
Docker容器环境下搭建Hadoop集群(完全分布式)
hadoop版本为hadoop-3.1.3
(1)安装额外的速度较快的镜像库
yum install -y epel-release
(2)安装同步工具,方便在多台服务器上进行文件的传输
yum install -y rsync
(3)安装网络工具
yum install -y net-tools
(4)安装具有代码高亮显示的编辑器
yum install -y vim
一、docker安装
安装所需要的资源包
yum install -y yum-utils
设置仓库(阿里云)
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
安装docker
yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
查看安装列表
yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
启动docker
systemctl start docker
关闭防火墙
sudo systemctl stop firewalld
sudo systemctl disable firewalld
关闭 iptables
sudo systemctl stop iptables
sudo systemctl disable iptables
查看状态
systemctl status docker
查看安装版本
docker version
拉取镜像
docker pull hello-world
通过运行 hello-world 镜像来验证是否正确安装了 Docker Engine-Community 。
docker run hello-world
二、Docker基础使用命令
1、启动docker
systemctl start docker
2、停止docker
systemctl stop docker
3、重启docker
systemctl restart docker
4、查看docker
systemctl status docker
5、设置开机自启
systemctl enable docker
6、查看docker概要信息
docker info
7、查看镜像
docker images
8、拉取镜像
docker pull hello-world
9、运行镜像
docker run hello-world
10、运行一个容器
docker run
: 运行一个容器。
示例:
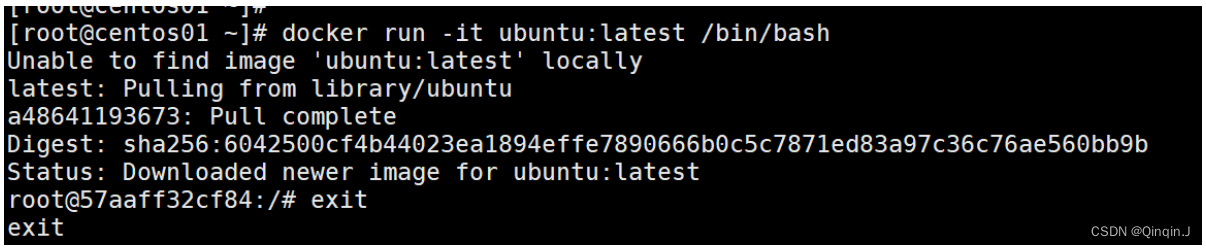
docker run -it ubuntu:latest /bin/bash
,这将在一个Ubuntu镜像上启动一个交互式的bash会话。
docker run -it ubuntu:latest /bin/bash
11、执行交互模式
docker exec -it <容器ID或容器名称> <命令>

12、列出正在运行的容器
docker ps : 列出正在运行的容器。
docker ps

查看所有容器
docker ps -a

13、停止一个正在运行的容器
docker stop
: 停止一个正在运行的容器。
示例:
docker stop <容器ID或名称>
,这将停止指定的容器。

14、删除一个容器
docker rm
: 删除一个容器。
示例:
docker rm <容器ID或名称>
,这将删除指定的容器。
docker rm -f <容器ID或名称> #强制删除

