
同步的不足
1、拓展性差,当要添加功能时,需要在原来的功能代码上做修改,高耦合。
2、性能下降,调用者需要等待服务提供者执行完返回结果后,才能继续向下执行
3、级联失败,由于我们是基于OpenFeign调用交易服务、通知服务。当交易服务、通知服务出现故障时,整个事务都会回滚(回滚的范围取决于自己的设定)
而通过RabbitMQ就能解决上述问题,因为其是异步调用
安装 安装docker后,使用docker拉取RabbitMQ的镜像,进行部署
相关概念
publisher: 生产者,也就是发送消息的一方
consumer: 消费者,也就是消费消息的一方
queue: 队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理
exchange: 交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列
virtual host: 虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
(与MySQL中的不同数据库相似)
SpringAMQP
RabbitMQ采用了AMQP协议,因此它具备跨语言的特性。任何语言只要遵循AMQP协议收发消息,都可以与RabbitMQ交互,而Spring的官方刚好基于RabbitMQ提供了这样一套消息收发的模板工具:SpringAMQP
提供的三个功能:
自动声明队列、交换机及其绑定关系
基于注解的监听器模式,异步接收消息
封装了RabbitTemplate工具,用于发送消息
案例入门
采用的方案结合注解的方式没有使用控制台。方便快速在Spring项目中开发
publisher发送消息到交换机,交换机发送消息到队列,consumer发送接受队列中的消息
导入AMQP依赖
<!--AMQP依赖,包含RabbitMQ--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency>
WorkQueues模型
让多个消费者绑定到一个队列,共同消费队列中的消息
有什么好处?
消息的处理速度就能提高
最佳实践
**消息发送到队列,模拟大量消息堆积的队列
/**
* workQueue
* 向队列中不停发送消息,模拟消息堆积。
*/
@Test
public void testWorkQueue() throws InterruptedException {
// 队列名称
String queueName ="simple.queue";
// 消息
String message ="hello, message_";for(int i =0; i <50; i++){
// 发送消息,每20毫秒发送一次,相当于每秒发送50条消息
rabbitTemplate.convertAndSend(queueName, message + i);
Thread.sleep(20);}}
消息接受
两个消费者接收队列中的消息,接受者1每20ms接收一个,消费者2每200ms接受一个
@RabbitListener(queues ="work.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(20);}
@RabbitListener(queues ="work.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(200);}
两个消息接收者都设置了Thead.sleep,模拟任务耗时:
消费者1 sleep了20毫秒,相当于每秒钟处理50个消息
消费者2 sleep了200毫秒,相当于每秒处理5个消息
可是实际测试结果是消费者1和消费者2竟然每人消费了25条消息:
消费者1很快完成了自己的25条消息,消费者2却在缓慢的处理自己的25条消息。
出现这种现象表明队列对于消息的分配并没有考虑到每个消费者的实际能力
优化配置
在yml文件中配置prefetch: 1 (
prefetch: 1
表示每个消费者每次只能从队列中预取1个消息,消费完就能拿下一次,不需要等轮询。它可以帮助保证每个消息在被消费者处理时都能得到较为均匀的分配,避免某个消费者处理速度慢而导致其他消费者空闲的情况。)
spring:
rabbitmq:
listener:
simple:
prefetch: 1# 每次只能获取一条消息,处理完成才能获取下一个消息
交换机
作用: 在接受生产者消息的同时最重要的是如何处理消息,比如是交给所有队列还是交给某个特定的队列
Fanout: 将消息交给所有绑定到交换机的队列,就像上面的案例,默认是每个队列平均的接受消息
Direct: 基于RoutingKey(路由key)发送给订阅了消息的队列,交换机不再把消息交给每个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的Routing Key与消息的Routing Key完全一致,这个队列才能接收到消息
总结
Direct交换机与Fanout交换机的差异?
