
数据可视化
在完成了对数据的透视之后,可以将数据透视的结果通过可视化的方式呈现出来,简单的说,就是将数据变成漂亮的图表,因为人类对颜色和形状会更加敏感,然后再进一步解读数据背后隐藏的价值。在之前的文章中已经为展示过用使用
Series
或
DataFrame
对象的
plot
方法生成可视化图表的操作,本文讲述的是绘图方法的基石,它就是充满视觉化体验的 matplotlib 库。
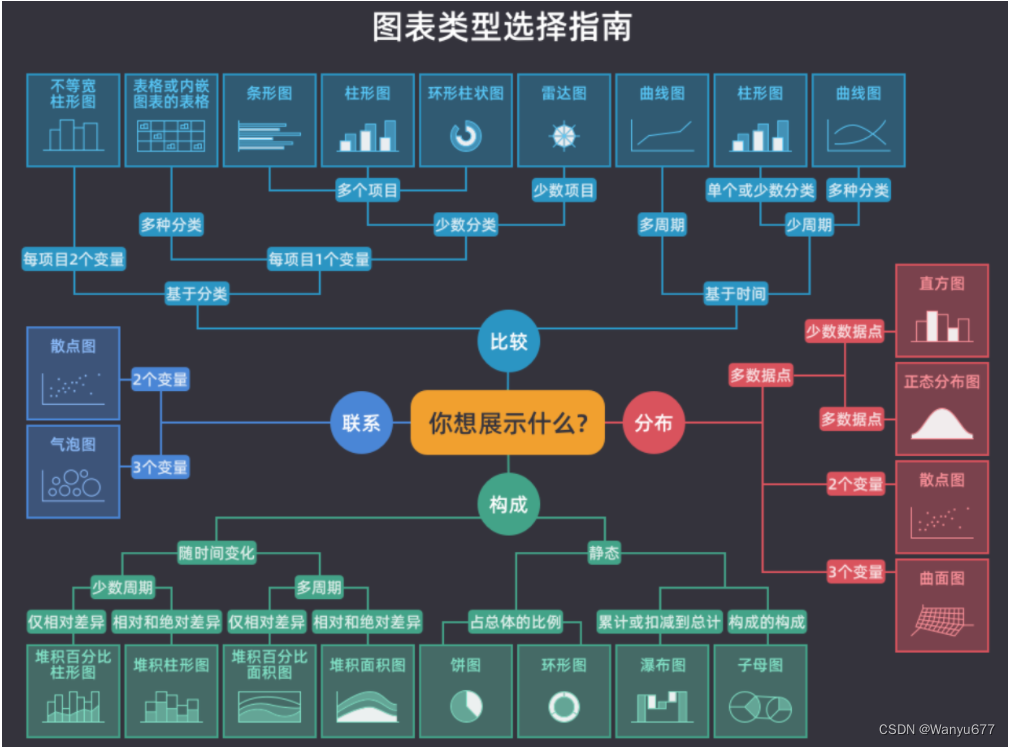
在开始学习 matplotlib 之前,请大看下面这张图,它给出了常用的图表类型及其应用场景。在选择统计图表时,如果不知道做出怎样的选择最合适,相信这张图就能帮到你。简单的说,看趋势折线图,比数据柱状图,定关系散点图,查占比饼状图,看分布直方图,找离群箱线图。
导入和配置
之前的文章中,有论述过如何安装和导入 matplotlib 库,如果不确定是否已经安装了 matplotlib,可以使用下面的魔法指令尝试安装或升级你的 matplotlib。
%pip install -U matplotlib
为了解决 matplotlib 图表中文显示的问题,我们需要修改
pyplot
模块的
rcParams
配置参数,具体的操作如下所示。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'].insert(0, 'SimHei')
plt.rcParams['axes.unicode_minus'] = False
说明:上面代码中的
SimHei是字体名称,需要将
axes.unicode_minus参数设置为
False,这样才能让坐标轴上的负号正常显示。
通过下面的魔法指令,可以在绘图时生成矢量图(SVG - Scalable Vector Graphics),矢量图的特点是不会因为放大、缩小或旋转等操作而失真,看起来会舒服很多。
%config InlineBackend.figure_format='svg'
创建画布
pyplot
模块的
figure
函数可以用来创建画布,创建画布时,可以通过
figsize
参数指定画布的尺寸(默认值是
[6.4, 4.8]
);可以通过
dpi
参数设置绘图的分辨率,因为
dpi
代表了每英寸的像素点数量。除此之外,还可以通过
facecolor
参数设置画布的背景色。
figure
函数的返回值是一个
Figure
对象,它代表了绘图使用的画布,由此可以基于画布来创建绘图使用的坐标系。
plt.figure(figsize=(8, 4), dpi=120, facecolor='darkgray')
创建坐标系
可以直接使用
pyplot
模块的
subplot
函数来创建坐标系,该函数会返回
Axes
对象。
subplot
的前三个参数分别用来指定整个画布分成几行几列以及当前坐标系的索引,这三个参数的默认值都是
1
。如果没有创建坐标系,绘图时会使用画布上默认的也是唯一的一个坐标系;如果需要在画布上创建多个坐标系,就可以使用该函数。当然,也可以通过上面创建的
Figure
对象的
add_subplot
方法或
add_axes
方法来创建坐标系,前者跟
subplot
函数的作用一致,后者会产生嵌套的坐标系。
plt.subplot(2, 2, 1)
绘制图像
折线图
在绘图时,如果没有先调用
figure
函数和
subplot
函数,我们将使用默认的画布和坐标系,如果要绘制折线图,可以使用
pyplot
模块的
plot
函数,并指定横轴和纵轴的数据。折线图适合观察数据的趋势,尤其是当横坐标代表时间的情况下。可以使用
plot
函数的
color
参数来定制折线的颜色,可以使用
marker
参数来定制数据点的标记(例如:
*
表示五角星,
^
表示三角形,
o
表示小圆圈等),可以使用
linestyle
参数来定制折线的样式(例如:
-
表示实线,
--
表示虚线,
:
表示点线等),可以使用
linewidth
参数来定制折线的粗细。 下面的代码绘制了一条正弦曲线,其中
marker='*'
会将数据点的标记设置为五角星形状,而
color='red'
会将折线绘制为红色。先
首先,举一个简单的例子:绘制一条直线,如下所示:
代码:
import numpy as np
import matplotlib.pyplot as plt # 导入 pyplot 模块
data = np.array([1,2,3,4,5])# 准备数据
plt.plot(data)# 在当前画布的绘图区域中绘制图表
plt.show()# 展示图表 # 展示图表
输出: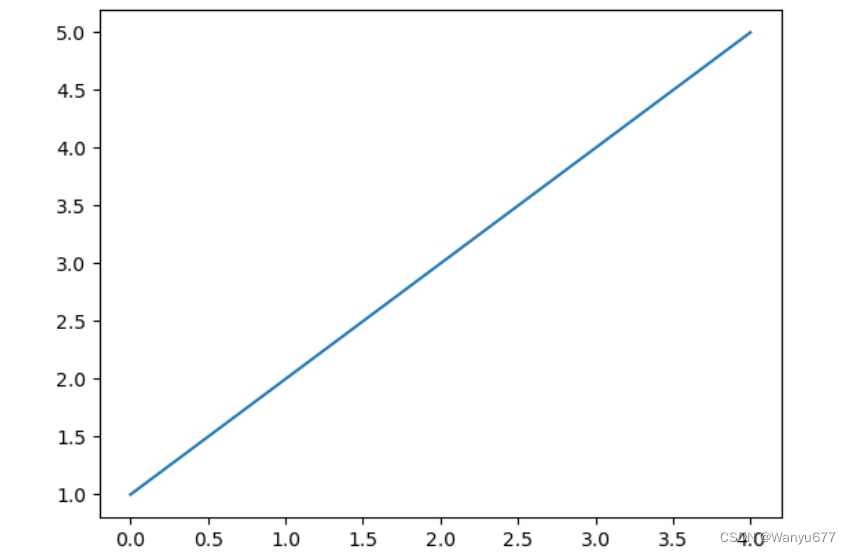
代码:
import numpy as np
