(String[] args)throwsException{///home/root/flink/lib/libSystem.setProperty("HADOOP_USER_NAME","root");// String configurationDirectory = "C:\\project\\test_flink_mode\\src\\main\\resources\\conf";String configurationDirectory ="/export/server/flink-1.18.1/conf";org.apache.hadoop.conf.Configuration conf =neworg.apache.hadoop.conf.Configuration();
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
conf.set("fs.file.impl",org.apache.hadoop.fs.LocalFileSystem.class.getName());String flinkLibs ="hdfs://node1.itcast.cn/flink/lib";String userJarPath ="hdfs://node1.itcast.cn/flink/user-lib/original.jar";String flinkDistJar ="hdfs://node1.itcast.cn/flink/lib/flink-yarn-1.18.1.jar";YarnClient yarnClient =YarnClient.createYarnClient();YarnConfiguration yarnConfiguration =newYarnConfiguration();
yarnClient.init(yarnConfiguration);
yarnClient.start();YarnClusterInformationRetriever clusterInformationRetriever =YarnClientYarnClusterInformationRetriever.create(yarnClient);//获取flink的配置Configuration flinkConfiguration =GlobalConfiguration.loadConfiguration(
configurationDirectory);
flinkConfiguration.set(CheckpointingOptions.INCREMENTAL_CHECKPOINTS,true);
flinkConfiguration.set(PipelineOptions.JARS,Collections.singletonList(
userJarPath));YarnLogConfigUtil.setLogConfigFileInConfig(flinkConfiguration,configurationDirectory);Path remoteLib =newPath(flinkLibs);
flinkConfiguration.set(YarnConfigOptions.PROVIDED_LIB_DIRS,Collections.singletonList(remoteLib.toString()));
flinkConfiguration.set(YarnConfigOptions.FLINK_DIST_JAR,
flinkDistJar);//设置为application模式
flinkConfiguration.set(DeploymentOptions.TARGET,YarnDeploymentTarget.APPLICATION.getName());//yarn application name
flinkConfiguration.set(YarnConfigOptions.APPLICATION_NAME,"jobname");//设置配置,可以设置很多
flinkConfiguration.set(JobManagerOptions.TOTAL_PROCESS_MEMORY,MemorySize.parse("1024",MEGA_BYTES));
flinkConfiguration.set(TaskManagerOptions.TOTAL_PROCESS_MEMORY,MemorySize.parse("1024",MEGA_BYTES));
flinkConfiguration.set(TaskManagerOptions.NUM_TASK_SLOTS,4);
flinkConfiguration.setInteger("parallelism.default",4);ClusterSpecification clusterSpecification =newClusterSpecification.ClusterSpecificationBuilder().createClusterSpecification();// 设置用户jar的参数和主类ApplicationConfiguration appConfig =newApplicationConfiguration(args,"com.azt.WordCount");YarnClusterDescriptor yarnClusterDescriptor =newYarnClusterDescriptor(
flinkConfiguration,
yarnConfiguration,
yarnClient,
clusterInformationRetriever,true);ClusterClientProvider<ApplicationId> clusterClientProvider =null;try{
clusterClientProvider = yarnClusterDescriptor.deployApplicationCluster(
clusterSpecification,
appConfig);}catch(ClusterDeploymentException e){
e.printStackTrace();}ClusterClient<ApplicationId> clusterClient = clusterClientProvider.getClusterClient();System.out.println(clusterClient.getWebInterfaceURL());ApplicationId applicationId = clusterClient.getClusterId();System.out.println(applicationId);Collection<JobStatusMessage> jobStatusMessages = clusterClient.listJobs().get();int counts =30;while(jobStatusMessages.size()==0&& counts >0){Thread.sleep(1000);
counts--;
jobStatusMessages = clusterClient.listJobs().get();if(jobStatusMessages.size()>0){break;}}if(jobStatusMessages.size()>0){List<String> jids =newArrayList<>();for(JobStatusMessage jobStatusMessage : jobStatusMessages){
jids.add(jobStatusMessage.getJobId().toHexString());}System.out.println(String.join(",",jids));}}}
由于我这里是windows电脑,所以我打包放到服务器上去运行
执行命令 :
java -cp test_flink_mode-1.0-SNAPSHOT.jar com.test.Main
不出以外的话,会打印如下日志
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
http://node2:33811
application_1715418089838_0017
6d4d6ed5277a62fc9a3a274c4f34a468
复制打印的url连接,就可以打开flink的webui了,在yarn的前端页面中也可以看到flink任务。
本文转载自: https://blog.csdn.net/weixin_43039757/article/details/138812778
版权归原作者 王糍粑的小夕 所有, 如有侵权,请联系我们删除。
版权归原作者 王糍粑的小夕 所有, 如有侵权,请联系我们删除。