
• Kafka简介
-Apache Kafka发源于LinkedIn,于2011年成为Apache的孵化项目,随后于2012年成为Apache的主要项目之一。
-Kafka使用Scala和Java进行编写。Apache Kafka是一个快速、可扩展的、高吞吐、可容错的分布式发布订阅消息系统。Kafka具有高吞吐量、内置分区、支持数据副本和容错的特性,适合在大规模消息处理场景中使用。
• Kafka特点
- 可靠性:Kafka是一个具有分区机制、副本机制和容错机制的分布式消息系统
- 可扩展性:Kafka消息系统支持集群规模的热扩展
- 高性能:Kafka在数据发布和订阅过程中都能保证数据的高吞吐量。即便在TB级数据存储的情况下,仍然能保证稳定的性能。
• Kafka术语
- Topic:在Kafka中,使用一个类别属性来划分数据的所属类,划分数据的这个类称为topic。如果把Kafka看做为一个数据库,topic可以理解为数据库中的一张表,topic的名字即为表名。
- Partition:topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
- Partition offset:每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。
- Replicas of partition:副本是一个分区的备份。副本不会被消费者消费,副本只用于防止数据丢失,即消费者不从为follower的partition中消费数据,而是从为leader的partition中读取数据。
- Broker:- Kafka 集群包含一个或多个服务器,服务器节点称为broker。- broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。- 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。- 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
- Producer:生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
- Consumer:消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
- Leader:每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
- Follower:Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
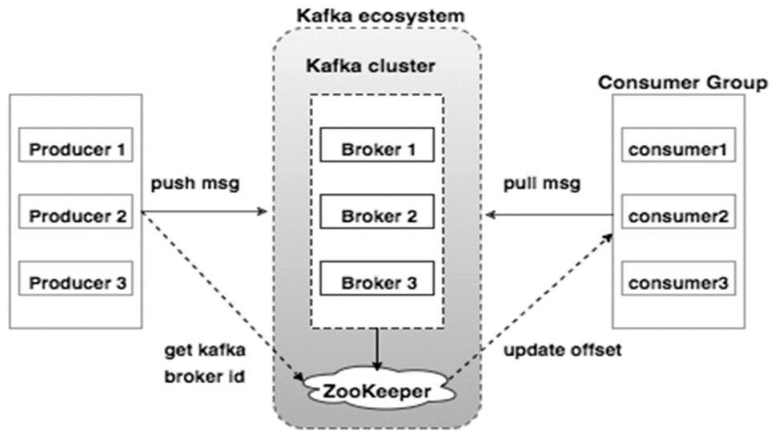
- Broker:Kafka的broker是无状态的,broker使用Zookeeper维护集群的状态。Leader的选举也由Zookeeper负责。
- Zookeeper:Zookeeper负责维护和协调broker。当Kafka系统中新增了broker或者某个broker发生故障失效时,由ZooKeeper通知生产者和消费者。生产者和消费者依据Zookeeper的broker状态信息与broker协调数据的发布和订阅任务。
- Producer:生产者将数据推送到broker上,当集群中出现新的broker时,所有的生产者将会搜寻到这个新的broker,并自动将数据发送到这个broker上。
- Consumer:因为Kafka的broker是无状态的,所以consumer必须使用partition offset来记录消费了多少数据。如果一个consumer指定了一个topic的offset,意味着该consumer已经消费了该offset之前的所有数据。consumer可以通过指定offset,从topic的指定位置开始消费数据。consumer的offset存储在Zookeeper中。
• 引入依赖
- spring-kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
• 配置Kafka
- 配置server、consumer
# KafkaProperties
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=community-consumer-group
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=3000
- 生产者
kafkaTemplate.send(topic, data);
@Component
class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic, String content) {
kafkaTemplate.send(topic, content);
}
}
- 消费者
@KafkaListener(topics = {"test"})
public void handleMessage(ConsumerRecord record) {}
@Component
class KafkaConsumer {
@KafkaListener(topics = {"test"})
public void handleMessage(ConsumerRecord record) {
System.out.println(record.value());
}
}
主函数调用
@Test
public void testKafka() {
kafkaProducer.sendMessage("test", "你好");
kafkaProducer.sendMessage("test", "在吗");
try {
Thread.sleep(1000 * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
整体代码
package com.nowcoder.community;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class KafkaTests {
@Autowired
private KafkaProducer kafkaProducer;
@Test
public void testKafka() {
kafkaProducer.sendMessage("test", "你好");
kafkaProducer.sendMessage("test", "在吗");
try {
Thread.sleep(1000 * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Component
class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic, String content) {
kafkaTemplate.send(topic, content);
}
}
@Component
class KafkaConsumer {
@KafkaListener(topics = {"test"})
public void handleMessage(ConsumerRecord record) {
System.out.println(record.value());
}
}
本文转载自: https://blog.csdn.net/qq_51118755/article/details/128794921
版权归原作者 晓宜 所有, 如有侵权,请联系我们删除。
版权归原作者 晓宜 所有, 如有侵权,请联系我们删除。