Fanout交换机将消息路由给每一个与之绑定的队列
Direct交换机根据RoutingKey判断路由给哪个队列
如果多个队列具有相同的RoutingKey,则与Fanout功能类似
Topic交换机
在Direct交换机中它对于队列接收消息的选择性是单一的,只能被单个的Routing Key绑定,而如果在将队列绑定Key时使用通配符绑定 就能将队列同时绑定多个Key
比如:
#:匹配一个或多个词
*:匹配不多不少恰好1个词
item.#:能够匹配item.spu.insert 或者 item.spu
item.*:只能匹配item.spu
接下来正式开始编码使用RabbitMQ,直接使用注解声明队列和交换机
消息发送者
后续前端请求该方法就可以发送消息
/**
* topicExchange
*/
@Test
public void testSendTopicExchange(){
// 交换机名称
String exchangeName ="hmall.topic";
// 消息
String message ="喜报!孙悟空大战哥斯拉,胜!";
// 发送消息
rabbitTemplate.convertAndSend(exchangeName, "blue", message);}
消息接受者
声明Direct模式的交换机和队列
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name ="direct.queue1"),//。如果指定名称的队列不存在,则会自动创建该队列
exchange = @Exchange(name ="hmall.direct", type= ExchangeTypes.DIRECT),//声明了direct的交换机
key ={"red", "blue"}//声明了key
))
public void listenDirectQueue1(String msg){
System.out.println("消费者1接收到direct.queue1的消息:【" + msg + "】");}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name ="direct.queue2"),
exchange = @Exchange(name ="hmall.direct", type= ExchangeTypes.DIRECT),
key ={"red", "yellow"}))
public void listenDirectQueue2(String msg){
System.out.println("消费者2接收到direct.queue2的消息:【" + msg + "】");}
结果就是只有listenDirectQueue1才能接收到消息
一、使用 RabbitMQ 作为中间通信层,实现不同编程语言间的通信,使用消息队列完成定时任务,保证功能可靠性
1.1、虚拟机安装RabbitMQ
首先是在虚拟机中安装配置RabbitMQ,基于docker安装,
docker pull rabbitmq
创建并运行 RabbitMQ 容器
docker run -d-p15672:15672 -p5672:5672 \-eRABBITMQ_DEFAULT_VHOST=my_vhost \-eRABBITMQ_DEFAULT_USER=admin \-eRABBITMQ_DEFAULT_PASS=admin \--hostname myRabbit \--name rabbitmq \
