
0. 前言
最近在系统改造过程中,接触到了国产分布式数据库TDSQL,记录一下关于TDSQL的部分知识点。
1. TDSQL简介
TDSQL是腾讯推出的一款兼容MySQL的自主可控、高一致性分布式数据库产品。
1.1 TDSQL优点:
- 数据强一致性
- 高性能低成本
- 线性水平扩展
- 金融级高可用
- 企业级安全性
- 便捷的运维
1.2 TDSQL系统总览
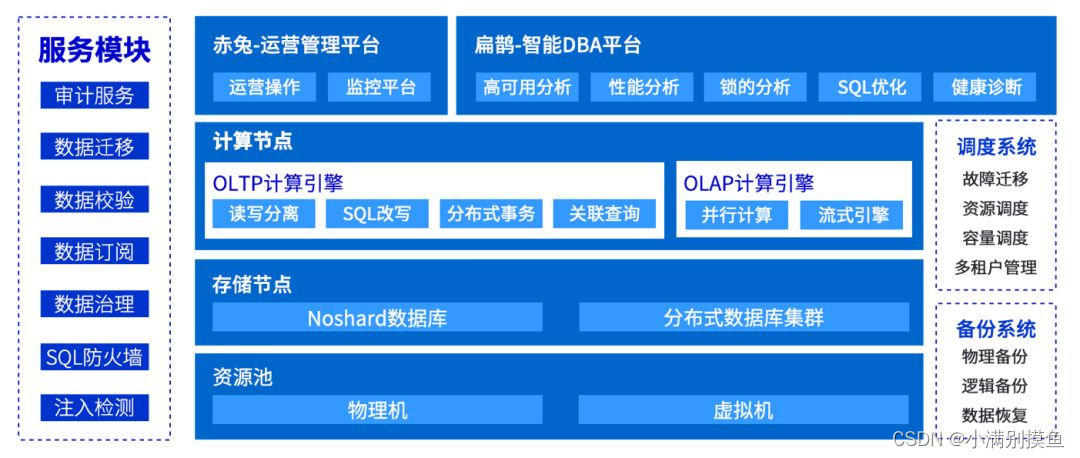
- 资源池:TDSQL部署的服务器资源。
- 存储节点:存储节点要强调的是TDSQL的两种存储形态,一种是Noshard数据库,一种是分布式数据库(也叫Shard版TDSQL)。简单来说,Noshard就是一个单机版的TDSQL,在MySQL的基础上做了一系列的改造和改良,让它支持TDSQL的一系列特性,包括高可用,数据强一致、7×24小时自动故障切换等。第二种是分布式数据库,具备水平伸缩能力。所以TDSQL对外其实呈现了两种形态,呈现一种非分布式形态,一种是分布式的形态。