x = np.linspace(-2 * np.pi, 2 * np.pi, 120)
y = np.sin(x)
# 创建画布
plt.figure(figsize=(8, 4), dpi=120)
# 绘制折线图
plt.plot(x, y, linewidth=2, marker='*', color='red')
# 显示绘图
plt.show()
输出:
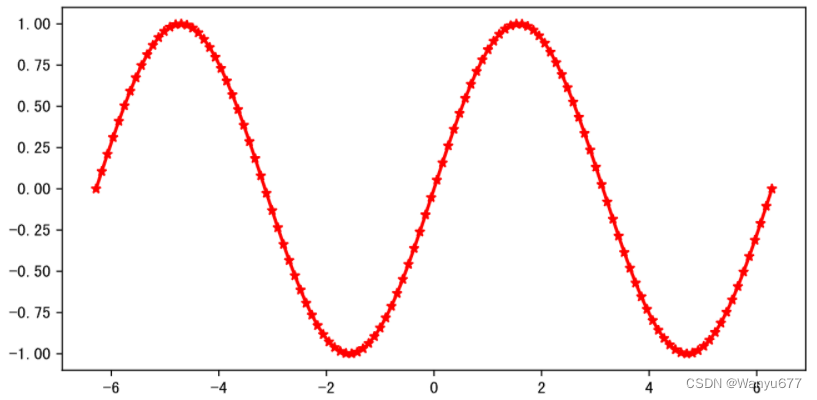
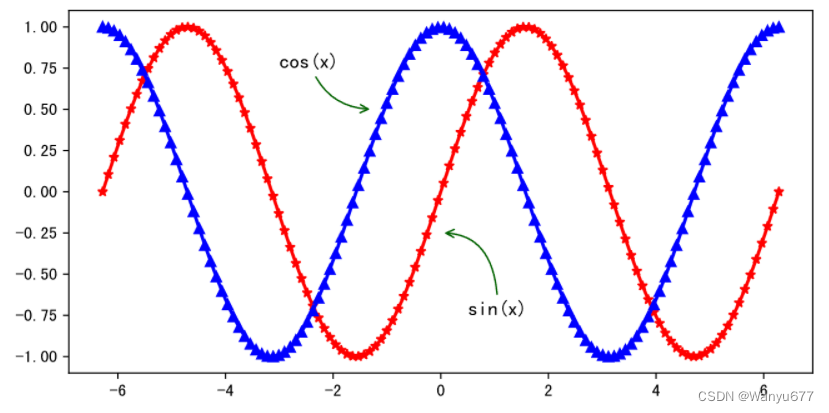
如果要在一个坐标系上同时绘制正弦和余弦曲线,可以对上面的代码稍作修改。
代码:
x = np.linspace(-2 * np.pi, 2 * np.pi, 120)
y1, y2 = np.sin(x), np.cos(x)
plt.figure(figsize=(8, 4), dpi=120)
plt.plot(x, y1, linewidth=2, marker='*', color='red')
plt.plot(x, y2, linewidth=2, marker='^', color='blue')
# 定制图表上的标注(annotate函数的参数如果不理解可以先不管它)
plt.annotate('sin(x)', xytext=(0.5, -0.75), xy=(0, -0.25), fontsize=12, arrowprops={
'arrowstyle': '->', 'color': 'darkgreen', 'connectionstyle': 'angle3, angleA=90, angleB=0'
})
plt.annotate('cos(x)', xytext=(-3, 0.75), xy=(-1.25, 0.5), fontsize=12, arrowprops={
'arrowstyle': '->', 'color': 'darkgreen', 'connectionstyle': 'arc3, rad=0.35'
})
plt.show()
输出:
如果要使用两个坐标系分别绘制正弦和余弦,可以用上面提到的
subplot
函数来创建坐标系,然后再绘图。
代码:
plt.figure(figsize=(8, 4), dpi=120)
# 创建坐标系(第1个图)
plt.subplot(2, 1, 1)
plt.plot(x, y1, linewidth=2, marker='*', color='red')
# 创建坐标系(第2个图)
plt.subplot(2, 1, 2)
plt.plot(x, y2, linewidth=2, marker='^', color='blue')
plt.show()
输出:
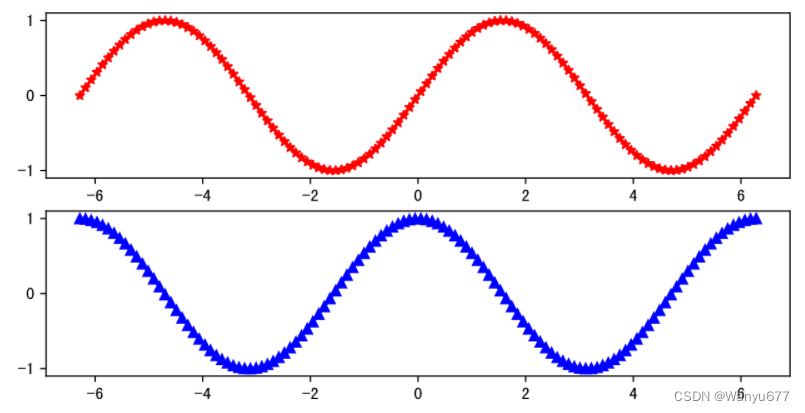
当然也可以像下面这么做,大家可以运行代码看看跟上面的图有什么区别。
plt.figure(figsize=(8, 4), dpi=120)
plt.subplot(1, 2, 1)
plt.plot(x, y1, linewidth=2, marker='*', color='red')
plt.subplot(1, 2, 2)
plt.plot(x, y2, linewidth=2, marker='^', color='blue')
plt.show()
再举一个实际生活中的例子:未来15天最高气温和最低气温
代码:
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(4,19)
y_max = np.array([32,33,34,34,33,31,30,29,30,29,26,23,21,25,31])
y_min = np.array([19,19,20,22,22,21,22,16,18,18,17,14,15,16,16])# 绘制折线图
plt.plot(x, y_max)
plt.plot(x, y_min)
plt.show()
输出: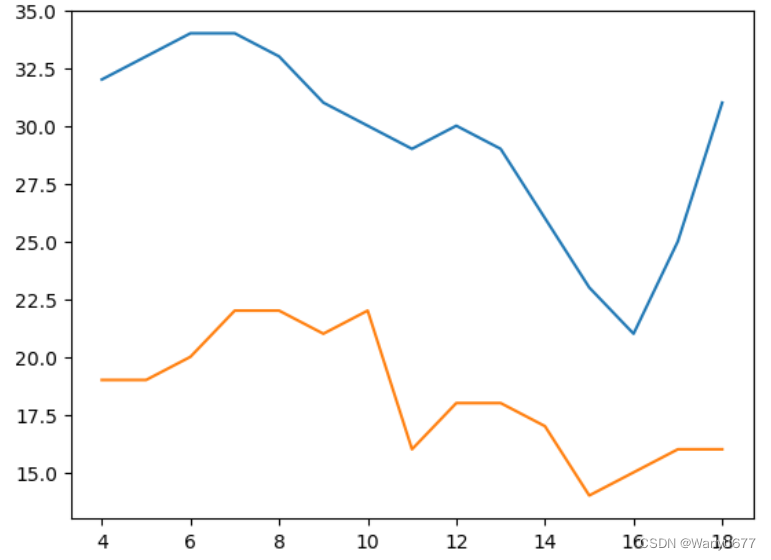
散点图
散点图可以帮助我们了解两个变量的关系,如果需要了解三个变量的关系,可以将散点图升级为气泡图。下面的代码中,
x
和
y
两个数组分别表示每个月的收入和每个月网购的支出,如果我们想了解
x
和
y
是否存在相关关系,就可以绘制如下所示的散点图。
代码:
x = np.array([5550, 7500, 10500, 15000, 20000, 25000, 30000, 40000])
y = np.array([800, 1800, 1250, 2000, 1800, 2100, 2500, 3500])