15、删除一个镜像
docker rmi
: 删除一个镜像。
示例:
docker rmi <镜像ID或名称>
,这将删除指定的镜像。
要先停止容器才能删除镜像
一、创建docker 网络
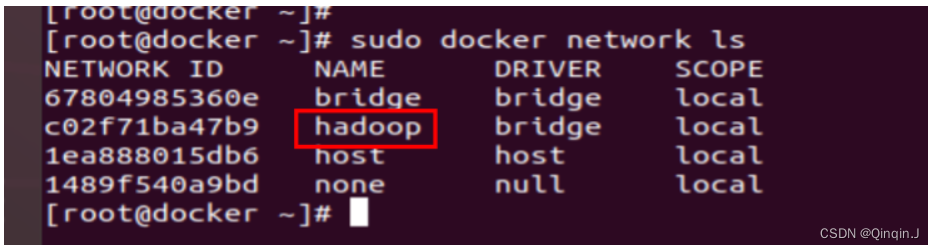
docker network create --driver=bridge hadoop
使用下面这个命令查看 Docker 中的网络
docker network ls
1、运行一个容器并加入到 hadoop 网络:
docker run -itd --name master --network hadoop centos:7 /bin/bash
docker run -itd --name slave1 --network hadoop centos:7 /bin/bash
docker run -itd --name slave2 --network hadoop centos:7 /bin/bash
拉取容器后,可以 exit 退出
2、连接容器
docker exec -it master /bin/bash
docker exec -it slave1 /bin/bash
docker exec -it slave2 /bin/bash
查看
docker network inspect hadoop
二、安装必备软件 ssh jdk8
1、安装jdk8
在宿主机上发文件
docker cp jdk-8u161-linux-x64.tar.gz master:/opt/software/
在容器中解压
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module/
配置 /etc/profile文件
vi /etc/profile
export JAVA_HOME=/opt/module/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
查看(生效环境变量)
source /etc/profile
java -version
2、安装ssh
在容器安装
yum install openssh-server -y
yum install openssh-clients -y
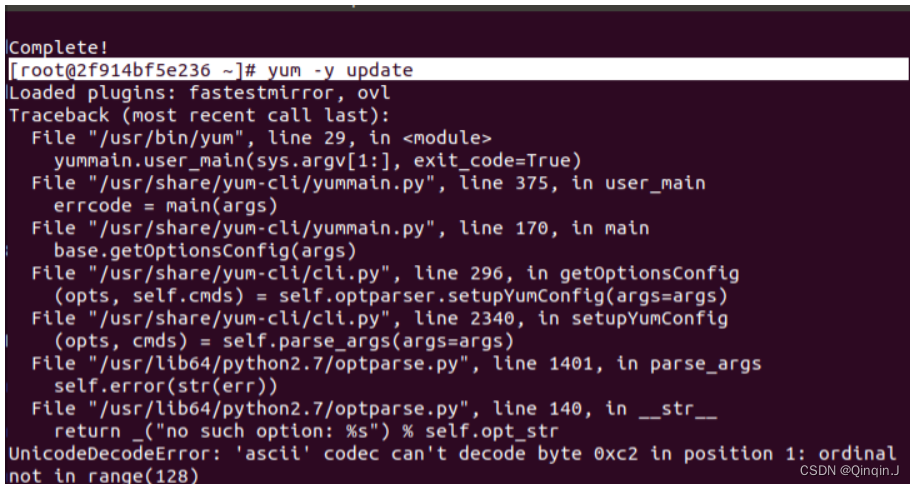
yum -y install passwd openssl openssh-server openssh-clients -y
yum -y update -y
报错
解决
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
yum -y update
3、解决 SSH 服务启动时可能出现的报错
创建 /var/run/sshd/目录,要不然sshd服务启动会报错
mkdir /var/run/sshd/
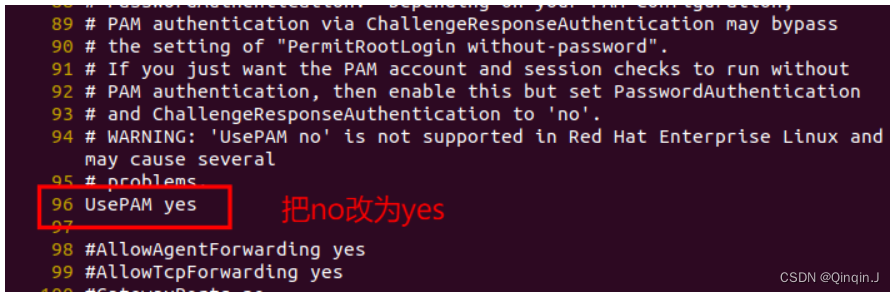
方法一:
编辑sshd的配置文件/etc/ssh/sshd_config,将其中的UsePAM no改为UsePAM yes
vi /etc/ssh/sshd_config
方法二:
sed -i "s/UsePAM.*/UsePAM yes/g" /etc/ssh/sshd_config
4、创建公钥
输入命令后,按两次回车键即可生成
ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key
ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key
完成上述几步后,可以开启ssh服务了
/usr/sbin/sshd
此时使用命令ps -ef | grep sshd 便可以看到
ps -ef | grep sshd
yum -y install lsof