rabbitmq
1.2、SpringBoot部署RabbitMQ
添加依赖spring-boot-starter-amqp
修改yaml配置
spring:
#rabbitmq 配置
rabbitmq:
host: 192.168.79.202
username: guest
password: guest
#虚拟主机
virtual-host: /
#端口
port: 5672
listener:
simple:
#消费者最小数量
concurrency: 10#消费者最大数量
max-concurrency: 10#限制消费者,每次只能处理一条消息,处理完才能继续下一条消息
prefetch: 1#启动时是否默认启动容器,默认为 true
auto-startup: true#被拒绝时重新进入队列的
default-requeue-rejected: true
template:
retry:
#启用消息重试机制,默认为 false
enabled: true#初始重试间隔时间
initial-interval: 1000ms
#重试最大次数,默认为 3 次
max-attempts: 3#重试最大时间间隔,默认 10000ms
max-interval: 10000ms
#重试的间隔乘数,#配置 2 的话,第一次等 1s,第二次等 2s,第三次等 4s
multiplier: 1#在 RabbitMQ 中,initial-interval 和 max-interval 是用于指定消息重试机制的两个参数,#它们的区别如下:#1. initial-interval(初始间隔时间):表示第一次重试的时间间隔,也就是在消息第一次处#理失败后,等待多长时间再尝试重新发送消息。这个参数的默认值是 1 秒。#2.max-interval(最大间隔时间):表示重试过程中的最大时间间隔,也就是每次重试时,#最长等待多长时间再尝试重新发送消息。这个参数的默认值是 10 秒。
1.3、消息发送者
@AutowiredprivateAmqpTemplate rabbitTemplate;//这里需要创建AmapTemplate对象,以便调用convertAndSend方法@TestpublicvoidtestSendTopicExchange(){// 交换机名称String exchangeName ="hmall.topic";// 消息String message ="检测到摔倒";// 发送消息
rabbitTemplate.convertAndSend(exchangeName, “ " message);}
这里传入的参数跟使用什么交换机有关系,如果使用funout交换机 就队列交换机和消息,如果使用direct交换机 就需要传入key 交换机名字 消息
在这个例子中生产者使用默认的交换机 所以需要指定队列 而不用指定key(主要是完成语言之间的通信)
1.4、python部署RabbitMQ
python中使用pika操作RabbitMQ
# coding=utf-8### 消费者import pika
user_info = pika.PlainCredentials('root','root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip',5672,'/', user_info))