plt.figure(figsize=(6, 4), dpi=120)
plt.scatter(x, y)
plt.show()
输出:
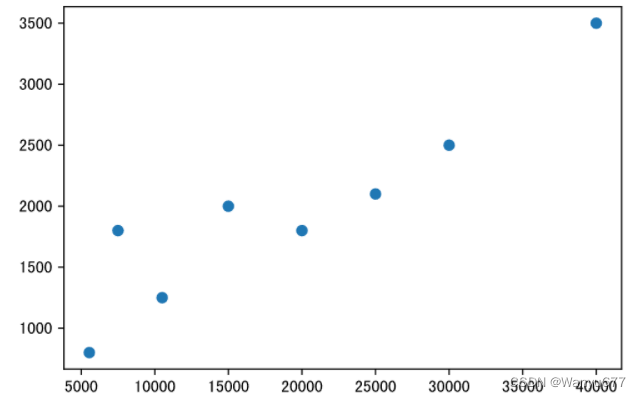
柱状图
在对比数据的差异时,柱状图是非常棒的选择,我们可以使用
pyplot
模块的
bar
函数来生成柱状图,也可以使用
barh
函数来生成水平柱状图(也称为“条状图”)。我们先为柱状图准备一些数据,代码如下所示。
x = np.arange(4)
y1 = np.random.randint(20, 50, 4)
y2 = np.random.randint(10, 60, 4)
绘制柱状图的代码。
代码:
plt.figure(figsize=(6, 4), dpi=120)
# 通过横坐标的偏移,让两组数据对应的柱子分开,width参数控制柱子的粗细,label参数为柱子添加标签
plt.bar(x - 0.1, y1, width=0.2, label='销售A组')
plt.bar(x + 0.1, y2, width=0.2, label='销售B组')
# 定制横轴的刻度
plt.xticks(x, labels=['Q1', 'Q2', 'Q3', 'Q4'])
# 定制显示图例
plt.legend()
plt.show()
输出:
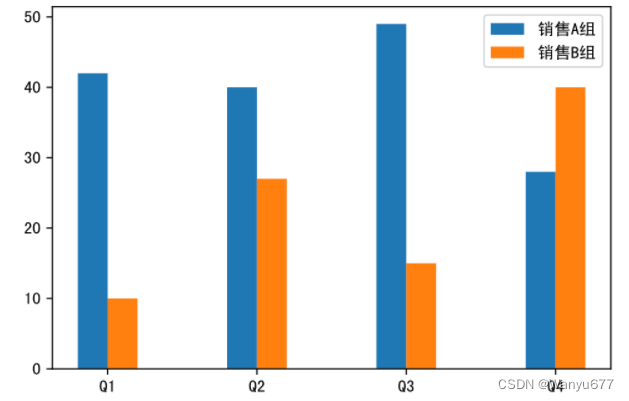
如果想绘制堆叠柱状图,可以对上面的代码稍作修改,如下所示。
代码:
labels = ['Q1', 'Q2', 'Q3', 'Q4']
plt.figure(figsize=(6, 4), dpi=120)
plt.bar(labels, y1, width=0.4, label='销售A组')
# 注意:堆叠柱状图的关键是将之前的柱子作为新柱子的底部,可以通过bottom参数指定底部数据,新柱子绘制在底部数据之上
plt.bar(labels, y2, width=0.4, bottom=y1, label='销售B组')
plt.legend(loc='lower right')
plt.show()
输出:
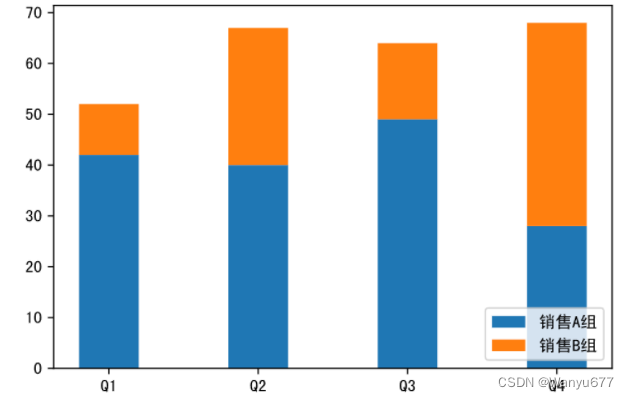
饼状图
饼状图通常简称为饼图,是一个将数据划分为几个扇形区域的统计图表,它主要用于描述数量、频率等之间的相对关系。在饼图中,每个扇形区域的大小就是其所表示的数量的比例,这些扇形区域合在一起刚好是一个完整的饼。在需要展示数据构成的场景下,饼状图、树状图和瀑布图是不错的选择,可以使用
pyplot
模块的
pie
函数来绘制饼图,代码如下所示。
代码:
data = np.random.randint(100, 500, 7)
labels = ['苹果', '香蕉', '桃子', '荔枝', '石榴', '山竹', '榴莲']
plt.figure(figsize=(5, 5), dpi=120)
plt.pie(
data,
# 自动显示百分比
autopct='%.1f%%',
# 饼图的半径
radius=1,
# 百分比到圆心的距离
pctdistance=0.8,
# 颜色(随机生成)
colors=np.random.rand(7, 3),
# 分离距离
# explode=[0.05, 0, 0.1, 0, 0, 0, 0],
# 阴影效果
# shadow=True,
# 字体属性
textprops=dict(fontsize=8, color='black'),
# 楔子属性(生成环状饼图的关键)
wedgeprops=dict(linewidth=1, width=0.35),
# 标签
labels=labels
)
# 定制图表的标题
plt.title('水果销售额占比')
plt.show()
输出:
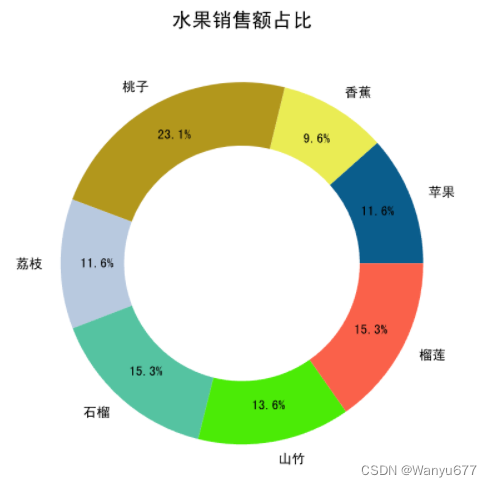
说明:可以试一试将上面代码中被注释的部分恢复,看看有什么样的效果哦。
直方图
在统计学中,直方图是一种展示数据分布情况的图形,是一种二维统计图表,它的两个坐标分别是统计样本和该样本对应的某个属性的度量。下面的数据是某学校100名男学生的身高,如果我们想知道数据的分布,就可以使用直方图。
heights = np.array([
170, 163, 174, 164, 159, 168, 165, 171, 171, 167,
165, 161, 175, 170, 174, 170, 174, 170, 173, 173,
167, 169, 173, 153, 165, 169, 158, 166, 164, 173,
162, 171, 173, 171, 165, 152, 163, 170, 171, 163,