- 计算节点:计算节点就是TDSQL的计算引擎,做到了计算层和存储层相分离。计算层主要是做一些SQL方面的处理,比如词法解析、语法解析、SQL改写等。如果是分布式数据库形态,还要做分布式事务相关的协调。
- 赤兔运营管理平台 :通过这个平台,DBA可以操纵TDSQL后台黑盒,所以相当于是一套WEB管理系统。让所有DBA的操作都可以在用户界面上完成,而不需要登陆到后台,管理节点的操作可以通过界面化完成。
- “扁鹊”智能DBA平台:扁鹊智能DBA平台还有一个智能诊断系统,可以定期由DBA发起对实例进行的诊断。
1.3 TDSQL架构模块及其特性
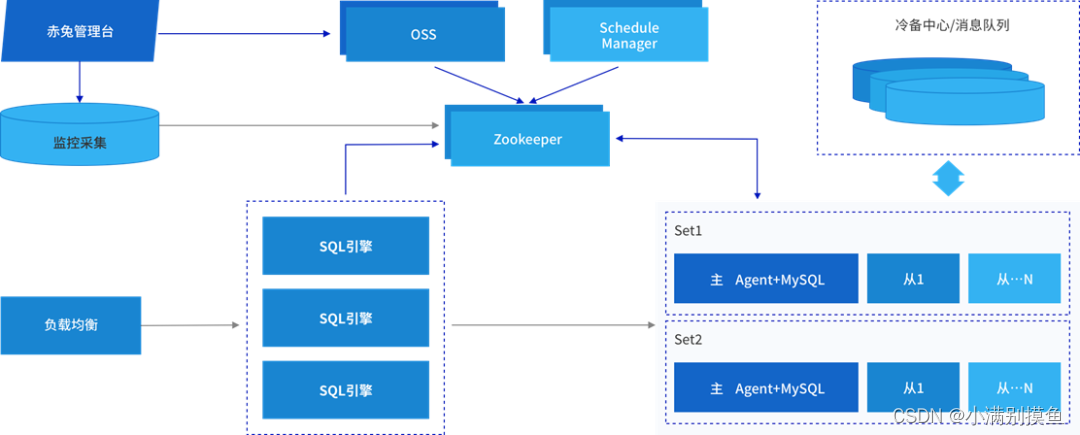
首先用户的请求通过负载均衡发往SQL引擎。然后,SQL引擎作为计算接入层,根据这个SQL的要求从后端的存储节点去取数据。当然,无论是SQL引擎还是后端的数据库实例都存在一个元数据来管理调度。举个例子,计算引擎需要拿到一个路由,路由告诉SQL引擎,这个SQL该发往哪一个后端的数据节点,到底是该发往主节点还是发往备节点。