channel = connection.channel()# 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作,生产者和消费者都做这一步的好处是# 这样生产者和消费者就没有必要的先后启动顺序了
channel.queue_declare(queue='hello')# 回调函数defcallback(ch, method, properties, body):print('消费者收到:{}'.format(body))# channel: 包含channel的一切属性和方法# method: 包含 consumer_tag, delivery_tag, exchange, redelivered, routing_key# properties: basic_publish 通过 properties 传入的参数# body: basic_publish发送的消息
channel.basic_consume(queue='hello',# 接收指定queue的消息
auto_ack=True,# 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息
on_message_callback=callback # 设置收到消息的回调函数)print('Waiting for messages. To exit press CTRL+C')# 一直处于等待接收消息的状态,如果没收到消息就一直处于阻塞状态,收到消息就调用上面的回调函数
channel.start_consuming()
队列使用的是默认队列
1.5、整体流程
在前端界面点击 发送get请求 前端根据传过来的是1还是2 就来进行不同的活动
importorg.springframework.web.bind.annotation.GetMapping;importorg.springframework.web.bind.annotation.RequestParam;importorg.springframework.web.bind.annotation.RestController;@RestControllerpublicclassMyController{@GetMapping("/example")publicStringexampleController(@RequestParam("param1")String param1,@RequestParam("param2")int param2){// 处理参数并返回响应return;}}
是1 就进行摔倒检测
后端使用RabbitMq的生产者的方法 发送消息到队列, python端接收到发送到指定队列的消息后开始调用摔倒检测 摔倒检测因为是使用的yolov8所以没有在本机运行,调用阿里云的服务
持续检测阿里云返回的是什么 如果返回的是摔倒了,就进行后续的活动
是2就通知python进行人脸检测安防
实现了python和java的通信之后再来说说如何实现的定时任务的
然后在ServiceImpl填写具体的方法 使用RabbitMQ发送消息
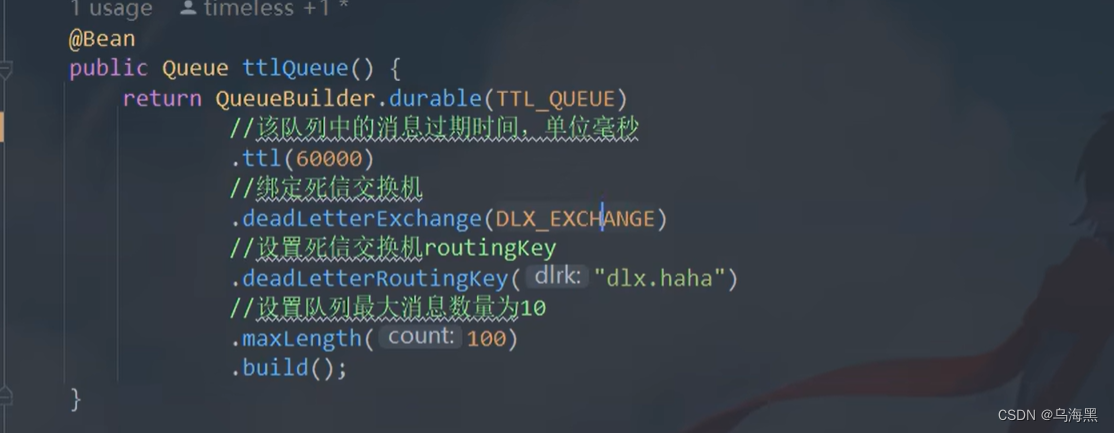