5、修改root密码
passwd #回车输入密码 #都要进行改密码
6、配置免密
输入命令后按四次回车键
ssh-keygen -t rsa
分发密钥
ssh-copy-id 主机名
报错


解决
cat ~/.ssh/id_rsa.pub
cat id_rsa.pub >> ~/.ssh/authorized_keys
#将密钥内容手动复制到个节点上
把authorized_keys内容复制到个节点上
#免密登录
ssh root@slave1
7、vi ~/.bashrc
在容器中添加
vi ~/.bashrc
在文件最后写入
/usr/sbin/sshd -D &
这样我们每次登录centos系统时,都能自动启动sshd服务
8、保存镜像文件
使用命令docker ps查看当前运行的容器:
docker ps
然后使用命令docker commit 容器id kerin/centos7:basic
docker commit 容器id kerin/centos7:basic
使用命令docker images 查看当前docker中所有镜像
docker images

三、制作安装hdoop镜像
1、安装hdoop
在宿主机
cd /opt/software/
docker cp hadoop-3.1.3.tar.gz master:/opt/software/
进入容器解压
cd /opt/software/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
2、配置环境变量
vi /etc/profile
#添加以下内容
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 生效环境变量
source /etc/profile
# 查看 hadoop 版本
hadoop version
3、配置Hadoop
集群分布
(1)、配置core-site.xml
vi core-site.xml
添加以下内容
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ha01:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<!-- <property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property> -->
</configuration>
原文件查找
core-default.xml:在
$HADOOP_HOME/share/hadoop/common/hadoop-common-3.2.2.jar
中
cd /opt/module/hadoop-3.1.3/share/hadoop/common/
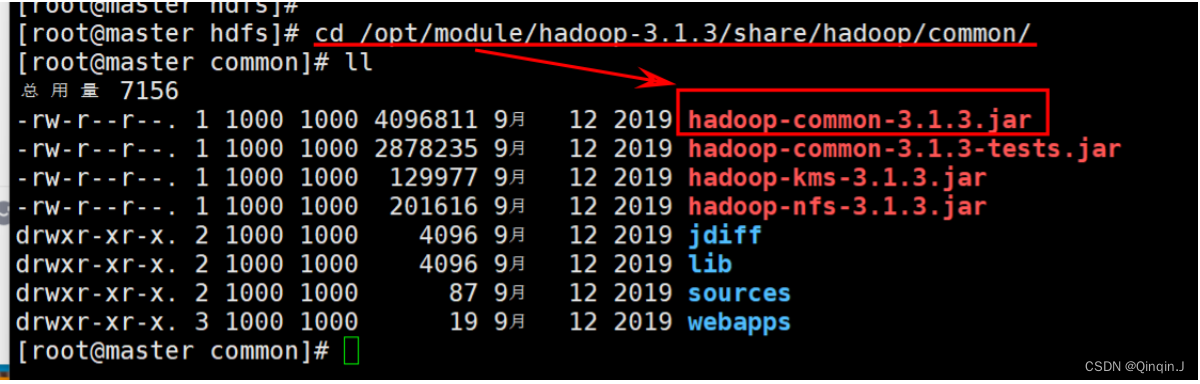
mkdir /root/hadoop-path
复制
cp hadoop-common-3.1.3.jar /root/hadoop-path
解压(从解压hadoop-common-3.1.3.jar中提取core-default.xml文件
jar xf hadoop-hdfs-3.1.3.jar core-default.xml
(2)、配置hdfs-site.xml
vi hdfs-site.xml
添加以下内容
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>ha01:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ha03:9868</value>
</property>
</configuration>
原文件查找
cd /opt/module/hadoop-3.1.3/share/hadoop/hdfs