TDSQL引入了ZK(Zookeeper)来储存类似于路由这类元数据信息。当然ZK只是静态的存储元数据,维护和管理这些元数据信息,还需要有一套调度以及接口组件,这里是OSS、Manager/Schedule。这张图可以看到是TDSQL整体来说就分为三部分:管理节点、计算节点和存储节点。当然这里还有一个辅助模块,帮助完成一些个性化需求的,比如备份、消息队列,数据迁移工具等。另外,这里的负载均衡其实不是必需的,用户可以选用自身的硬件负载,也可以用LVS软负载,这个负载均衡根据实际的用户场景可自定义。
2. 模块划分
2.1 管理模块
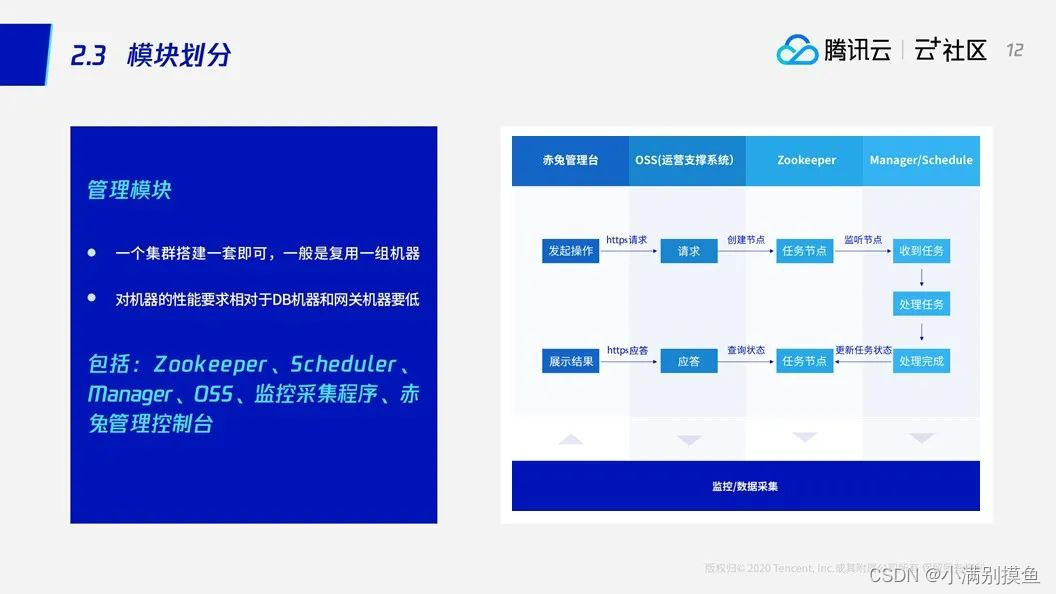
作为一个集群只搭建一套的管理模块,一般可以复用一组机器。
首先,DBA用户在赤兔管理台——这一套WEB前台发起一个操作——点了一个按纽,这个按纽可能是对实例进行扩容,这个按纽会把这个https的请求转移到OSS模块,这个OSS模块有点像web服务器,它能接收web请求,但是它可以把这个转发到ZK。