165, 166, 155, 155, 171, 161, 167, 172, 164, 155,
168, 171, 173, 169, 165, 162, 168, 177, 174, 178,
161, 180, 155, 155, 166, 175, 159, 169, 165, 174,
175, 160, 152, 168, 164, 175, 168, 183, 166, 166,
182, 174, 167, 168, 176, 170, 169, 173, 177, 168,
172, 159, 173, 185, 161, 170, 170, 184, 171, 172
])
可以使用
pyplot
模块的
hist
函数来绘制直方图,其中
bins
参数代表了我们使用的分箱方式(身高从150厘米到190厘米,每5厘米为一个分箱),代码如下所示。
代码:
plt.figure(figsize=(6, 4), dpi=120)
# 绘制直方图
plt.hist(heights, bins=np.arange(145, 196, 5), color='darkcyan')
# 定制横轴标签
plt.xlabel('身高')
# 定制纵轴标签
plt.ylabel('概率密度')
plt.show()
输出:
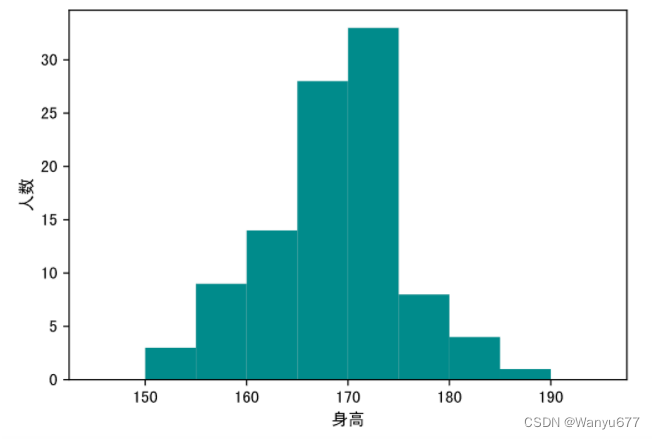
绘制直方图时,如果将
hist
函数的
density
参数修改为
True
,同时将
cumulative
参数也修改为
True
,那么一方面纵轴会显示为概率密度,而图表会绘制概率的累计分布,如下所示。
代码:
plt.figure(figsize=(6,4), dpi=120)# 绘制直方图
plt.hist(heights, bins=np.arange(145,196,5), color='darkcyan', density=True, cumulative=True)# 定制横轴标签
plt.xlabel('身高')# 定制纵轴标签
plt.ylabel('概率')
plt.show()
输出:
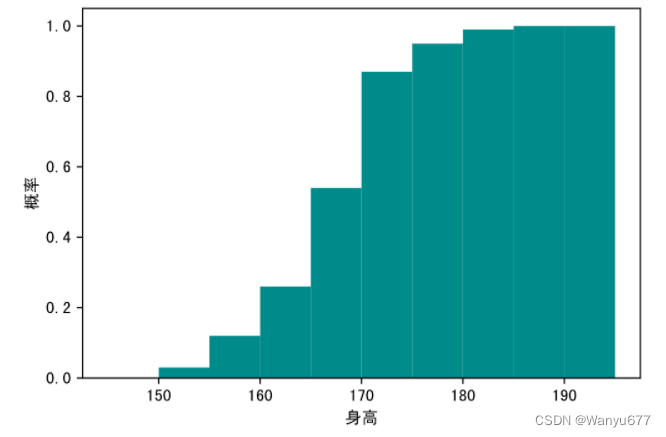
箱线图
箱线图又叫箱型图或盒须图,是一种用于展示一组数据分散情况的统计图表,如下所示。因图形如箱子,而且在上下四分位数之外有线条像胡须延伸出去而得名。在箱线图中,箱子的上边界是上四分位数(
Q
3
Q_3
Q3)的位置,箱子的下边界是下四分位数(
Q
1
Q_1
Q1)的位置,箱子中间的线条是中位数(
Q
2
Q_2
Q2)的位置,而箱子的长度就是四分位距离(IQR)。除此之外,箱子上方线条的边界是最大值,箱子下方线条的边界是最小值,这两条线之外的点就是离群值(outlier)。所谓离群值,是指数据小于
Q
1
−
1.5
×
I
Q
R
Q_1 - 1.5 \times IQR
Q1−1.5×IQR或数据大于
Q
3
+
1.5
×
I
Q
R
Q_3 + 1.5 \times IQR
Q3+1.5×IQR的值,公式中的
1.5
还可以替换为
3
来发现极端离群值(extreme outlier),而介于
1.5
到
3
之间的离群值通常称之为适度离群值(mild outlier)。
可以使用
pyplot
模块的
boxplot
函数来绘制箱线图,代码如下所示。
代码:
# 数组中有47个[0, 100)范围的随机数
data = np.random.randint(0, 100, 47)
# 向数组中添加三个可能是离群点的数据
data = np.append(data, 160)
data = np.append(data, 200)
data = np.append(data, -50)
plt.figure(figsize=(6, 4), dpi=120)
# whis参数的默认值是1.5,将其设置为3可以检测极端离群值,showmeans=True表示在图中标记均值的位置
plt.boxplot(data, whis=1.5, showmeans=True, notch=True)
# 定制纵轴的取值范围
plt.ylim([-100, 250])
# 定制横轴的刻度
plt.xticks([1], labels=['data'])
plt.show()
输出:
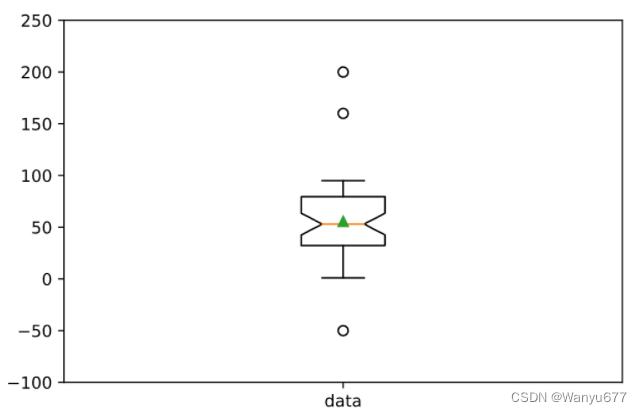
说明:由于数据是随机生成的,运行上面的代码生成的图表可能跟我这里并不相同,以实际运行结果为准。
显示或保存图像
可以使用
pyplot
模块的
show
函数来显示绘制的图表,在上面的代码中使用过这个函数。如果希望保存图表,可以使用
savefig