复制
cp hadoop-hdfs-3.1.3.jar /root/hadoop-path/
解压
jar xf hadoop-hdfs-3.1.3.jar hdfs-site.xml
(3)、配置 yarn-site.xml
vi yarn-site.xml
添加以下内容
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ha02</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
原文件查找
cd /opt/module/hadoop-3.1.3/share/hadoop/hdfs

复制
cp hadoop-hdfs-3.1.3.jar /root/hadoop-path/
解压
jar xf hadoop-hdfs-3.1.3.jar hdfs-site.xml
开启日志聚集功能
vi yarn-site.xml
添加以下内容(最后配置)
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>ha02</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://ha01:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
如果是格式化后添加配置历史服务器,需要分发文件
scp $HADOOP_HOME/etc/hadoop/yarn-site.xml root@ha02:$HADOOP_HOME/etc/hadoop
scp $HADOOP_HOME/etc/hadoop/yarn-site.xml root@ha03:$HADOOP_HOME/etc/hadoop
4、配置mapred-site.xml
vi mapred-site.xml
添加以下内容
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
原文件查找
cd /opt/module/hadoop-3.1.3/share/hadoop/hdfs

复制
cp hadoop-mapreduce-client-core-3.1.3.jar /root/hadoop-path/
解压
jar xf hadoop-mapreduce-client-core-3.1.3.jar mapred-default.xml
配置历史服务器
vi mapred-site.xml
添加以下内容(最后配置)
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>ha01:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>ha01:19888</value>
</property>
</configuration>
如果是格式化后添加配置历史服务器,需要分发文件
scp $HADOOP_HOME/etc/hadoop/mapred-site.xml root@ha02:$HADOOP_HOME/etc/hadoop
scp $HADOOP_HOME/etc/hadoop/mapred-site.xml root@ha03:$HADOOP_HOME/etc/hadoop
(5)、配置workers
vi workers
添加以下内容
ha01
ha02
ha03
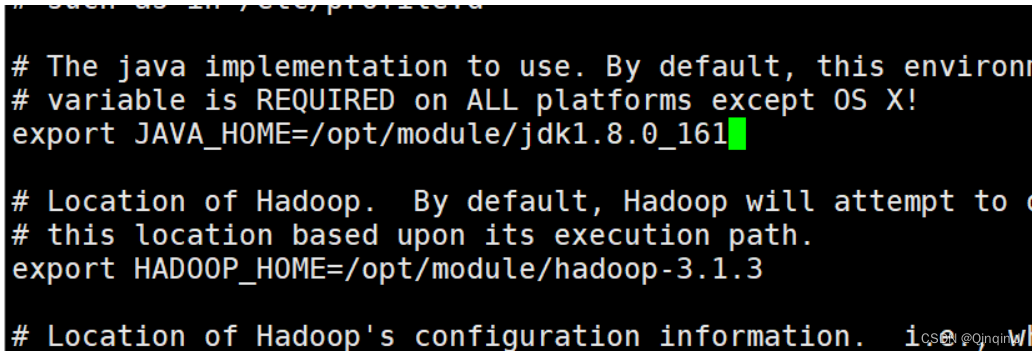
(6)、配置hadoop-env.sh
vi hadoop-env.sh
添加以下内容
export JAVA_HOME=/opt/module/jdk1.8.0_161
export HADOOP_HOME=/opt/module/hadoop-3.1.3
(7)、分发 hadoop 、Java、环境变量
hadoop
scp -r /opt/module/hadoop-3.1.3/ ha@ha02:/opt/module/
scp -r /opt/module/hadoop-3.1.3/ ha@ha03:/opt/module/
Java
scp -r /opt/module/jdk1.8.0_161 ha@ha02:/opt/module/
scp -r /opt/module/jdk1.8.0_161 ha@ha03:/opt/module/
环境变量
scp -r /etc/profile/ root@ha02:/etc/
scp -r /etc/profile/ root@ha03:/etc/
生效环境变量
source /etc/profile
4、保存镜像
(注意先停掉有数据的服务。如hdfs 防止造成不同步)
在容器master 中
stop-all.shjps
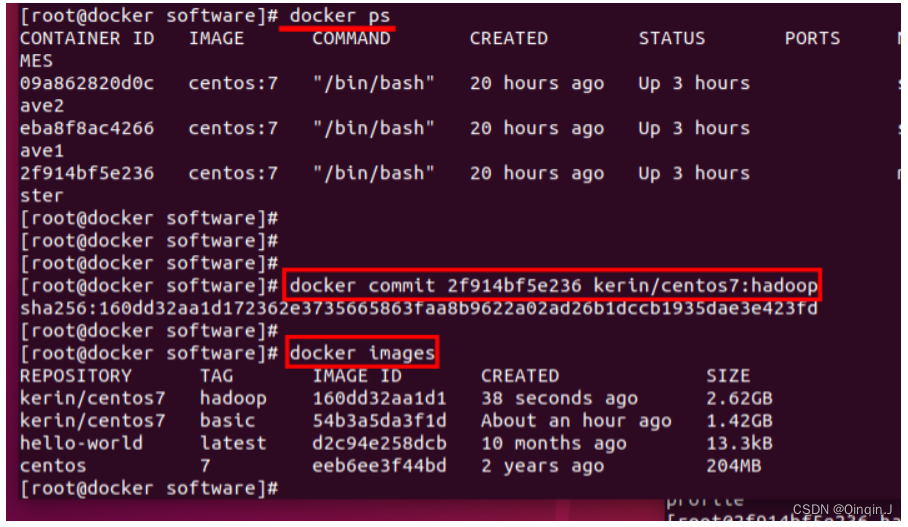
在宿主机中
docker images
docker ps
docker commit id kerin/centos7:hadoop
四、使用hadoop镜像搭建集群
1、停用和删除全部运行中的容器
docker stop id
docker rm -f id
2、创建master、slave1、slave2
master
docker run -it --network hadoop -h "master" --name "master" -p 9870:9870 -p 8081:8081 -p 60010:60010 -p 2181:2181 -p 8080:8080 -p 4040:4040 -p 3306:3306 -p 18080:18080 -p 19888:19888 kerin/centos7:hadoop /bin/bash
# 退出
exit
slave1
docker run -it --network hadoop -h "slave1" --name "slave1" -p 8088:8088 kerin/centos7:hadoop /bin/bash
# 退出
exit
slave2
docker run -it --network hadoop -h "slave2" --name "slave2" -p 9868:9868 kerin/centos7:hadoop /bin/bash
# 退出
exit