所以,OSS模块就是一个前端到后台的桥梁,有了OSS模块,整个后台的工作模块都可以跟前台、跟web界面绑定在一起。
捕捉到这个请求之后,在ZK上创建一个任务节点,这个任务节点被调度模块捕获,捕获之后就处理任务。处理完任务,再把它的处理结果返回到ZK上。ZK上的任务被OSS捕获,最后也是https的请求,去查询这个任务,最后得到一个结果,返回给前端。
这是一个纯异步的过程。
2.2 DB模块
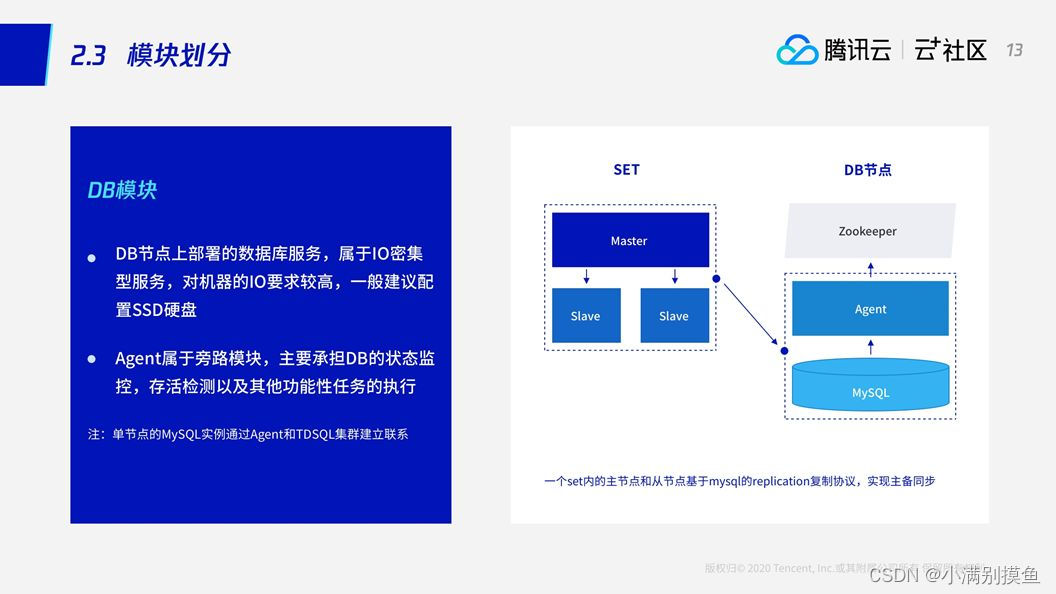
DB模块,即数据节点,数据存取服务属于IO密集型的服务,因此,数据节点是TDSQL的存储节点,它对IO的要求比较高。
SET就是数据库实例,一个SET包含数据库的主从节点。
模块Agent,它来完成对所有集群对MySQL的操作,并且上报MySQL的状态。
2.3 SQL引擎模块
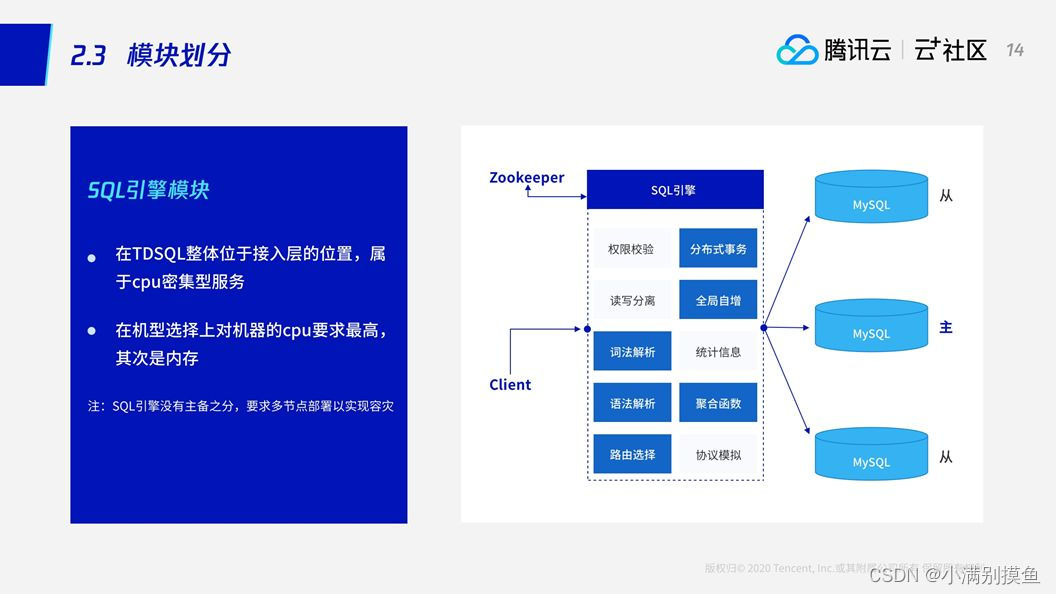