函数。需要注意的是,如果要同时显示和保存图表,应该先执行
savefig
函数,再执行
show
函数,因为在调用
show
函数时,图表已经被释放,位于
show
函数之后的
savefig
保存的只是一个空白的区域。
plt.savefig('chart.png')
plt.show()
其他图表
使用 matplotlib,还可以绘制出其他的统计图表(如:雷达图、玫瑰图、热力图等),但实际应用中,使用频率最高的几类图表在上面已经为大家完整的展示出来了。此外,matplotlib 还有很多对统计图表进行定制的细节,例如定制坐标轴、定制图表上的文字和标签等。如果想了解如何用 matplotlib 绘制和定制更多的统计图表,可以直接查看 matplotlib 官方网站上的文档和示例。
接下来,让我们一起尝试用 matplotlib 来绘制一些高阶统计图表。正如上面所说的,大家可以通过 matplotlib 官方网站来学习如何使用 matplotlib 并绘制出更加高级的统计图表;尤其是在定制一些比较复杂的图表时,建议大家直接找到官网提供的示例,然后只需要做出相应的修改,就可以绘制出自己想要的图表。这种“拷贝+修改”的做法应该会大大提高你的工作效率,因为大多数时候,你的代码跟官网上的代码就仅仅是数据有差别而已,没有必要去做重复乏味的事情。
气泡图
气泡图可以用来了解三个变量之间的关系,通过比较气泡位置和大小来分析数据维度之间的相关性。例如在我们之前绘制的月收入和网购支出的散点图中,我们已经发现了二者的正相关关系,如果我们引入第三个变量网购次数,那么我们就需要使用气泡图来进行展示。
代码:
income = np.array([5550,7500,10500,15000,20000,25000,30000,40000])
outcome = np.array([800,1800,1250,2000,1800,2100,2500,3500])
nums = np.array([5,3,10,5,12,20,8,10])# 通过scatter函数的s参数和c参数分别控制面积和颜色
plt.scatter(income, outcome, s=nums *30, c=nums, cmap='Reds')# 显示颜色条
plt.colorbar()# 显示图表
plt.show()
输出:
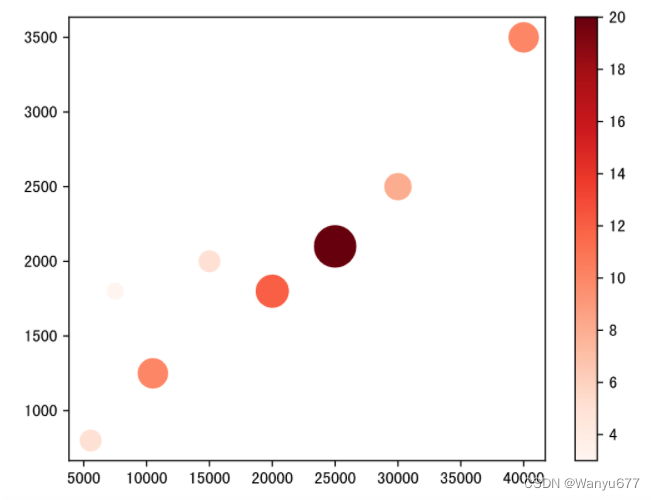
面积图
面积图又叫堆叠折线图,是在折线图的基础上,对折线以下的区域进行颜色填充(展示面积),用于在连续间隔或时间跨度上展示数值,一般用来显示趋势和对比数值,不同颜色的填充可以让多个面积块之间的对比和趋势更好的突显。下面的例子中,用面积图来展示从周一到周日花在睡觉、吃饭、工作和玩耍上的时间。
代码:
plt.figure(figsize=(8,4))
days = np.arange(7)
sleeping =[7,8,6,6,7,8,10]
eating =[2,3,2,1,2,3,2]
working =[7,8,7,8,6,2,3]
playing =[8,5,9,9,9,11,9]# 绘制堆叠折线图
plt.stackplot(days, sleeping, eating, working, playing)# 定制横轴刻度
plt.xticks(days, labels=[f'星期{x}'for x in'一二三四五六日'])# 定制图例
plt.legend(['睡觉','吃饭','工作','玩耍'], fontsize=10)# 显示图表
plt.show()
输出:
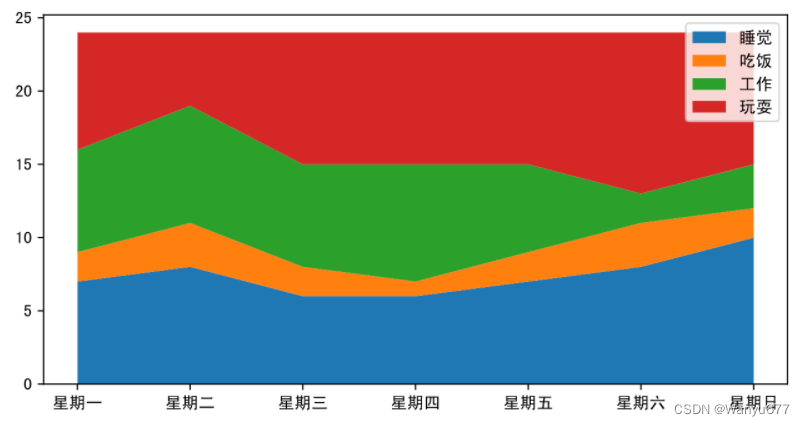
雷达图
雷达图通常用来比较多个定量数据,用于查看哪些变量具有相似的值。 雷达图也可用于查看数据集中哪些变量的值比较低,哪些变量的值比较高,是显示性能或表现的理想选择。经常观看篮球、足球比赛的读者或者是玩过王者荣耀的玩家应该对雷达图非常熟悉,例如在 NBA 的转播中就经常使用雷达图来展示球员的各项数据,使用雷达图对游戏角色,局内表现进行分析。雷达图的本质折线图,只不过将折线图映射到了极坐标系。在绘制雷达图时,需要让折线闭合,简单的说就是首尾相连,下面是绘制雷达图的代码。
代码:
labels = np.array(['速度','力量','经验','防守','发球','技术'])# 马龙和水谷隼的数据
malong_values = np.array([93,95,98,92,96,97])
shuigu_values = np.array([30,40,65,80,45,60])
angles = np.linspace(0,2* np.pi, labels.size, endpoint=False)# 多加一条数据让图形闭合
