
HDFS编程实践(Hadoop3.1.3)
HDFS编程实践(Hadoop3.1.3)
Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核心组件之一,如果已经安装了 Hadoop,其中就已经包含了 HDFS 组件,不需要另外安装。
接下来介绍Linux操作系统中关于HDFS文件操作的常用Shell命令,利用Web界面查看和管理Hadoop文件系统,以及利用Hadoop提供的Java API进行基本的文件操作。
我们需要启动Hadoop(版本是Hadoop3.1.3)。执行如下命令:
cd /usr/local/hadoop # 进入 Hadoop 安装目录
./sbin/start-dfs.sh # 启动 Hadoop 集群
一、利用Shell命令与HDFS进行交互
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。总共有三种shell命令方式。
hadoop fs
、
hadoop dfs
、
hdfs dfs
,其中
hadoop fs
适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs
只能适用于HDFS文件系统,
hdfs dfs
跟
hadoop dfs
的命令作用一样,也只能适用于HDFS文件系统。
我们可以在终端输入如下命令(先使用
cd
命令进入 Hadoop 安装目录),查看
fs
总共支持了哪些命令:
./bin/hadoop fs
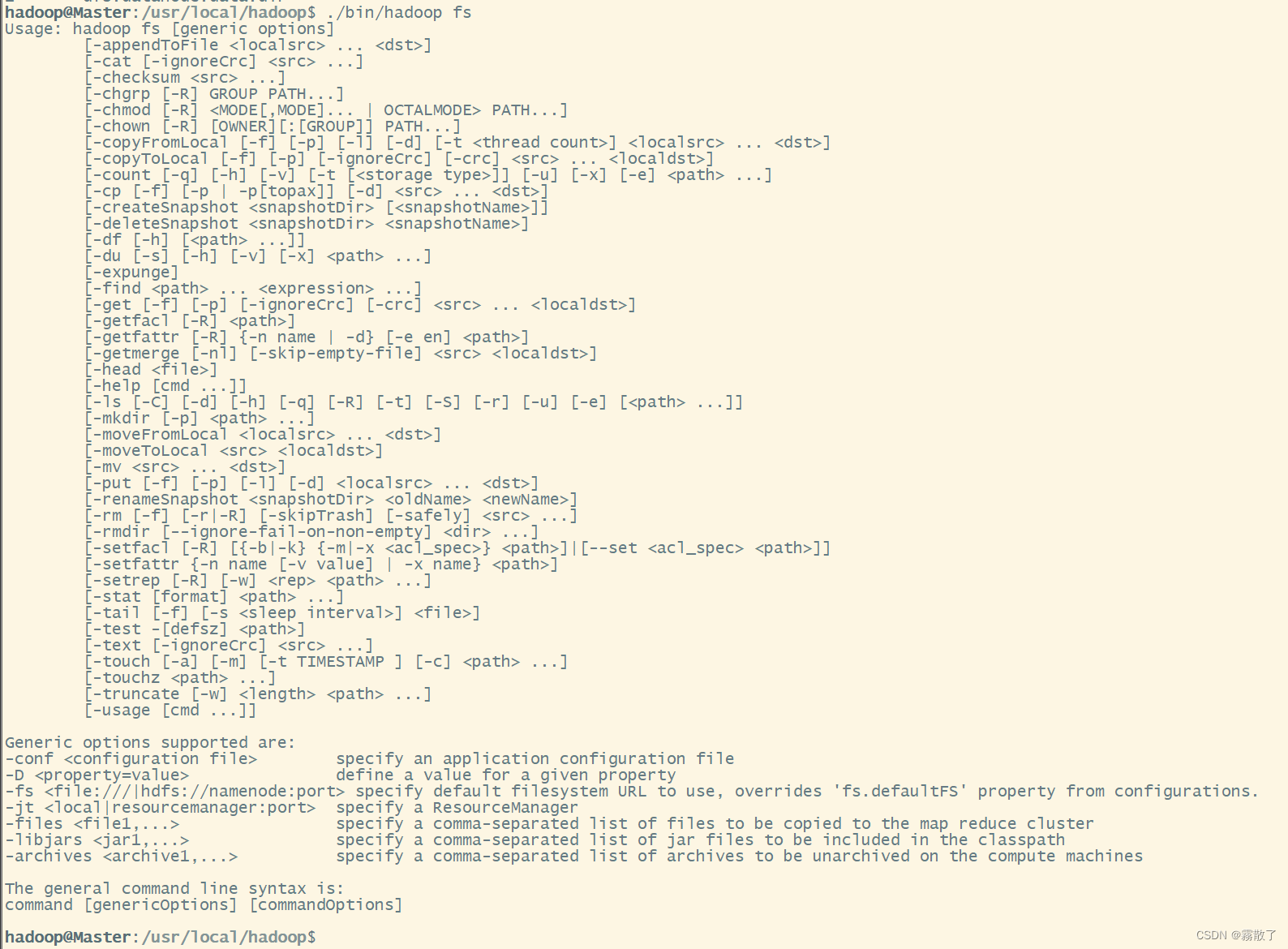
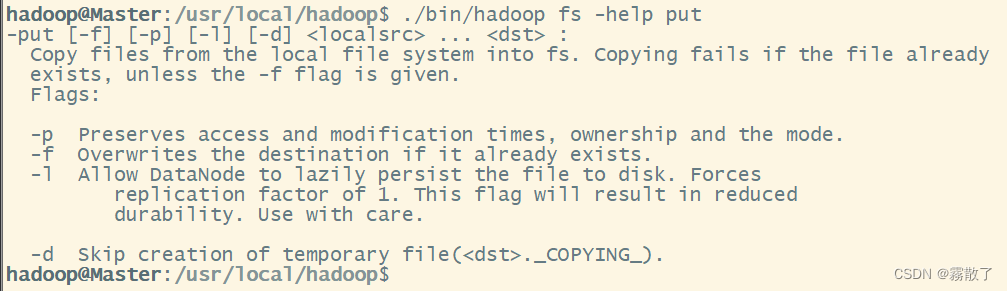
在终端输入如下命令,可以查看具体某个命令的作用,例如:我们查看put命令如何使用,可以输入如下命令
./bin/hadoop fs -help put
1、目录操作
Hadoop 系统安装好以后,第一次使用 HDFS 时,需要首先在 HDFS 中创建用户目录。我这里全部采用 hadoop 用户登录 Linux 系统,因此,需要在 HDFS 中为 hadoop 用户创建一个用户目录,命令如下:
cd /usr/local/hadoop # 进入 Hadoop 安装目录
./bin/hdfs dfs -mkdir -p /user/hadoop # 创建 hadoop 用户目录
该命令中表示在 HDFS 中创建一个
/user/hadoop
目录,
-mkdir
是创建目录的操作,-p 表示如果是多级目录,则父目录和子目录一起创建,这
/user/hadoop
就是一个多级目录,因此必须使用参数
-p
,否则会出错。

/user/hadoop
目录就成为 hadoop 用户对应的用户目录,可以使用如下命令显示 HDFS 中与当前用户 hadoop 对应的用户目录下的内容:
./bin/hdfs dfs -ls .
该命令中,
-ls
表示列出HDFS某个目录下的所有内容,
.
表示 HDFS 中的当前工作目录,也就是
/user/hadoop
目录

既然如此,我们还可以用下面命令来查看
/user/hadoop
目录:
./bin/hdfs dfs -ls /user/hadoop

可以看到上面两张图的效果是一摸一样的,因此,上面的两条命令在这条件下便是等价的。
如果要列出 HDFS 上的所有目录,可以使用如下命令:
./bin/hdfs dfs -ls

下面,可以使用如下命令创建一个 input 目录:
./bin/hdfs dfs -mkdir input
在创建个 input 目录时,采用了相对路径形式,实际上,这个 input 目录创建成功以后,它在 HDFS 中的完整路径是
/user/hadoop/input
。

因为在之前的 Hadoop 执行分布式实例的时候已经创建过
/user/hadoop/input
目录了,所以这里会显示目录已存在。
如果要在 HDFS 的根目录下创建一个名称为 input 的目录,则需要使用如下命令:
./bin/hdfs dfs -mkdir /input
先看使用命令前,在
/
下是不存在
input
这个目录的
在使用了
./bin/hdfs dfs -mkdir /input
命令之后,我们再看
/
目录下有
input
目录被创建了

可以使用
rm
命令删除一个目录,比如,可以使用如下命令删除刚才在 HDFS 中创建的
/input
目录(不是
/user/hadoop/input
目录):
./bin/hdfs dfs -rm -r /input
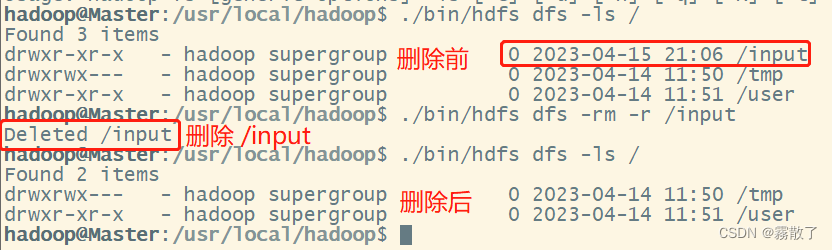
上面命令中,
-r
参数表示如果删除
/input
目录及其子目录下的所有内容,如果要删除的一个目录包含了子目录,则必须使用
-r
参数,否则会执行失败。
2、文件操作
在实际应用中,经常需要从本地文件系统向 HDFS 中上传文件,或者把 HDFS 中的文件下载到本地文件系统中。首先,使用 vim 编辑器,在本地 Linux 文件系统的
/home/hadoop/
目录下创建一个文件
myLocalFile.txt
文件
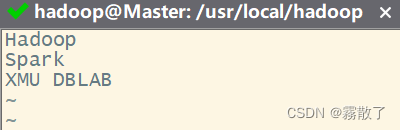
vim myLocalFile.txt
里面可以随意输入一些单词,比如,输入如下三行:
Hadoop
Spark
XMU DBLAB
然后,可以使用如下命令把本地文件系统的
/home/hadoop/myLocalFile.txt
上传到 HDFS 中的当前用户目录的
input
目录下,也就是上传到HDFS的
/user/hadoop/input/
目录下:
./bin/hdfs dfs -put /home/hadoop/myLocalFile.txt input
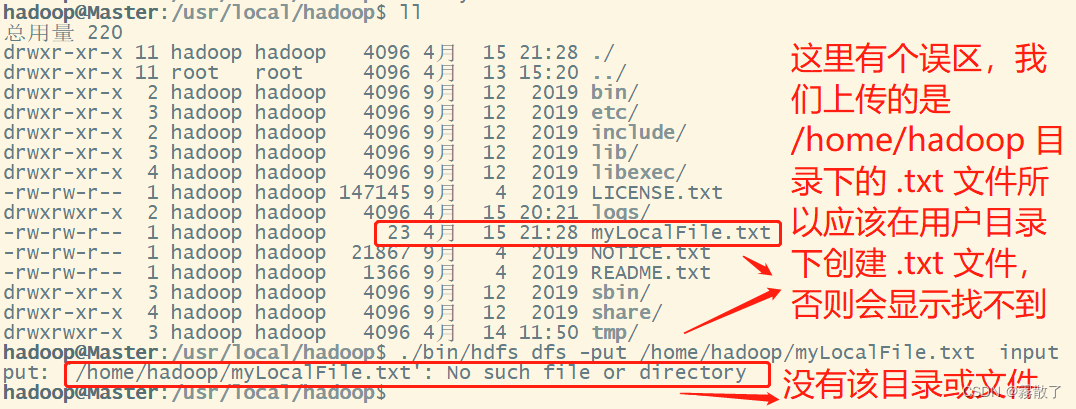
所以正确的步骤是:
cd# 进入用户目录vim myLocalFile.txt # 新建 myLocalFile.txt 文件cd /usr/local/hadoop # 进入 hadoop 安装目录
./bin/hdfs dfs -put /home/hadoop/myLocalFile.txt input
查看用户目录是否已经存在
myLocalFile.txt
文件:
ll ~ |grep my

如图所示就已经是上传成功了,看起来像是报错,其实是正常的
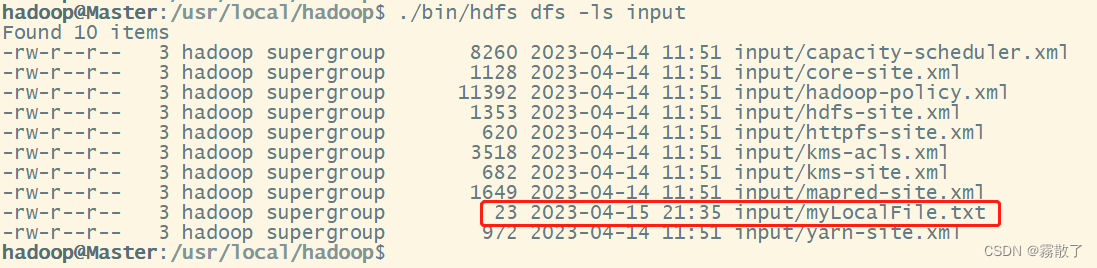
我们可以用下面命令来查看是否已经上传成功:
./bin/hdfs dfs -ls input
下面红框框的地方就是我上传的文件了。
如果想查看我们上传的文件内容,可以使用
cat
命令来查看,输入下面内容:
./bin/hdfs dfs -cat input/myLocalFile.txt
可以看到我们输入文件的内容就被显示出来了。