SQL引擎处于计算层的位置,本身属于CPU密集型,所以在选机型上尽量要求CPU高一些。其次是内存,作为计算接入层,它要管理链接,如果是大量的短链接或者长链接,非常占内存,所以它对CPU和内存的要求比较高。此外,它本身不存储数据,也没有主备之分。
SQL引擎要处理分布式事物,还要维护全局自增字段,保证多个数据、多个存储节点共享一个保证全局自增的序列;如果是分布式的话,要限制一些语法,包括词法和语法的解析;还有在一些复杂计算上,它还要做一些SQL下推,以及最后数据的聚合。
2.4 TDSQL主备数据复制
mysql主备数据复制实现方式:
- 异步复制:主机在不等从机应答直接返回客户端成功。
- 半同步:主机在一定条件下等备机应答,如果等不到备机应答,它还是会返回业务成功,也就是说它最终还会退化成一个异步的方式。
- 全同步机制:当主库提交事务之后,所有的从库节点必须收到,APPLY并且提交这些事务,然后主库线程才能继续做后续操作。
TDSQL引入了基于raft协议的强同步复制,主机接收到业务请求后,等待其中一个备机应答成功后才返回客户端成功。
有点类似把半同步的基础上把这个超时时间改成无限大同时应答的备机设置为1,但是TDSQL强同步复制的性能是在原生半同步的基础上做了大量的优化和改进,使得性能基本接近于异步。
2.5自动容灾切换
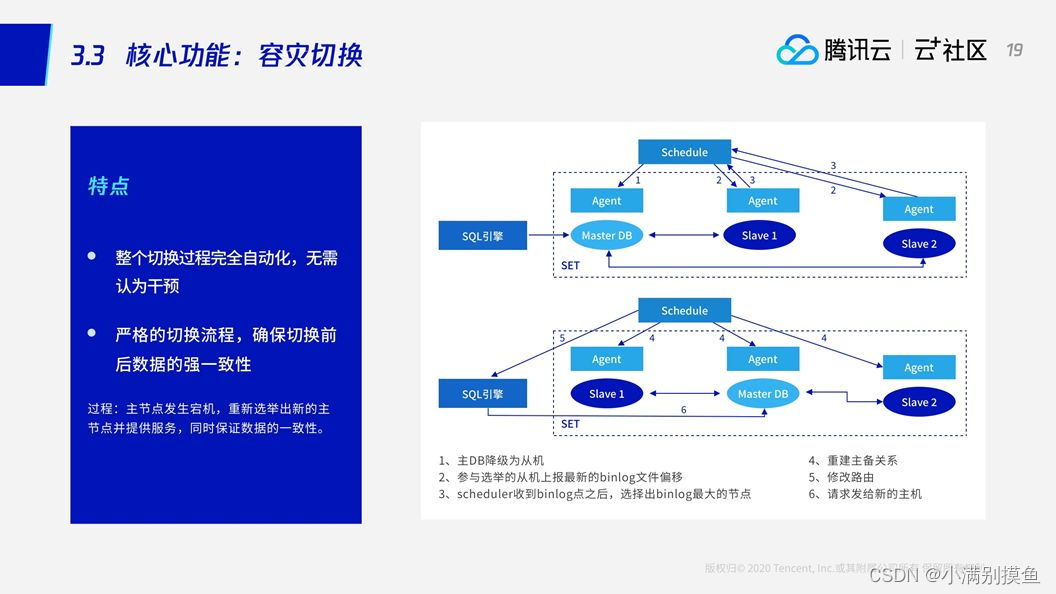
SQL引擎将请求发给主节点,主节点被两个备机所同步,每个节点上都有对应的Agent上报当前节点的状态。这时,主节点发生了故障被Agent觉察,上报到zk被Scheduler捕获,然后Scheduler首先会把这个主节点进行降级,把它变成Slave。也就是说此时其实整个集群里面全是Slave,没有主节点。这个时候另外两个存活的备机上报自己最新的binlog点,因为有了强同步的保障,另外两个备机其中之一一定有最新的binlog,那么两个备机分别上报自己最新的点后,Schedule就可以清楚的知道哪个节点的数据是最新的,并将这个最新的节点提升成主节点。
容灾切换需要建立在强同步的基础上。
2.6 数据强一致性