-p 后面表示要向主机映射的端口号
3、格式化
启动容器
进入容器
docker exec -it master /bin/bash
docker exec -it slave1 /bin/bash
docker exec -it slave2 /bin/bash
格式化
hdfs namenode -format
4、启动
启动start-dfs.sh
start-dfs.sh
报错一
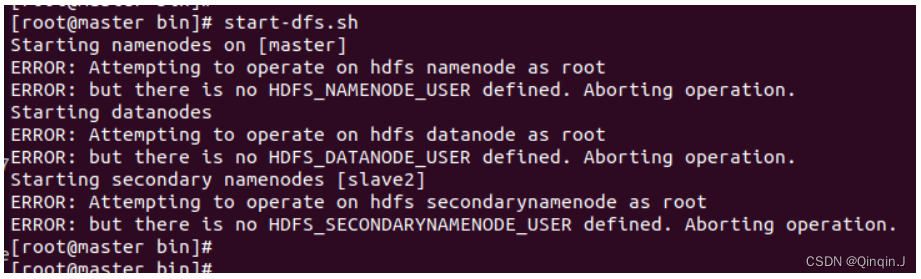
解决
vi /etc/profile
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
分发
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/

报错二
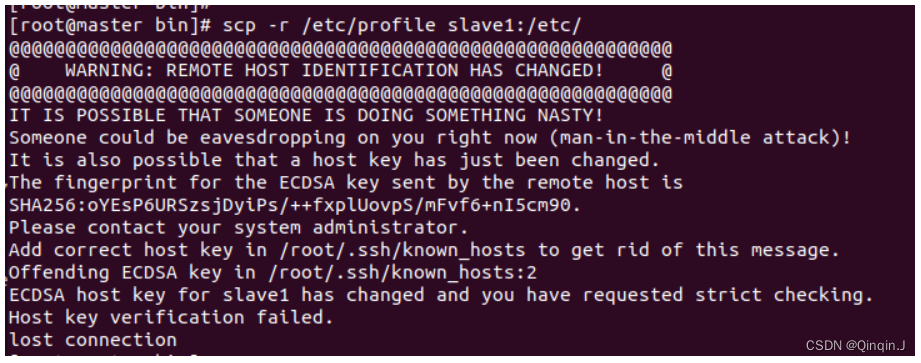
解决
vi /root/.ssh/known_hosts
注释第二行和第三行
重新运行 scp -r /etc/profile slave1:/etc/ 命令,SSH 将会询问您是否要添加 slave1 的新密钥,输入 yes 以接受并添加新的主机密钥。