下面把HDFS中的
myLocalFile.txt
文件下载到本地文件系统中的
/home/hadoop/下载/
这个目录下,首先需要先看看大家安装的 Ubuntu 是中文版还是英文版的,这个是有差距的,我的是中文版,所以我这里的显示的是
下载
,如果是英文版,可以将目录改为
/home/hadoop/Downloads

再来查看一下
/home/hadoop/下载/
目录下有没有我们需要下载的文件,输入下面命令:
ll ~/下载/ |grep myLocalFile.txt
这里的
|
是连接两个命令的意思,就是在
|
前面的命令的结果连接上后面的命令,多用于在查找指定文件的指定内容。
grep
是过滤的意思,我将要查找的字符串卸载后面,如果有,则会用红色标红并显示出来;如果没有,则会如下图所示。据此可知,在
/home/hadoop/下载/
目录下,是没有
myLocalFile.txt
文件存在的。

接下来我们使用下面命令将文件下载到
/home/hadoop/下载/
目录下:
./bin/hdfs dfs -get input/myLocalFile.txt /home/hadoop/下载
然后我们使用
ll
、
grep
、
cat
命令可以查找并且查看文件内容,具体的命令如下:
ll ~/下载/ |grep myLocalFile.txt # 在 ~/下载/ 目录下查找 myLocalFile.txt 文件cat ~/下载/myLocalFile.txt # 查看 ~/下载/ 目录下 myLocalFile.txt 的文件内容
文件
myLocalFile.txt
已经下载到
/home/hadoop/下载/
目录下了,并且文件内容也一致。具体效果如下图所示:

最后,了解一下如何把文件从 HDFS 中的一个目录拷贝到 HDFS 中的另外一个目录。比如,如果要把 HDFS 的
/user/hadoop/input/myLocalFile.txt
文件,拷贝到 HDFS 的另外一个目录
/input
中(注意,这个 input 目录位于 HDFS 根目录下),可以使用如下命令:
./bin/hdfs dfs -cp input/myLocalFile.txt /input

然后使用
ls
、
grep
、
cat
命令查看是否
myLocalFile.txt
文件是否已经复制过去,并且查看文件内容是否对应。
./bin/hdfs dfs -ls input/ |grep myLocalFile.txt
./bin/hdfs dfs -cat input/myLocalFile.txt

二、利用Web界面管理HDFS
打开Linux自带的Firefox浏览器,点击此链接HDFS的Web界面,即可看到HDFS的web管理界面。WEB界面的访问地址是http://localhost:9870。
Overview 界面: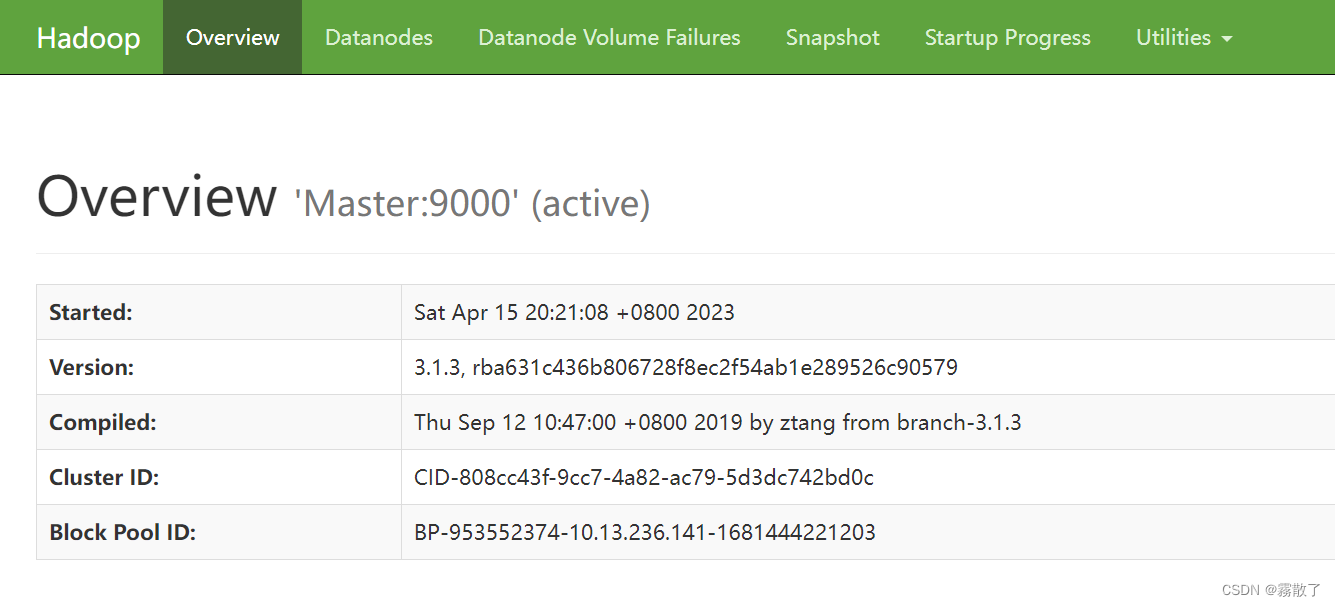
Datanode 界面: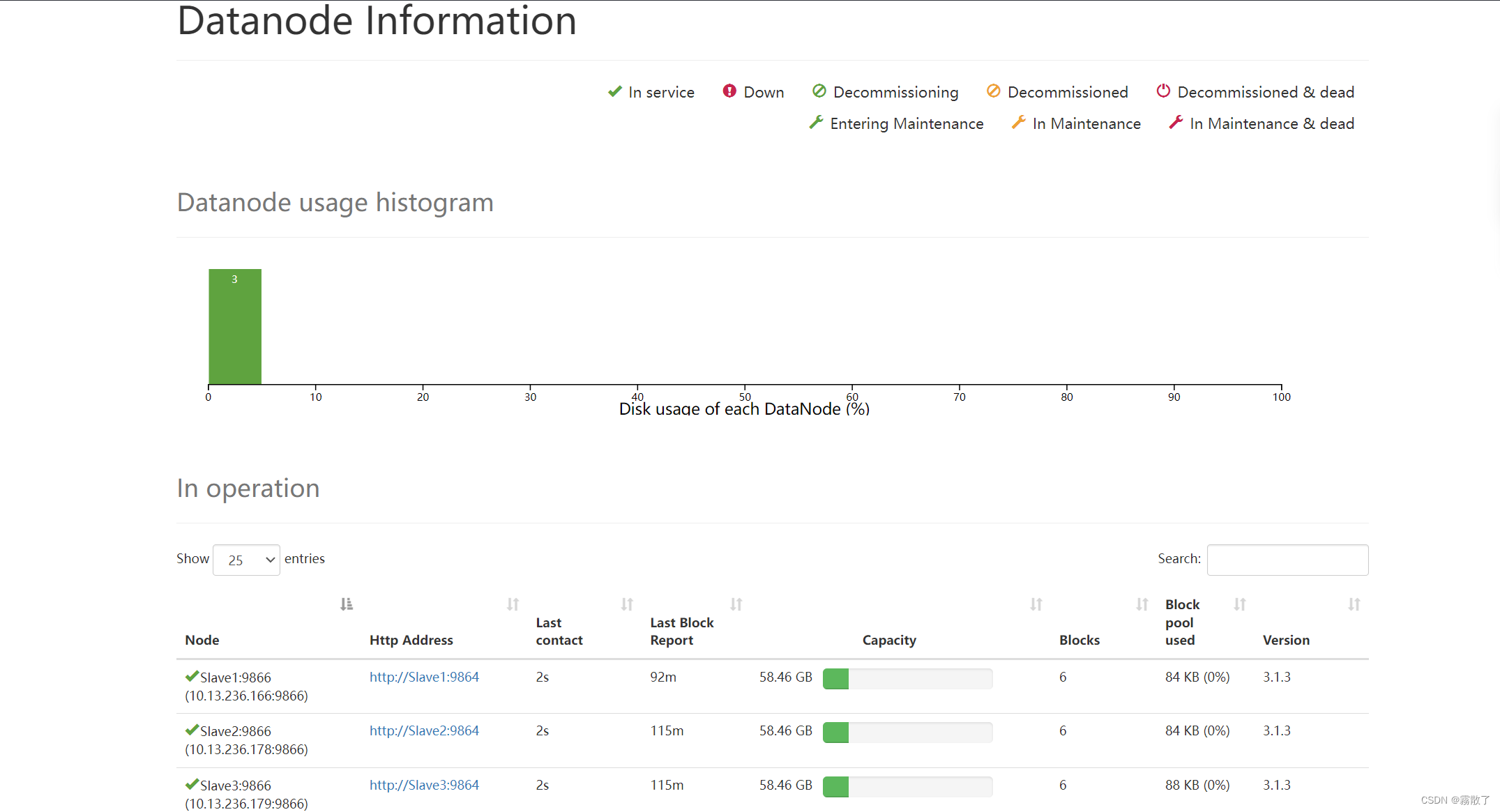
Browse Directory 界面: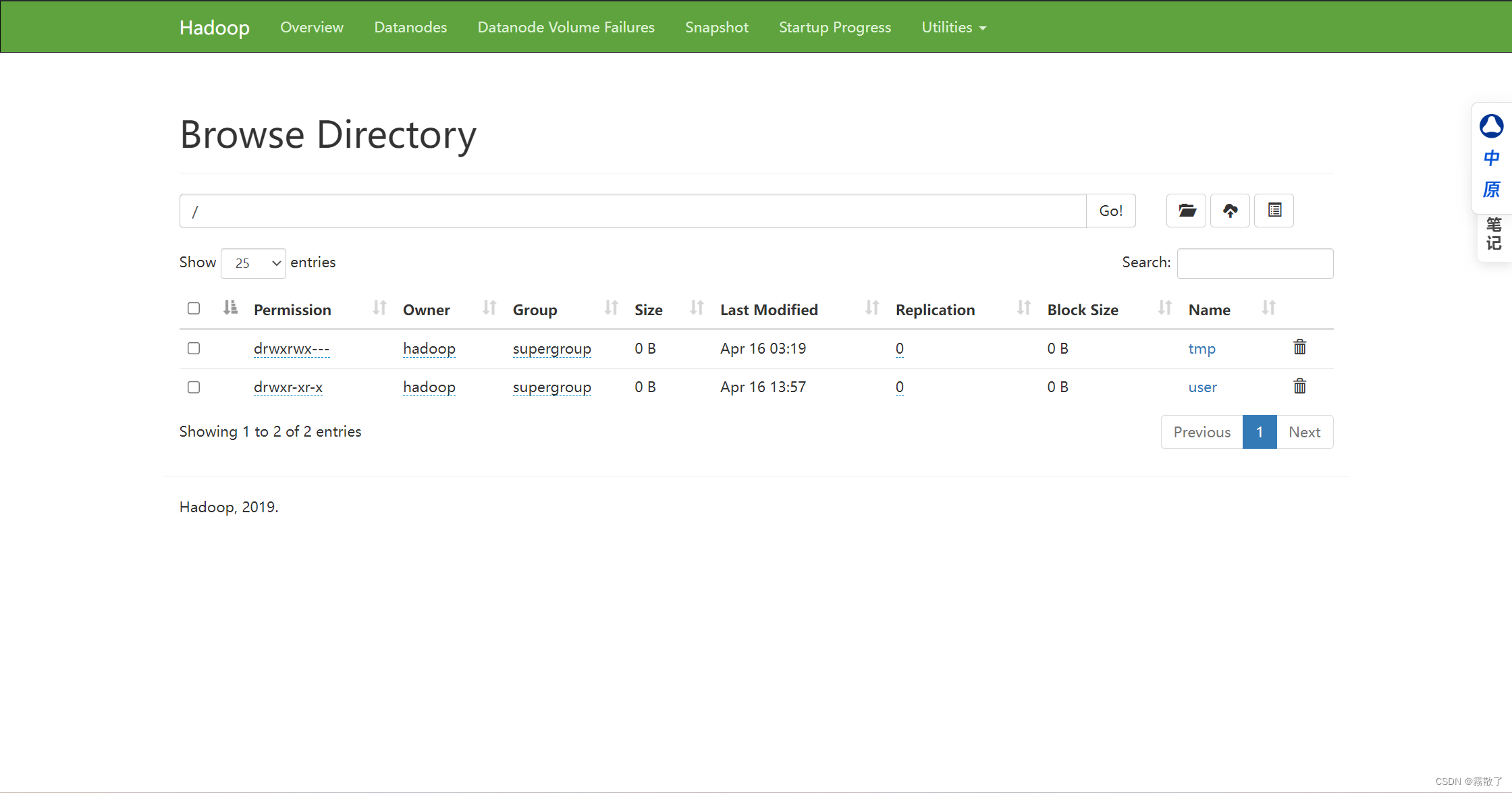
About the Cluster 界面: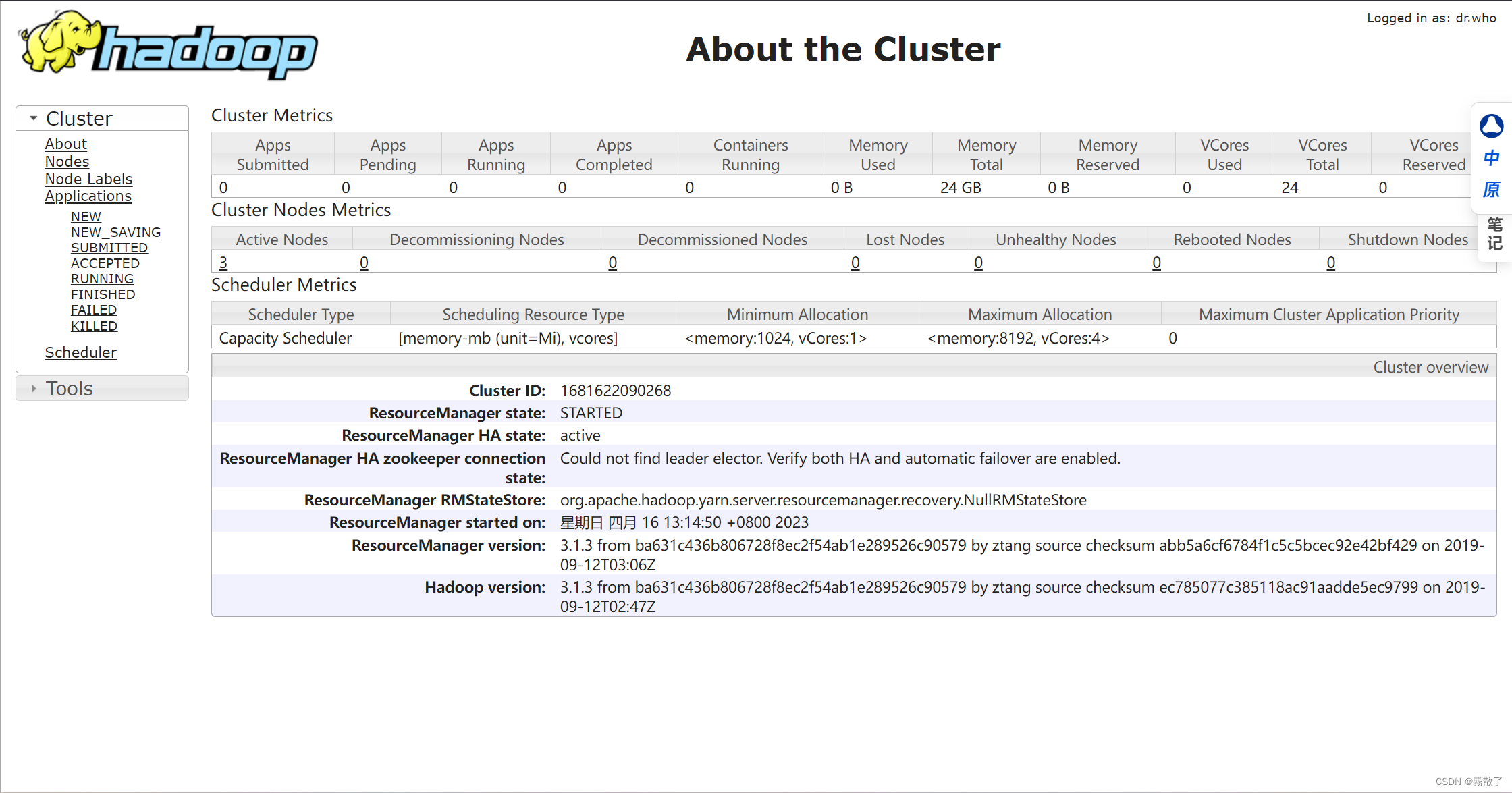
三、利用 Java API 与 HDFS 进行交互
Hadoop不同的文件系统之间通过调用Java API进行交互,上面介绍的Shell命令,本质上就是Java API的应用。下面提供了Hadoop官方的Hadoop API文档,想要深入学习Hadoop,可以访问如下网站,查看各个API的功能。
Hadoop API文档
利用Java API进行交互,需要利用软件Eclipse编写Java程序。
(一) 在 Ubuntu 中安装 Eclipse
Eclipse 是常用的程序开发工具,本教程很多程序代码都是使用 Eclipse 开发调试,因此,需要在 Linux 系统中安装 Eclipse。可以到 Eclipse 官网(https://www.eclipse.org/downloads/)下载安装包。假设安装文件下载后保存在了Linux系统的目录
~/下载
下,下面执行如下命令对文件进行解压缩:
cd ~/下载
sudotar -zxvf ./eclipse-4.7.0-linux.gtk.x86_64.tar.gz -C /usr/local
如果没有报错那就是成功了,然后我们用
ls
、
grep
命令来查看 Eclipse 是否已经成功安装到
/usr/local
目录下:
ll /usr/local/ |grep eclipse