malong_values = np.append(malong_values, malong_values[0])
shuigu_values = np.append(shuigu_values, shuigu_values[0])
angles = np.append(angles, angles[0])# 创建画布
plt.figure(figsize=(4,4), dpi=120)# 创建坐标系
ax = plt.subplot(projection='polar')# 绘图和填充
plt.plot(angles, malong_values, color='r', linewidth=2, label='马龙')
plt.fill(angles, malong_values, color='r', alpha=0.3)
plt.plot(angles, shuigu_values, color='g', linewidth=2, label='水谷隼')
plt.fill(angles, shuigu_values, color='g', alpha=0.2)# 显示图例
ax.legend()# 显示图表
plt.show()
输出:
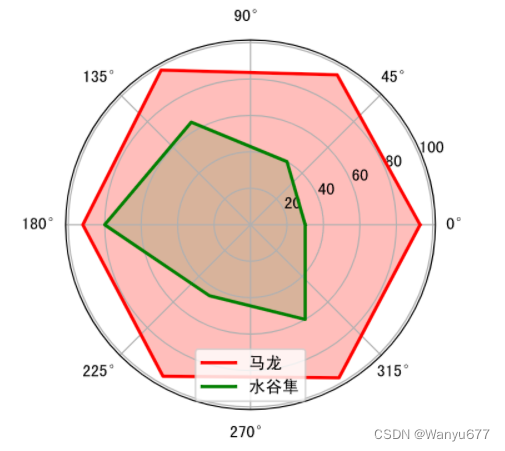
玫瑰图
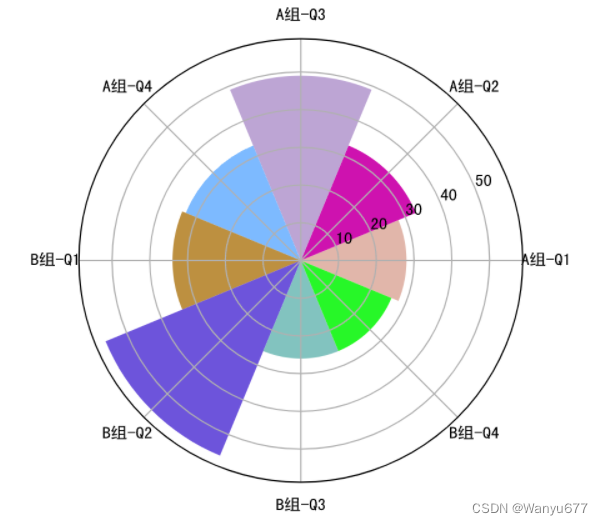
玫瑰图是映射在极坐标下的柱状图,由弗罗伦斯·南丁格尔(Florence Nightingale)所发明,当年是南丁格尔用来呈现战地医院季节性死亡率的一种图表。由于半径和面积的关系是平方的关系,南丁格尔玫瑰图会将数据的比例大小夸大,尤其适合对比大小相近的数值,同时由于圆形有周期的特性,所以南丁格尔玫瑰图也适用于表示一个周期内的时间概念,比如星期、月份。
代码:
group1 = np.random.randint(20,50,4)
group2 = np.random.randint(10,60,4)
x = np.array([f'A组-Q{i}'for i inrange(1,5)]+[f'B组-Q{i}'for i inrange(1,5)])
y = np.array(group1.tolist()+ group2.tolist())# 玫瑰花瓣的角度和宽度
theta = np.linspace(0,2* np.pi, x.size, endpoint=False)
width =2* np.pi / x.size
# 生成8种随机颜色
colors = np.random.rand(8,3)# 将柱状图投影到极坐标
ax = plt.subplot(projection='polar')# 绘制柱状图
plt.bar(theta, y, width=width, color=colors, bottom=0)# 设置网格
ax.set_thetagrids(theta *180/ np.pi, x, fontsize=10)# 显示图表
plt.show()
输出:
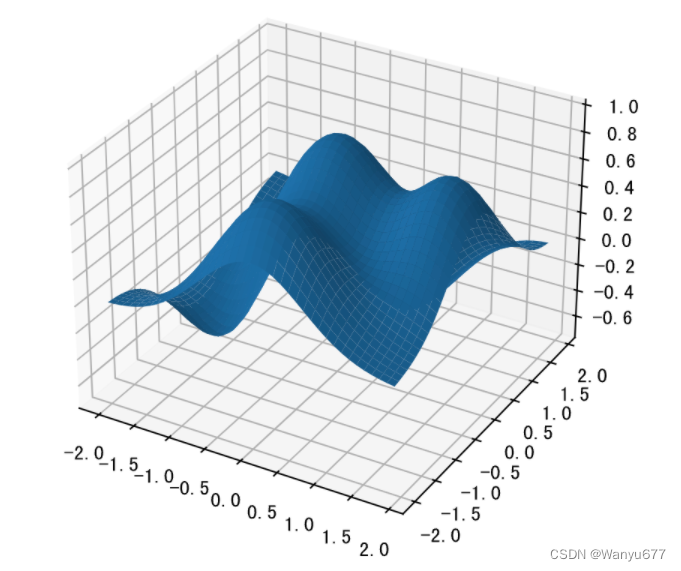
3D图
matplotlib 还可以用于绘制3D图,具体的内容可以参考官方文档,下面用一段简单的代码为大家展示如何绘制3D图表。
代码:
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8,4), dpi=120)# 创建3D坐标系并添加到画布上
ax = Axes3D(fig, auto_add_to_figure=False)
fig.add_axes(ax)
x = np.arange(-2,2,0.1)
y = np.arange(-2,2,0.1)
x, y = np.meshgrid(x, y)
z =(1- y **5+ x **5)* np.exp(-x **2- y **2)# 绘制3D曲面
ax.plot_surface(x, y, z)# 显示图表
plt.show()
输出:
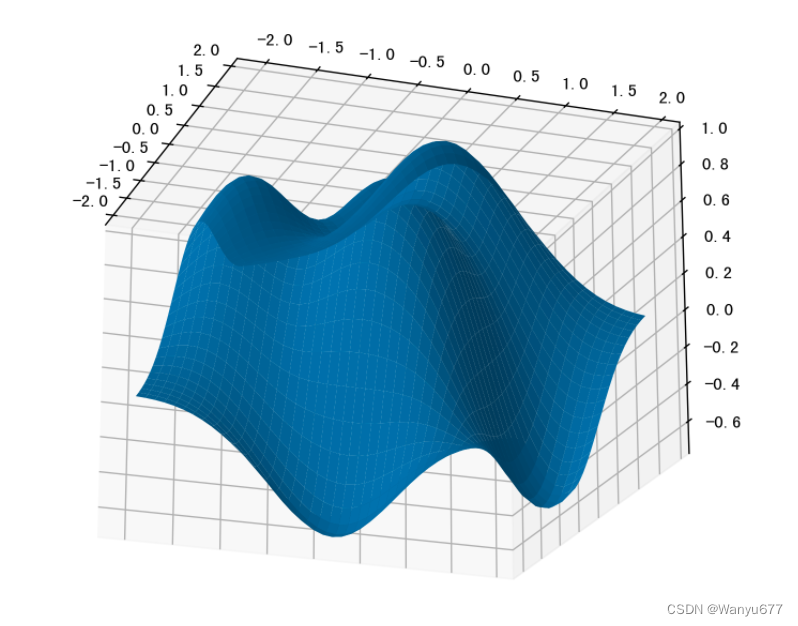
需要指出的是, JupyterLab 中渲染的3D图并不是真正的3D图,因为你没有办法调整观察者的视角,也没有办法旋转或者缩放。如果想要看到真正的3D效果,需要在将图表渲染到 Qt 窗口中,为此我们可以先安装名为 PyQt6 的三方库,如下所示。
%pip install PyQt6
然后,我们使用魔法指令让 JupyterLab 将图表渲染到 Qt 窗口中。
%matplotlib qt
在完成上面的操作后,可以重新运行刚才绘制3D图的代码,看到如下所示的窗口。在这个窗口中,可以通过鼠标对3D进行旋转、缩放,有可以选中图表的一部分数据进行观测,是不是非常的酷!