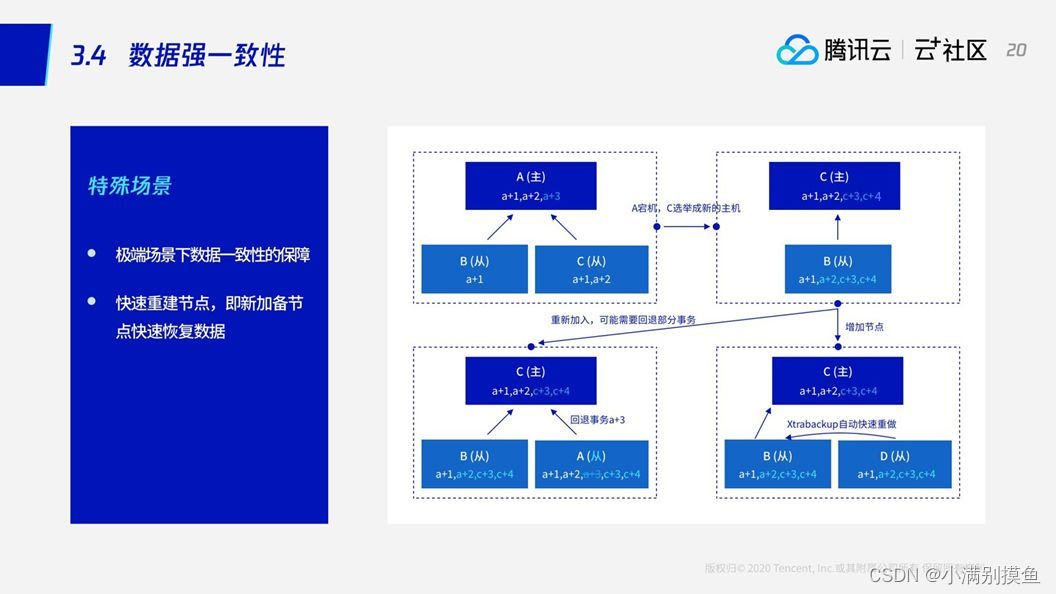
比如说A节点作为主节点,B、C是从,正常去同步A节点的数据,A+1、A+2,接下来该同步A+3。当A+3还没有同步到从节点的时候发生了故障,这个时候根据B、C节点的数据情况,C的数据是最新的,因此C被选成了主节点,进而C继续同步数据到B。过了一阵,A节点拉起了,可以重新加入集群。重新加入集群之后,发现它有一笔请求A+3还没有来得及被B、C节点应答,但已经写入到日志。这个时候其实A节点的数据是有问题的,我们需要把这个没有被备机确认的A+3的回滚掉,防止它将来再同步给其他的节点。
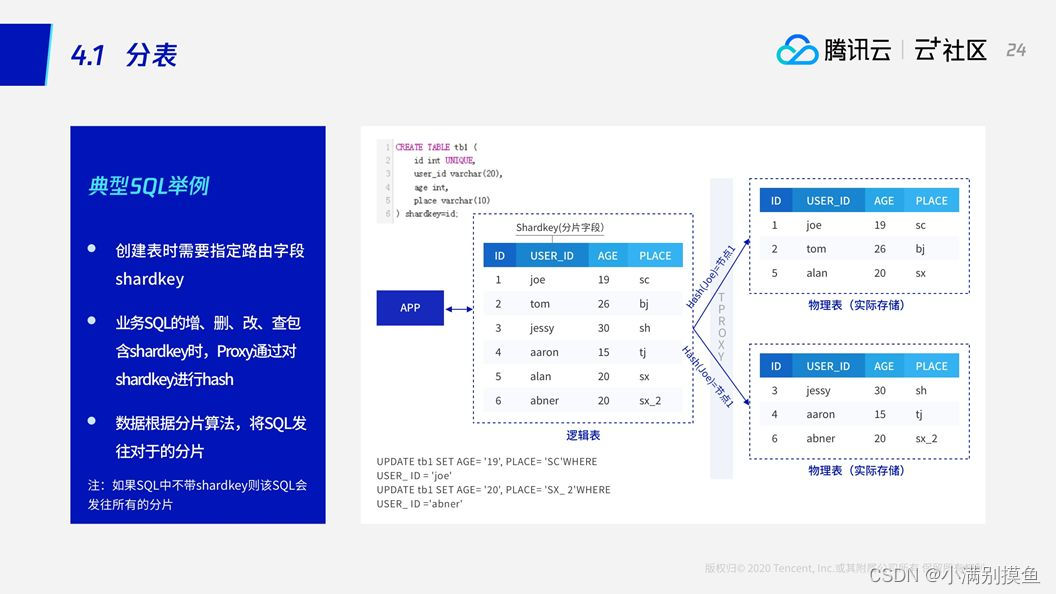
3. 分表
3.1 分表
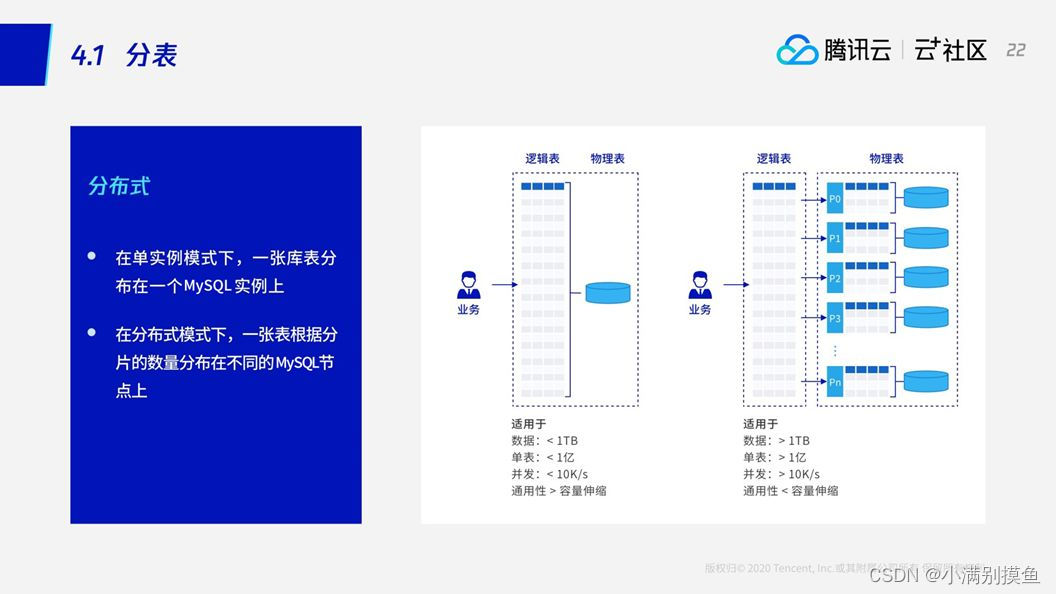
shardkey——是TDSQL的分片关键字,也就是说TDSQL会根据shardkey字段将这个数据去分散。
3.2 水平拆分
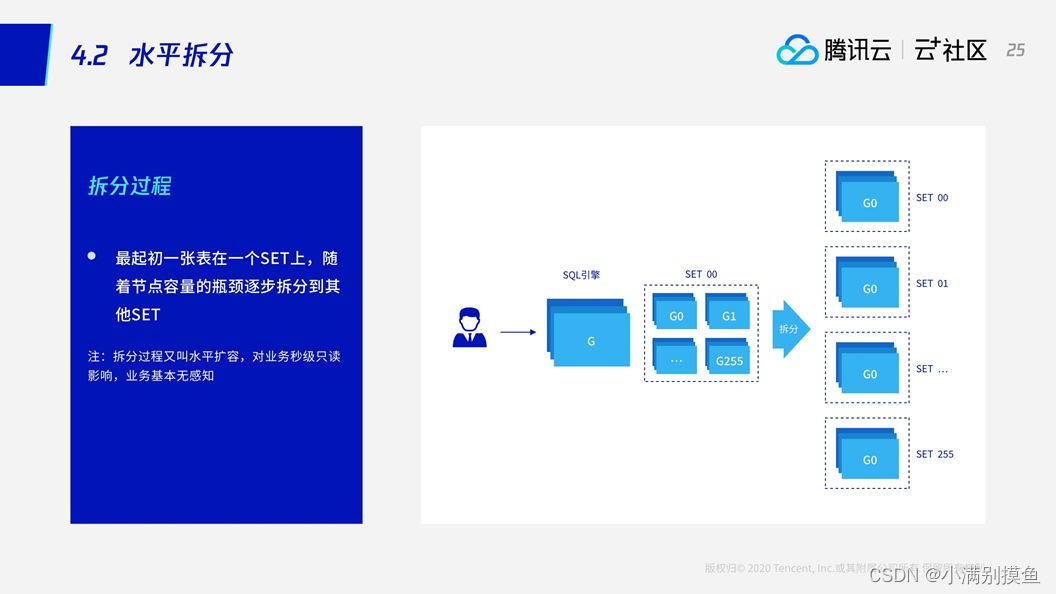