然后,执行如下命令启动Eclipse:
cd /usr/local/eclipse # 进入 Eclipse 安装目录
./eclipse # 运行 Eclipse
这时我们就能看到 Eclipse 的启动界面了:

(二) 使用 Eclipse 开发调试 HDFS Java 程序
Hadoop 采用 Java 语言开发的,提供了 Java API 与 HDFS 进行交互。上面介绍的 Shell 命令,在执行时实际上会被系统转换成 Java API 调用。Hadoop 官方网站提供了完整的 Hadoop API 文档(http://hadoop.apache.org/docs/stable/api/),想要深入学习 Hadoop 编程,可以访问 Hadoop 官网查看各个 API 的功能和用法。这里只介绍基础的 HDFS 编程。为了提高程序编写和调试效率,我们将采用 Eclipse 工具编写 Java 程序。现在要执行的任务是:假设在目录
hdfs://localhost:9000/user/hadoop
下面有几个文件,分别是
file1.txt
、
file2.txt
、
file3.txt
、
file4.abc
和
file5.abc
,这里需要从该目录中过滤出所有后缀名不为
.abc
的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件
hdfs://localhost:9000/user/hadoop/merge.txt
中。
1. 在Eclipse中创建项目
启动Eclipse。当Eclipse启动以后,会弹出如下图所示界面,提示设置工作空间(workspace):
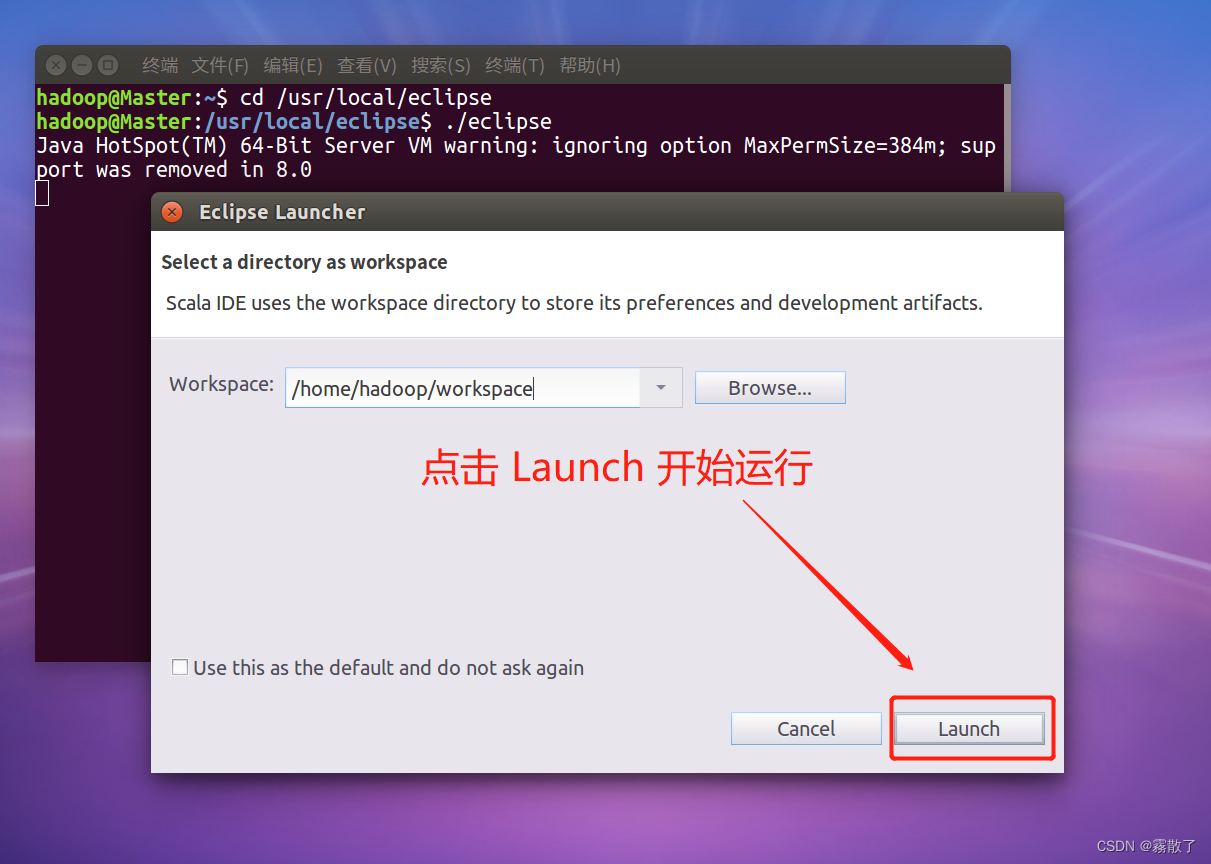
可以直接采用默认的设置
/home/hadoop/workspace
,点击
Launch
按钮。可以看出,由于当前是采用 hadoop 用户登录了 Linux 系统,因此,默认的工作空间目录位于 hadoop 用户目录
/home/hadoop
下。Eclipse启动以后,会呈现如下图所示的界面:
选择
File-->New-->Project
菜单,开始创建一个 Java 工程,会弹出如下图所示界面:
然后选择
Java Project --> Next
:
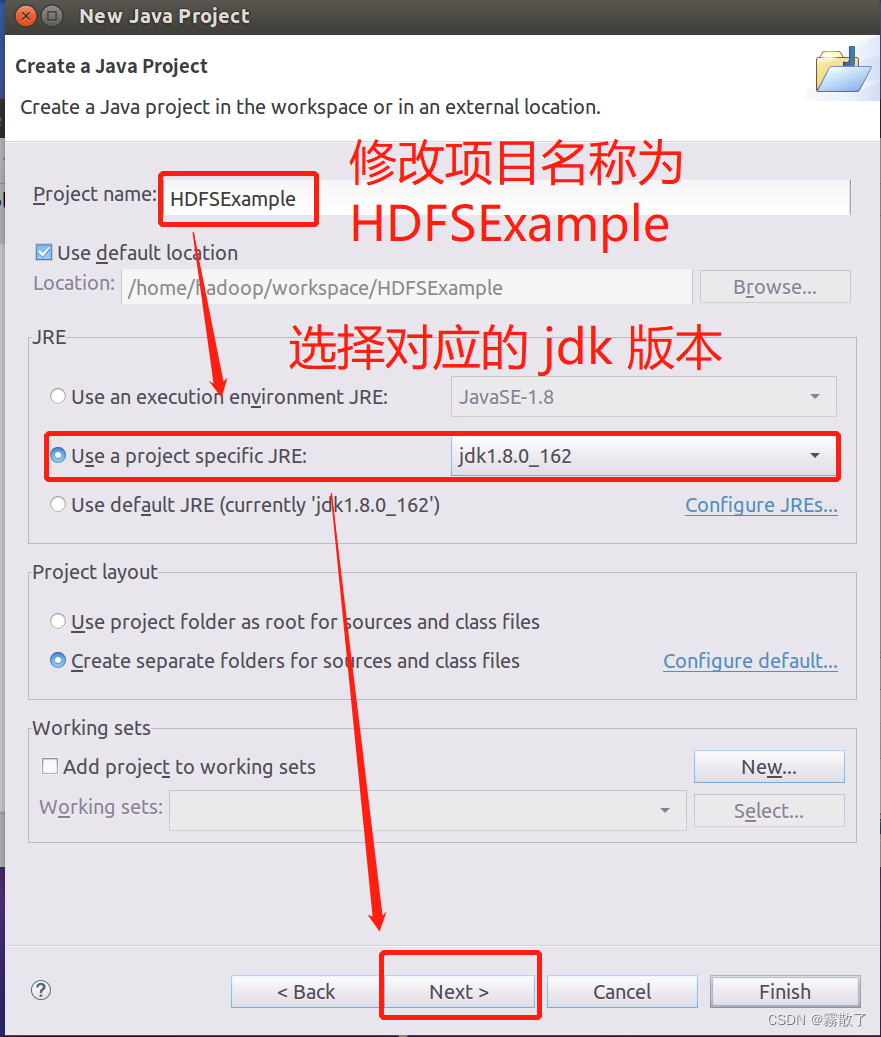
进入下一步工程选择界面,在
Project name
后面输入工程名称
HDFSExample
,选中
Use default location
,让这个 Java 工程的所有文件都保存到
/home/hadoop/workspace/HDFSExample
目录下。在
JRE
这个选项卡中,可以选择当前的 Linux 系统中已经安装好的 JDK,比如 jdk1.8.0_162。然后,点击界面底部的
Next>
按钮,进入下一步的设置:
2. 为项目添加需要用到的JAR包
进入下一步的设置以后,点击界面中的
Libraries
选项卡,然后,点击界面右侧的
Add External JARs…
按钮,如下图所示:
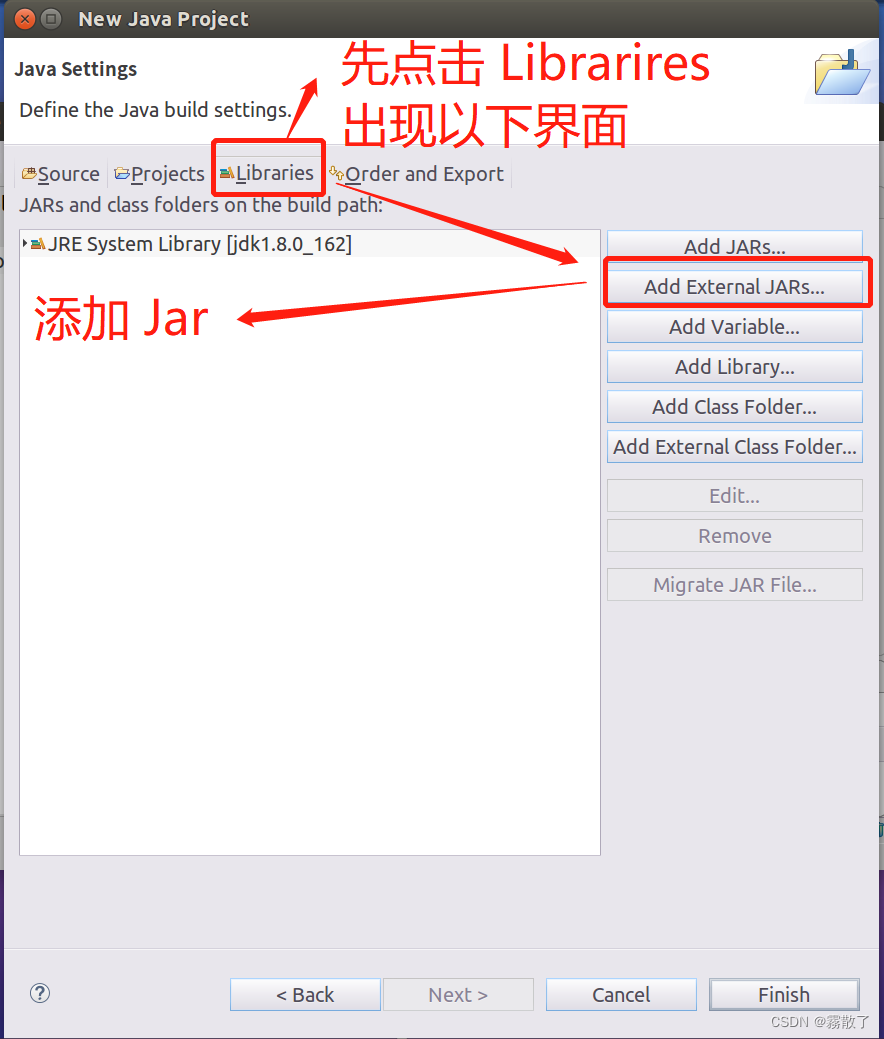
需要在这个界面中加载该 Java 工程所需要用到的 JAR 包,这些 JAR 包中包含了可以访问 HDFS 的 Java API。这些 JAR 包都位于 Linux 系统的 Hadoop 安装目录下,对于我而言,就是在
/usr/local/hadoop/share/hadoop
目录下。
在该界面中,上面的一排目录按钮(即
usr
、
local
、
hadoop
、
share
、
hadoop
和
common
),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个能够与 HDFS 交互的 Java 应用程序,一般需要向 Java 工程中添加以下 JAR 包:
(1)
/usr/local/hadoop/share/hadoop/common
目录下的所有 JAR 包,包括 hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar 和 haoop-kms-3.1.3.jar,注意,不包括目录 jdiff、lib、sources 和 webapps;
(2)
/usr/local/hadoop/share/hadoop/common/lib
目录下的所有 JAR 包;
(3)
/usr/local/hadoop/share/hadoop/hdfs
目录下的所有 JAR 包,注意,不包括目录 jdiff、lib、sources 和 webapps;
(4)
/usr/local/hadoop/share/hadoop/hdfs/lib