通过上面的学习,我们已经对数据可视化工具 matplotlib 有一个初步的认知。大家可能也会发现了,matplotlib 提供的函数虽然强大,但是参数太多,要想对图表进行深度的定制就需要修改一系列的参数,这一点对新手并不友好。另一方面,使用 matplotlib 定制的统计图是静态图表,可能在某些需要交互效果的场景下并不合适。为了解决这两个问题,下面为大家介绍两个新的可视化工具,一个是 seaborn,一个是 pyecharts。
Seaborn
Seaborn 是建立在 matplotlib 之上的数据可视化工具,它相当于是对 matplotlib 进行了更高级的封装,而且 seaborn 也能跟 pandas 无缝整合,让我们可以用更少的代码构建出更好的统计图表,帮助我们探索和理解数据。Seaborn 包含但不局限于以下描述的功能:
- 面向数据集的 API,可用于检查多个变量之间的关系。
- 支持使用分类变量来显示观察结果或汇总统计数据。
- 能够可视化单变量或双变量分布以及在数据子集之间进行比较的选项
- 各类因变量线性回归模型的自动估计与作图。
- 集成调色板和主题,轻松定制统计图表的视觉效果。
可以使用 Python 的包管理工具 pip 来安装 seaborn。
pip install seaborn
在 Jupyter 中,可以直接使用魔法指令进行安装,如下所示。
%pip install seaborn
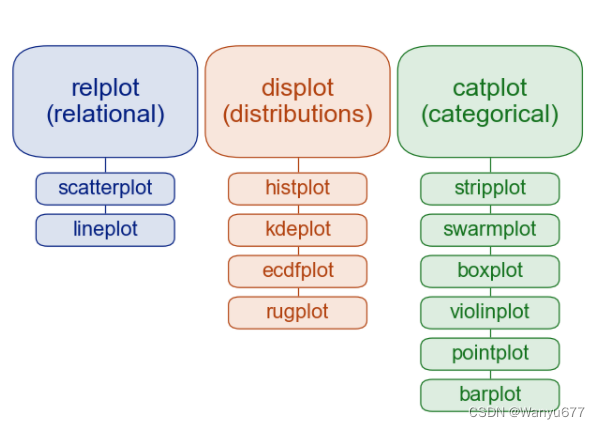
下面,我们用 seaborn 自带的数据集为例,为大家简单的展示 seaborn 的用法和强大之处,想要深入研究 seaborn 的读者可以自行阅读官方文档和并查看官方作品集中的示例。根据官方示例来编写自己的代码是一个不错的选择,简单的说就是保留官方代码,将数据换成自己的数据即可。下图展示了 seaborn 绘制图表的函数,可以看出,seaborn 的这些函数主要支持我们通过绘制图表来探索数据的关系、分布和分类。
使用 seaborn,首先需要导入该库并设置主题,代码如下所示。
import seaborn as sns
sns.set_theme()
如果需要在图表上显示中文,还需要用之前讲过的方法修改 matplotlib 的配置参数,代码如下所示。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'].insert(0, 'SimHei')
plt.rcParams['axes.unicode_minus'] = False
注意:上面的代码必须放在调用 set_theme 函数之后,否则调用 set_theme 函数时又会重新修改 matplotlib 配置参数中的字体设置。
加载官方的 Tips 数据集(就餐小费数据)。
tips_df = sns.load_dataset('tips')
tips_df.info()
运行结果如下所示,其中 total_bill 表示账单总金额,tip 表示小费的金额,sex 是顾客的性别,smoker 表示顾客是否抽样,day 代表星期几,time 代表是午餐还是晚餐,size 是就餐人数。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.4 KB
由于数据集是联网加载的,上述代码可能因为 SSL 的原因无法获取到数据,可以尝试先运行下面的代码,然后再加载数据集。