scp -r /etc/profile slave1:/etc/
启动start-yarn.sh
start-yarn.sh
报错 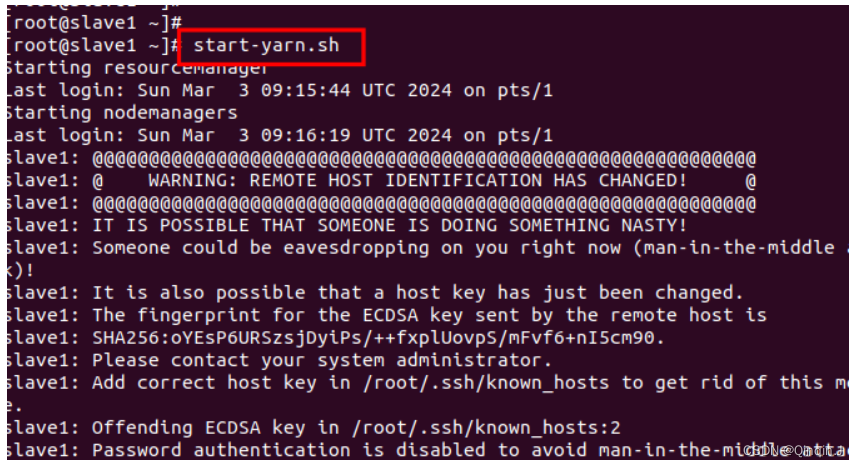
解决
vi /root/.ssh/known_hosts
注释第二行和第三行
查看进程
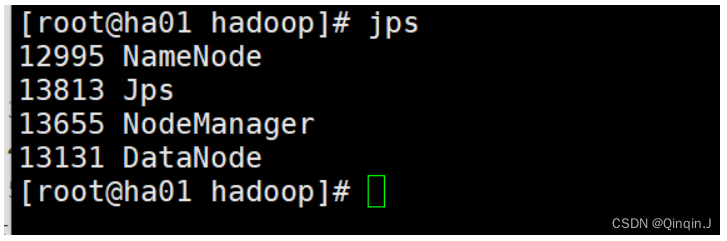
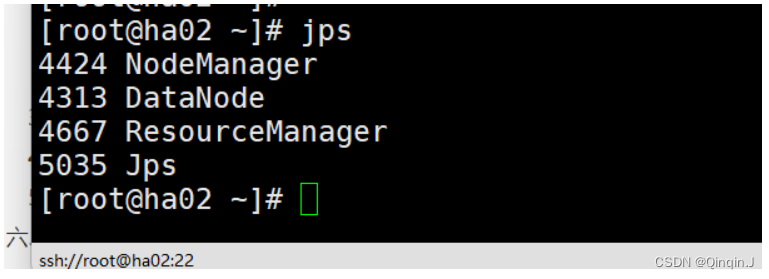
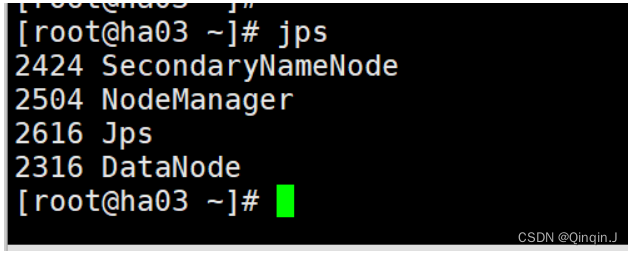
5、访问端口
windos添加访问容器路由
ROUTE -p add 172.20.0.0 mask 255.255.0.0 192.168.153.134
ubuntu添加访问容器路由
sudo ip route add 172.20.0.0/16 via 192.168.153.134
宿主机ip+端口号
192.168.153.134:9870
192.168.153.134:8088
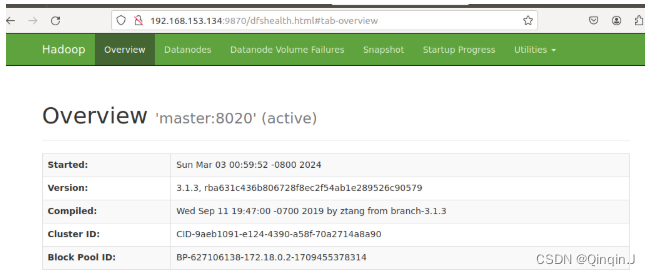