目录下的所有 JAR 包。
比如,如果要把
/usr/local/hadoop/share/hadoop/common
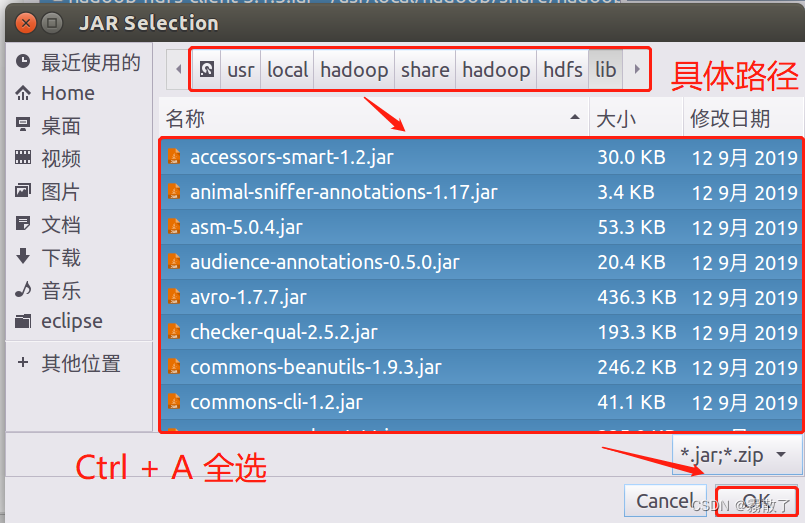
目录下的 hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar 和 haoop-kms-3.1.3.jar 添加到当前的 Java 工程中,可以在界面中点击目录按钮,进入到 common 目录,然后,界面会显示出 common 目录下的所有内容(如下图所示)。
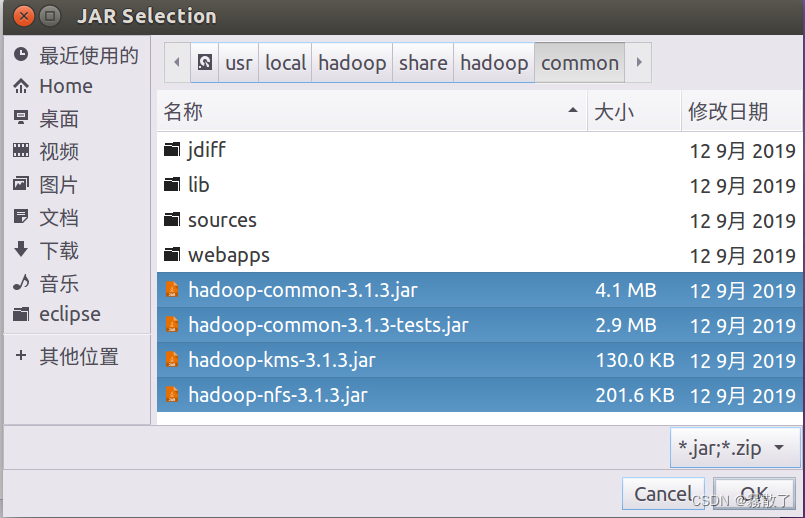
请在界面中用鼠标点击选中 hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar和haoop-kms-3.1.3.jar(不要选中目录 jdiff、lib、sources 和 webapps),然后点击界面右下角的
OK
按钮,就可以把这四个 JAR 包增加到当前Java工程中,出现的界面如下图所示。
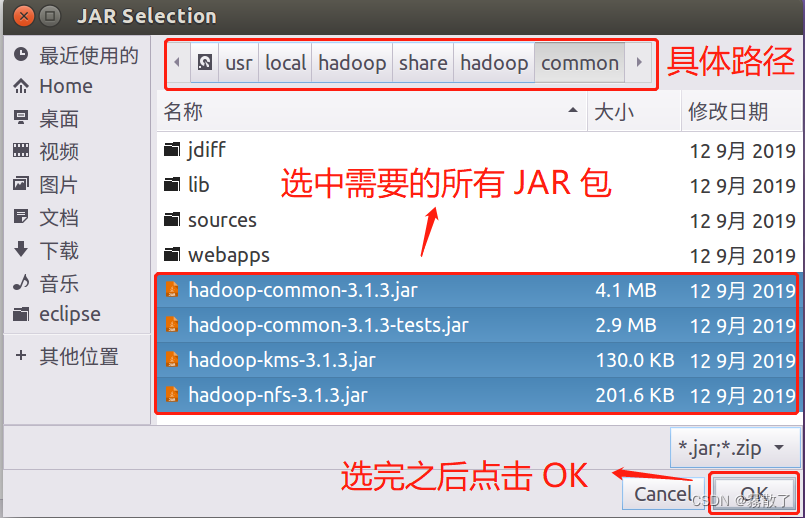
从这个界面中可以看出,hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar 和 haoop-kms-3.1.3.jar 已经被添加到当前 Java 工程中。然后,按照类似的操作方法,可以再次点击
Add External JARs…
按钮,把剩余的其他 JAR 包都添加进来。需要注意的是,当需要选中某个目录下的所有 JAR 包时,可以使用
Ctrl+A
组合键进行全选操作。
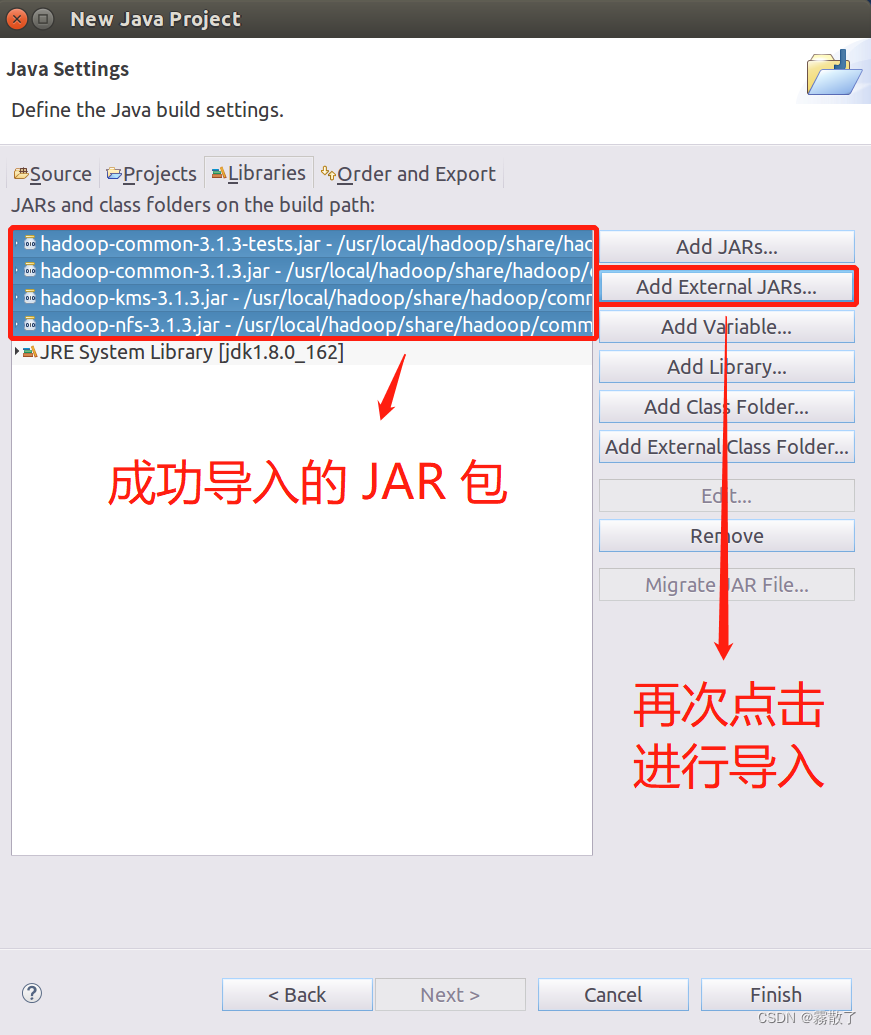
进入
/usr/local/hadoop/share/hadoop/common/lib
,然后
Ctrl + A
进行全选,最后点击
OK
按钮进行确认。
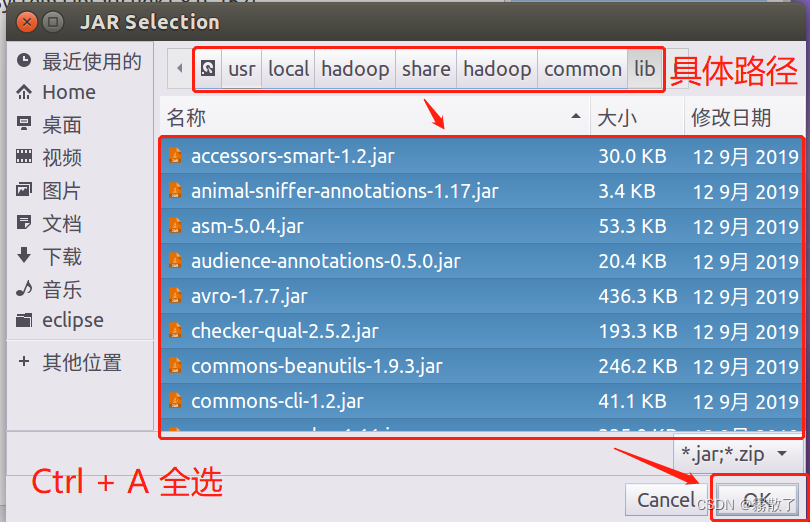
进入
/usr/local/hadoop/share/hadoop/hdfs
,选择第一个包,然后
Ctrl + Shift + End
选择到末尾,然后点击
OK
按钮确认
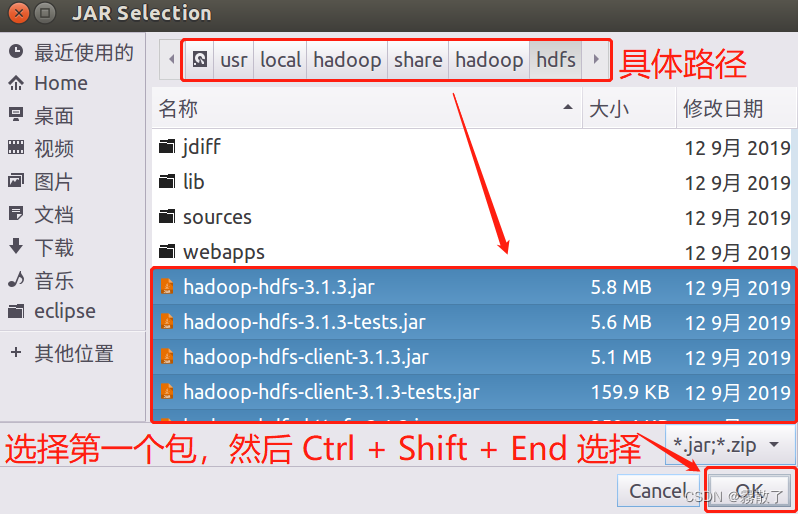
进入
/usr/local/hadoop/share/hadoop/hdfs/lib
,然后
Ctrl + A
进行全选,最后点击
OK
按钮进行确认。
全部添加完毕以后,就可以点击界面右下角的
Finish
按钮,完成 Java 工程 HDFSExample 的创建。
步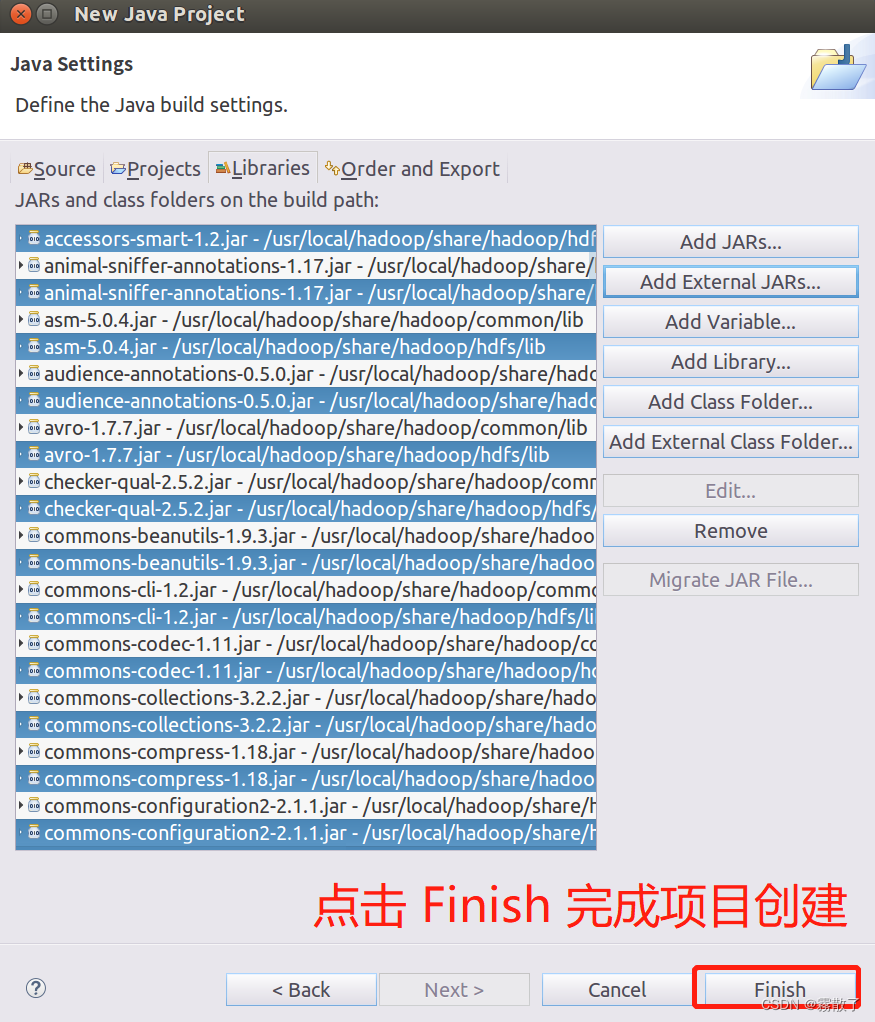
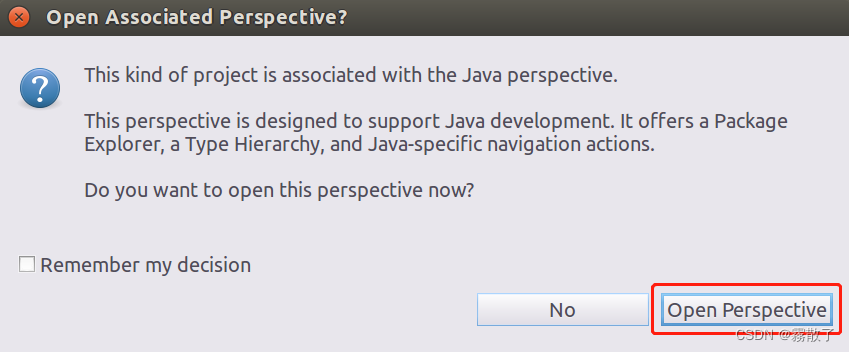
下图的意思是:
这种项目与Java 透视图相关联。
此透视图旨在支持Java 开发。它提供了一个 PackageExplorer、一个 Type Hierarchy 和特定于 Java 的导航操作。
现在要打开这个透视图吗?
我们选择
Open Perspective
,打开视图。
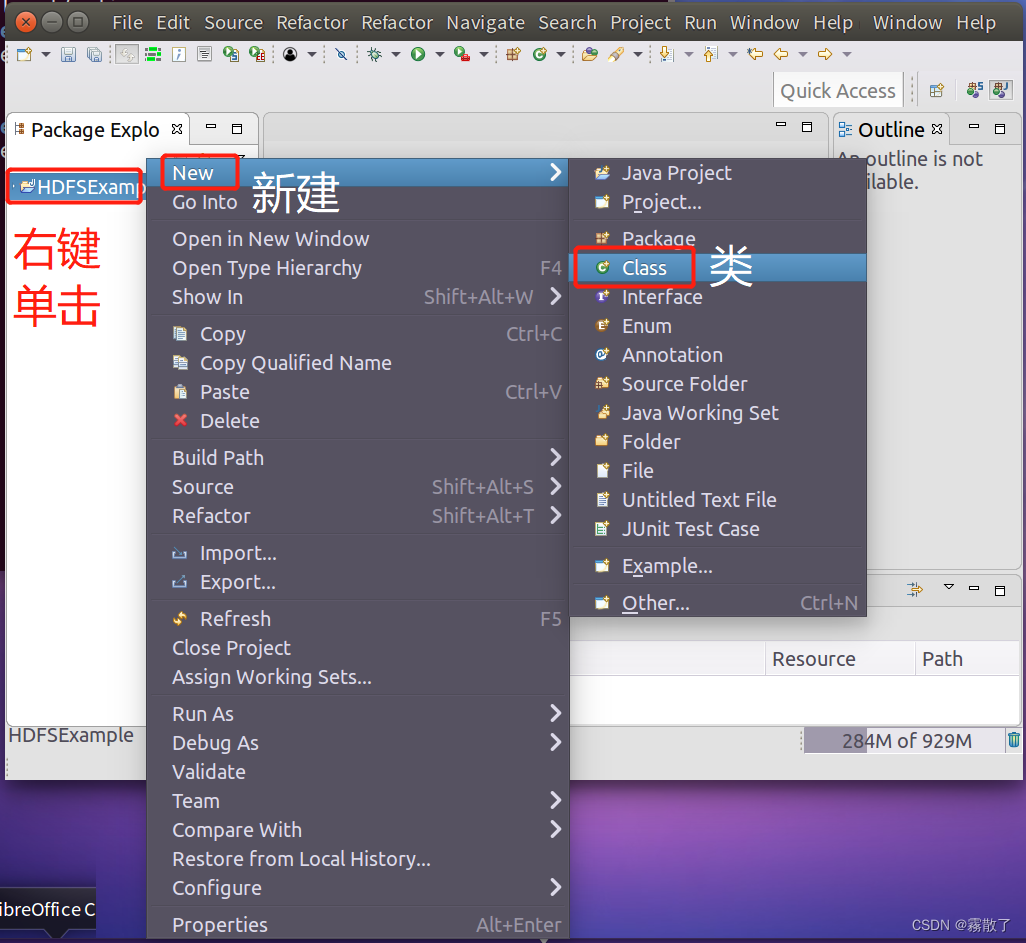
3. 编写 Java 应用程序
下面编写一个 Java 应用程序。请在 Eclipse 工作界面左侧的
Package Explorer
面板中(如下图所示),找到刚才创建好的工程名称
HDFSExample
,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择
New --> Class
菜单。
选择
New-->Class
菜单以后会出现如下图所示界面:
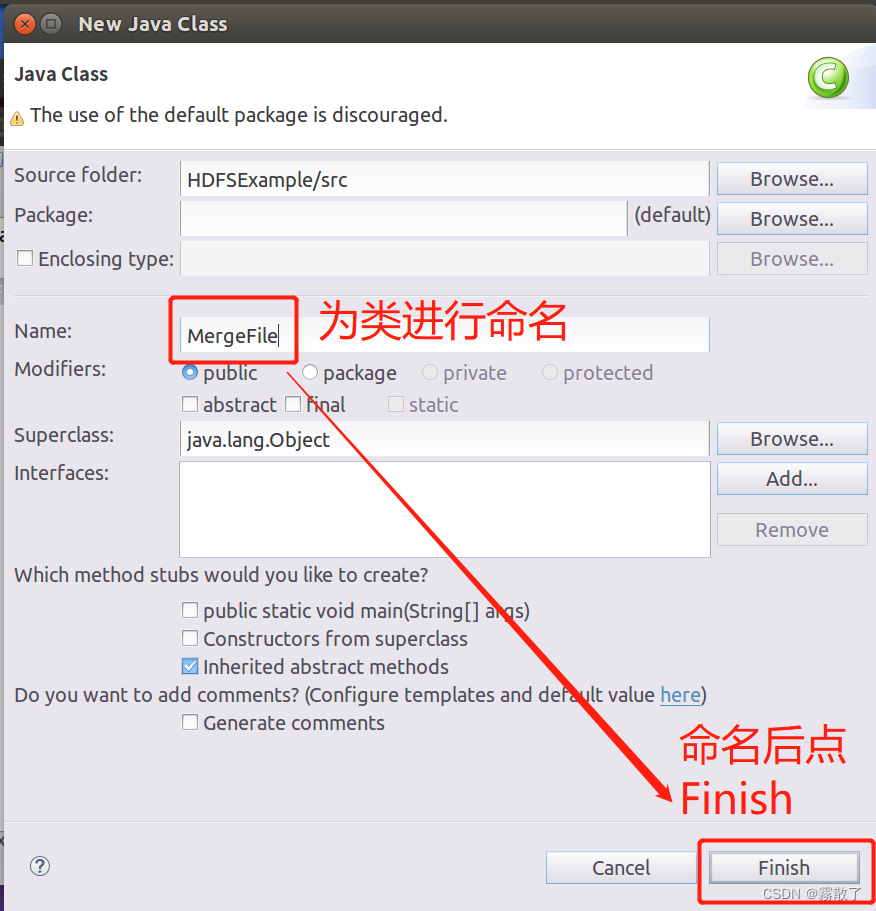
在该界面中,只需要在
Name
后面输入新建的 Java 类文件的名称,这里采用名称
MergeFile
,其他都可以采用默认设置,然后,点击界面右下角
Finish
按钮,出现如下图所示界面:
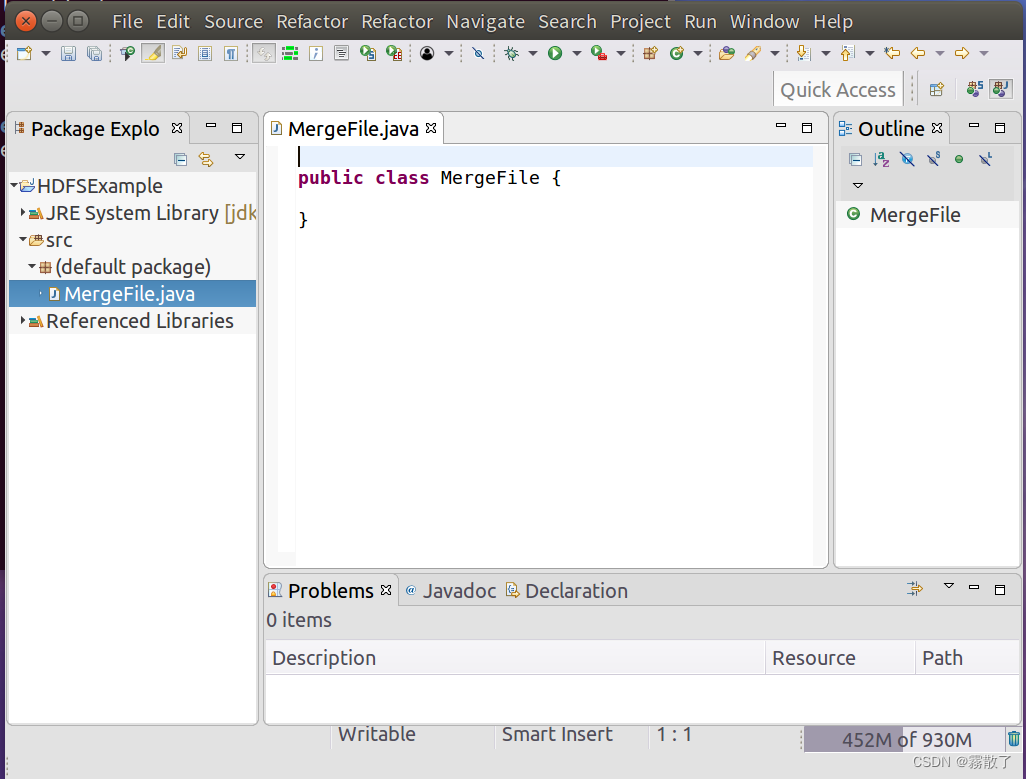
可以看出,Eclipse自动创建了一个名为
MergeFile.java
的源代码文件,请在该文件中输入以下代码:
importjava.io.IOException;importjava.io.PrintStream;importjava.net.URI;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.*;/**
* 过滤掉文件名满足特定条件的文件
