
一、Hadoop核心技术介绍
Hadoop核心技术的课程总结主要涵盖了Hadoop的基本概念、核心技术模块以及其在大数据处理领域的优势和应用。
首先,Hadoop是一个由Apache基金会开发的分布式系统基础架构,主要用于解决大数据集的存储和计算分析问题。它使用Java语言开发,具有跨平台性,并且是开源的。Hadoop运行在廉价机器上,并考虑到机器故障是常态,因此具有高可靠性和容错性。它利用集群的CPU的并发和计算能力,提供了高性能的处理能力。
1、Hadoop的核心技术模块主要包括以下几个方面:
- HDFS(Hadoop Distributed FileSystem):Hadoop分布式存储文件系统,用于存储大数据集。HDFS是一个可靠性高、可扩展性好的分布式文件系统,它将大规模数据集分散存储在多个计算节点上,实现了数据的冗余备份和高效的并行读写。
- MapReduce:Hadoop的分布式计算框架,提供了移动计算而非移动数据的思想。MapReduce将大规模数据集分解为小的数据块,并在分布式计算集群上进行并行处理,从而能够高效地处理大规模数据集。

- Common:Hadoop框架的通用模块,提供了基础功能和服务。
此外,Hadoop生态系统还提供了许多与Hadoop集成的工具和框架,如Hive、Pig、HBase和Spark等,这些工具和框架扩展了Hadoop的功能,使得数据分析和处理更为方便。
2、Hadoop在大数据处理方面的优势主要体现在以下几个方面:
- 高可靠性:由于数据存储在多个计算节点上,并且备份了多个副本,即使某个节点发生故障,数据仍然可靠地保留在其他节点上。
- 高扩展性:Hadoop能够方便地扩展集群规模,以应对不断增长的数据量和计算需求。
- 高性能:利用集群的并发计算能力,Hadoop能够高效地处理大规模数据集。
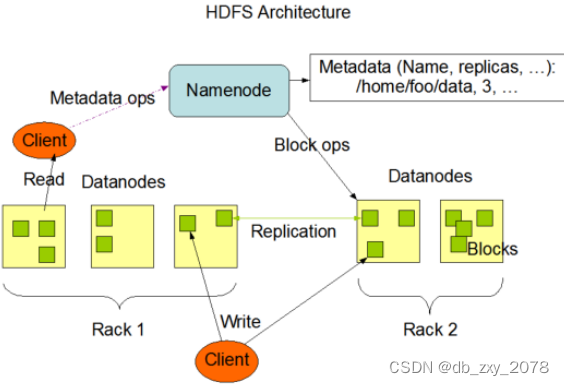
二、HDFS的架构
1、NameNode:即是master:
- 管理HDFS的命名空间
- 配置副本策略
- 惯例数据块Blocks的映射欣喜
- 处理客户端读写请求
2、DataNode:即是slave:
- master下达命令,DataNode执行操作
- 存储实际的数据块
- 执行数据块的读/写操作
**3、Clinet:客户端 **
- 文件切分。文件上传HDFS时,Client将文件切分成一个个Block后上传
- 与NameNode交互,获取文件的位置信息
- 与DataNode交互,读取或写入数据
- Client提供一些命令来管理HDFS,如NameNode语法化
- Client通过一些命令来访问HDFS,如HDFS增删改查操作
4、Secondary NameNode:
- 辅助NameNode,分单其工作量,如定期合并simage和Edits,并推送给NameNode
- 在紧急情况下,可以辅助恢复NameNode
三、HDFS的常用命令
- 显示HDFS指定路径下的所有文件 语法:hdfs dfs -ls
- 在HDFS上创建文件夹 语法:hdfs dfs -mkdir [-p]
- 上传本地文件到HDFS 语法:hdfs dfs -put
- 查看文件 语法:hdfs dfs -cat
- 将HDFS的文件下载到本地文件系统的路径 语法:hdfs dfs -get
- 删除HDFS上的文件或者目录 语法:hdfs dfs -rm [-r]
- 改变指定文件(夹)的所有者或者所属组 语法:hdfs dfs -chown [-R] [OWNER][:[GROUP]]
四、MapReduce概述
定义:MapReduce是一个分布式运算程序的编程框架,其核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
一个基本完整的MapReduce程序流程,包括:数据分片-数据映射-数据混洗-数据归约-数据输出
一个MapReduce例子:对以下左侧“输入”数据进行词频统计,输出结果如右侧“输出”所示
1、Map阶段处理过程
对于输入文件进行键值对组合,即切割出每个单词,并发配初始频数1。
2、Shuffle
将键相同的键值进行汇集
3、Reduce阶段过程
根据实际应用进行结果计算
五、数据处理
Map阶段
/**
* KEYIN,map 阶段输入的key,(Hello World。。。。)
* VALUEIN,map阶段输入的value, (》。。)
* KEYOUT,map阶段输出的key, (Hello) (World) (Our) (World)
* VALUEOUT,map阶段输出的value, (1) (1) (1) (1)
*
* (Hello World。。。。) (World) (1)
*/
public class WordCountMap extends Mapper<LongWritable, Text, Text,IntWritable> {
private Text KEYOUT = new Text();
private IntWritable VALUEOUT = new IntWritable(1);
@Override
protected void map(LongWritable key,
Text value,
Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//从value获取到文本的一行内容 Hello World Our World
String line = value.toString();
//使用了split函数对一行内容进行了切割,得到一个数组words = ["Hello",]
String[] words = line.split(" ");
for (String word : words) {
KEYOUT.set(word);
context.write(KEYOUT,VALUEOUT);
}
}
// public static void main(String[] args){
// String line = "hello you";
// String[] words = line.split(" ");
// for (int i=0; i < words.length;i++){
// String word =words[i];
// System.out.println(word);
// }
// }
}
Reduce阶段
/**
* KEYIN, reduce输入,也是map的输出经过了Shuffle处理,(Hello)。。。。。(Hello)。。。。。。。(Hello)
* VALUEIN, reduce输入,也是map的输出经过了Shuffle处理,(1。1。1)
* KEYOUT, reduce输出,(Hello)
* VALUEOUT,reduce输出,(3)
* 入;String , int 出:String , int
*/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable VALUEOUT = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum =0;//用于累加
for (IntWritable value : values) {
sum+=value.get();//固定写法 0+1=1 1+1=2 2+1=3,最终得到Hello的累加结果3
}
VALUEOUT.set(sum);//固定写法
context.write(key,VALUEOUT);
}
}
Driver阶段
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1 获取job
Configuration conf = new Configuration();
Job job =Job.getInstance(conf);//Job
//2 设置jar路径
job.setJarByClass(WordCountDriver.class);
//3 关联map reduce
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
//4 map的key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5 最终结果的key value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job , new Path(args[0]));//选择提示了String那个setInputPaths
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//文件夹里没有创建wordcount的,该类似我们linux的时候,不能再执行一遍;需要重新统计的时候,命令行改成了output或者删除原output文件夹
//7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
总的来说,Hadoop核心技术的课程不仅深入讲解了Hadoop的基本原理和核心技术,还通过实际案例和项目应用,使学员能够更好地理解和应用Hadoop进行大数据处理和分析。同时,课程也强调了Hadoop的复杂性和学习难点,如需要掌握多种编程语言、工具和框架,深入理解分布式环境以及注重数据安全和管理等。
本文转载自: https://blog.csdn.net/m0_74198026/article/details/137914972
版权归原作者 db_zxy_2078 所有, 如有侵权,请联系我们删除。
版权归原作者 db_zxy_2078 所有, 如有侵权,请联系我们删除。