rabbitTemplate.convertAndSend(RabbitMQConfig.TTL_EXCHANGE,"ttl.test", orderInfo)
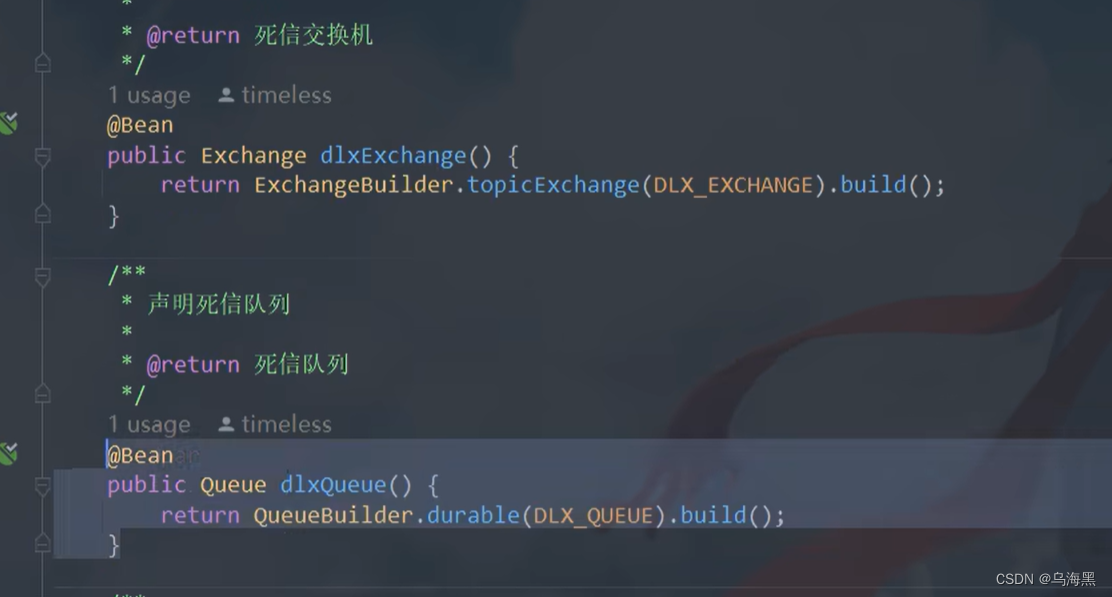
发送给ttl交换机 这个交换机绑定了ttl队列,同时ttl队列绑定了死信交换机,这个死信交换机绑定了死信队列
有由于这个ttl队列设置了过期时间,所以过期时间到后,消息就会到死信交换机
死信队列监听到之后就会开始处理,这样就能确保定时任务中不会确保定时没有成功的情况
RabbitMQ如何保证消息不丢失
生产者确认机制
RabbitMQ提供了publisher confirm机制来避免消息发送到MQ过程中丢失。消息发送到MQ以后,会返回一个结果给发送者,表示消息是否处理成功(避免了消息在发送交换机或者发送到队列丢失的情况)
MQ默认是内存存储消息,开启持久化功能可以确保缓存在MQ中的消息不丢失。
当内存出问题还有磁盘兜底
通过交换机持久化,队列持久化,消息持久化
消费者确认
RabbitMQ支持消费者确认机制,消费者处理消息后可以向MQ发送ack回执,MQ收到ack回执后才会删除该消息
最好采用auto的确认模式 即 自动ack 由spring检测istener代码是否出现异常,没有异常就返回ack,抛出异常就返回nack
如果消费者接受消息失败,也可以利用Spring的retry机制,在消费者出现异常时利用本地重试,设置重试次数,当次数达到以后,如果消息依然失败将消息投递到异常交换机,交由人工处理
RabbitMQ消息的重复消费问题
出现的原因是网络抖动等,消费者处理消息后因为网络问题没能成功发送确认给MQ,导致Spring的重试机制,就重复消费了消息
解决方案:
每条消息设置一个唯一的标识id
幂等方案 ,可以加锁
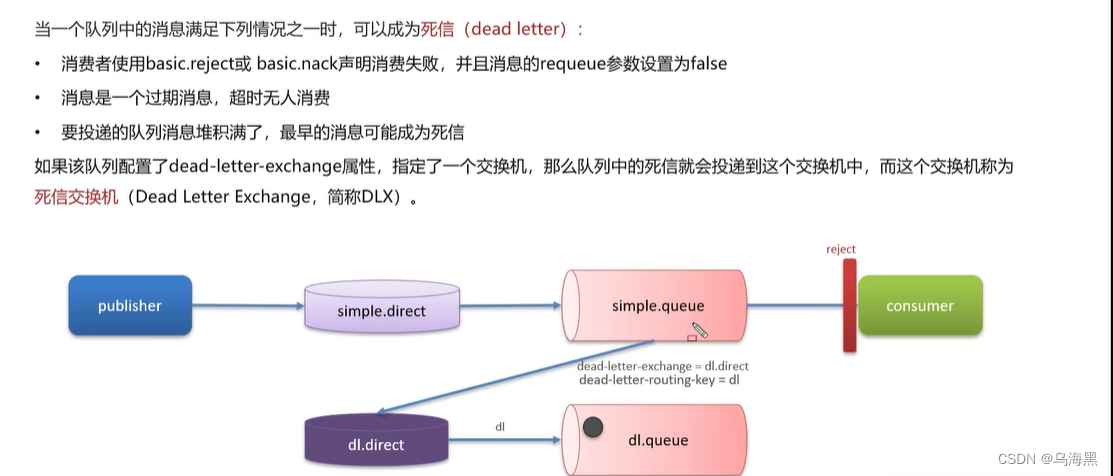
死信交换机(延迟队列)
延迟队列:进入队列的消息会被延迟消费的队列
场景:超时订单、限时优惠、定时发布
延迟队列=死信交换机+TTL
TTL,也就是Time-To-Live。如果一个队列中的消息TTL结束仍未消费,则会变为死信,ttl超时分为两种情况:
消息所在的队列设置了存活时间
消息本身设置了存活时间
延迟队列插件
可以使用DelayExchange插件
DelayExchange的本质还是官方的三种交换机,只是添加了延迟功能。因此使用时只需要声明一个交换机,交换机的类型可以是任意类型,然后设定delayed属性为true即可。
具体怎么使用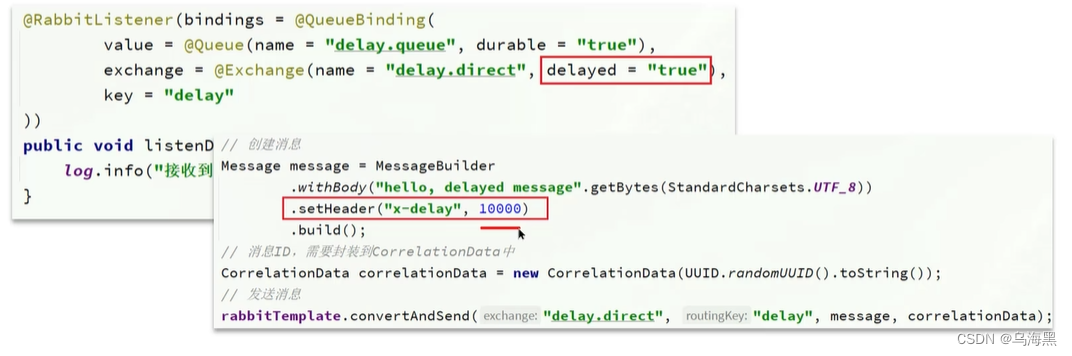
如果有100万消息堆积在MQ,如何解决
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题
增加更多消费者,提高消费速度
在消费者内开启线程池加快消息处理速度
扩大队列容积,提高堆积上限
惰性队列的特征如下:
接收到消息后直接存入磁盘而非内存
消费者要消费消息时才会从磁盘中读取并加载到内存
支持数百万条的消息存储
配置的方式添加
注解的方式添加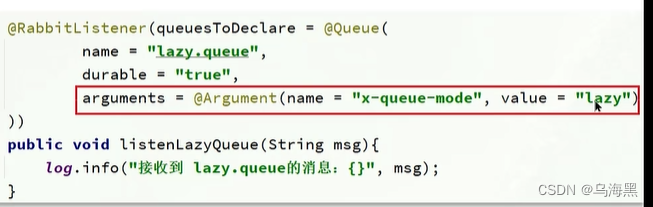
RabbitMQ高可用机制
在生产环境下,使用集群来保证高可用性
普通集群、镜像集群、仲裁队列
暂时不看
版权归原作者 乌海黑 所有, 如有侵权,请联系我们删除。