*/classMyPathFilterimplementsPathFilter{String reg =null;MyPathFilter(String reg){this.reg = reg;}publicbooleanaccept(Path path){if(!(path.toString().matches(reg)))returntrue;returnfalse;}}/***
* 利用FSDataOutputStream和FSDataInputStream合并HDFS中的文件
*/publicclassMergeFile{Path inputPath =null;//待合并的文件所在的目录的路径Path outputPath =null;//输出文件的路径publicMergeFile(String input,String output){this.inputPath =newPath(input);this.outputPath =newPath(output);}publicvoiddoMerge()throwsIOException{Configuration conf =newConfiguration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");FileSystem fsSource =FileSystem.get(URI.create(inputPath.toString()), conf);FileSystem fsDst =FileSystem.get(URI.create(outputPath.toString()), conf);//下面过滤掉输入目录中后缀为.abc的文件FileStatus[] sourceStatus = fsSource.listStatus(inputPath,newMyPathFilter(".*\\.abc"));FSDataOutputStream fsdos = fsDst.create(outputPath);PrintStream ps =newPrintStream(System.out);//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中for(FileStatus sta : sourceStatus){//下面打印后缀不为.abc的文件的路径、文件大小System.out.print("路径:"+ sta.getPath()+" 文件大小:"+ sta.getLen()+" 权限:"+ sta.getPermission()+" 内容:");FSDataInputStream fsdis = fsSource.open(sta.getPath());byte[] data =newbyte[1024];int read =-1;while((read = fsdis.read(data))>0){
ps.write(data,0, read);
fsdos.write(data,0, read);}
fsdis.close();}
ps.close();
fsdos.close();}publicstaticvoidmain(String[] args)throwsIOException{MergeFile merge =newMergeFile("hdfs://localhost:9000/user/hadoop/","hdfs://localhost:9000/user/hadoop/merge.txt");
merge.doMerge();}}
输入完后是如下图这样的:
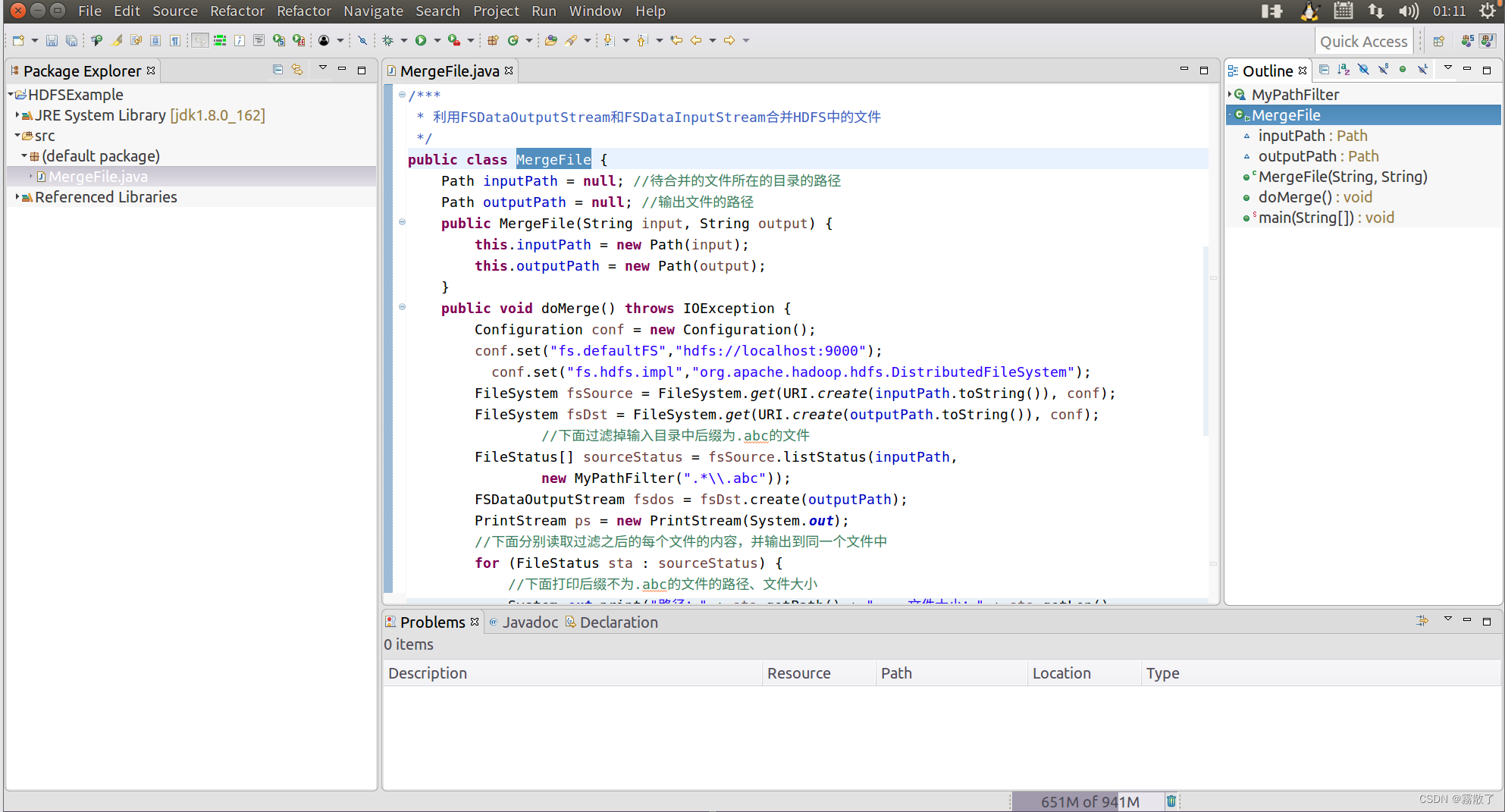
4. 编译运行程序
在开始编译运行程序之前,请一定确保Hadoop已经启动运行,如果还没有启动,需要打开一个 Linux 终端,输入以下命令启动 Hadoop:
cd /usr/local/hadoop # 进入 hadoop 安装目录
./sbin/start-dfs.sh # 启动 Hadoop
然后,要确保HDFS的
/user/hadoop
目录下已经存在 file1.txt、file2.txt、file3.txt、file4.abc 和 file5.abc,每个文件里面有内容。这里,假设文件内容如下:
file1.txt 的内容是: this is file1.txt
file2.txt 的内容是: this is file2.txt
file3.txt 的内容是: this is file3.txt
file4.abc 的内容是: this is file4.abc
file5.abc 的内容是: this is file5.abc
如果未上传,可以先把这五个文件进行上传,具体命令如下:
./bin/hdfs dfs -put ./file* /user/hadoop
这其中
*
是通配符,具体效果如下:

当我们有了这五个文件之后,便可以使用
ls
、
grep
、
cat
命令去判断文件是否存在和查看文件内容,命令如下:
./bin/hdfs dfs -ls /user/hadoop/ |grepfile# 查找是否存在文件名称中带有 file 字样的文件或目录
./bin/hdfs dfs -cat /user/hadoop/file* # 查看所有带有 file 前缀的文件的内容

现在就可以编译运行上面编写的代码。可以直接点击 Eclipse 工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择
Run As
,继续在弹出来的菜单中选择
Java Application
,如下图所示:
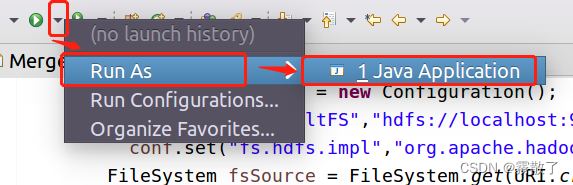
运行发现了一个问题,无法链接到机器的 9000 端口,也就是用于 HDFS 的端口无法连接,有很多种可能,接下来我们尝试一一排查:
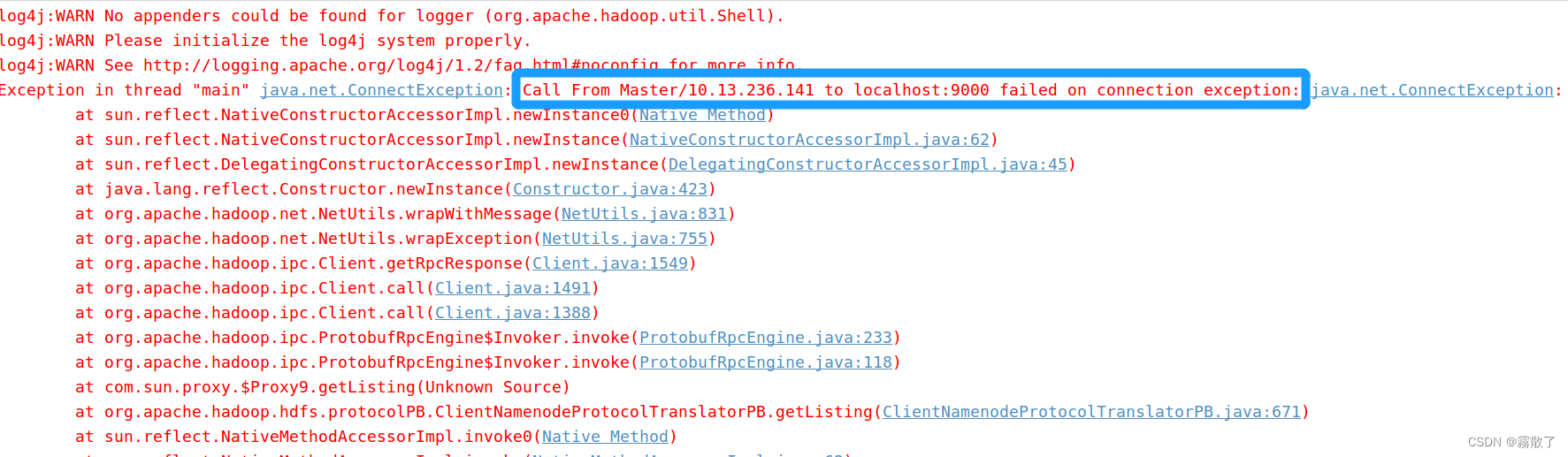
- Check the hostname the client using is correct. If it’s in a Hadoop configuration option: examine it carefully, try doing an ping by hand. 检查客户端使用的主机名是否正确。如果它在Hadoop配置选项中:仔细检查,试着用手做一个ping:
ping Master -c 3很明显就看不出来这个有什么错误,进行下一个排查。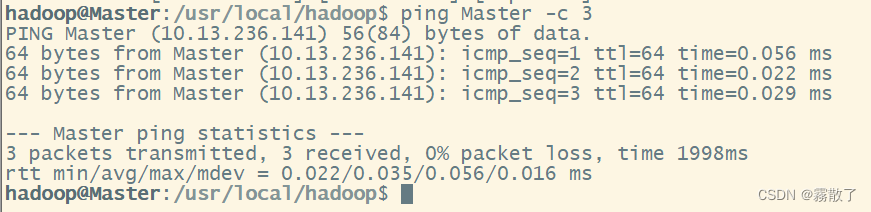
- Check the IP address the client is trying to talk to for the hostname is correct. 检查客户端尝试与之通信的IP地址,以确定主机名是否正确:检查了一下,都对应的上,说明也不是这个问题,ping 的时候跟报错也是一样的,因为 ping 我用的就是主机名,所以应该不是这里错了,进行下一个排查。
- Make sure the destination address in the exception isn’t 0.0.0.0 -this means that you haven’t actually configured the client with the real address for that service, and instead it is picking up the server-side property telling it to listen on every port for connections. 确保异常中的目标地址不是 0.0.0.0 这意味着您实际上没有为客户端配置该服务的真实的地址,而是获取服务器端属性,告诉它侦听每个端口的连接。很明显根据这个异常的地址我们就可以知道并不是这里的问题,继续下一个排查。
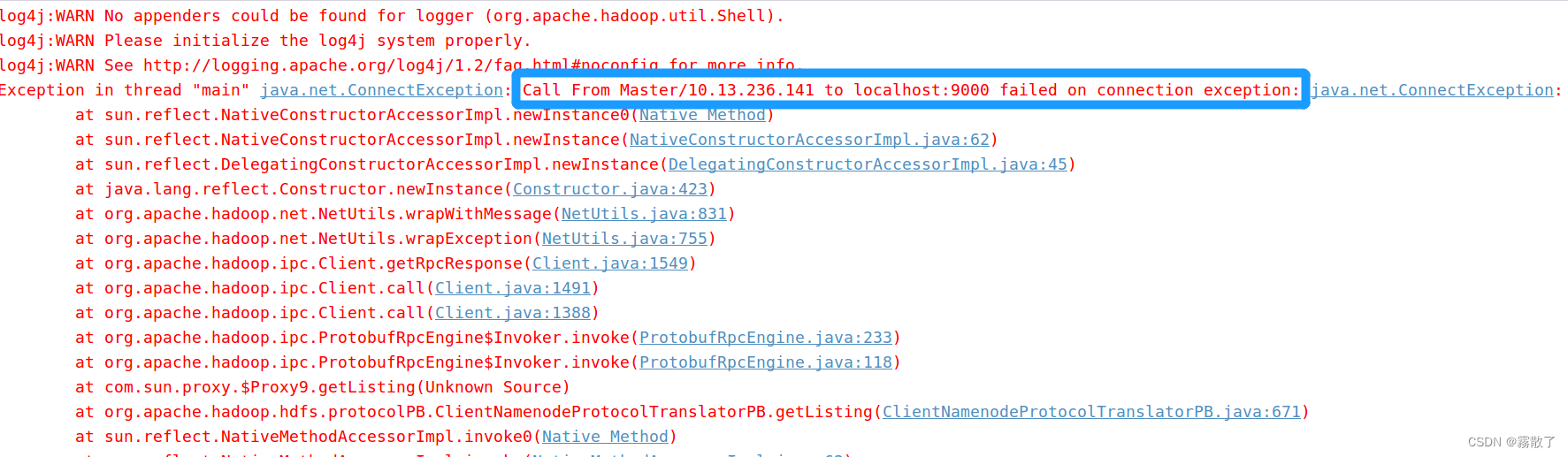
- If the error message says the remote service is on “127.0.0.1” or “localhost” that means the configuration file is telling the client that the service is on the local server. If your client is trying to talk to a remote system, then your configuration is broken. 如果错误消息指出远程服务位于
127.0.0.1或localhost上,这意味着配置文件告诉客户端该服务位于本地服务器上。如果您的客户端试图与远程系统通信,那么您的配置就被破坏了。根据我们的异常报错,好像确实是有这个localhost的存在,但说的应该是前面这个而不是后面的这个,所以应该不是因为这个存在错误,进行下一个排查。 - Check that there isn’t an entry for your hostname mapped to 127.0.0.1 or 127.0.1.1 in
/etc/hosts(Ubuntu is notorious for this). 检查您的主机名是否映射到127.0.0.1或127.0.1.1在/etc/hosts中(Ubuntu为此而臭名昭著)。之前已经修改过/etc/hosts文件,主机名映射只与IP有关系,但是确实有一个localhost/9000,思索甚久,决定再次将/etc/hosts文件内容进行一下更改:sudovim /etc/hosts # 使用 vim 编辑器修改 /etc/hosts 文件将localhost的映射修改为具体的IP地址,如下图所示: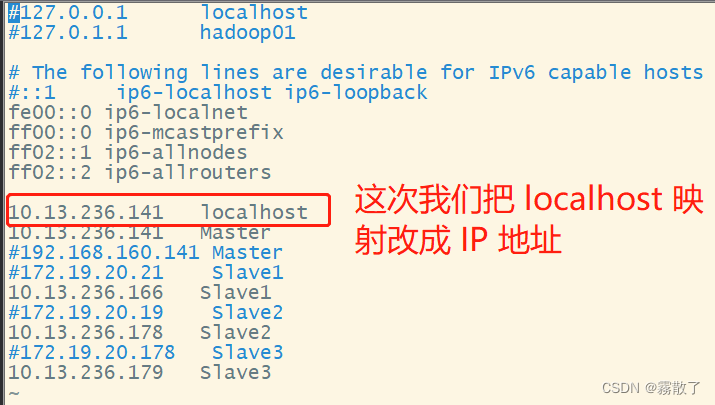 再次编译运行代码,查看结果:
再次编译运行代码,查看结果:
连接问题已经解决,如果大家没有解决连接问题,可以接着往下看,如果跟我一样解决了,可以跳过下面的排查问题,然后进入下一个问题的解决。
- Check the port the client is trying to talk to using matches that the server is offering a service on. The
netstatcommand is useful there. 使用服务器提供服务的匹配项来检查客户端试图与之通信的端口。netstat命令在那里很有用。我在 Master 上输入下面命令,来寻找端口是否已经开启:netstat|grep9000因为我们单纯只是寻找 HDFS 服务的端口,所以我们直接查找9000即可,从图中看来端口应该已经准备就绪,找不到无法使用的原因,进行下一个排查。
- On the server, try a
telnet localhost <port>to see if the port is open there. 在服务器上,尝试telnet localhost <port>以查看端口是否在那里打开。我输入下面命令,从我的 Master 上进行连接,以此排查错误:telnet localhost 9000图是不会骗人的,这就会有两种可能性了,首先就是本地服务未开启,也就是23端口未被监听,又或者是9000端口未被监听 输入下面命令查看是否有监听
输入下面命令查看是否有监听 23端口:netstat -tnl |grep :23看图就懂,没有进程在监听本地的23端口,说明本地的telnet服务没有启动,找到问题,接下来我们将启动本地telnet服务。 1. 安装
1. 安装 xinetd和telnetd输入下面命令安装:sudoapt-getinstall xinetd telnetd 2. 创建文件
2. 创建文件 /etc/inetd.conf新建一个inetd.conf文件到/etc目录下sudovim /etc/inetd.conf在文件中添加如下内容:telnet stream tcp nowait telnetd /usr/sbin/tcpd /usr/sbin/in.telnetd 3. 修改文件
3. 修改文件 /etc/xinetd.conf输入如下命令使用vim编辑器打开/etc目录下的xinetd.conf文件sudovim /etc/xinetd.conf修改文件为下列内容:# Simple configuration file for xinetd## Some defaults, and include /etc/xinetd.d/defaults{# Please note that you need a log_type line to be able to use log_on_success# and log_on_failure. The default is the following :# log_type = SYSLOG daemon infoinstances =60log_type = SYSLOG authprivlog_on_success = HOST PIDlog_on_failure = HOSTcps =2530}includedir /etc/xinetd.d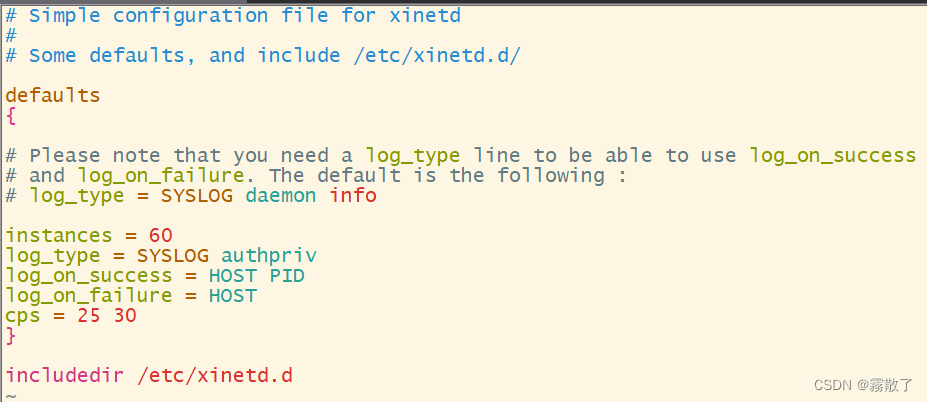 4. 创建文件
4. 创建文件 /etc/xinetd.d/telnet新建telnet文件到/etc/xinetd.d/目录下,命令如下:sudovim /etc/xinetd.d/telnet输入下列内容:# default: on# description: The telnet server serves telnet sessions; it uses \# unencrypted username/password pairs for authentication.service telnet{disable = noflags = REUSEsocket_type = streamwait= nouser = rootserver = /usr/sbin/in.telnetdlog_on_failure += USERID}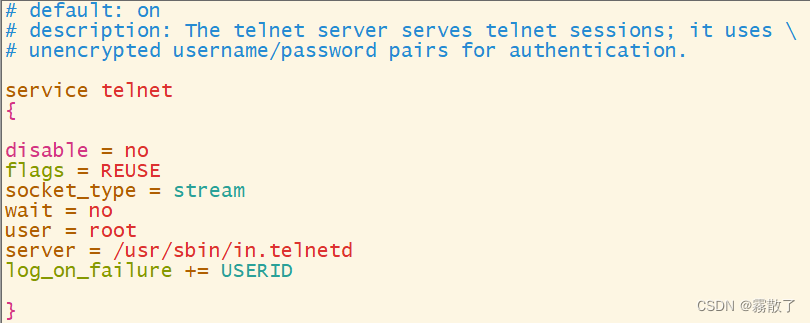 5. 重启系统,查看端口状态输入下面命令重启系统,并且查看端口状态:
5. 重启系统,查看端口状态输入下面命令重启系统,并且查看端口状态:reboot# 重启系统netstat -tnl # 查看端口状态 6. 测试远程登录本地
6. 测试远程登录本地telnet 127.0.0.1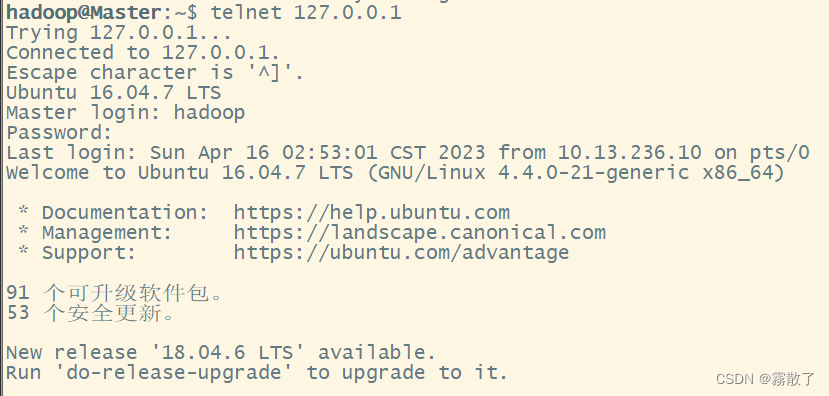
- On the client, try a
telnet <server> <port>to see if the port is accessible remotely. 在客户端上,尝试telnet <server> <port>以查看端口是否可远程访问。 - Try connecting to the server/port from a different machine, to see if it just the single client misbehaving. 尝试从另一台机器连接到服务器/端口,看看是否只是单个客户端行为不正常。
- If your client and the server are in different subdomains, it may be that the configuration of the service is only publishing the basic hostname, rather than the Fully Qualified Domain Name. The client in the different subdomain can be unintentionally attempt to bind to a host in the local subdomain —and failing. 如果您的客户端和服务器位于不同的子域中,则可能是服务的配置仅发布基本主机名,而不是完全限定的域名。不同子域中的客户端可能会无意中尝试绑定到本地子域中的主机,并失败。
排查到第八个我就觉得不对劲,所以我就没有继续排查下去了,反思了一下,又回到了问题本身,一看到那个
localhost/9000
我就深有感触,总觉得就是它了,所以我又回到第四个排查,此次将
/etc/hosts
文件更改了之后,发现就可以了。然后,进入下一个问题的排查:

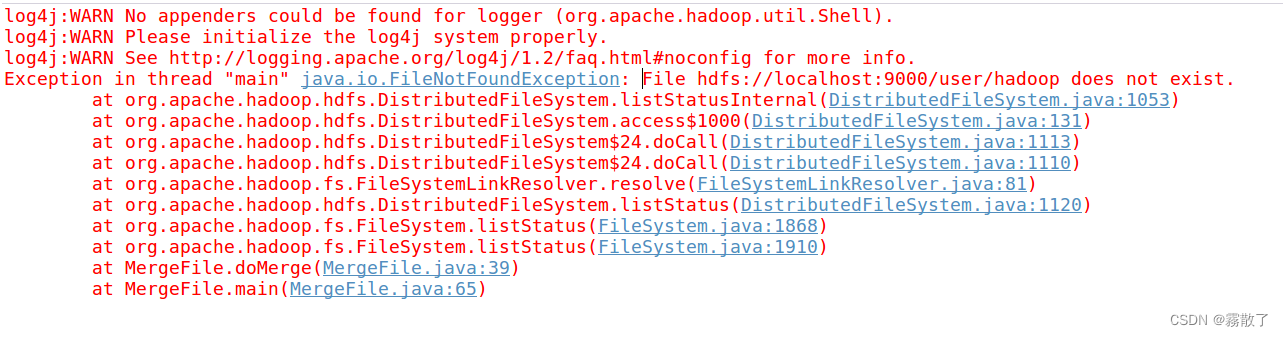
先看看图,它说这个文件不存在,然后我思考了一下,好像是因为我重新格式化,然后把
tmp
所有东西都删掉了,所以才有这个问题,尝试着重新创建文件夹,上传五个文件,最后再次编译运行,为了不让大家往上翻,如果你也删掉了,那就看这两行命令吧,但前提是你已经有五个文件在本地。
./bin/hdfs dfs -mkdir -p /user/hadoop # 创建 hadoop 用户目录
./bin/hdfs dfs -put ./file* /user/hadoop
最终就成功运行了,虽然挺坎坷,但是办法总比困难嘛。
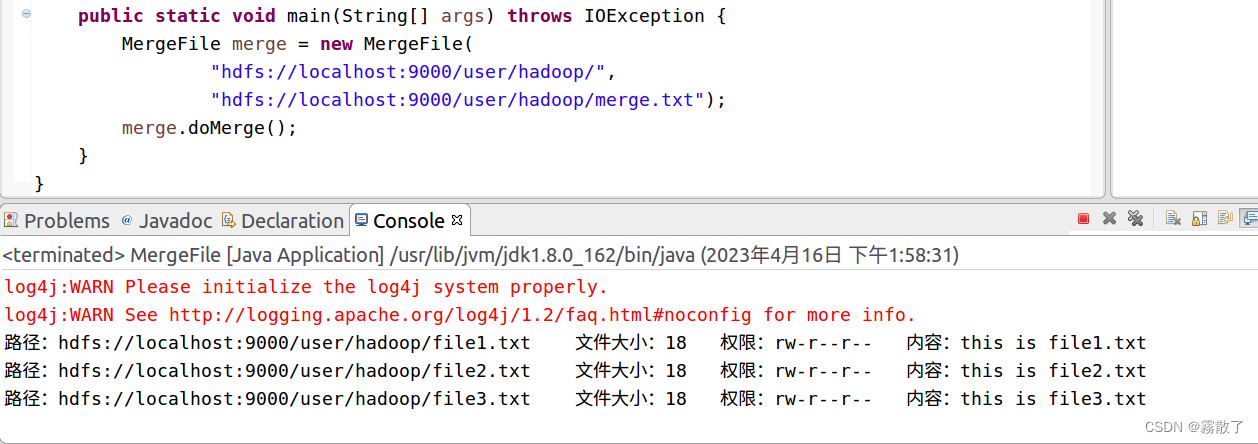
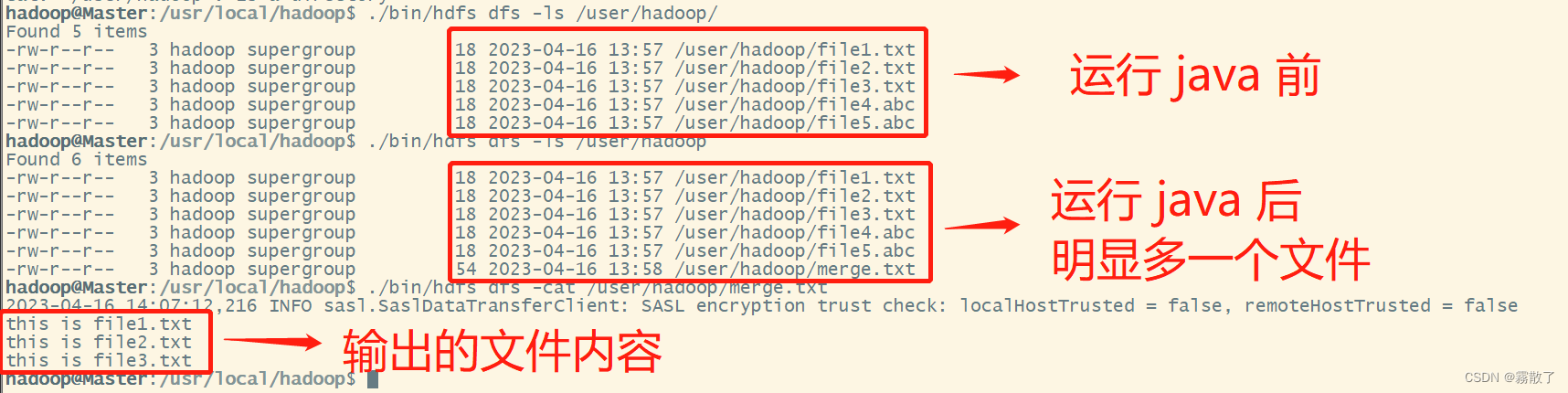
如果程序运行成功,这时,可以到 HDFS 中查看生成的
merge.txt
文件,比如,可以在 Linux 终端中执行如下命令:
cd /usr/local/hadoop # 进入 hadoop 安装目录
./bin/hdfs dfs -ls /user/hadoop
./bin/hdfs dfs -cat /user/hadoop/merge.txt
5. 应用程序的部署
下面介绍如何把 Java 应用程序生成 JAR 包,部署到 Hadoop 平台上运行。首先,在 Hadoop 安装目录下新建一个名称为 myapp 的目录,用来存放我们自己编写的 Hadoop 应用程序,可以在 Linux 的终端中执行如下命令:
cd /usr/local/hadoop # 进入 hadoop 安装目录mkdir myapp # 新建一个名为 myapp 的文件夹
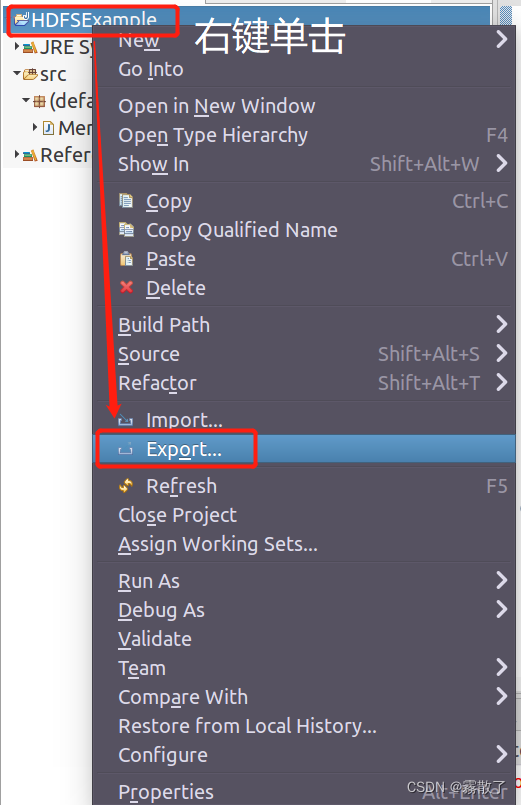
然后,请在 Eclipse 工作界面左侧的
Package Explorer
面板中,在工程名称
HDFSExample
上点击鼠标右键,在弹出的菜单中选择
Export
,如下图所示:
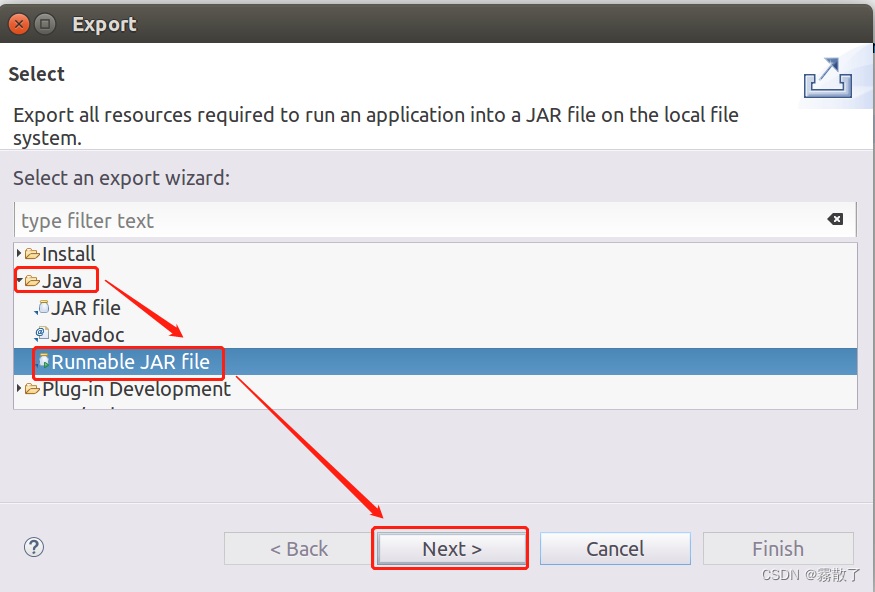
在弹出的界面中,选择
Java --> Runnable JAR file
,然后,点击
Next>
按钮,如下图:
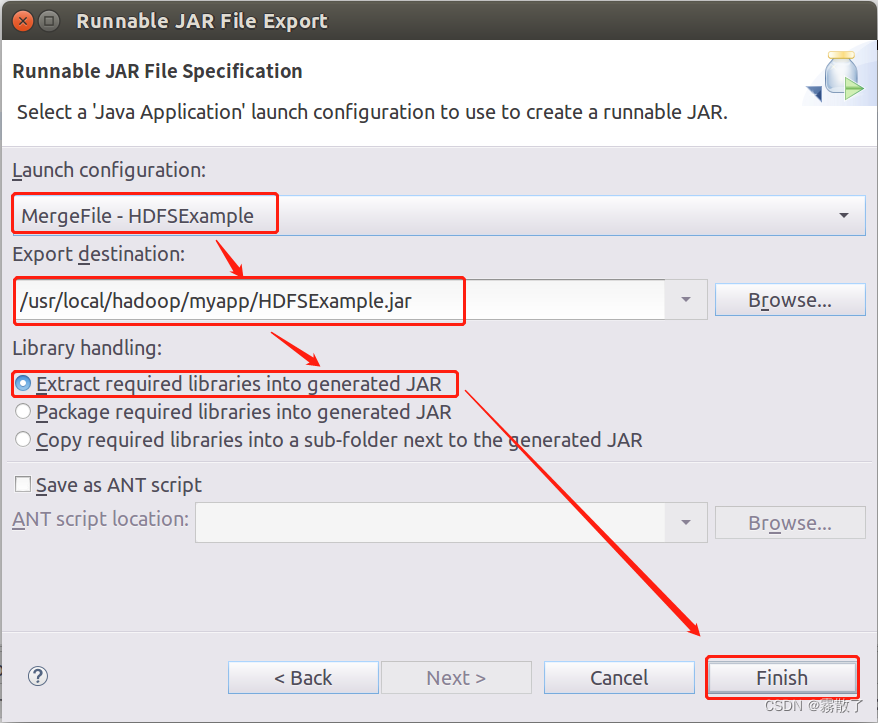
在该界面中,
Launch configuration
用于设置生成的 JAR 包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类
MergeFile-HDFSExample
。在
Export destination
中需要设置 JAR 包要输出保存到哪个目录,比如,这里设置为
/usr/local/hadoop/myapp/HDFSExample.jar
。在
Library handling
下面选择
Extract required libraries into generated JAR
。然后,点击
Finish
按钮,如下图所示:
然后就出现了一个提示界面:
此操作将重新打包引用的库。
请查看与您希望引用的库关联的许可证,以确保您能够使用此应用程序重新打包它们。另请注意,此操作不会将签名文件从原始库复制到生成的 JAR 文件。
可以忽略该界面的信息,直接点击界面右下角的
OK
按钮,启动打包过程,如下图所示:
打包过程结束后,会出现一个警告信息界面。
JAR 文件的位置:
/usr/local/hadoop/myapp不存在。你想创建它吗?
可以忽略该界面的信息,直接点击界面右下角的
Yes
按钮,如下图所示:
至此,已经顺利把 HDFSExample 工程打包生成了HDFSExample.jar。可以到 Linux 系统中查看一下生成的 HDFSExample.jar 文件,可以在 Linux 的终端中执行如下命令:
cd /usr/local/hadoop/myapp
ls -l
可以看到,
/usr/local/hadoop/myapp
目录下已经存在一个 HDFSExample.jar 文件。