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
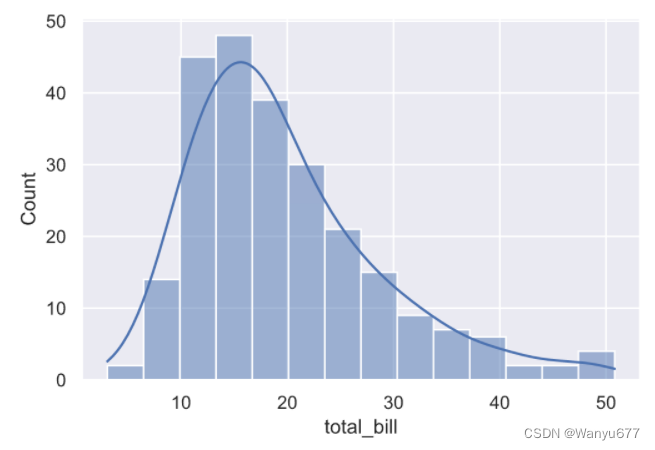
如果希望了解账单金额的分布,可以使用下面的代码来绘制分布图。
sns.histplot(data=tips_df, x='total_bill', kde=True)
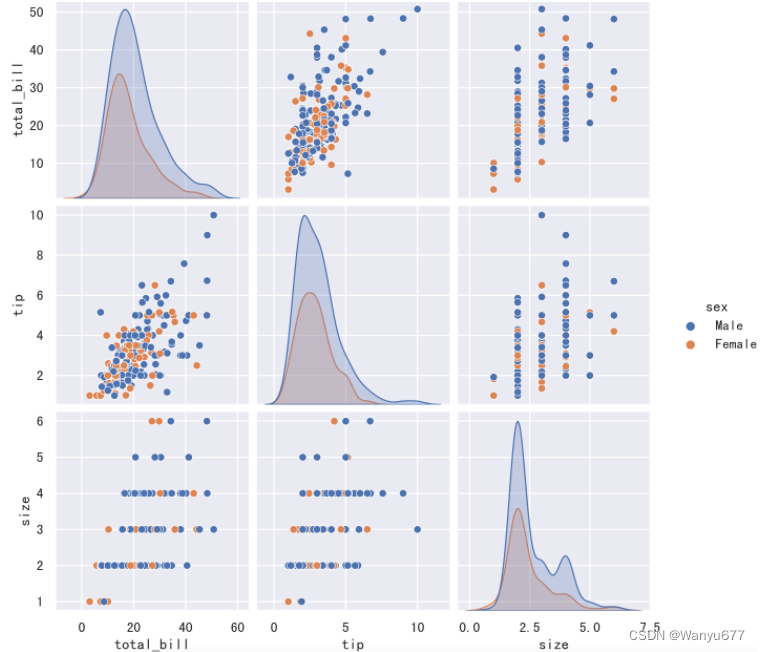
如果想了解变量之间的两两关系,我们可以绘制点对图,代码和效果如下所示。
sns.pairplot(data=tips_df, hue='sex')
将上面的代码稍作修改,看看运行结果有什么差别。
sns.pairplot(data=tips_df, hue='sex', palette='Dark2')
接下来,为 total_bill 和 tip 两组数据绘制联合分布图,代码如下所示。
sns.jointplot(data=tips_df, x='total_bill', y='tip', hue='sex')
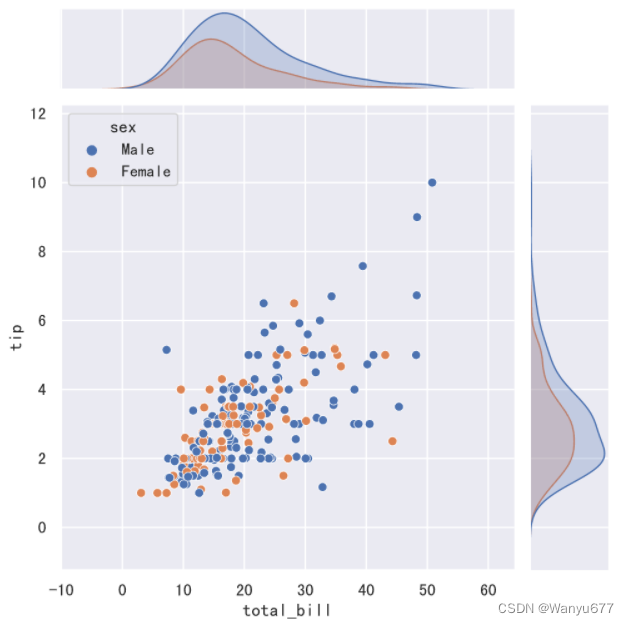
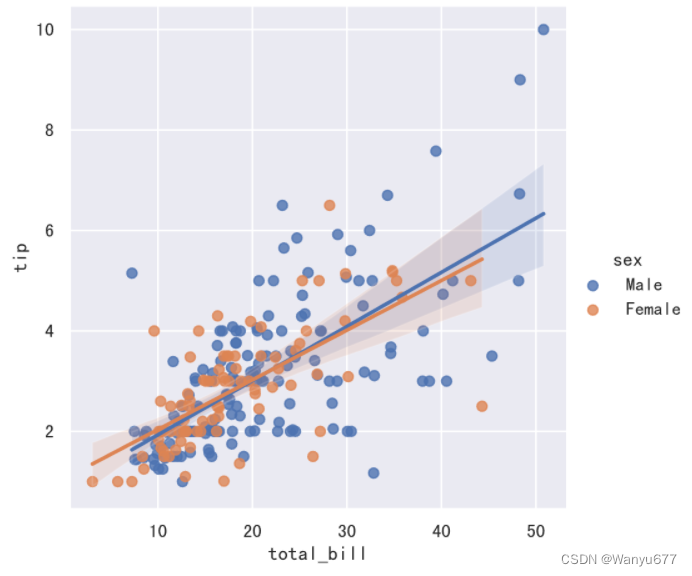
上面清晰的展示了,total_bill 和 tip 之间存在正相关关系,这一点也可以通过 DataFrame 对象的 corr 方法进行验证。接下来,可以建立回归模型来拟合这些数据点,而 seaborn 的线性回归模型图已经帮实现了这项功能,代码如下所示。
sns.lmplot(data=tips_df, x='total_bill', y='tip', hue='sex')
如果希望了解账单金额的集中和离散趋势,可以绘制箱线图或小提琴图,代码如下所示,将数据按星期四、星期五、星期六和星期天分别进行展示。
sns.boxplot(data=tips_df, x='day', y='total_bill')
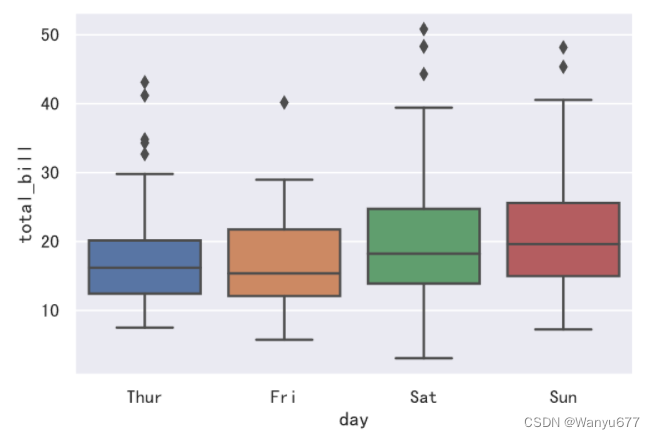
sns.violinplot(data=tips_df, x='day', y='total_bill')

说明:相较于箱线图,小提琴图没有标注异常点而是显示了数据的整个范围,另一方面,小提琴图很好的展示了数据的分布(密度轨迹)。
累了,最后让Al总结下叭~~~
这篇文档是一份关于数据可视化的教程,主要介绍了如何使用Python的matplotlib和seaborn库来创建和定制各种统计图表。文档首先解释了数据可视化的重要性,然后逐步介绍了matplotlib的基本使用,包括如何安装、配置、创建画布和坐标系,以及如何绘制折线图、散点图、柱状图、饼状图、直方图和箱线图等。此外,还探讨了如何绘制更高级的图表,如气泡图、面积图、雷达图、玫瑰图和3D图。最后,文档介绍了seaborn库,它提供了更简洁的API和美观的主题,特别适合与pandas库结合使用,以更高效地探索和理解数据。通过丰富的代码示例和图表输出,文档为读者提供了一个全面的学习资源。
希望文章会对您有所帮助~~~
有关Numpy和Pandas的内容在主页也有详细介绍哦~
Pandas万字总结1
Numpy万字总结1
版权归原作者 Wanyu677 所有, 如有侵权,请联系我们删除。