对于分布式来说,可能最初我们所有的数据都在一个节点上。当一个节点出现了性能瓶颈,需要将数据拆分。
3.3 分布式事务
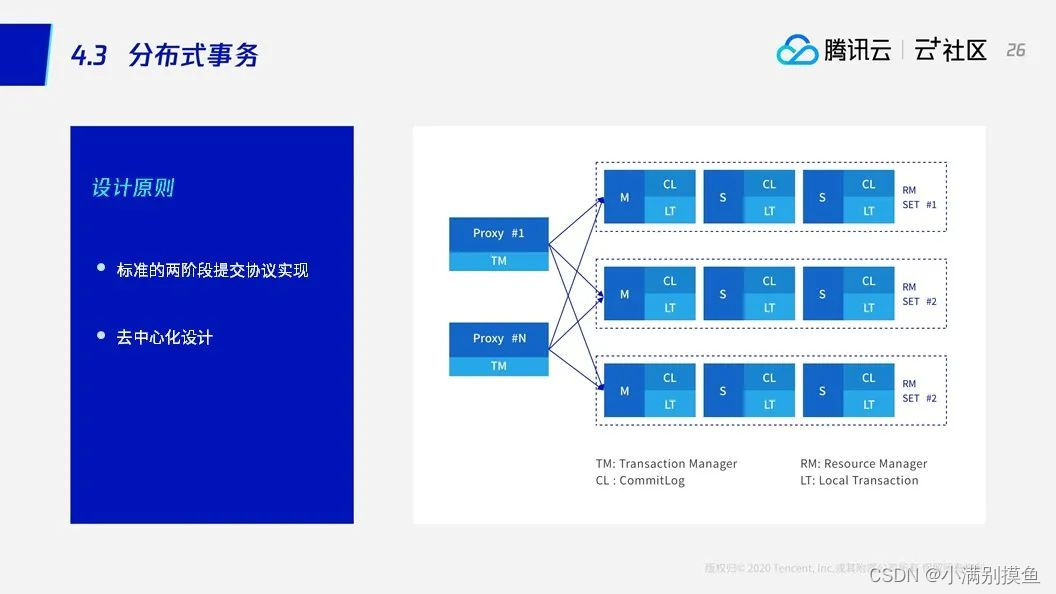
分布式事务也是根据shardkey来判断,具体来说,对于SQL引擎读发起一个事务,比如第一条SQL是改用户ID为A的用户信息表。第二条SQL是插入一个用户ID为A的流水表,这两张表都以用户ID作为shardkey。如果这两条SQL都是发往一个分片,虽然是一个开启的事务,但是发现它并没有走分布式事务,它实际还是限制在单个分片里面走了一个单节点的事务。当然如果涉及到转帐:比如从A帐户转到B帐户,正好A帐户在第一个分片,B帐户是第二个分片,这样就涉及到一个分布式事务,需要SQL引擎完成整个分布式事务处理。
TDSQL分布式事务优点:
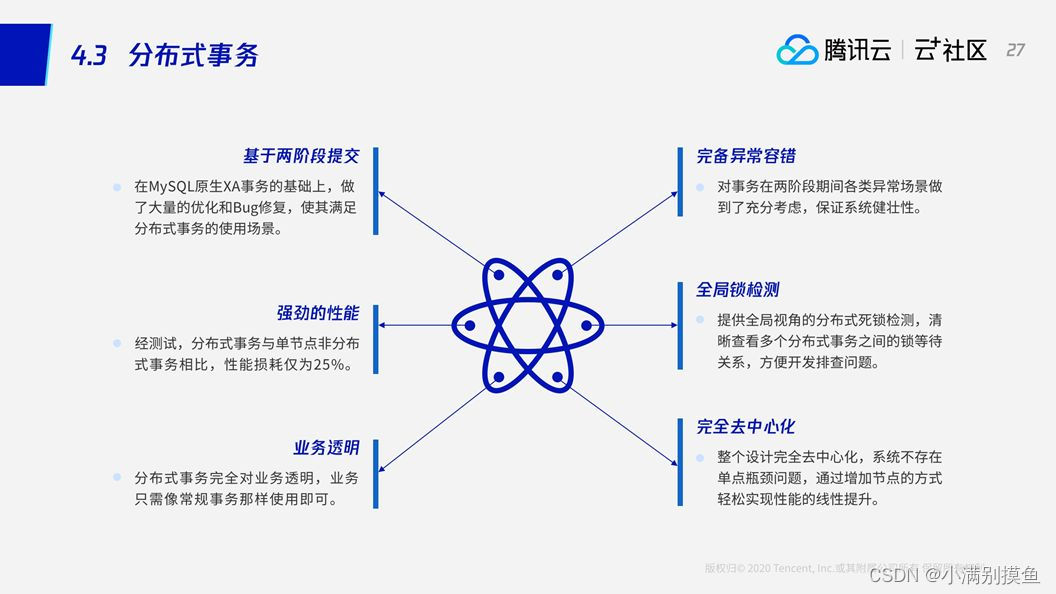
3.4 分布式总结

版权归原作者 小满别摸鱼 所有, 如有侵权,请联系我们删除。