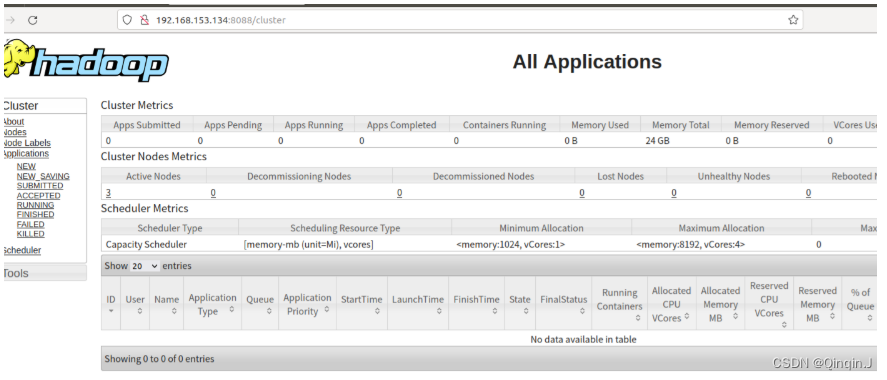
6、保存镜像
(注意先停掉有数据的服务。如hdfs 防止造成不同步)
在容器master 中
stop-all.shjps
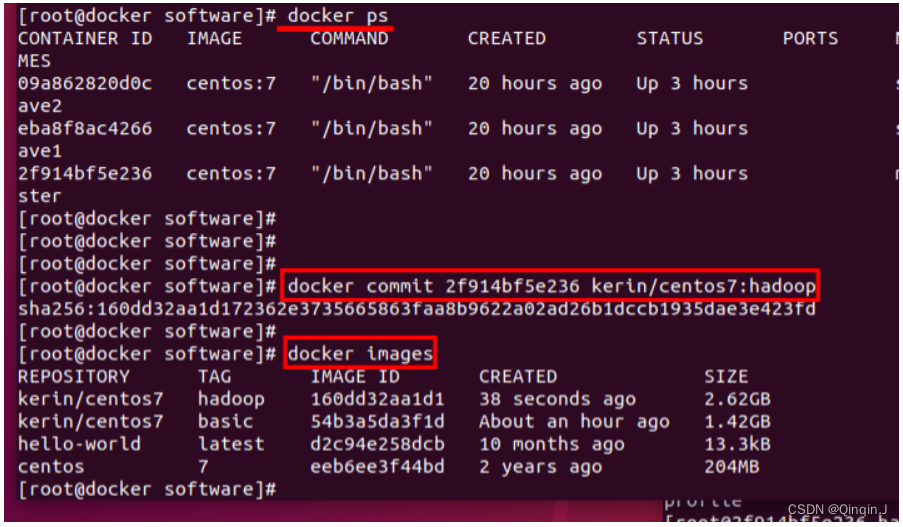
在宿主机中
docker images
docker ps
docker commit master容器的id kerin/hadoop:hadoop
版权归原作者 Qinqin.J 所有, 如有侵权,请联系我们删除。