由于之前已经运行过一次程序,已经生成了 merge.txt,因此,需要首先执行如下命令删除该文件:
cd /usr/local/hadoop
./bin/hdfs dfs -rm /user/hadoop/merge.txt

然后我们再来看一下
/user/hadoop
目录下是否真的已经删除了
merge.txt
文件:
./bin/hdfs dfs -ls /user/hadoop/
通过
ls
命令,就可以看见没有了
merge.txt
文件

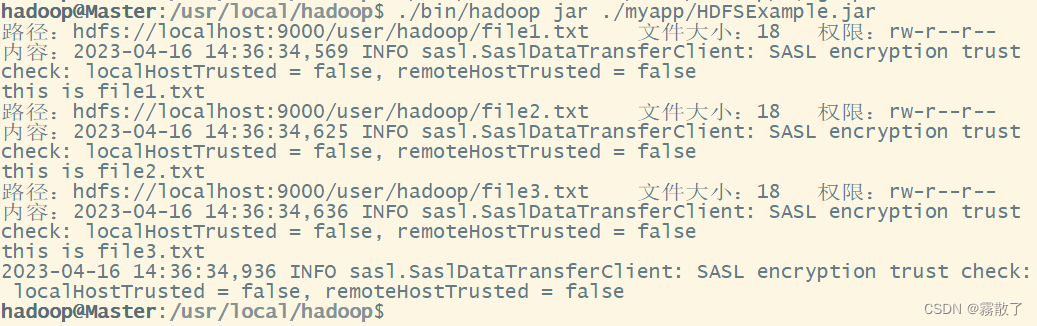
现在,就可以在 Linux 系统中,使用 hadoop jar 命令运行程序,命令如下:
cd /usr/local/hadoop
./bin/hadoop jar ./myapp/HDFSExample.jar
这里的
false
是正常的,并不是报错,所以不要在意。
上面程序执行结束以后,可以到 HDFS中 查看生成的 merge.txt 文件,比如,可以在Linux终端中执行如下命令:
cd /usr/local/hadoop
./bin/hdfs dfs -ls /user/hadoop
./bin/hdfs dfs -cat /user/hadoop/merge.txt
可以看到如下结果:
版权归原作者 HeZaoCha 所有, 如有侵权,请联系我们删除。